怎么生成你想要的图片?MaskDiffusion帮你实现
本文详细介绍了一种自适应掩码的交叉注意力机制,该机制基于注意力图和提示嵌入动态调整每个文本标记对图像特征的贡献。这一方法显著减少了文本编码器中语义信息嵌入的模糊性,从而提高了合成图像的文本到图像一致性。
本推文介绍了收录于IJCV2024的论文《MaskDiffusion: Boosting Text-to-Image Consistency with Conditional Mask》,作者Yupeng Zhou,Daquan Zhou,Yaxing Wang等提出了MaskDiffusion方法,通过引入条件掩码来增强交叉注意力机制,以动态调整每个文本标记对图像特征的贡献。成功在不增加额外计算成本和数据集的情况下,提高文本到图像一致性,改善现有扩散模型在生成对象及其属性时的准确性。
推文作者为龚裕涛,审校为王一鸣。
原文链接:https://link.springer.com/article/10.1007/s11263-024-02294-2
代码链接:https://github.com/HVision-NKU/MaskDiffusion
1.期刊介绍

International Journal of Computer Vision(IJCV)于1987年出版,期刊详细介绍计算机领域的科学和工程。一般性发表的文章提出广泛普遍关心的重大技术进步,短文章提供了一个新的研究成果快速发布通道。综述性文章给予了重要的评论,以及当今发展现状的概括。IJCV是CCF推荐的人工智能领域四个A类期刊之一,是人工智能、计算机视觉最重要的顶级学术期刊之一。
2.研究背景及主要贡献
近年来,扩散模型在图像生成领域取得了显著的进展,展示了其生成高质量图像的强大能力。这些模型通过迭代去噪的方法有效地建模数据分布,已成为生成方法中的主流。然而,确保生成图像与给定文本提示之间的正确匹配仍然是一个持续的挑战。
尽管当前的一些最先进的根据文本生成图像的模型(如DALL·E 2、Stable Diffusion等)在生成高质量图像方面表现出色,但它们在文本提示与生成图像之间的一致性方面仍存在不足。在文本到图像生成过程中,一些常见的问题包括对象缺失、属性不匹配以及颜色、材料和位置等细节错误,如图1所示。

图1 文本与生成图像不一致展示
3.方法
在本文中,作者重新审视交叉注意力机制,指出问题所在,并提出MaskDiffusion方法以指导文本进行图像生成。在没有任何训练下,该方法是即插即用且无需潜优化,仅在去噪过程中修改交叉注意力映射。得益于这样的设计,该方法能够以最小消耗和更高效率解决一致性问题。
3.1审视交叉注意力机制
(1)重叠关注区域:当两个没有语义关系的对象在注意力图中重叠且它们的注意值接近时,会产生语义冲突。在这种情况下,扩散模型会忽略其中一个对象。例如图1中,马和狗之间没有语义关系,但关注区域重叠。存在语义冲突,因此扩散模型忽略了狗,只生成了马。
(2)抢占关注区域:在这种情况下,两个对象的关注区域出现在正确的位置,但它们之间存在较大的注意值差异。由于Softmax操作会在标记之间产生竞争,具有较大激活值的对象可能会抑制具有较小激活值对象的表达。例如图2中,“大象”的注意分数远高于“眼镜”。因此,“眼镜”未出现在生成的图像中。
(3)错误关注区域:这种情况涉及到描述属性词对应标记的交叉注意力图。这意味着属性出现在错误的位置,从而导致属性被表达在其他对象上。如图1所示,“黄色”属性反映在“鸟”对象上,而不是“熊”对象。因此,没有按照提示生成蓝色鸟。在生成的图像中,“鸟”是黄色而不是蓝色。
3.2MaskDiffusion方法
通过在文本提示嵌入和交叉注意力图上添加一个条件掩码,整体流程如图2所示。给定一个文本提示,一开始提取与视觉内容中存在对象对应的所有名词和形容词。在采样过程中,使用Stable Diffusion的预训练U-Net网络在每个时间步进行去噪,同时将掩码应用于交叉注意力块。具体来说,掩码M是通过一个算法计算交叉注意力图得到,重点关注选定标记,如对象名词及其相关属性。为了在推理过程中优化计算效率,仅计算与提取出的名词和形容词相关联的注意力掩码,而忽略其他文本标记。
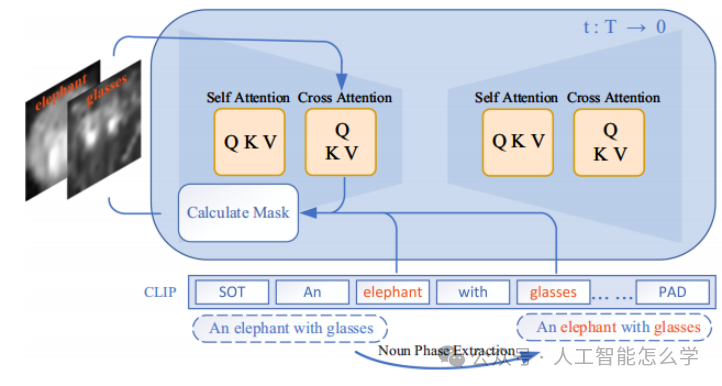
图2 MaskDiffusion整体流程
掩码生成算法的核心目标是通过调整交叉注意力图来提高文本到图像生成的一致性。首先,算法接收文本提示P、选定标记集S以及一个初始为零的掩码矩阵M作为输入,并设置权重参数w接下来,对于每个选定标记,算法使用区域选择算法从注意力图中找到与该标记相关的像素,并将这些像素放入对应的区域这一过程旨在选择具有高响应值的区域,同时避免不同区域之间的重叠。在此基础上,算法对每个标记对应的区域中的每个像素进行处理:首先找到当前掩码中该像素的最大值,然后更新掩码矩阵中的相应位置,通过增加权重参数乘以最大值来完成更新。最终,生成并输出用于改善文本到图像一致性的掩码矩阵。
4.实验
4.1生成图像质量比较
对MaskDiffusion与Stable Diffusion,Composable Diffusion,StructureDiffusion和Attend-and-Excite的视觉比较可以看出,从生成的图像来看,MaskDiffusion方法在所有五个模型中表现最佳。
如图3所示,对于复杂和简单提示,本文的的MaskDiffusion可以实现更好的图像质量和改进的一致性,可以产生自然整合所需元素且构图和谐逼真的图像。
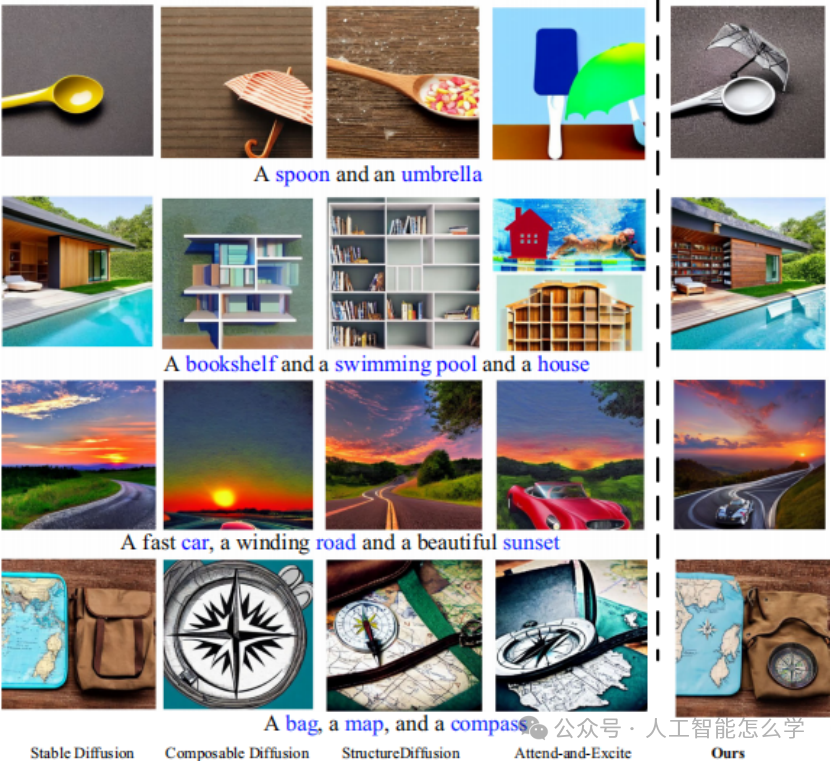
图3 生成图像对比
4.2推理速度比较
对方法MaskDiffusion与Stable Diffusion、Composable Diffusion、StructureDiffusion和Attend-and-Excite的定量比较。如表1所示,提供了推理时间、CLIP分数和BLIP分数在两个测试集上的表现,以全面衡量模型的性能。
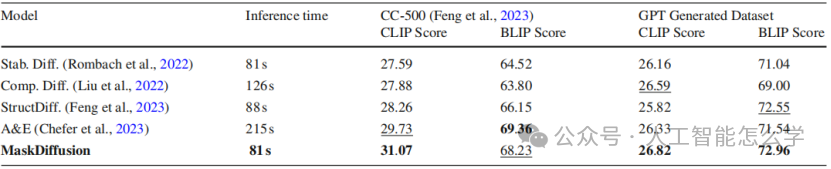
表1 性能对比
在这五种模型中,Attend-and-Excite表现出最慢的推理速度,这主要是由于单一采样时间步内的迭代优化所致。MaskDiffusion推理大约需要81秒,与原版Stable Diffusion相当,并且显著快于需要215秒的Attend-and-Excite。
4.3消融实验
在MaskDiffusion方法中使用动量更新交叉注意力图。这种方法考虑了前一个时间步的信息,使生成的掩码更加稳定。为了展示这一操作的效果,设计了一组消融实验,即原始Stable Diffusion、没有动量更新的MaskDiffusion和完整的MaskDiffusion,在图4中显示结果。从图中可以看出,没有动量更新策略时,生成图像中可能会缺失一些对象。

图4 消融实验效果图
4.4可插拔性测试
为证明方法的可插拔性,对其他模型进行了测试,即RealVision和原始Stable Diffusion 1.5。观察到相似问题,如对象遗漏和属性错误,在其他扩散模型中仍然存在。在这些模型上实施MaskDiffusion后,观察到结果有类似增强,结果如图5所示。

图5 可插拔性测试效果图
5.总结
论文中重新审视交叉注意力机制,指出问题所在,并提出MaskDiffusion方法以指导文本进行图像生成。MaskDiffusion可以用于生成具有高度文本到图像一致性的高质量图像。在广泛的实验中,与原始扩散模型相比,MaskDiffusion以较低成本实现了更好的文本到图像一致性。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)