Neurlps2024论文解析|Chain of Preference Optimization Improving Chain-of-Thought Reasoning in LLMs-water
本文提出了一种新的方法——链式偏好优化(CPO),旨在提高大型语言模型(LLMs)在复杂问题解决中的推理能力。尽管链式思维(CoT)解码能够生成明确的逻辑推理路径,但研究表明这些路径并不总是最佳的。树形思维(ToT)方法通过树搜索探索推理空间,发现CoT可能忽略的更优路径,但其推理复杂度显著增加。CPO通过利用ToT构建的搜索树对LLMs进行微调,使得CoT能够在不增加推理负担的情况下实现类似或更
论文标题
Chain of Preference Optimization: Improving Chain-of-Thought Reasoning in LLMs 链式偏好优化:改进大型语言模型中的链式思维推理
论文链接
Chain of Preference Optimization: Improving Chain-of-Thought Reasoning in LLMs论文下载
论文作者
Xuan Zhang, Chao Du, Tianyu Pang, Qian Liu, Wei Gao, Min Lin
内容简介
本文提出了一种新的方法——链式偏好优化(CPO),旨在提高大型语言模型(LLMs)在复杂问题解决中的推理能力。尽管链式思维(CoT)解码能够生成明确的逻辑推理路径,但研究表明这些路径并不总是最佳的。树形思维(ToT)方法通过树搜索探索推理空间,发现CoT可能忽略的更优路径,但其推理复杂度显著增加。CPO通过利用ToT构建的搜索树对LLMs进行微调,使得CoT能够在不增加推理负担的情况下实现类似或更好的性能。实验结果表明,CPO在问答、事实验证和算术推理等多种复杂问题上显著提高了LLM的性能,验证了其有效性。

分点关键点
-
链式偏好优化(CPO)方法
- CPO通过对LLMs进行微调,使其在推理过程中对每一步的CoT路径与ToT路径进行对齐,利用树搜索过程中的偏好信息。这种方法避免了高推理复杂度,同时提升了推理质量。
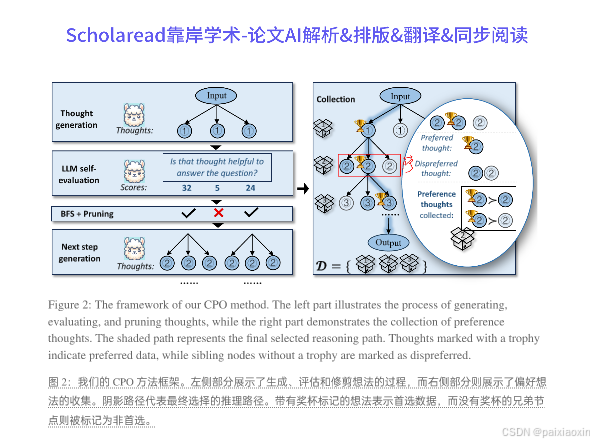
- CPO通过对LLMs进行微调,使其在推理过程中对每一步的CoT路径与ToT路径进行对齐,利用树搜索过程中的偏好信息。这种方法避免了高推理复杂度,同时提升了推理质量。
-
推理路径的生成与评估
- CPO在每个推理步骤中生成多个思维,并对其进行评估,选择出最佳的推理路径。通过对生成的思维进行分类,CPO能够有效地利用非最优思维提供的偏好信息,从而增强LLMs的推理能力。
-
实验结果与性能提升
- 在七个数据集上的实验表明,CPO在多个推理任务中相较于基础模型平均提高了4.3%的准确率,最高可达9.7%。此外,CPO的推理延迟显著低于ToT方法,表明其在效率和效果上的优势。
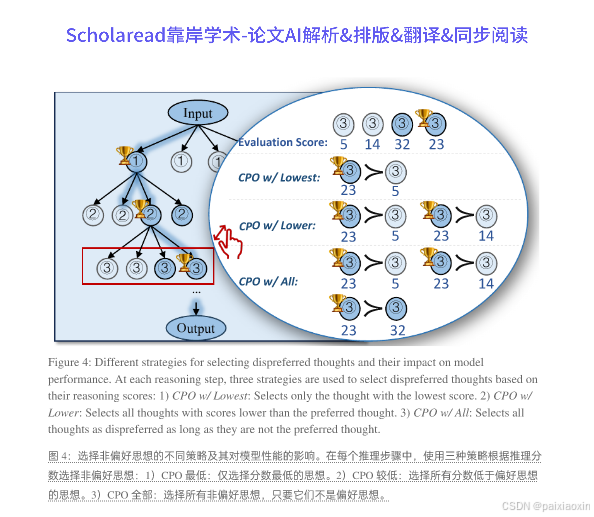
- 在七个数据集上的实验表明,CPO在多个推理任务中相较于基础模型平均提高了4.3%的准确率,最高可达9.7%。此外,CPO的推理延迟显著低于ToT方法,表明其在效率和效果上的优势。
-
无须额外标注数据
- CPO的一个重要优势是其不依赖于额外的人类标注数据,这使得其在资源受限的环境中尤为有效,能够自我学习并优化推理过程。
论文代码
代码链接:https://github.com/sail-sg/CPO
中文关键词
- 链式思维
- 大型语言模型
- 推理路径
- 偏好优化
- 复杂问题解决
- 事实验证
- 算术推理
Neurlps2024论文合集:
希望这些论文能帮到你!如果觉得有用,记得点赞关注哦~ 后续还会更新更多论文合集!!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)