正大杯攻略|一文搞懂文本分析全流程
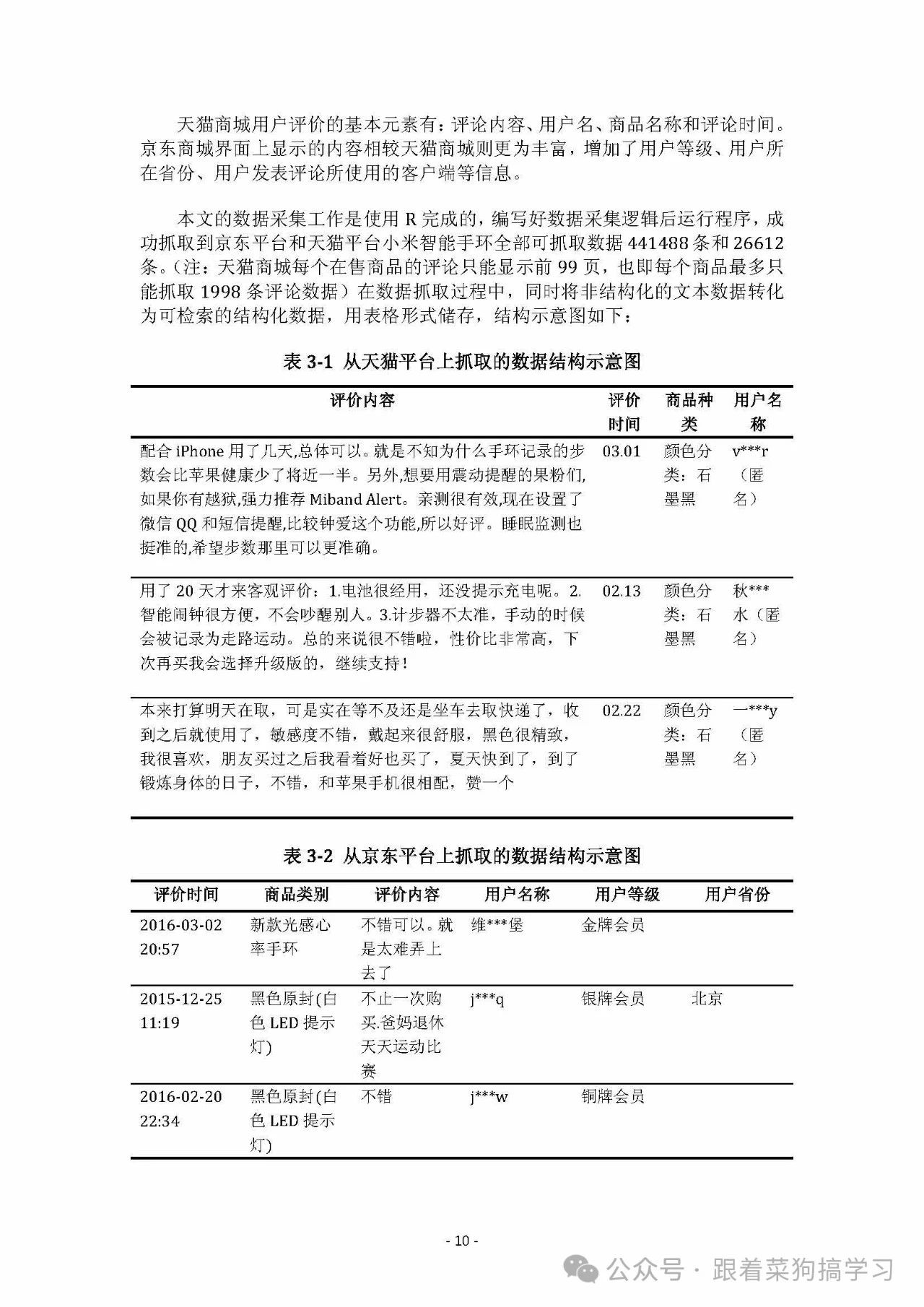
不过要留意,如今大厂普遍设有反爬机制,0 基础新手贸然学习爬虫,可能会在应对反爬问题上耗费大量精力,还未必能顺利获取数据。大家齐心协力,把目标网页上的关键文本复制下来,短时间内就能积累一定量的数据,且无需担忧触犯反爬规则,能稳稳开启项目。先运用 LDA 找出文本主题,再针对各主题分别使用 snownlp 库做情感分析,精准定位各主题情感状况,为产品优化、服务升级指明方向。有了词频数据,词云图可将其
一、数据采集⭐⭐⭐
这是文本分析的起始环节,数据源多样,获取方法各有优劣。
1. Python 爬虫技术(进阶)
对于有编程基础、想高效采集数据的朋友,可以使用Python 爬虫。不过要留意,如今大厂普遍设有反爬机制,0 基础新手贸然学习爬虫,可能会在应对反爬问题上耗费大量精力,还未必能顺利获取数据。
2. 手动复制粘贴(新手友好)
相较而言,组内多人分工手动复制粘贴虽看似笨拙,实则实用。大家齐心协力,把目标网页上的关键文本复制下来,短时间内就能积累一定量的数据,且无需担忧触犯反爬规则,能稳稳开启项目。
二、数据清洗⭐⭐⭐
采集来的数据通常较为杂乱,清洗环节对后续分析质量至关重要。
1. 基础清洗
去除重复数据:相同的数据会产生信息冗余导致后续分析不准,利用 Excel 的“删除重复项”功能或 Python 的相关代码,筛除冗余信息。
无效数据清理:像乱码字符、无意义的符号以及广告推广语都要删除,这些对分析毫无价值,只会造成干扰。
空缺数据处理:若数据集中存在空缺数据,可直接删去对应行;
2. 去停用词及分词(文本预处理关键步)
这一步旨在提取句子主干信息,便于后续深入分析。
去停用词:借助停用词表(常见中文停用词表包含“的”“是”“在”等高频无实质意义的词),去除这些无价值的词,让关键信息显现。
分词:中文文本需分词处理,Python 的 jieba 库作用显著,能将连续句子精准切分成单个词语。
三、词频统计及词云图绘制⭐⭐⭐
1. 词频统计
清洗好的数据蕴含丰富信息,词频统计能帮我们找出重点。利用 Python 编写代码,可统计出每个词语在数据集中的出现频率。
2. 词云图绘制
有了词频数据,词云图可将其可视化。导入词频数据后,高频词以大字体呈现,低频词字体小,能直观展现文本聚焦点,让观众一眼看清热门内容。
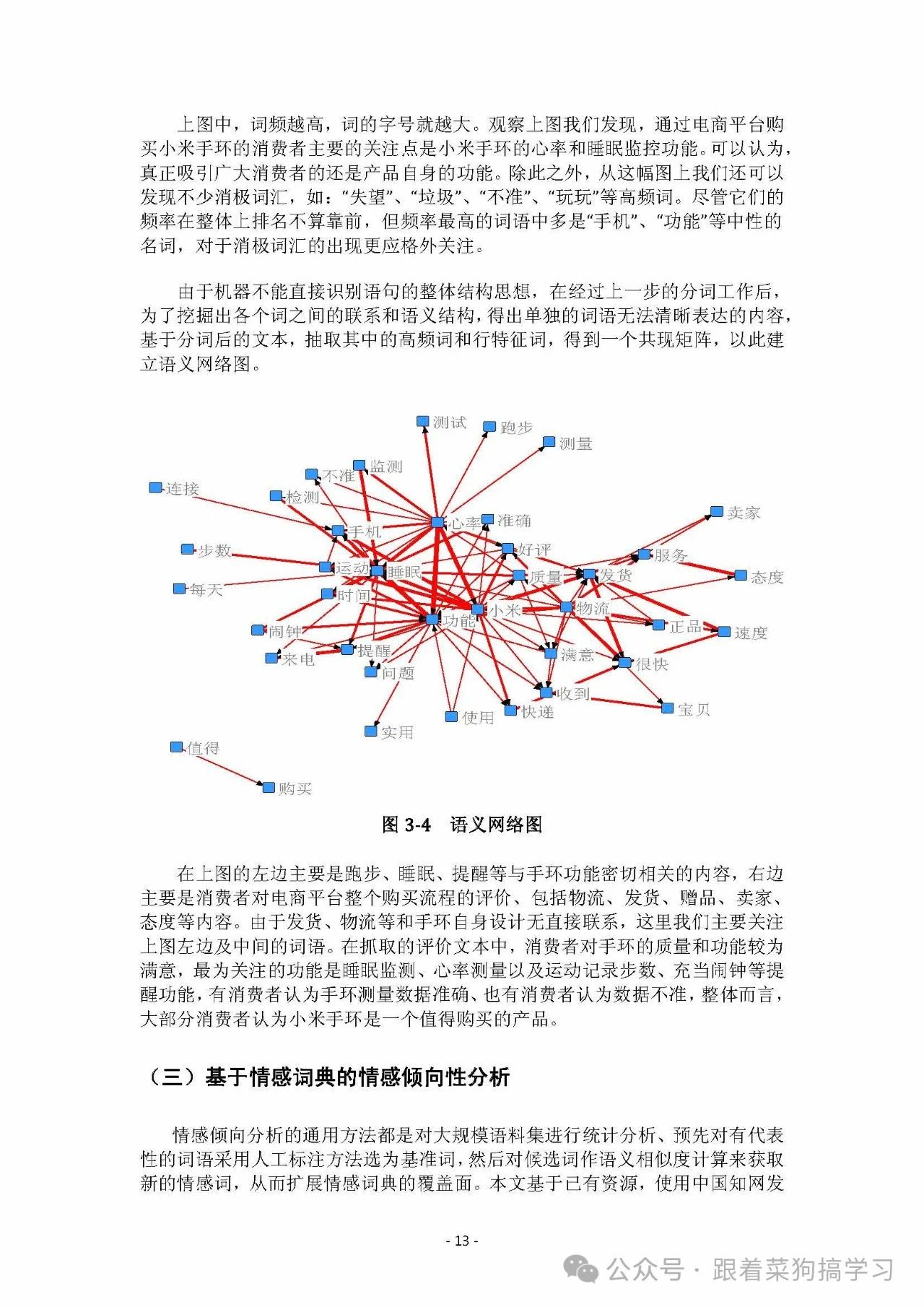
四、共线网络分析⭐⭐
这一步能挖掘词语关联,揭示隐藏语义组合。文本中的词可视为有联系的元素,经常一起出现的词关联紧密。
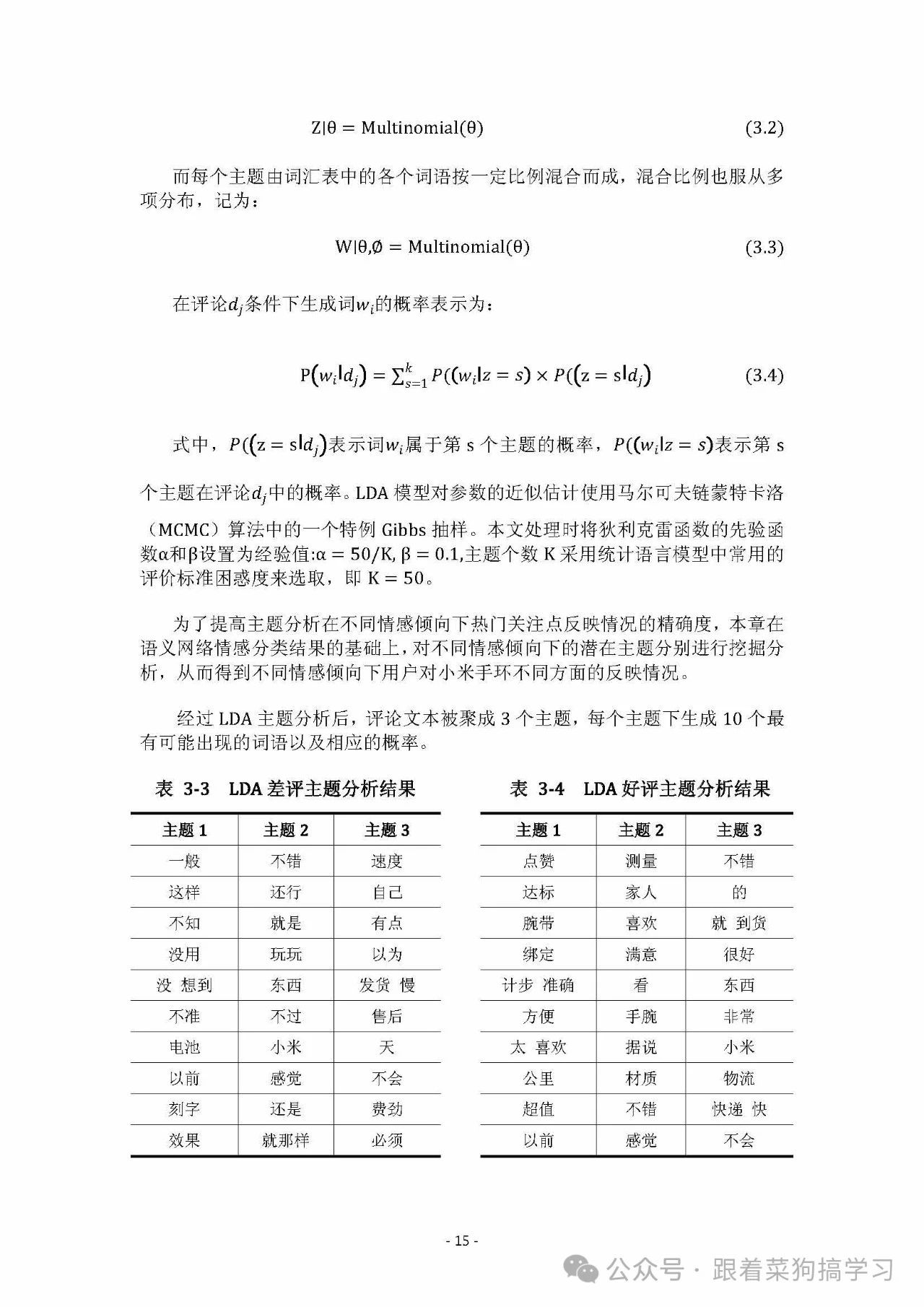
五、LDA 主题分析⭐⭐⭐⭐⭐
LDA 主题分析可自动聚类文本,提取宏观主题分布。
其原理是假设文本由多个潜在主题按一定比例混合而成,通过分析词频、词汇语义等,反向推导出主题构成。
六、情感分析⭐⭐⭐⭐
想了解文本背后的情感倾向,可以直接使用 Python 中的 snownlp 库来进行情感分析,量化情绪极性(积极/中性/消极)。
数值越接近 1 表示情感越积极,越接近 0 表示情感越消极。可手动设置阈值将结果输出为积极;中性;消极三种
七、情感分析与 LDA 主题分析的结合⭐⭐⭐⭐⭐
这是进阶的分析方法,能让结果更深入、具体。
1. 先 LDA 主题分析,后情感分析
先运用 LDA 找出文本主题,再针对各主题分别使用 snownlp 库做情感分析,精准定位各主题情感状况,为产品优化、服务升级指明方向。
2. 先情感分析,后 LDA 主题分析
先使用 snownlp 库将整个数据集依情感划分为积极、中性、消极三类。再对各情感分类分别做 LDA 主题分析,可针对性挖掘不同情感背后原因,为企业改进产品、提升用户满意度提供支撑。
八:国奖案例






火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 36
36 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)