多模态大语言模型综述
本文综述了多模态大型语言模型(MLLMs)的最新进展,探讨了其基本架构、训练策略、评估方法以及面临的挑战和未来研究方向。MLLMs结合了大型语言模型(LLMs)和大型视觉模型(LVMs)的优势,通过模态编码器、预训练LLM和模态接口实现多模态信息的接收、推理和输出。文章强调了MLLMs在细粒度支持、模态支持、语言支持和特定场景应用方面的扩展。同时,指出了MLLMs在处理长上下文信息、遵循复杂指令、
多模态大语言模型综述
摘要 本文综述了多模态大型语言模型(MLLMs)的最新进展,探讨了其基本架构、训练策略、评估方法以及面临的挑战和未来研究方向。MLLMs结合了大型语言模型(LLMs)和大型视觉模型(LVMs)的优势,通过模态编码器、预训练LLM和模态接口实现多模态信息的接收、推理和输出。文章强调了MLLMs在细粒度支持、模态支持、语言支持和特定场景应用方面的扩展。同时,指出了MLLMs在处理长上下文信息、遵循复杂指令、技术改进以及开发具身代理方面的挑战,并强调了模型安全性的重要性。最后,文章总结了MLLMs的研究进展,并对未来的研究方向提出了展望。
关键词 多模态大型语言模型, 大语言模型, 预训练
1 引言
近年来,大语言模型(LLMs)取得了显著的进展[1][2][3]。通过扩大数据规模和模型规模,这些LLMs展现出了非凡的处理问题的能力,通常包括指令遵循[4][5]、上下文学习[6]和思维链[7]。尽管LLMs在大多数自然语言处理任务上表现出了惊人的零样本/少样本推理性能,但它们无法“看见”图像,只能理解离散的文本信息。与此同时,大型视觉模型(LVMs)可以清晰地看懂图像[8][9][10][11],但它通常在推理上落后。
基于这种互补性,LLM和LVM相互借鉴,由此产生了多模态大预言模型(MLLM)的新领域。在概念上,它指的是基于LLM的模型,同时具有接收、推理和输出多模态信息的能力。在MLLM之前,已经有很多致力于多模态的工作,可以分为判别[12][13][14]和生成范式[15][16][17]。CLIP[12]作为前者的代表,将视觉和文本信息投射到一个统一的表示空间中,为下游多模态任务架起了一座桥梁。相比之下,OFA[15]是后者的代表,它以序列到序列的方式统一了多模态任务。MLLM可以根据序列操作被分类为后者,但它展现了两个与以往模型相比的代表性特征:(1)MLLM使用基于数十亿参数规模的LLM,这在以前的模型中是无法做到的。(2)MLLM使用新的训练方式来释放其全部潜力,例如使用多模态指令调整来鼓励模型遵循新指令[18][19]。凭借这两个特征,MLLM展现了新的能力,例如基于图像编写网站代码[20]、理解梗图的深层含义[21]和无需OCR(Optical Character Recognition,光学字符识别)的数学推理[22]。
自从GPT-4[2]发布以来,由于它展示的惊人的多模态能力,MLLM的研究热潮兴起。快速的发展得益于学术界和工业界的共同努力。对MLLM的初步研究集中在基于文本提示和图像、视频、音频的文本内容生成上。随后的工作拓展了模型的能力或使用场景,包括:(1)更好的细粒度支持。开发了对用户提示更精细控制的功能,通过框来支持特定区域,或通过单击支持某个对象。(2)增强的输入和输出模态支持,例如图像、视频、音频和点云。除了输入,像NEXT-GPT[23]这样的项目进一步支持不同模态的输出。(3)改进的语言支持。已经做出了努力,将MLLM的成功扩展到其他语言上,这些语言的训练语料库相对有限。(4)扩展到更多领域和使用场景。一些研究将MLLM的强大能力转移到其他领域,如医学图像理解和文档解析。
2 模型架构
一个典型的多模态大语言模型可以抽象为三个模块:一个与训练的模态编码器、一个预训练的大语言模型,以及连接它们的模态接口。类比于人类,模态编码器如图像/音频编码器就像人的眼睛/耳朵,接收和预处理光学/声学信号,而大语言模型就像人脑,理解和推理处理过的信号。模态接口用于对齐不同的模态。一些MLLM还包括一个生成器,用于输出除文本之外的其他模态。
2.1 模态编码器
编码器将原始信息(如图像或音频)压缩成更紧凑的表示形式。与其从头开始训练,常见的方法是使用一个已经预训练并且与其他模态对其的编码器。例如,CLIP[12]通过在图像-文本对上进行大规模预训练,将视觉编码器与文本语义对齐,因此更容易使用这样的预对齐编码器与LLM通过对齐与训练进行对齐。而后有类似BLIP-2[24]的多模态大语言模型旨在利用已经训练好视觉编码器和大语言模型去做多模态任务,文章的重点在于如何将图像与文本作对齐任务,这样既节省了资源,还取得了很不错的效果。
2.2 预训练LLM
与其从头开始训练一个LLM,更有效和实际的方法是从预训练的LLM开始。通过在网络语料库上进行大规模预训练,LLM已经嵌入了丰富的世界知识,并展现出强大的泛化和推理能力。值得注意的是,大多数LLM都属于因果解码器类别,遵循GPT-3[6]。其中,Flan-T5[25]系列是较早在BLIP-2[24]和InstructBLIP[26]等工作中使用的LLM。LLaMA系列[4][27]、和Vicuna家族[3]是引起学术界广泛关注的代表性开源LLM。由于这两个LLM主要在英语语料库上预训练,所以它们在多语言支持,如中文方面存在局限性。相比之下,Qwen[28]是一个双语LLM,能够很好地支持中文和英文。
需要注意的是,与增加输入分辨率的情况类似,扩大LLM的参数规模也会带来额外的提升。具体来说,Liu等人[29][30]发现,简单地将LLM从7B扩大到13B就能在各种基准测试上带来全面的提升。此外,当使用34B LLM时,即使在训练期间仅使用英语多模态数据,模型也显示出了零样本中文能力。Lu等人[31]通过将LLM从13B扩大到35B和65B/70B,发现更大的模型规模在专门为MLLM设计的基准测试上带来了一致的提升。还有一些工作使用较小的LLM以便于在移动设备上部署。例如,MobileVLM系列[32][33]使用缩小版的LLaMA(称为MobileLLaMA 1.4B/2.7B),实现在移动处理器上的高效推理。
最近,对LLM的Mixture of Experts(MoE)架构的探索引起了越来越多的关注。与密集模型相比,稀疏架构在不增加计算成本的情况下,通过选择性激活参数,实现了总参数规模的扩大。实证上,MM1[34]和MoE-LlaVA[35]发现MoE实现在几乎所有基准测试上都比密集对应物表现更好。
2.3 模态交互
由于LLM只能感知文本,因此有必要搭建自然语言与其他模态之间的桥梁。然而,以端到端的方式训练一个大型多模态模型成本较高。更实际的方法是在预训练的视觉编码器和LLM之间引入一个可学习的连接器。另一种方法是利用专家模型,如图像描述模型,将图像翻译成语言,然后将语言发送给LLM。
Learnable Connector(可学习的连接器),负责桥接不同模态之间的差距。具体来说,该模块将信息投影到LLM能够高效理解的空间中。根据多模态信息如何融合,大致有两种实现这种接口的方式,即 token-level 和 feature-level 融合。
对于 token-level 融合,编码器输出的特征被转换为 tokens,并与文本 tokens 连接后一起送入 LLM。一个常见且可行的解决方案是利用一组可学习的查询 tokens 以查询方式提取信息,这首先在 BLIP-2[24]中实现,并随后被多种工作继承。这种 Q-Former 风格的方法是将视觉 tokens 压缩成较少数量的表示向量。相比之下,一些方法简单地使用基于 MLP 的接口来桥接模态差距。例如,LLaVA系列采用一个/两个线性 MLP[19][29]来投影视觉 tokens,并将特征维度与词嵌入对齐。
在相关方面,MM1[34]对连接器的设计选择进行了消融研究,发现对于 token-level 融合,模态适配器的类型远不如视觉 tokens 的数量和输入分辨率重要。尽管如此,Zeng等人[36]比较了 token 和 feature-level 融合的性能,并实证揭示了 token-level 融合变体在 VQA 基准测试中的性能更好。关于性能差距,作者建议交叉注意力模型可能需要更复杂的超参数搜索过程才能达到可比的性能。作为另一条线,feature-level 融合插入额外的模块,使文本特征和视觉特征之间能够进行深入的交互和融合。例如,Flamingo[37]在 LLM 的冻结 Transformer 层之间插入额外的交叉注意力层,从而通过外部视觉提示增强语言特征。类似地,CogVLM[38]在每个 Transformer 层中插入视觉专家模块,以实现视觉和语言特征之间的双重交互和融合。为了获得更好的性能,引入模块的 QKV 权重矩阵是从预训练的 LLM 初始化的。同样,LLaMA-Adapter[39]在 Transformer 层中引入可学习的提示。这些提示首先嵌入视觉知识,然后作为前缀与文本特征连接。
在参数规模方面,可学习的接口通常只占编码器和 LLM 的一小部分。以 Qwen-VL[40]为例,Q-Former 的参数规模约为 0.08B,占整个参数的不到 1%,而编码器和 LLM 分别占约 19.8%(1.9B)和 80.2%(7.7B)。
3 训练策略和数据集
一个完整的多模态大型语言模型(MLLM)的训练包括三个阶段:预训练、指令调整和对齐调整。每个训练阶段都需要不同类型的数据,并实现不同的目标。在本节中,我们讨论训练目标,以及每个训练阶段的数据收集和特点。
3.1 预训练
3.1.1 训练细节
作为第一个训练阶段,预训练主要旨在对齐不同模态并学习多模态世界知识。预训练阶段通常涉及大规模的文本配对数据,例如标题数据。通常情况下,这些标题对描述图像/音频/视频以自然语言句子的形式。这里,我们考虑一个常见的场景,即MLLM被训练以对齐视觉与文本。预训练的一个常见方法是保持预训练模块(例如视觉编码器和LLM)冻结,并训练一个可学习的接口[19]。这个想法是在不丢失预训练知识的情况下对齐不同的模态。一些方法[40]也解冻了更多的模块(例如视觉编码器),以使更多的可训练参数用于对齐。需要注意的是,训练方案与数据质量密切相关。对于简短且嘈杂的标题数据,可以采用较低的分辨率(例如224)以加快训练过程,而对于更长和更干净的数据,则最好利用更高的分辨率(例如448或更高)以减少幻觉。此外,ShareGPT4V[41]发现,在预训练阶段使用高质量的标题数据时,解锁视觉编码器有助于更好的对齐。
3.1.2 数据集
预训练数据主要服务于两个目的,即(1)对齐不同模态和(2)提供世界知识。根据粒度,预训练语料库可以分为粗粒度和细粒度数据,我们将依次介绍。我们在表1中总结
了常用的预训练数据集。
粗粒度标题数据有一些共同的特点:(1)数据量很大,因为样本通常来源于互联网。(2)由于网络爬取的特性,标题通常简短且嘈杂,因为它们源自网络图像的alt-text。这些数据可以通过自动工具进行清洗和过滤,例如,使用CLIP[12]模型过滤掉图像-文本对的相似度低于预定义阈值的样本。
表1 常用于预训练的数据集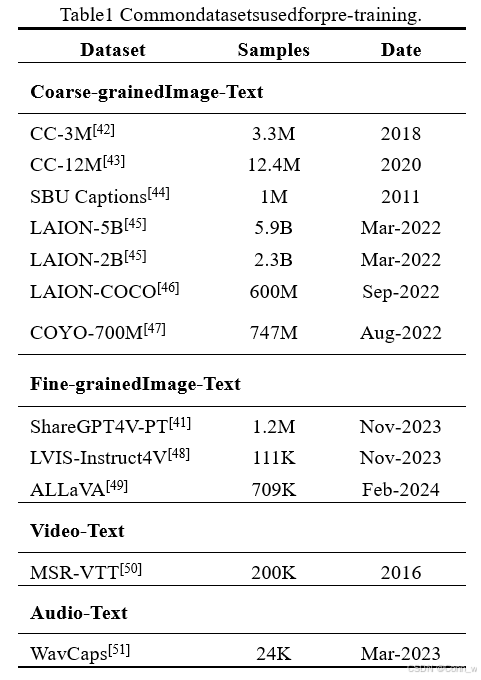
最近,更多工作[41][48][49]探索了通过提示强大的MLLM(例如GPT-4V)生成高质量的细粒度数据。与粗粒度数据相比,这些数据通常包含更长、更准确的图像描述,从而实现更细粒度的图像和文本模态之间的对齐。然而,由于这种方法通常需要调用商业使用的MLLM,成本较高,数据量相对较小。值得注意的是,ShareGPT4V[41]通过首先使用GPT-4V生成的100K数据进行训练,然后在预训练的标题生成器的基础上将数据量扩展到1.2M,达到了平衡。
3.2 指令调整
3.2.1 引言
指令调整是指对模型进行调整,使其更好地理解用户的指令并完成所需任务。通过这种方式调整,LLM能够通过遵循新指令泛化到未见任务,从而提高零样本性能。这种简单而有效的想法激发了后续NLP工作的成功率,如ChatGPT[2]、InstructGPT[52]、FLAN[18]和OPT-IML[53]。监督式微调方法通常需要大量的任务特定数据来训练任务特定模型。提示方法减少了对大规模数据的依赖,并通过提示工程完成特定任务。在这种情况下,尽管少样本性能得到了改善,但零样本性能仍然相当平均[6]。不同地,指令调整学习如何泛化到未见任务,而不是像另外两个对应物那样拟合特定任务。此外,指令调整与多任务提示高度相关。在本节中,我们描述指令样本的格式、训练目标、收集指令数据的典型方式以及相应的常用数据集。
3.2.2 训练细节
多模态指令样本通常包括一个可选的指令和一个输入-输出对。指令通常是描述任务的自然语言句子,例如,“详细描述图像”。输入可以是像VQA任务那样的图像-文本对,或者只是图像,如图像标题任务。输出是指令条件下输入的答案。指令模板是灵活的,可以根据手动设计进行调整注意,指令模板也可以推广到多轮对话的情况[19]。
正式地,一个多模态指令样本可以用三元组形式表示,即(I, M, R),其中I、M、R分别代表指令、多模态输入和真实响应。MLLM根据指令和多模态输入预测答案:
这里, 表示预测的答案, 是模型的参数。训练目标通常是用于训练LLM的原始自回归目标,基于此,MLLM被鼓励预测响应的下一个token。目标可以表示为:
其中N是真实响应的长度。
4 评估
评估是开发多模态大型语言模型(MLLMs)的一个重要组成部分,因为它提供了模型优化的反馈,并有助于比较不同模型的性能。与传统多模态模型的评估方法相比,MLLMs的评估显示出几个新特征:(1)由于MLLMs通常具有通用性,因此对MLLMs进行全面评估很重要。(2)MLLMs展现出许多紧急能力,需要特别关注(例如,无需OCR的数学推理),因此需要新的评估方案。MLLMs的评估可以分为两类,即封闭集和开放集。
4.1 封闭集
封闭集问题是指可能的答案选项是预定义的,并且限制在有限的集合中的问题。评估通常在特定任务的数据集上进行。在这种情况下,响应可以通过基准指标自然地进行评判。例如,InstructBLIP[26]报告了在ScienceQA[54]上的准确率,以及在NoCaps[56]和Flickr30K[57]上的CIDEr分数[55]。评估设置通常是零样本或微调。第一种设置通常选择涵盖不同通用任务的广泛数据集,并将它们分成保留和非保留数据集。在前者上调整后,在后者上评估零样本性能,这些数据集或任务是未见过的。相比之下,第二种设置通常在评估特定领域的任务时观察到。例如,LlaVA[19]和LLaMA-Adapter[39]在ScienceQA[54]上报告了微调性能。LLaVA-Med[58]在生物医学VQA上报告结果。上述评估方法通常限于少数选定的任务或数据集,缺乏全面的定量比较。为此,一些努力已经开发了专门针对MLLMs的新基准。例如,Fu等人[59]构建了一个全面的评估基准MME,包括总共14个感知和认知任务。MME中的所有指令-答案对都是手动设计的,以避免数据泄露。
4.2 开放集
与封闭集问题相比,开放集问题的回答可以更加灵活,MLLMs通常扮演聊天机器人的角色。由于聊天内容可以是任意的,因此比封闭答案的输出更难评判。评判标准可以分为手动评分、GPT评分和案例研究。手动评分需要人类评估生成的响应。这种方法通常涉及为评估特定维度而设计的问题。例如,mPLUG-Owl[60]收集了一个与视觉相关的评估集,以评判自然图像理解、图表和流程图理解等能力。同样,GPT4Tools[61]构建了两个集合,分别用于微调和零样本性能,并评估响应的思想、行动、论点和整体。由于手动评估工作量很大,一些研究人员探索了使用GPT进行评分,即GPT评分。这种方法通常用于评估多模态对话的性能。LlaVA[19]提出通过文本GPT-4对响应进行评分,评分方面包括有用性和准确性。具体来说,从COCO验证集中抽取了30个图像,每个图像都与一个简短的问题、一个详细的问题和一个复杂推理问题相关联,通过在GPT-4上进行自我指令。模型和GPT-4生成的答案被发送给GPT-4进行比较。随后的工作遵循这个想法,并提示ChatGPT或GPT-4对结果进行评分或判断哪一个更好。应用文本GPT-4作为评估器的一个主要问题是,评估器仅基于与图像相关的文本内容,例如标题或边界框坐标,而没有访问图像。因此,在这种情况下,将GPT-4设置为性能上限可能是有问题的。随着GPT视觉接口的发布,一些工作利用更先进的GPT-4V模型评估MLLMs的性能。例如,Woodpecker[62]采用GPT-4V根据图像评估模型答案的质量。预计这种评估比使用文本GPT-4更准确,因为GPT-4V可以直接访问图像。另一种补充方法是通过案例研究比较MLLMs的不同能力。例如,一些研究评估了两个典型的商业使用模型,GPT-4V和Gemini。Wen等人[63]对GPT-4V进行了更集中的评估,设计了针对自动驾驶场景的样本。Fu等人[59]对Gemini-Pro进行了全面评估,将模型与GPT-4V进行了比较。结果表明,尽管GPT-4V和Gemini在响应风格上有所不同,但它们在视觉推理能力上表现出了相当的水平。
5 扩展
近期的研究在扩展多模态大型语言模型(MLLMs)的能力方面取得了显著进展,涵盖了从更强大的基础能力到更广泛的应用场景。本文概述了MLLMs在这方面的主要发展。
粒度支持。为了促进代理与用户之间的更好交互,研究人员开发了能够更精细控制输入和输出粒度的MLLMs。在输入方面,模型逐渐发展以支持从图像到区域甚至像素的更精细控制。例如,Shikra[64]支持区域级输入和理解,使用户能够通过自然语言形式的边界框更灵活地与助手交互。Ferret[65]进一步支持更灵活的引用,设计了混合表示方案。该模型支持不同形式的提示,包括点、框和草图。同样,Osprey[66]支持通过使用分割模型[8]的点输入,使用户能够通过单击指定单个实体或其部分。在输出方面,随着输入支持的发展,定位能力也得到了提升。Shikra[64]支持以边界框注释的形式对图像进行响应,从而实现更高的精度和更精细的引用体验。
模态支持。增加对模态的支持是MLLM研究的一个趋势。一方面,研究人员探索了使MLLM适应支持更多模态内容的输入,如3D点云。另一方面,MLLM也被扩展为生成更多模态的响应,如图像、音频、和视频。例如,NExT-GPT[23]提出了一个框架,支持输入和输出混合模态,特别是文本、图像、音频和视频的组合,借助附加到MLLM的扩散模型。该框架采用编码器-解码器架构,并将LLM作为理解和推理的中心。
语言支持。当前模型主要是单语的,可能是因为高质量的非英语训练语料库稀缺。一些工作致力于开发多语言模型,以便覆盖更广泛的用户群体。具体来说,该方案以英语作为关键语言,拥有丰富的训练语料库。利用预训练的双语LLM,通过在指令调整期间添加一些翻译样本,将多模态能力转移到中文。采用类似方法,Qwen-VL[28]从双语LLM Qwen[40]开发而来,支持中文和英文。在预训练期间,将中文数据混合到训练语料库中,以保持模型的双语能力,占整个数据量的22.7%。
场景/任务扩展。除了开发常见的通用助手外,一些研究专注于更具体的应用场景,其中需要考虑实际条件,而其他研究则将MLLM扩展到具有特定专业知识的下游任务。
一个典型的趋势是将MLLM适应于更具体的现实生活场景。MobileVLM[32]探索了为资源受限场景开发MLLM的小尺寸变体。一些设计和技术被用于在移动设备上部署,如更小尺寸的LLM和量化技术以加速计算。其他工作开发了与现实世界互动的代理,例如为图形用户界面(GUI)特别设计的 用户友好助手,如CogAgent。这些助手擅长规划和指导完成用户指定的任务的每个步骤,作为人机交互的有用代理。另一条线是为解决不同领域任务增强MLLM的特定技能,例如文档理解和医疗领域。对于文档理解,mPLUG-DocOwl[67]利用各种形式的文档级数据进行调整,从而增强了模型在无需OCR的文档理解方面的能力。TextMonkey[68]结合了与文档理解相关的多个任务,以提高模型性能。除了传统的文档图像和场景文本数据集外,还添加了与位置相关的任务,以减少幻觉并帮助模型学习定位响应在视觉信息中。MLLM也可以通过注入医学领域的知识扩展到医疗领域。例如,LLaVA-Med[58]将医学知识注入普通的LLaVA[19],开发了专门用于医学图像理解和问答的助手。
6 挑战和未来研究方向
多模态大型语言模型(MLLMs)的发展仍处于初级阶段,因此有很大的改进空间,本文总结如下:
当前MLLMs在处理长上下文的多模态信息方面存在限制。这限制了具有更多多模态token的高级模型的发展,例如长视频理解以及图像和文本交错的长文档。
MLLMs应该升级以遵循更复杂的指令。例如,生成高质量的问题-答案对数据的主流方法仍然是提示封闭源GPT-4V,因为其先进的指令遵循能力,而其他模型通常无法实现。
在多模态图像对比学习和多模态思维链等技术方面仍有改进空间。当前对这两种技术的研究还处于初级阶段,MLLMs的相关能力较弱。因此,探索其背后的机制和潜在改进是有前景的。
开发基于MLLMs的具身代理是一个热门话题。开发能够与真实世界互动的此类代理将具有意义。这类努力需要模型具备关键能力,包括感知、推理、规划和执行。
安全问题。与LLMs类似,MLLMs可能容易受到精心策划的攻击的影响。换句话说,MLLMs可能会被误导以输出有偏见或不期望的响应。因此,提高模型安全性将是一个重要的课题。
7 结论
在这篇综述中,我对现有的多模态大语言模型文献进行了调查,并提供了其主要方向的广泛视角,包括基本原理和相关扩展。此外,强调了当前研究中需要填补的差距,并指出了一些有前景的研究方向。希望这篇综述能为读者提供多模态大语言模型当前进展的清晰图景,并激发自己完成更多的工作。
References
1 W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y. Hou, Y. Min, B. Zhang, J. Zhang, Z. Dong et al., “A survey of large language models,” arXiv preprint arXiv:2303.18223, 2023.
2 OpenAI, “Chatgpt: A language model for conversational ai,” OpenAI, Tech. Rep., 2023. [Online]. Available: https: //www.openai.com/research/chatgpt
3 W.-L. Chiang, Z. Li, Z. Lin, Y. Sheng, Z. Wu, H. Zhang, L. Zheng,S. Zhuang, Y. Zhuang, J. E. Gonzalez et al., “Vicuna: An open-source chatbot impressing gpt-4 with 90% chatgpt quality,”2023. [Online]. Available:https://vicuna.lmsys.org
4 H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux,T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar et al.,“Llama: Open and efficient foundation language models,” arXiv preprint arXiv:2302.13971, 2023.
5 B. Peng, C. Li, P. He, M. Galley, and J. Gao, “Instruction tuning with gpt-4,” arXiv preprint arXiv:2304.03277, 2023.
6 T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal,A. Neelakantan, P. Shyam, G. Sastry, A. Askell et al., “Language models are few-shot learners,” NeurIPS, 2020.
7 J. Wei, X. Wang, D. Schuurmans, M. Bosma, E. Chi, Q. Le, and D. Zhou, “Chain of thought prompting elicits reasoning in large language models,” arXiv preprint arXiv:2201.11903, 2022.
8 A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson,T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo et al., “Segment anything,” arXiv preprint arXiv:2304.02643, 2023.
9 Y. Shen, C. Fu, P. Chen, M. Zhang, K. Li, X. Sun, Y. Wu, S. Lin,and R. Ji, “Aligning and prompting everything all at once for universal visual perception,” in CVPR, 2024.
10 H. Zhang, F. Li, S. Liu, L. Zhang, H. Su, J. Zhu, L. M. Ni, and H.-Y. Shum, “Dino: Detr with improved denoising anchor boxes for end-to-end object detection,” arXiv preprint arXiv:2203.03605, 2022.
11 M. Oquab, T. Darcet, T. Moutakanni, H. Vo, M. Szafraniec,V. Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby et al.,“Dinov2: Learning robust visual features without supervision,” arXiv preprint arXiv:2304.07193, 2023.
12 A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal,G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,”in ICML, 2021.
13 J. Li, R. Selvaraju, A. Gotmare, S. Joty, C. Xiong, and S. C. H. Hoi,“Align before fuse: Vision and language representation learning with momentum distillation,” NeurIPS, 2021.
14 Y.-C. Chen, L. Li, L. Yu, A. El Kholy, F. Ahmed, Z. Gan, Y. Cheng, and J. Liu, “Uniter: Universal image-text representation learning,”in ECCV, 2020.
15 P. Wang, A. Yang, R. Men, J. Lin, S. Bai, Z. Li, J. Ma, C. Zhou,J. Zhou, and H. Yang, “Ofa: Unifying architectures, tasks,and modalities through a simple sequence-to-sequence learning framework,” in ICML, 2022.
16 J. Cho, J. Lei, H. Tan, and M. Bansal, “Unifying vision-and language tasks via text generation,” in ICML, 2021.
17 Z. Wang, J. Yu, A. W. Yu, Z. Dai, Y. Tsvetkov, and Y. Cao,“Simvlm: Simple visual language model pretraining with weak supervision,” arXiv preprint arXiv:2108.10904, 2021.
18 J. Wei, M. Bosma, V. Y. Zhao, K. Guu, A. W. Yu, B. Lester, N. Du,A. M. Dai, and Q. V. Le, “Finetuned language models are zeroshot learners,” arXiv preprint arXiv:2109.01652, 2021.
19 H. Liu, C. Li, Q. Wu, and Y. J. Lee, “Visual instruction tuning,” arXiv preprint arXiv:2304.08485, 2023.
20 D. Zhu, J. Chen, X. Shen, X. Li, and M. Elhoseiny, “Minigpt-4:Enhancing vision-language understanding with advanced large language models,” arXiv preprint arXiv:2304.10592, 2023.
21 Z. Yang, L. Li, J. Wang, K. Lin, E. Azarnasab, F. Ahmed, Z. Liu,C. Liu, M. Zeng, and L. Wang, “Mm-react: Prompting chatgpt for multimodal reasoning and action,” arXiv preprint arXiv:2303.11381, 2023.
22 D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter,A. Wahid, J. Tompson, Q. Vuong, T. Yu et al., “Palm-e: An embodied multimodal language model,” arXiv preprint arXiv:2303.03378, 2023.
23 S.Wu, H. Fei, L. Qu,W. Ji, and T.-S. Chua, “Next-gpt: Any-to-any multimodal llm,” arXiv preprint arXiv:2309.05519, 2023.
24 J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,” arXiv preprint arXiv:2301.12597, 2023.
25 H.W. Chung, L. Hou, S. Longpre, B. Zoph, Y. Tay,W. Fedus, E. Li,X. Wang, M. Dehghani, S. Brahma et al., “Scaling instruction-finetuned language models,” arXiv preprint arXiv:2210.11416, 2022.
26 W. Dai, J. Li, D. Li, A. M. H. Tiong, J. Zhao, W. Wang,B. Li, P. Fung, and S. Hoi, “Instructblip: Towards generalpurpose vision-language models with instruction tuning,” arXiv preprint arXiv:2305.06500, 2023.
27 H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi,Y. Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale et al., “Llama 2: Open foundation and fine-tuned chat models,” arXiv preprint arXiv:2307.09288, 2023.
28 J. Bai, S. Bai, Y. Chu, Z. Cui, K. Dang, X. Deng, Y. Fan,W. Ge, Y. Han, F. Huang et al., “Qwen technical report,” arXiv preprint arXiv:2309.16609, 2023.
29 H. Liu, C. Li, Y. Li, and Y. J. Lee, “Improved baselines with visual instruction tuning,” arXiv preprint arXiv:2310.03744, 2023.
30 H. Liu, C. Li, Y. Li, B. Li, Y. Zhang, S. Shen, and Y. J. Lee,“Llava-next: Improved reasoning, ocr, and world knowledge,”January 2024. [Online]. Available: https://llava-vl.github.io/blog/2024-01-30-llava-next/
31 Y. Lu, C. Li, H. Liu, J. Yang, J. Gao, and Y. Shen, “An empirical study of scaling instruct-tuned large multimodal models,” arXiv preprint arXiv:2309.09958, 2023.
32 X. Chu, L. Qiao, X. Lin, S. Xu, Y. Yang, Y. Hu, F. Wei,X. Zhang, B. Zhang, X. Wei et al., “Mobilevlm: A fast, reproducibleand strong vision language assistant for mobile devices,” arXiv preprint arXiv:2312.16886, 2023.
33 X. Chu, L. Qiao, X. Zhang, S. Xu, F. Wei, Y. Yang, X. Sun,Y. Hu, X. Lin, B. Zhang et al., “Mobilevlm v2: Faster and stronger baseline for vision language model,” arXiv preprint arXiv:2402.03766, 2024.
34 B. McKinzie, Z. Gan, J.-P. Fauconnier, S. Dodge, B. Zhang,P. Dufter, D. Shah, X. Du, F. Peng, F. Weers et al., “Mm1:Methods, analysis & insights from multimodal llm pre-training,” arXiv preprint arXiv:2403.09611, 2024.
35 B. Lin, Z. Tang, Y. Ye, J. Cui, B. Zhu, P. Jin, J. Zhang, M. Ning, and L. Yuan, “Moe-llava: Mixture of experts for large vision-language models,” arXiv preprint arXiv:2401.15947, 2024.
36 Y. Zeng, H. Zhang, J. Zheng, J. Xia, G. Wei, Y. Wei, Y. Zhang, and T. Kong, “What matters in training a gpt4-style language model with multimodal inputs?” arXiv preprint arXiv:2307.02469, 2023.
37 J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y. Hasson,K. Lenc, A. Mensch, K. Millican, M. Reynolds et al., “Flamingo: a visual language model for few-shot learning,” NeurIPS, 2022.
38 W. Wang, Q. Lv, W. Yu, W. Hong, J. Qi, Y. Wang, J. Ji, Z. Yang,L. Zhao, X. Song et al., “Cogvlm: Visual expert for pretrained language models,” arXiv preprint arXiv:2311.03079, 2023.
39 R. Zhang, J. Han, A. Zhou, X. Hu, S. Yan, P. Lu, H. Li, P. Gao,and Y. Qiao, “Llama-adapter: Efficient fine-tuning of language models with zero-init attention,” arXiv preprint arXiv:2303.16199, 2023.
40 J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou,and J. Zhou, “Qwen-vl: A frontier large vision-language model with versatile abilities,” arXiv preprint arXiv:2308.12966, 2023.
41 L. Chen, J. Li, X. Dong, P. Zhang, C. He, J. Wang, F. Zhao, and D. Lin, “Sharegpt4v: Improving large multi-modal models with better captions,” arXiv preprint arXiv:2311.12793, 2023.
42 P. Sharma, N. Ding, S. Goodman, and R. Soricut, “Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning,” in ACL, 2018.
43 S. Changpinyo, P. Sharma, N. Ding, and R. Soricut, “Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts,” in CVPR, 2021.
44 V. Ordonez, G. Kulkarni, and T. Berg, “Im2text: Describing images using 1 million captioned photographs,” NeurIPS, 2011.
45 C. Schuhmann, R. Beaumont, R. Vencu, C. Gordon, R.Wightman,M. Cherti, T. Coombes, A. Katta, C. Mullis, M. Wortsman et al.,“Laion-5b: An open large-scale dataset for training next generation image-text models,” NeurIPS, 2022.
46 C. Schuhmann, A. Köpf, R. Vencu, T. Coombes, and R. Beaumont,“Laion coco: 600m synthetic captions from laion2b-en.”https://laion.ai/blog/laion-coco/, 2022.
47 M. Byeon, B. Park, H. Kim, S. Lee, W. Baek, and S. Kim,“Coyo-700m: Image-text pair dataset,” https://github.com/kakaobrain/coyo-dataset, 2022.
48 J. Wang, L. Meng, Z. Weng, B. He, Z. Wu, and Y.-G. Jiang, “To see is to believe: Prompting gpt-4v for better visual instruction tuning,” arXiv preprint arXiv:2311.07574, 2023.
49 G. H. Chen, S. Chen, R. Zhang, J. Chen, X. Wu, Z. Zhang,Z. Chen, J. Li, X. Wan, and B. Wang, “Allava: Harnessing gpt4v-synthesized data for a lite vision-language model,” arXiv preprint arXiv:2402.11684, 2024.
50 J. Xu, T. Mei, T. Yao, and Y. Rui, “Msr-vtt: A large video description dataset for bridging video and language,” in CVPR, 2016.
51 X. Mei, C. Meng, H. Liu, Q. Kong, T. Ko, C. Zhao, M. D. Plumbley,Y. Zou, and W. Wang, “Wavcaps: A chatgpt-assisted weaklylabelled audio captioning dataset for audio-language multimodal research,” arXiv preprint arXiv:2303.17395, 2023.
52 L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray et al.,“Training language models to follow instructions with human feedback,” NeurIPS, 2022.
53 S. Iyer, X. V. Lin, R. Pasunuru, T. Mihaylov, D. Simig, P. Yu,K. Shuster, T. Wang, Q. Liu, P. S. Koura et al., “Opt-iml: Scaling language model instruction meta learning through the lens of generalization,” arXiv preprint arXiv:2212.12017, 2022.
54 P. Lu, S. Mishra, T. Xia, L. Qiu, K.-W. Chang, S.-C. Zhu, O. Tafjord, P. Clark, and A. Kalyan, “Learn to explain: Multimodal reasoning via thought chains for science question answering,” NeurIPS,2022.
55 R. Vedantam, C. Lawrence Zitnick, and D. Parikh, “Cider:Consensus-based image description evaluation,” in CVPR, 2015.
56 H. Agrawal, K. Desai, Y. Wang, X. Chen, R. Jain, M. Johnson, D. Batra, D. Parikh, S. Lee, and P. Anderson, “Nocaps: Novelobject captioning at scale,” in ICCV, 2019.
57 P. Young, A. Lai, M. Hodosh, and J. Hockenmaier, “From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions,” TACL, 2014.
58 C. Li, C. Wong, S. Zhang, N. Usuyama, H. Liu, J. Yang, T. Naumann, H. Poon, and J. Gao, “Llava-med: Training a large language-and-vision assistant for biomedicine in one day,” arXiv preprint arXiv:2306.00890, 2023.
59 C. Fu, P. Chen, Y. Shen, Y. Qin, M. Zhang, X. Lin, Z. Qiu, W. Lin, Z. Qiu, W. Lin et al., “Mme: A comprehensive evaluation benchmarkfor multimodal large language models,” arXiv preprint arXiv:2306.13394,2023.
60 Q. Ye, H. Xu, G. Xu, J. Ye, M. Yan, Y. Zhou, J. Wang, A. Hu, P. Shi, Y. Shi et al., “mplug-owl: Modularization empowers large language models with multimodality,” arXiv preprint arXiv:2304.14178, 2023.
61 R. Yang, L. Song, Y. Li, S. Zhao, Y. Ge, X. Li, and Y. Shan,“Gpt4tools: Teaching large language model to use tools via selfinstruction,” arXiv preprint arXiv:2305.18752, 2023. 7
62 S. Yin, C. Fu, S. Zhao, T. Xu, H. Wang, D. Sui, Y. Shen, K. Li, X. Sun, and E. Chen, “Woodpecker: Hallucination correction for multimodal large language models,” arXiv preprint arXiv:2310.16045, 2023.
63 L. Wen, X. Yang, D. Fu, X. Wang, P. Cai, X. Li, T. Ma, Y. Li, L. Xu, D. Shang et al., “On the road with gpt-4v (ision): Early explorations of visual-language model on autonomous driving,” arXiv preprint arXiv:2311.05332.
64 K. Chen, Z. Zhang, W. Zeng, R. Zhang, F. Zhu, and R. Zhao,“Shikra: Unleashing multimodal llm’s referential dialoguemagic,” arXiv preprint arXiv:2306.15195.
65 H. You, H. Zhang, Z. Gan, X. Du, B. Zhang, Z. Wang, L. Cao, S.-F. Chang, and Y. Yang, “Ferret: Refer and ground anything anywhere at any granularity,” arXiv preprint arXiv:2310.07704, 2023.
66 Y. Yuan, W. Li, J. Liu, D. Tang, X. Luo, C. Qin, L. Zhang, and J. Zhu, “Osprey: Pixel understanding with visual instruction tuning,” arXiv preprint arXiv:2312.10032.
67 J. Ye, A. Hu, H. Xu, Q. Ye, M. Yan, Y. Dan, C. Zhao, G. Xu, C. Li, J. Tian et al., “mplug-docowl: Modularized multimodal large language model for document understanding,” arXiv preprint arXiv:2307.02499,2023.
68 Y. Liu, B. Yang, Q. Liu, Z. Li, Z. Ma, S. Zhang, and X. Bai,“Textmonkey: An ocr-free large multimodal model for understanding document,” arXiv preprint arXiv:2403.04473, 2024.

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)