基于langgraph的自监督提示词优化简单实现——Self‑Supervised Prompt Optimization (SPO) base-on langgraph
MetaGPT 项目中的SPO🔗(Self-Supervised Prompt Optimization,自监督提示优化)模块旨在自动优化大型语言模型的提示词。它通过让模型自我评估并改进提示,在无需人工标注数据或外部知识的情况下提升输出质量。SPO 引入了一个“三阶段循环”的机制,即执行 (Execute) – 评估 (Evaluate) – 优化 (Optimize),使提示词逐步逼近最优方案
介绍
MetaGPT 项目中的 SPO🔗(Self-Supervised Prompt Optimization,自监督提示优化)模块旨在自动优化大型语言模型的提示词。它通过让模型自我评估并改进提示,在无需人工标注数据或外部知识的情况下提升输出质量。
SPO 引入了一个“三阶段循环”的机制,即执行 (Execute) – 评估 (Evaluate) – 优化 (Optimize),使提示词逐步逼近最优方案。在执行阶段,给定当前的提示词,模型生成回答;评估阶段,模型对不同提示词下的回答进行成对比较打分;优化阶段,模型根据评估结果自我改写提示。如此循环迭代,实现提示的自我改进。这一模块不局限于特定领域任务(如信息抽取或知识图谱构建),而是通用于任何需要优化提示词的场景,支持封闭性问答任务和开放式创作任务。由于采用了自监督方法,SPO 不需要人工反馈或标准答案即可运行,同时通过模型自身的判断力来指导优化,显著降低了优化成本。据官方介绍,SPO 在达到同等效果的情况下,成本仅为传统方法的1.1%–5.6%,效率提高了约17.8到90倍。总之,SPO 模块的核心用途在于利用大模型最懂自己的原理**,自动调整提示以提升任务性能,为提示工程提供高效、低成本的解决方案。
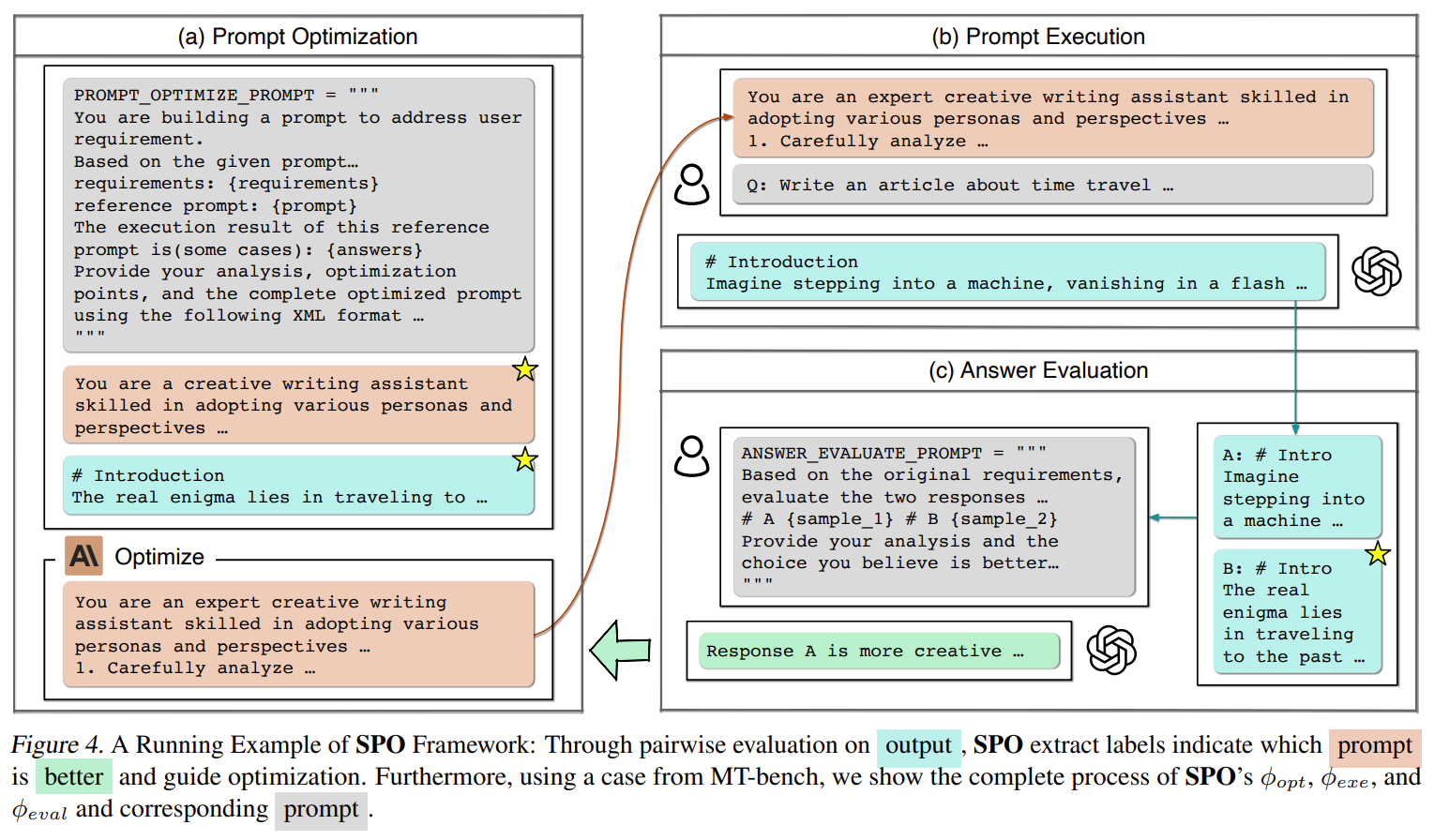
基本原理入下图
代码实现
注意,你需要自己选择baseModel。
"""Self‑Supervised Prompt Optimization (SPO) — **In‑Code Demo Suite**
All three share the same Execute → Evaluate → Optimize loop; only the task
content differs. Feel free to tweak the `demos` list inside `main()` or add
your own.
"""
from __future__ import annotations
import enum
import logging
from typing import Annotated, TypedDict
from langchain_openai import ChatOpenAI
from langchain_core.language_models import BaseChatModel
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableConfig
from langgraph.graph import END, StateGraph
from pydantic import BaseModel
max_trials = 3
###############################################################################
# 1. Prompt templates
###############################################################################
PROMPT_OPTIMIZE_PROMPT = """
## Role ##
你正在构建一个用于满足用户需求的提示词。
##task##
请基于所提供的原始提示词,和优化要求,重新构建并优化它。你可以添加、修改或删除提示内容。在优化过程中,可以引入任何思维模型。
这是一个在先前迭代中表现出色的提示词。你必须在此基础上进行进一步的优化和改进。修改后的提示词必须与原始提示词有所不同。
##原始提示词##
{old_prompt}
##要求##
{requirements}
限制在{max_words}字以内
##原始提示词示词的执行结果##
{answers}
"""
EVALUATE_PROMPT = """
##task##
根据需求,评估两个回复 A 和 B,并判断哪一个更好地满足了这些需求。
## 要求 ##
{requirements}
## 选项 ##
# A
{respA}
# B
{respB}
"""
###############################################################################
# 2. Config & State classes
###############################################################################
class SPOConfig(RunnableConfig):
init_prompt: str
requirements: str | None
max_words: int
rounds: int
title: str
class SPOState(TypedDict):
current_prompt: str
best_prompt: str
best_answer: str
answer: str
is_better: bool
round_no: int
###############################################################################
# 3. Helper utilities
###############################################################################
class OptimizeModel(BaseModel):
analyse: Annotated[str, "分析参考提示词产生的结果中存在的缺陷,以及可以如何改进。"]
modification: Annotated[str, "一句话总结本次优化的关键改进点"]
prompt: Annotated[str, "输出完整优化后的提示词"]
class EvaluateModel(BaseModel):
"""Provide your analysis and the choice you believe is better,"""
analysis: Annotated[str, "分析理由"]
choose: Annotated[str, "A/B (the better answer in your opinion)"]
class ModelEnum(enum.StrEnum):
DOUBAO_FUNCTION_CALL = enum.auto()
DOUBAO_1_5_PRO_32K = enum.auto()
DEEPSEEK_R1 = enum.auto()
DEEPSEEK_V3 = enum.auto()
def get_llm(model: ModelEnum, temperature: float = 0.1) -> BaseChatModel:
match model:
case ModelEnum.DOUBAO_1_5_PRO_32K|_:
return ChatOpenAI(
temperature=temperature,
timeout=60
)
###############################################################################
# 4. LangGraph nodes
###############################################################################
def execute_node(state: SPOState) -> SPOState:
llm = get_llm(ModelEnum.DEEPSEEK_V3, temperature=0.7)
state["answer"] = (llm | StrOutputParser()).invoke(input=state["current_prompt"])
if not state["best_answer"]:
state["best_answer"] = state["answer"]
return state
def evaluate_node(state: SPOState):
llm = get_llm(ModelEnum.DEEPSEEK_V3, temperature=0.5)
structured_llm = llm.with_structured_output(EvaluateModel)
wins = 0
for _ in range(max_trials):
prompt = EVALUATE_PROMPT.format(
requirements=cfg["requirements"] or "",
respA=state["current_prompt"],
respB=state["best_prompt"],
)
llm_res = structured_llm.invoke(prompt)
assert isinstance(llm_res, EvaluateModel)
if llm_res.choose == "A":
wins += 1
state["is_better"] = wins > (max_trials / 2)
if state["is_better"]:
state["best_prompt"], state["best_answer"] = state["current_prompt"], state["answer"]
logging.info(
f"[Round {state['round_no']}] {'✓ improved' if state['is_better'] else '✗ unchanged'} — wins={wins}"
)
state["round_no"]+=1
state["is_better"]=False
return state
def optimize_node(state: SPOState, cfg: SPOConfig):
llm = get_llm(ModelEnum.DEEPSEEK_V3, temperature=0.7)
structured_llm = llm.with_structured_output(OptimizeModel)
llm_res = structured_llm.invoke(
PROMPT_OPTIMIZE_PROMPT.format(
requirements=cfg["requirements"] or "(无)",
old_prompt=state["current_prompt"],
answers=state["answer"],
max_words=cfg["max_words"],
)
)
# Assert the type to help type checker
assert isinstance(llm_res, OptimizeModel)
state["current_prompt"] = llm_res.prompt
return state
###############################################################################
# 5. Build LangGraph workflow
###############################################################################
def build_graph(rounds: int):
g = StateGraph(SPOState)
g.add_node("execute", execute_node)
g.add_node("evaluate", evaluate_node)
g.add_node("optimize", lambda s: optimize_node(s, cfg))
g.set_entry_point("optimize")
g.add_edge("execute", "evaluate")
g.add_edge("optimize", "execute")
g.add_conditional_edges(
"evaluate",
lambda s: "continue" if s["is_better"] and s["round_no"] < rounds else "stop",
{"continue": "optimize", "stop": END},
)
return g.compile()
###############################################################################
# 6. Main entry: run all demos sequentially
###############################################################################
完整代码:https://github.com/yuvenhol/simple_spo

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)