Milvus向量数据库学习笔记(1)。
第一存储结构概念篇
我在第一篇学习笔记上,稍有犹豫。是应该先写架构篇,还是现在本篇内容。其实绝大部分数据库书籍,或者官网通常会考虑先介绍架构或者先教会如何安装。所以,我必然不能这么写。因为我不可能比官网的文档写的更好。所以,从一个学习者的视角来看。首要是易懂,其次是规整一些重要的感兴趣的概念。所以还是先放一放架构。学习向量数据库,难道我最感兴趣它的高可用架构?那必是不可能的。我当然想了解的是,向量数据库跟AI领域强相关的内容。另外,就我个人喜好而言,学习和理解一个数据库,我还是喜欢从数据库的存储结构来进入。
Milvus数据库的一些对象
这一部分对应官网文档的第四部分用户指南。
数据库Database
Milvus中,数据库是个逻辑概念。是组织和管理数据的逻辑单元。用于实现多租户,实现不同应用和租户的数据隔离性。有点类似于MYSQL的SCHEMA。或者ORACLE的数据库概念。常见的属性包括
- 副本数。replica.number
- 资源组。resource_groups
- 磁盘空间大小。diskquota.mb
- 允许最大链接。collections
- 强制拒绝写。force.deny.writing
- 强制拒绝读。force.deny.reading
集合Collections\实体Entities\字段Fields\Schema
首先,集合Collections,在传统数据中没有这个名词。它是一个管理数据用的对象。有一点类似于关系数据中的表。实体Entities,对标关系数据库中的某一行数据。数据需要作为实体来插入到Collections中,每一个实体对应了一个数据行。字段Fields,类似于关系型的列或者字段概念。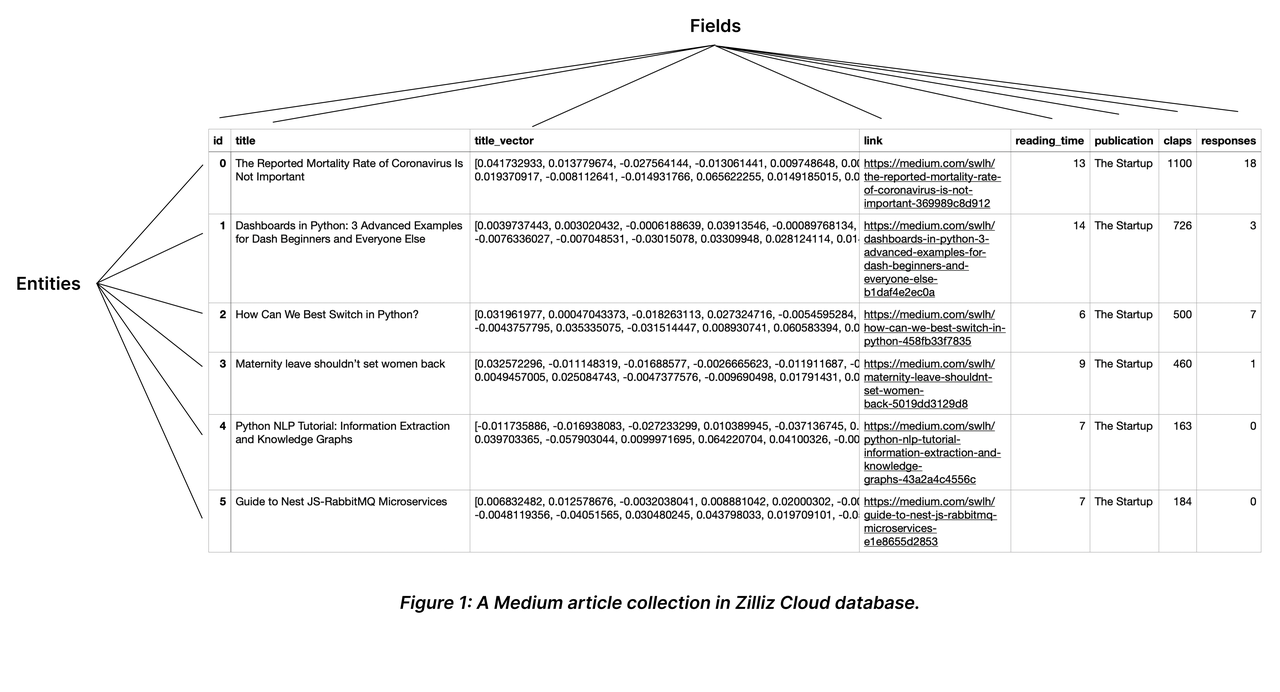
在文档中,Schema是最不好理解的一个概念,需要阅读或运行一下代码更好体会。假如我们要尝试者用一个传统的数据库并理解相关的数据库概念时,通常的套路是,建一个表,或许还有些其他对象。然后导入一些数据,再尝试访问数据。不妨按这个流程和官方给出的示例代码来试一下。
在创建一个Collections时,需要定义Schema、索引参数、度量参数等等。这就非常类似于,关系型数据库在建一张表的时候,要定义各个字段(包括字段名,字段类型,长度)、主键、索引等等。Schema按官网定义,Collection Schema是一个表的组合。从案例和描述上来看,它类似于关系型建表DDL里面,描述各个字段的定义部分。所以Schema定好了之后,插入的实体必须满足各个Schema的限定,才可以进入Collection。这类似关系数据,插入数据,每一列都要符合那一列的属性。一个Collection Schema有一个主键、最多四个向量字段、和几个标量字段。在官网创建Schema和添加字段的add_field示例代码来看,field应该是没有顺序概念的。所以猜测各个field的存储也是相互独立开的。这个从milvus可以只加载搜索涉及的字段进内存上来说,也比较像独立存储的。
从阅读文档的角度来看,初学时,容易混淆Collections和Schema的概念和二者的关系。这里比对Collections和Schema的创建代码,看起来更加清晰。以下是SCHEMA的创建。
Schema=milvusClient.create_schema(
Auto_id=False,
Enable_dynamic_field=True,
)
从代码上来,创建schema这个操作,并不需要先创建一个Collections。单独也可以执行,当没有关联上任何Collections之前,执行完这段代码不报错,但似乎没有特别的意义和痕迹。这和传统数据库的数据结构定义,直接写在建表语法之中不太一样。
再看Collections的创建代码。
Cliecnt.create_collection(
Collection_name=”customized_setup_1”,
Schema=schema,
Index_params=index_params
)
在建立一个Collection之后,这里Schema定义的各字段类型得以在Collection中保存下来。而在创建Collection,它的逻辑结构Schema必须在这之前,就被创建好。而在建立Collection的过程中提示,所有的向量字段都必须建立索引,否者Collection无法加载出来。
所以,一个完整正确的Collection的创建DDL的顺序是先定SCHEMA,把各种字段给定义出来。接下来把索引结构定义好。最后在collection的创建语句中,把schema和index_params指向刚刚定义好的SCHEMA和索引结构,最后再调用get_load_state就可以把Collection加载出来了。
索引index
这里只做简述,若以后合适,详述必然要再开一篇。看一下索引的定义代码。
Index_params=client.prepare_index_params()
Index_params.add_index(
Field_name=”my_id”,
Index_type=”AUTOINDEX”
)
Index_params.add_index(
Field_name=”my_vector”,
Index_type=”AUTOINDEX”,
Metric_type=”COSINE”
)
可以看出,这个索引参数Index_params就跟前面那个schema一样,它要在集合创建之前,先逻辑定义好。并且在集合创建的时候,指向这个索引参数,来在集合中把这个索引给实体化出来。
Enable_dynamic_field
SCHEMA中,Enable_dynamic_field参数设置为True就可以提供更多的灵活性。可以加入一些没有定义的列,这些列会放到一个JSON字段,称之为meta列。
它的查询用法,就和JSON字段类似。如果一个字段经常输出,或者频繁访问或过滤,就推荐明确定义。
动态字段,可以就理解为一个隐藏附加列。这个概念看起来就是灵活性为主,解决一些数据不那么标准的易兼容问题。但是,从查询 的限制上来看,暗示着这里面的数据不那么重要。起码使用者不打算用它来做重要的数据处理。
主键
Collection的主字段,实体的唯一标识,全局不可重。主字段只能是整数或者字符串。实体插入默认应该包含。可以使用AutoId自动生成。
向量字段\标量字段
一个Collections可以添加四个向量字段,必须建索引,可以用来向量计算,比如相似性搜索。标量字段,可以用来过滤,提高搜索结果的正确性。
分区
一个Collection的子集,一个Collections可以有1024个分区。可以限制某些分区内搜索和查询,以提高搜索性能。分区通过实体对应的分区键,计算一个哈希值来确定目标分区。(这个限定住了,在搜索是分区键限定在分区内搜索是等值或者IN的方式,而不能是某个范围)。加载和释放,也可以按分区的维度进行。
加载和释放
关系型没有的概念。贴合存算分离的思想
加载集合Collections是在集合中进行相似性搜索和查询的前提。–PS:所以人工智能要茫茫多的显卡,那不是没有原因的。通过load_collection加载。加载时,Milvus将所有文件和所有字段的原始数据加载到内存。快速响应搜索和查询。
本篇概念简述至此,Milvus的一些基本概念,既可以简单了对标到传统数据库的概念上。亦可以以此准备些测试的数据库对象和数据进行尝试了。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)