AI时代的C++
本文探讨了C++在AI领域的关键作用。尽管Python在AI开发中占据主导地位,但C++凭借其底层可控性、高效计算能力和内存优化优势,成为AI技术落地的核心支撑。文章分析了C++在AI框架底层架构、大模型推理优化(指令集加速、内存管理、量化计算)以及边缘AI部署中的不可替代性,指出C++与Python形成"协同关系":Python负责原型开发,C++负责高效落地。随着AI对性能
大家好,我是D枫。当AI技术以“颠覆性”姿态重塑各行各业时,人们的目光多聚焦于Python的便捷、PyTorch/TensorFlow的易用性,却往往忽略了隐藏在这些高级框架之下的“隐形功臣”——C++。在大模型推理、自动驾驶感知、工业AI质检等对性能与延迟极致苛求的场景中,C++从未缺席,反而凭借其底层可控性、高效计算能力,成为AI技术落地的“最后一公里”关键支撑。它不再只是传统认知中“老旧的系统级语言”,而是AI时代实现“算力最大化利用”的核心引擎。
文章目录
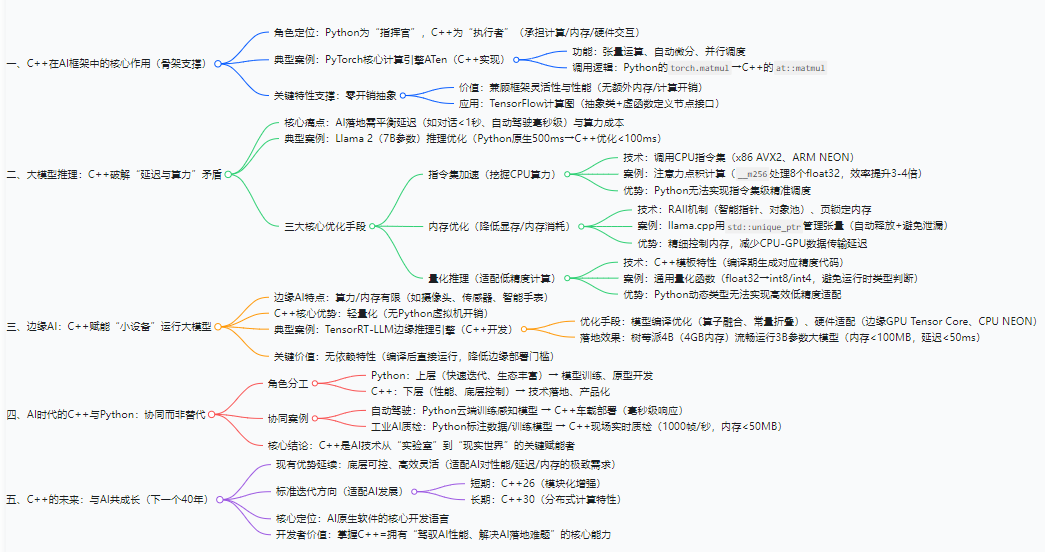
一、AI框架的“骨架”:C++撑起底层核心架构
无论是主流的PyTorch、TensorFlow,还是轻量级的TinyNN,其“用户可见的Python接口”之下,真正负责计算、内存管理、硬件交互的核心模块,几乎全由C++实现。Python的角色更像“指挥官”,而C++则是“执行者”,承担着AI框架中最繁重的“体力活”。
以PyTorch为例,其核心计算引擎“ATen”完全基于C++开发,负责实现张量运算、自动微分、并行调度等核心逻辑。当开发者用Python写下torch.matmul(A, B)时,背后实际调用的是C++实现的at::matmul函数——该函数通过模板特化适配不同数据类型(float32、float16),通过CPU指令集优化(AVX、SSE)或GPU调用(CUDA C++)实现高效计算。若将PyTorch比作“智能工厂”,Python是“中控面板”,C++则是“生产线的核心机械臂”,决定着生产效率的上限。
更关键的是,C++的“零开销抽象”特性,让AI框架在兼顾灵活性的同时,无需付出性能代价。例如TensorFlow的“计算图”模块,通过C++的抽象类与虚函数定义计算节点接口,不同算子(卷积、池化)可通过继承实现自定义逻辑,而运行时仅需调用虚函数即可触发对应计算——这种设计既保证了框架的可扩展性,又避免了额外的内存或计算开销,这是Python等带有虚拟机的语言难以实现的。
二、大模型推理:C++破解“延迟与算力”的核心矛盾
大模型落地的核心痛点之一,是“推理延迟”与“算力成本”的平衡。当用户与ChatGPT类产品对话时,若响应超过1秒便会影响体验;而在自动驾驶场景中,激光雷达点云的AI处理需在毫秒级完成,否则可能引发安全事故。此时,C++成为破解这一矛盾的关键技术。
以7B参数的开源大模型Llama 2为例,若直接用Python原生推理,单条对话响应延迟可能超过500ms,而通过C++优化的推理引擎(如llama.cpp),可将延迟降至100ms以内,核心优化手段集中在三点:
1. 指令集加速:手写SIMD挖掘CPU算力
大模型推理的核心是“矩阵乘法”与“Transformer注意力计算”,C++可通过直接调用CPU指令集(如x86的AVX2、ARM的NEON)实现向量并行计算。例如在注意力机制的“点积计算”中,通过C++的__m256(AVX2指令集)可同时处理8个float32数据,将计算效率提升3-4倍:
// C++ AVX2优化注意力点积计算
#include <immintrin.h>
#include <vector>
void attention_dot_product(const std::vector<float>& q,
const std::vector<float>& k,
std::vector<float>& output,
int seq_len) {
for (int i = 0; i < seq_len; i++) {
__m256 sum = _mm256_setzero_ps(); // 初始化累加向量
// 每次处理8个元素,循环遍历k的所有维度
for (int j = 0; j < seq_len; j += 8) {
// 加载q的单个元素,广播到8个位置
__m256 q_val = _mm256_set1_ps(q[i * seq_len + j / 8]);
// 加载k的8个连续元素
__m256 k_vals = _mm256_loadu_ps(&k[j * seq_len + i]);
// 向量点积:sum += q_val * k_vals
sum = _mm256_fmadd_ps(q_val, k_vals, sum);
}
// 将8个元素的累加结果汇总为单个值,存入output
float result = 0;
float temp[8];
_mm256_storeu_ps(temp, sum);
for (int m = 0; m < 8; m++) result += temp[m];
output[i] = result;
}
}
这种“贴近硬件”的优化,只有C++能实现——Python的动态类型与虚拟机开销,根本无法支撑指令集级别的精准调度。
2. 内存优化:RAII机制降低显存/内存消耗
大模型推理时,张量数据的频繁创建与销毁会导致内存碎片,而C++的RAII(资源获取即初始化)机制可通过智能指针、对象池实现内存高效管理。例如llama.cpp通过std::unique_ptr管理张量内存,确保张量生命周期结束时自动释放内存,避免内存泄漏;同时通过“页锁定内存”(Pin Memory)技术,减少CPU与GPU之间的数据传输延迟——这一过程完全依赖C++对操作系统内存接口的直接调用,Python无法实现如此精细的内存控制。
3. 量化推理:C++模板适配低精度计算
为降低算力消耗,大模型推理常采用“量化技术”(如将float32转为int8、int4),而C++的模板特性可轻松适配不同精度的计算逻辑。例如通过模板函数定义通用的量化/反量化接口,编译时自动生成对应精度的代码,避免运行时类型判断的开销:
// C++ 模板实现通用量化函数
template <typename T, typename U>
void quantize(const std::vector<T>& input,
std::vector<U>& output,
T scale,
T zero_point) {
for (size_t i = 0; i < input.size(); i++) {
// 量化公式:output = round(input / scale) + zero_point
output[i] = static_cast<U>(std::round(input[i] / scale) + zero_point);
}
}
// 编译时自动生成float32→int8、float32→int4的实现
quantize<float, int8_t>(fp32_tensor, int8_tensor, 0.01f, 127);
quantize<float, int4_t>(fp32_tensor, int4_tensor, 0.02f, 7);
这种“编译期优化”是C++的独有优势,Python的动态类型系统无法做到如此高效的低精度适配。
三、边缘AI:C++让“小设备”也能跑大模型
随着AI从“云端”向“边缘端”(如摄像头、工业传感器、智能手表)渗透,设备的算力与内存资源更加有限,此时C++的“轻量化”特性成为关键。例如在智能摄像头的“实时人脸识别”场景中,设备的CPU算力可能仅为云端服务器的1/100,内存不足1GB,Python的虚拟机开销(约占10%-20%内存)已无法承受,而C++编写的推理程序可做到“内存占用低于100MB,延迟低于50ms”。
以开源项目TensorRT-LLM为例,其边缘端推理引擎完全基于C++开发,通过“模型编译优化”(如算子融合、常量折叠)与“硬件适配”(如适配边缘GPU的Tensor Core、边缘CPU的NEON指令集),可在树莓派4B(4GB内存)上流畅运行3B参数的大模型,而这一切的核心在于C++的“无依赖特性”——编译后的C++程序可直接运行,无需依赖Python解释器等额外环境,大幅降低边缘设备的部署门槛。
四、AI时代的C++:不是“替代者”,而是“赋能者”
有人质疑:“AI时代Python已成主流,C++是否会被淘汰?”答案是否定的。Python的优势在于“快速迭代与生态丰富”,适合AI模型的训练与原型开发;而C++的优势在于“性能与底层控制”,适合AI技术的落地与产品化。二者并非“替代关系”,而是“协同关系”——Python负责“想法诞生”,C++负责“想法落地”。
例如在自动驾驶领域,算法工程师用Python在云端训练感知模型,而工程团队用C++将模型部署到车载芯片,通过C++调用激光雷达、摄像头的硬件接口,实现“感知-决策-控制”的毫秒级响应;在工业AI质检中,数据科学家用Python标注数据、训练分类模型,而现场设备的实时质检程序用C++编写,确保每秒钟处理1000帧图像,且内存占用稳定在50MB以内。
这种“Python做上层,C++做下层”的协同模式,已成为AI行业的主流实践——C++不是AI时代的“过时者”,而是让AI技术从“实验室”走向“现实世界”的关键赋能者。
结语:C++的下一个40年,与AI共成长
从1985年诞生至今,C++已走过40年,它经历了PC时代、移动时代,如今又迎来了AI时代。每一次技术浪潮中,C++都能凭借其“底层可控、高效灵活”的核心特性,找到自己的位置。在AI时代,C++的价值不仅在于“支撑现有技术”,更在于“推动技术突破”——当大模型的参数规模突破万亿,当边缘设备的AI需求日益增长,对性能、延迟、内存的极致追求,只会让C++的重要性愈发凸显。
随着C++26、C++30等标准的迭代(如模块化、分布式计算特性的增强),它将进一步适配AI技术的发展需求,成为“AI原生软件”的核心开发语言。对于开发者而言,掌握C++不再只是“掌握一门古老的语言”,而是拥有“驾驭AI性能、解决AI落地难题”的核心能力——这正是AI时代赋予C++的新使命,也是C++留给开发者的新机遇。
最后希望我可以获得与C++之父现场交流的机会,哈哈!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)