图像编辑新突破!天大&快手提出GRAG:4 行代码改造DiT注意力层,实现图像编辑 “指令跟随-原图保真” 双优
论文基本信息
|
信息项 |
内容 |
|---|---|
| 论文标题 |
Group Relative Attention Guidance for Image Editing |
| 作者 |
Xuanpu Zhang, Xuesong Niu*, Ruidong Chen, Dan Song, Jianhao Zeng, Penghui Du, Haoxiang Cao, Kai Wu, An-an Liu |
| 单位/团队 |
天津大学,快手Kolors团队 |
| 论文链接 |
arXiv:2510.24657v1 |
| 项目主页 |
GRAG-Image-Editing (即将开源) |
| 发表时间 |
2025年10月 |
原、文、指路:图像编辑新突破!天大&快手提出GRAG:4 行代码改造DiT注意力层,实现图像编辑 “指令跟随-原图保真” 双优
一、前言 / 背景引入
随着Diffusion Transformer(DiT)模型的兴起,文生图与图像编辑能力实现了飞跃,特别是在多模态MM-Attention架构加持下,图文、图图混合的复杂编辑需求被更精准地满足。然而,现有编辑方法对“编辑强度”的控制不够灵活,用户往往难以兼顾指令响应度与原图一致性,只能借助提示工程、反复试错等手段。
本论文聚焦于DiT图像编辑中的内在机制,首次揭示并利用MM-Attention中的“群体偏置向量”现象,提出**Group Relative Attention Guidance (GRAG)**新方法,实现连续、可调、无须微调的“编辑强度”精准控制。无论训练型还是免训练型编辑框架,GRAG都可一键集成,并超越主流的Classifier-Free Guidance(CFG),带来更细腻、更符合人意图的编辑体验。
二、创新点与方法亮点
本论文围绕Diffusion-in-Transformer(DiT)图像编辑的可控性难题,提出了独具开创性的Group Relative Attention Guidance(GRAG)机制。以下分点详细梳理其核心创新,并配合图、表、公式深入解读:
1. 揭示MM-Attention层的“群体偏置向量”现象
-
论文首次对DiT架构下的多模态注意力机制(MM-Attention)进行深入分析,发现每层Attention的Query和Key分布均高度集中于某一主导向量(偏置),即:其中 为主导偏置, 为每个token的内容偏移。
-
这一主导偏置向量本质上控制了编辑行为的“基准动作”,而偏移部分才携带具体编辑内容。
★
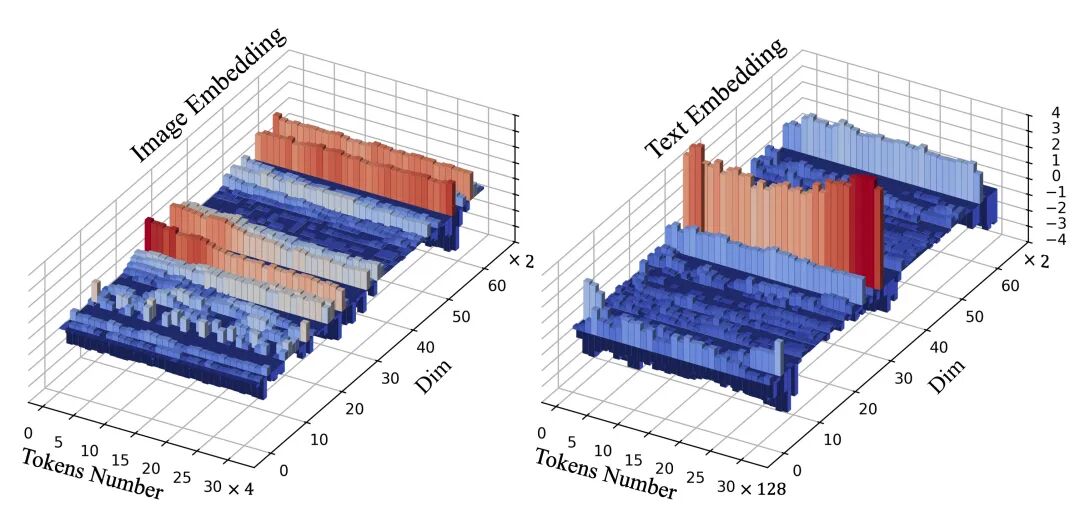
Kontext模型Attention层特征分布可视化。可见文本token集中于低频率区间,图像token集中于高频率区间,均呈现强烈偏置。
2. 提出Group Relative Attention Guidance(GRAG)创新机制
-
核心思想:直接在MM-Attention中建模“偏置+偏移”的结构,通过可调参数连续控制编辑强度。
-
具体做法:
-
加强整体编辑方向, 加强内容响应。
-
分组求均值,以源图像token为例,计算Key组的均值,每个token与均值的偏移。
-
参数连续控制偏置与偏移占比:
-
-
工程极致简洁,仅需4行代码即可集成,且对各类DiT/Flux.1/Flowedit等架构无缝适配。
★
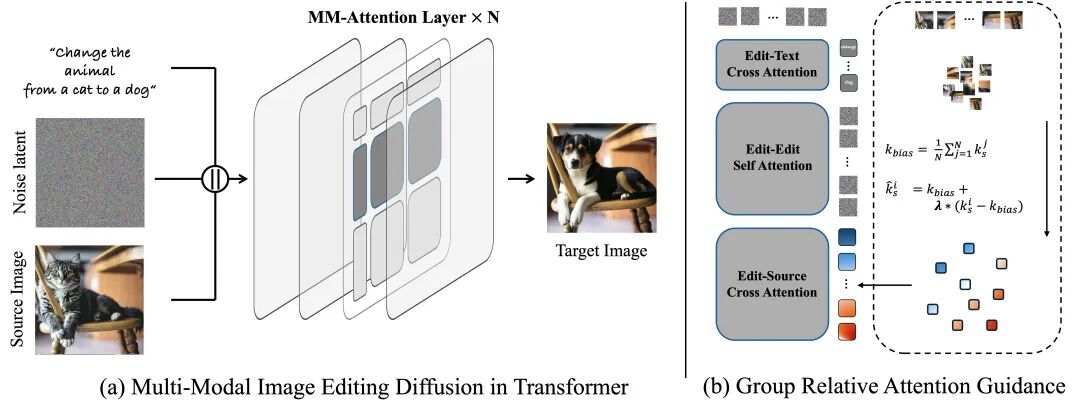
GRAG机制在MM-Attention流程中的作用示意。红色token响应增强,蓝色响应抑制,实现精准可控编辑。
伪代码实现
Kbias = mean(Ks, dim=1)K_delta = Ks - KbiasKs = lambda * Kbias + delta * K_delta# 后续按原attention流程继续-
PyTorch官方实现片段:
s_idx, e_idx, bias_scale, delta_scale = 4096, 8192, 1.0, 1.05group_bias = img_key[:, s_idx:e_idx, :, :].mean(dim=1)img_key[:, s_idx:e_idx, :, :] = bias_scale * group_bias + delta_scale * (img_key[:, s_idx:e_idx, :, :] - group_bias)原、文👉图像编辑新突破!天大&快手提出GRAG:4 行代码改造DiT注意力层,实现图像编辑 “指令跟随-原图保真” 双优 https://mp.weixin.qq.com/s/C9T7_H4rEjg7UwJh571Q_g
https://mp.weixin.qq.com/s/C9T7_H4rEjg7UwJh571Q_g
3. 精细调节编辑强度,超越CFG的连续可控能力
-
与主流Classifier-Free Guidance(CFG)对比,GRAG具备真正连续、柔顺的编辑强度调节能力。
-
只需调整即可获得从“弱变强”的顺滑编辑过渡,而CFG难以实现如此线性可控的变化。

同一输入下,CFG和GRAG不同编辑强度的可视化对比。GRAG实现了更平滑的渐变,且编辑区域细节更优。
4. 多类型模型广泛适配与轻量集成
-
GRAG不仅适配Kontext、Qwen-Edit、Step1X-Edit等训练型模型,还能用于Flowedit、Stableflow等“免训练”Diffusion编辑器,实现跨模型通用性。
-
工程集成极简,仅需在Attention主干插入数行代码,不影响原有训练/推理流程。
5. 多维实验指标验证显著提升
训练型方法集成GRAG前后量化对比
|
Model |
LPIPS↓ |
SSIM↑ |
Cons↑ |
PF↑ |
EditScore↑ |
|---|---|---|---|---|---|
|
Kontext-Dev |
0.3061 |
0.9213 |
8.9051 |
6.9051 |
6.0887 |
|
+GRAG |
0.3873 |
0.8156 |
8.6788 |
7.4177 |
6.4081 |
|
Step1X-Edit |
0.3228 |
0.9042 |
8.4714 |
7.8406 |
6.8292 |
|
+GRAG |
0.3174 |
0.9137 |
8.6240 |
8.0406 |
7.0045 |
|
Qwen-Edit |
0.3428 |
0.8506 |
8.5211 |
8.4806 |
7.2576 |
|
+GRAG |
0.3042 |
0.9263 |
8.9440 |
8.3303 |
7.3245 |
★
LPIPS/SSIM:内容保真度
Cons:与原图一致性
PF:指令响应性
EditScore:综合编辑得分(越高越优)
6. 机制消融分析与灵敏度研究
-
调节影响有限,可实现连续且无伪影的强度调节。两者联动虽可进一步加大编辑力度,但容易带来失真。
CFG与GRAG参数消融
|
Method |
LPIPS↓ |
SSIM↑ |
Cons↑ |
PF↑ |
EditScore↑ |
|---|---|---|---|---|---|
|
CFG = 5.00 |
0.3381 |
0.8548 |
8.3989 |
8.4640 |
7.1857 |
|
λ=1.05, δ=1.05 |
0.3042 |
0.9263 |
8.9440 |
8.3303 |
7.3245 |
|
λ=1.15, δ=1.15 |
0.2885 |
0.9448 |
9.1051 |
6.6091 |
5.9955 |
三、核心方法与公式详解
本节将系统梳理GRAG(Group Relative Attention Guidance)的数学建模、核心流程、关键公式与代码实现,并穿插图例与直观说明,助力技术读者真正吃透“如何实现可控Diffusion图像编辑”。
1. MM-DiT架构与Attention机制核心回顾
多模态Diffusion Transformer基础
-
输入映射:将文本token 与图像token 投影到共享空间
其中为对应的投影矩阵,为通道维度。
-
联合Attention计算:
其中为token拼接。
-
编辑流程分三路:
★
说明:上述为简化表达,省略项。
-
Text
-
Editing (目标区域)
-
Source (原始区域)
-
2. 发现与建模群体偏置向量(Bias Vector)
分解结构
-
论文通过可视化和统计,发现Query/Key在注意力层有以下分解结构:
-
偏置向量主导“编辑行为”,而部分编码具体“内容”。
★
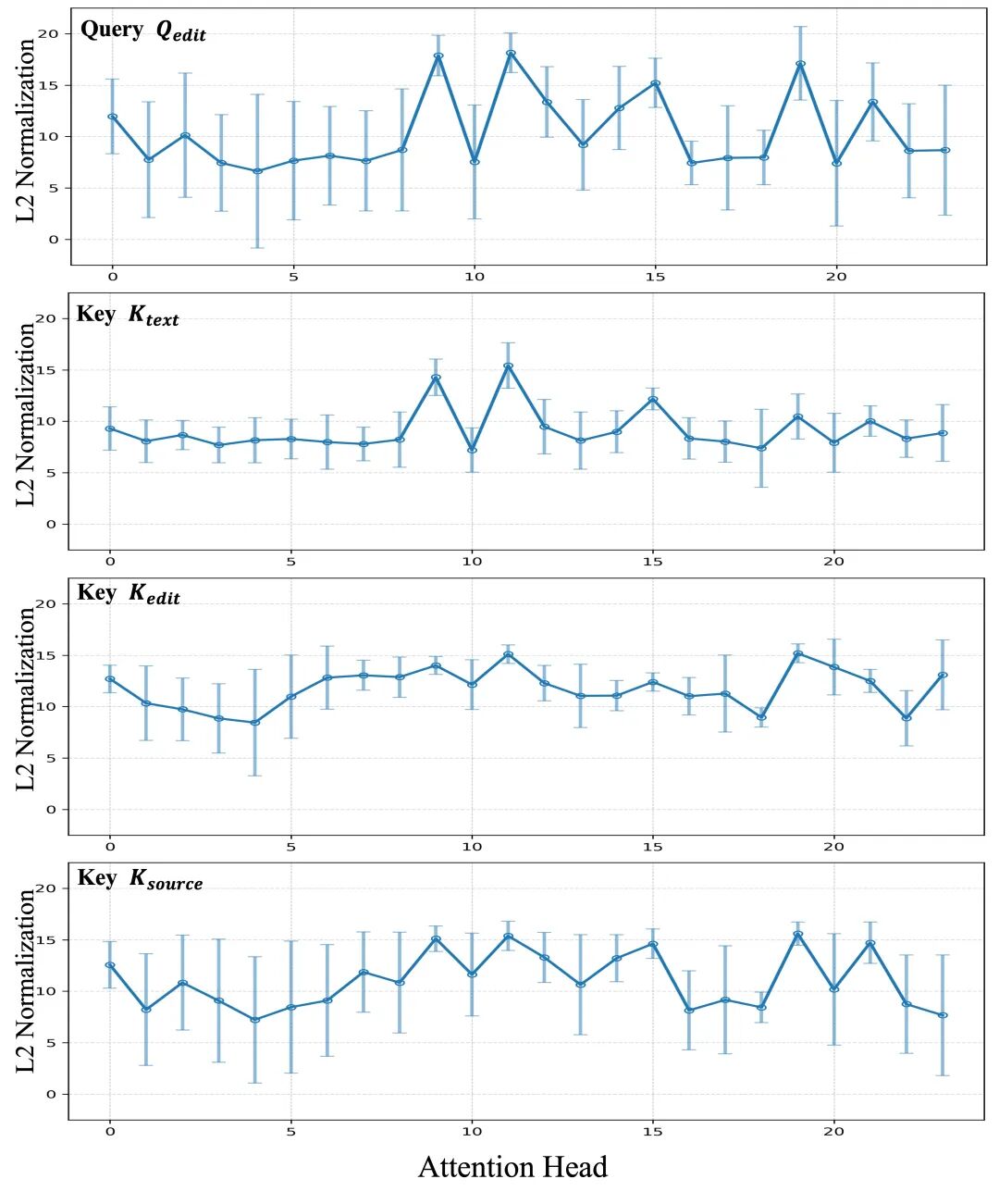
Query-Edit各Attention Head上的均值与方差统计,显示明显偏置分布。
实际影响
-
在Attention分数计算中,的存在会稀释的影响,从而削弱条件信号(如编辑指令)的控制力。
-
如何通过调控提升编辑可控性,成为方法设计关键。
3. GRAG核心公式与流程
偏置调制公式
-
Group Relative Attention Guidance关键公式:
-
调节主导偏置权重
-
调节内容偏移强度(建议主要调以获得连续柔顺的编辑效果)
-
群体偏置与偏移的计算
-
为分组token数(如源图像tokens)
伪代码与官方实现
★Algorithm 1(节选)
Kbias = mean(Ks, dim=1)K_delta = Ks - KbiasKs = lambda * Kbias + delta * K_delta★PyTorch实现
# 4096~8192为image token indexs_idx, e_idx, bias_scale, delta_scale = 4096, 8192, 1.0, 1.05group_bias = img_key[:, s_idx:e_idx, :, :].mean(dim=1)img_key[:, s_idx:e_idx, :, :] = bias_scale * group_bias + delta_scale * (img_key[:, s_idx:e_idx, :, :] - group_bias)-
重点:仅需4行,即可对Attention模块实现GRAG集成。
4. GRAG作用流程可视化与结构图
★
GRAG在MM-Attention的作用流程。红色为增强token,蓝色为抑制token,实现精准可控的编辑调节。
-
a. 选择关键token分组(如源图像token),计算偏置
-
b. 偏置+偏移可调混合,形成新的Key参与Attention
-
c. 实现对编辑区域与原图细节的“柔性”控制
5. 参数灵敏度与调控能力分析
-
****:主控整体编辑风格,调整幅度过大易致失真
-
****:核心调节编辑强度,实现从“无变动”到“强烈编辑”的顺滑过渡
CFG与GRAG参数调节实验
|
Method |
LPIPS↓ |
SSIM↑ |
Cons↑ |
PF↑ |
EditScore↑ |
|---|---|---|---|---|---|
|
CFG = 5.00 |
0.3381 |
0.8548 |
8.3989 |
8.4640 |
7.1857 |
|
λ=1.05, δ=1.05 |
0.3042 |
0.9263 |
8.9440 |
8.3303 |
7.3245 |
|
λ=1.15, δ=1.15 |
0.2885 |
0.9448 |
9.1051 |
6.6091 |
5.9955 |
-
结论:调节带来连续可控、无明显伪影的编辑能力,是Diffusion图像编辑中细粒度调节的关键参数。
6. 全流程概览与适配性说明
-
GRAG只需在MM-Attention层插入4行代码,工程极其简洁。
-
可直接用于训练型/免训练型Diffusion编辑方法,对主流开源框架无缝集成。
-
最终效果:实现编辑内容/强度的灵活平衡,既能细腻响应用户指令,也能最大程度保留原图细节。
★通过对MM-Attention偏置结构的挖掘与GRAG机制的设计,本文不仅实现了方法层的理论突破,更提供了极具工程实用性的解决方案,为Diffusion图像编辑领域带来全新可控性范式。
四、实验结果与可视化分析
GRAG方法经过系统定量与定性实验,覆盖主流训练型与免训练型Diffusion图像编辑模型,取得了极具说服力的性能提升和细粒度可控性突破。本节将按定性展示、量化对比、参数消融等维度,结合图表与代码,完整解析实验发现。
1. 训练型与免训练型方法上的可视化效果
(1)训练型方法:Kontext、Step1X-Edit、Qwen-Edit

GRAG集成于训练型编辑器的效果可视化。GRAG显著提升了编辑区域的可控性,且保留了原图细节。
如图第一列,鸟的羽毛被精细调整,树干细节依旧清晰。
最后一列Kontext原生方法几乎无编辑响应,GRAG后能精准实现指令编辑。
(2)免训练型方法:Flowedit、StableFlow、StableFlow+
★
GRAG在免训练方法上的可控编辑。编辑区域的变化更平滑、细致。

2. 与主流CFG方法的可控性对比

CFG与GRAG在不同强度下的编辑对比。GRAG能实现连续且线性的编辑效果,细节过渡自然;而CFG调整下结果跳变明显,难以实现平滑强度调节。
3. 量化实验对比(PIE数据集)
训练型方法GRAG集成前后对比
|
Model |
LPIPS↓ |
SSIM↑ |
Cons↑ |
PF↑ |
EditScore↑ |
|---|---|---|---|---|---|
|
Kontext-Dev |
0.3061 |
0.9213 |
8.9051 |
6.9051 |
6.0887 |
|
+GRAG |
0.3873 |
0.8156 |
8.6788 |
7.4177 |
6.4081 |
|
Step1X-Edit |
0.3228 |
0.9042 |
8.4714 |
7.8406 |
6.8292 |
|
+GRAG |
0.3174 |
0.9137 |
8.6240 |
8.0406 |
7.0045 |
|
Qwen-Edit |
0.3428 |
0.8506 |
8.5211 |
8.4806 |
7.2576 |
|
+GRAG |
0.3042 |
0.9263 |
8.9440 |
8.3303 |
7.3245 |
★
LPIPS/SSIM:内容保真度
Cons:与原图一致性
PF:指令响应性
EditScore:综合编辑得分(越高越优)
免训练型方法GRAG集成前后对比
|
Model |
LPIPS↓ |
SSIM↑ |
Cons↑ |
PF↑ |
EditScore↑ |
|---|---|---|---|---|---|
|
Flowedit |
0.3758 |
0.8237 |
6.8794 |
5.0531 |
4.6635 |
|
+GRAG |
0.3670 |
0.8312 |
7.2223 |
4.8954 |
4.6697 |
|
StableFlow |
0.3219 |
0.9185 |
8.9309 |
2.2177 |
2.4573 |
|
+GRAG |
0.3292 |
0.9098 |
8.8731 |
2.7429 |
3.0303 |
|
StableFlow+ |
0.3691 |
0.8229 |
7.3599 |
5.3926 |
5.0970 |
|
+GRAG |
0.3595 |
0.8316 |
7.7997 |
4.8395 |
4.7251 |
4. 参数消融实验与可控性分析
CFG与GRAG参数调节消融
|
Method |
LPIPS↓ |
SSIM↑ |
Cons↑ |
PF↑ |
EditScore↑ |
|---|---|---|---|---|---|
|
CFG = 5.00 |
0.3381 |
0.8548 |
8.3989 |
8.4640 |
7.1857 |
|
CFG = 3.00 |
0.3312 |
0.8659 |
8.6251 |
8.3954 |
7.2761 |
|
λ=1.05, δ=1.05 |
0.3042 |
0.9263 |
8.9440 |
8.3303 |
7.3245 |
|
λ=1.15, δ=1.15 |
0.2885 |
0.9448 |
9.1051 |
6.6091 |
5.9955 |
-
结论:仅调整时编辑强度变化有限,调节可以获得最连续、平滑且无伪影的编辑渐变,是可控编辑的关键参数。
5. 代码与实现细节(可直接复现)
★伪代码(节选自Algorithm 1)
Kbias = mean(Ks, dim=1)K_delta = Ks - KbiasKs = lambda * Kbias + delta * K_delta# 后续参与标准Attention★PyTorch代码实现(附录A)
s_idx, e_idx, bias_scale, delta_scale = 4096, 8192, 1.0, 1.05group_bias = img_key[:, s_idx:e_idx, :, :].mean(dim=1)img_key[:, s_idx:e_idx, :, :] = bias_scale * group_bias + delta_scale * (img_key[:, s_idx:e_idx, :, :] - group_bias)五、总结与未来展望
本部分将结合论文核心内容,对GRAG方法的贡献、工程与理论意义、存在的局限,以及未来发展趋势进行深入梳理。
1. 论文核心贡献总结
-
首次揭示MM-Attention偏置结构 论文系统分析了Diffusion-in-Transformer(DiT)架构下多模态注意力机制的内部特征分布,发现并理论化了每层Query/Key的“群体偏置向量”现象,为理解与调控大模型编辑行为提供了全新视角。
-
提出极简、通用的GRAG可控编辑机制 Group Relative Attention Guidance(GRAG)通过仅4行代码、无须微调即可集成于各类MM-Attention架构,实现了编辑强度的连续、可调、细粒度控制,极大提升了用户自定义编辑体验,并超越传统CFG等主流方法。
-
多模态编辑性能与可用性全面提升 实验证明GRAG在训练型与免训练型主流编辑框架下均能带来更优异的编辑质量、响应度与一致性,编辑强度调节更平滑,工程集成门槛极低,具有广泛实际落地价值。
2. 方法局限与待突破点
-
免训练场景稳定性尚有提升空间 当前GRAG在部分免训练型Diffusion编辑器(如StableFlow等)中,表现出一定的不稳定性。主要原因是GRAG更适合调控MM-Attention的cross-attention结构,而部分免训练架构的源图像特征注入方式不同,后续可进一步针对不同Attention路径优化适配策略。
-
部分极端参数设置下会带来视觉伪影 虽然参数可实现编辑强度柔顺连续调节,但若、设定过高,可能会在特定样本上导致局部失真或编辑失控。因此,合理的参数区间选择与自适应策略是未来优化方向。
3. 未来展望与研究方向
-
面向更复杂编辑任务的通用可控机制 未来可探索GRAG在多模态、多场景(如视频编辑、跨模态风格迁移、图文融合创作等)任务中的泛化能力,推动可控编辑范式成为大模型架构的“标配能力”。
-
与其他条件调控机制的深度融合 可尝试将GRAG与LoRA、指令微调(Instruction Tuning)、检索增强(RAG)等方法结合,实现更强大的端到端多模态可控编辑系统。
-
理论机制与可解释性深入拓展 进一步分析Attention偏置与内容可控之间的数学联系,丰富编辑强度、内容多样性、用户主观意图之间的映射关系,为可解释性与信任度提升打下理论基础。
-
提升工程实用性与生态完善 随着GRAG代码开源,后续将持续完善配套示例、社区文档和一键集成脚本,助力产业界、开源社群快速集成和落地创新。
★GRAG的提出不仅是Diffusion大模型图像编辑可控性领域的重要突破,更为AI创意内容生产、用户个性化定制、产业智能化升级等应用场景提供了全新技术底座。期待学界与产业界共同推动Diffusion大模型可控编辑能力的普及与发展。
六、工程复现与代码实践指南(即将开源)
★声明:截至发稿时,GRAG官方项目主页(GitHub: little-misfit/GRAG-Image-Editing)尚未正式开源,下述内容仅为简要功能介绍,具体代码和部署细节请关注项目主页后续更新。
1. 快速集成特性
-
极致轻量:GRAG仅需4行代码即可插入主流Diffusion-in-Transformer(DiT)或MM-Attention模块,兼容如Kontext、Step1X-Edit、Qwen-Edit、Flowedit、StableFlow等开源/自研Diffusion编辑框架。
-
无须微调:工程落地无需模型结构重训练,可直接在原有推理流程中动态切换GRAG开关与参数,便于实验与产业快速验证。
2. 典型伪代码片段
# 假设img_key为image tokens,s_idx/e_idx为编辑token范围s_idx, e_idx, bias_scale, delta_scale = 4096, 8192, 1.0, 1.05group_bias = img_key[:, s_idx:e_idx, :, :].mean(dim=1)img_key[:, s_idx:e_idx, :, :] = bias_scale * group_bias + delta_scale * (img_key[:, s_idx:e_idx, :, :] - group_bias)# 后续进入标准Attention流程-
参数解释:
bias_scale控制偏置影响,delta_scale调节编辑内容强度,灵活实现连续、可控编辑。
3. 推荐工程配置与集成说明
-
推荐环境:Python 3.9+、PyTorch >=1.12、常见Diffusers/Transformers库
-
集成方式:直接在MM-Attention主干插入上述片段,或按官方README示例添加GRAG模块参数配置。
-
未来开源后,预计将包含详细的文档说明、集成Demo、参数调优脚本及丰富案例,可一键复现论文实验与可控编辑效果。
4. 注意事项与展望
-
当前尚未正式开源,如有需求请关注项目主页或联系作者团队获取工程咨询。
-
开源后将持续迭代,包括更多Diffusion大模型适配支持、视频/多模态拓展、社区教程等。
★结语:GRAG以极简工程实现和卓越可控能力,推动可控Diffusion图像编辑向更高标准演进。期待开源正式发布后,与技术社区共同创新更多场景应用!
七、附录/扩展资源
-
论文原文:https://arxiv.org/html/2510.24657v1
-
项目主页:GRAG-Image-Editing:https://github.com/little-misfit/GRAG-Image-Editing
-
主流基线框架:Kontext、Step1X-Edit、Qwen-Edit、StableFlow等
-
其他参考:
-
Diffusers库:(https://github.com/huggingface/diffusers)
-
Flux.1-dev模型:(https://huggingface.co/black-forest-labs/FLUX.1-dev)
-
往期推荐
强烈推荐!多模态融合顶会新成果!CVPR/AAAI 高分成果,这波思路必须学!
OCR “去幻觉” 新纪元!通义点金 OCR-R1 搞定模糊盖章+跨页表格,攻克 OCR 三大痛点!
NeurIPS'2025高分入选!扩散模型+Transformer,效率与质量双线飙升!
杀疯了!2025 最新Agent Memory顶会论文,拿捏发文密码!
ICCV 2025|FrDiff:频域魔法+扩散模型暴力去雾,无监督性能刷爆榜单!
NeurIPS 2025 | 港科大&上交大HoloV:多模态大模型“瘦身”新突破,剪枝88.9%视觉Token,性能几乎无损
太牛了!北大:Unified-GRPO让理解生成正反馈,超 GPT-4o-Image

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)