最顶尖的OCR算法有哪些?
然而,现实世界中的文档往往布局复杂、表格嵌套、内含图片公式,甚至跨页分布,这让许多现有的 OCR(光学字符识别系统,Optical Character Recognition)系统感到棘手。在数字化办公与 AI 技术深度融合的今天,文档智能解析技术已成为信息抽取、检索增强生成和自动化文档分析的核心基石。上较此前最优方法(MinerU2.5、PPOCR-VL、DeepSeek-OCR 等)实现了全面

向AI转型的程序员都关注公众号 机器学习AI算法工程
在数字化办公与 AI 技术深度融合的今天,文档智能解析技术已成为信息抽取、检索增强生成和自动化文档分析的核心基石。然而,现实世界中的文档往往布局复杂、表格嵌套、内含图片公式,甚至跨页分布,这让许多现有的 OCR(光学字符识别系统,Optical Character Recognition)系统感到棘手。
一 .突破性轻量OCR:3B参数的MonkeyOCR吊打Gemini与72B巨头
MonkeyOCR v1.5是一个全新的统一视觉 - 语言文档解析框架。它在全能多模态文档解析基准OmniDocBench v1.5,OCRFlux-bench上较此前最优方法(MinerU2.5、PPOCR-VL、DeepSeek-OCR 等)实现了全面突破,更在复杂表格、嵌入图像和跨页结构等棘手场景中,相较此前最优方法大幅提升 9.7%。
技术圈长期面临一个三元悖论:精度、效率、成本难以兼得。
- 传统流水线方案
(如MinerU )依赖串联工具链,错误逐级累积,公式识别准确率不足60%;
- 端到端大模型
(如Qwen-VL-72B)虽精度高,但处理单页文档需数十秒,成本陡增;
- 直到MonkeyOCR登场
:仅3B参数的轻量化模型,在英文文档解析任务中超越Gemini 2.5 Pro,表格识别率提升8.6%,处理速度达0.84页/秒(较Qwen-VL-7B快7倍)。
GitHub源码:https://github.com/Yuliang-Liu/MonkeyOCR
在线Demo:http://vlrlabmonkey.xyz:7685
模型下载:https://huggingface.co/echo840/
实战指南:从安装到结构化输出
# 创建环境(需Python 3.10) conda create -n MonkeyOCR python=3.10 conda activate MonkeyOCR # 克隆代码库 git clone https://github.com/Yuliang-Liu/MonkeyOCR.git cd MonkeyOCR # 安装依赖(适配CUDA 12.4) pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 \ --index-url https://download.pytorch.org/whl/cu124 pip install -e . # 下载模型权重(HuggingFace) pip install huggingface_hub python tools/download_model.py一键解析PDF/图片
# 解析PDF(自动生成Markdown/JSON/布局可视化) python parse.py path/to/your.pdf -o ./output # 启动Gradio交互界面 pip install gradio==5.23.3 pdf2image==1.17.0 python demo/demo_gradio.py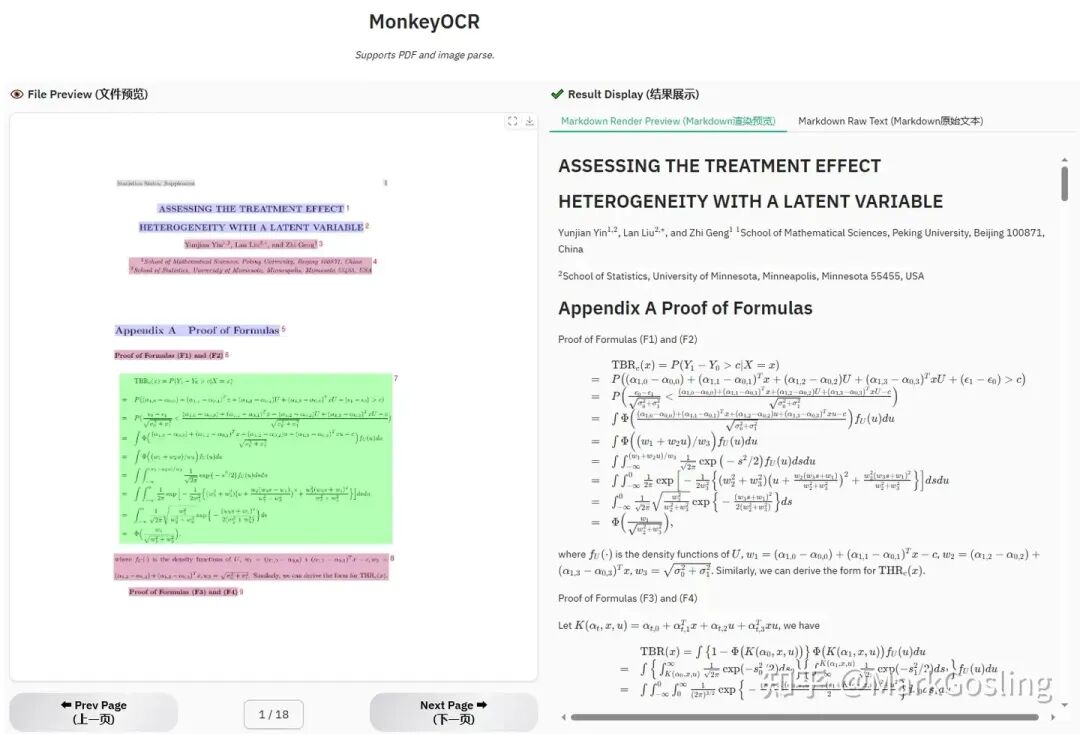
二. Surya - OCR、布局分析、阅读顺序、语言检测
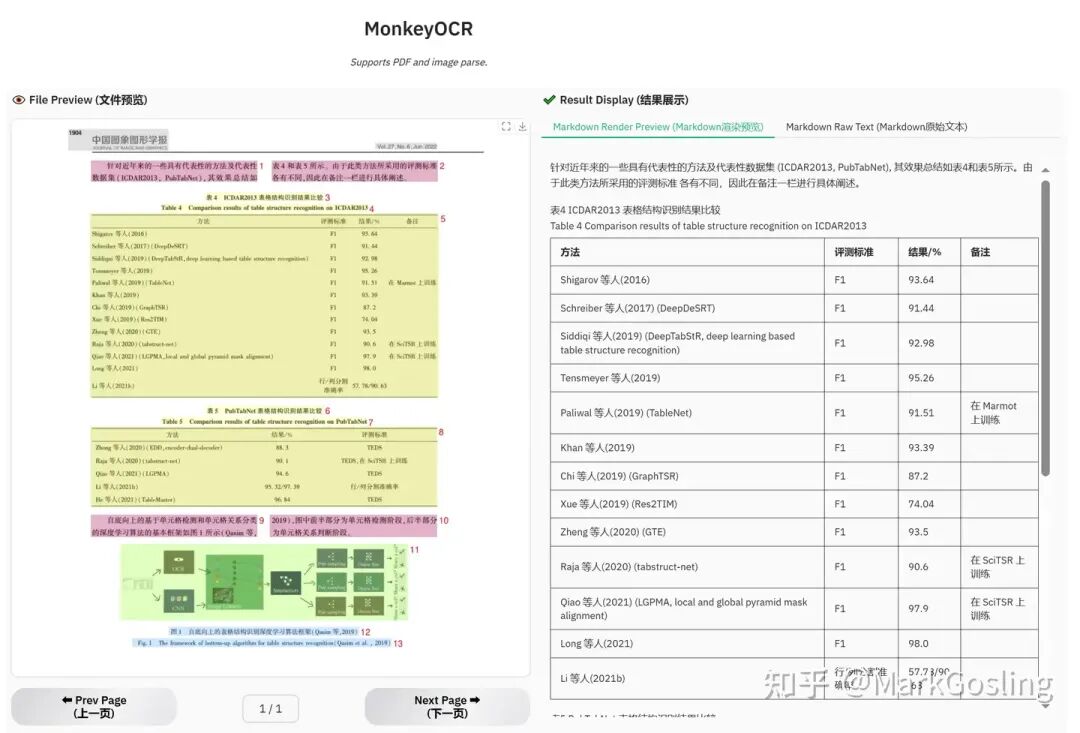
一款开源的OCR工具,性能炸裂,更新了 表格识别功能,它不仅能识别表格的行、列、单元格,还能识别旋转的表格和复杂的布局,而且支持90多种语言,简直无敌。
Surya 它通过先进的架构,尤其是在表格识别方面,性能优于当前的SoTA开源模型 Table Transformer 。目前GitHub 上收藏人数超过1万(10K),不仅免费开源,还能应用于商业场景。
-
github : https://github.com/VikParuchuri/surya

安装
pip install surya-ocrfrom PIL import Imagefrom surya.ocr import run_ocrfrom surya.model.detection import segformerfrom surya.model.recognition.model import load_modelfrom surya.model.recognition.processor import load_processor
image = Image.open(IMAGE_PATH)langs = ["en"] # Replace with your languagesdet_processor, det_model = segformer.load_processor(), segformer.load_model()rec_model, rec_processor = load_model(), load_processor()
predictions = run_ocr([image], [langs], det_model, det_processor, rec_model, rec_processor)机器学习算法AI大数据技术
搜索公众号添加: datanlp

长按图片,识别二维码
阅读过本文的人还看了以下文章:
整理开源的中文大语言模型,以规模较小、可私有化部署、训练成本较低的模型为主
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)