GPT-2 分析与实现
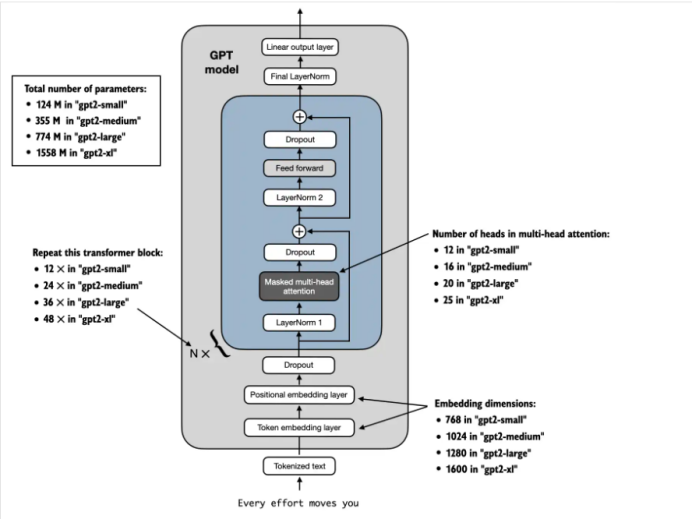
参考“从零构建大模型”这本畅销书,我们来分析一下GPT-2这个经典的大语言模型。下图是整个GPT-2框架图:
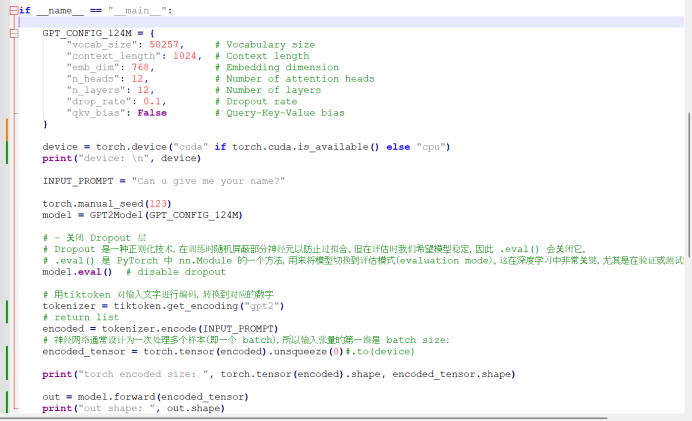
GPT_CONFIG_124M = {
"vocab_size": 50257, # Vocabulary size
"context_length": 1024, # context length
"emb_dim": 768, # Embedding dimension
"n_heads": 12, # Number of attention heads
"n_layers": 12, # Number of layers
"drop_rate": 0.1, # Dropout rate
"qkv_bias": False # Query-key-value bias
}
我们先看看pytorch里面nn.embedding, nn.Linear, nn.Parameter的区别和各自的作用。

1. 嵌入层(embedding dimensions):
Token embedding layer: 字典表里面每一个word代表一个emb_dim的一维向量,总共50257 words, 768维。Size: 50257 x 768 = 38,597,376 个系数
Positioning embedding layer: 为上下文每一个位置分配一个emb_dim的向量,总共1024个words, 768维。Size: 1024 x 768 = 786,432 个系数
我们来实现一下这个嵌入层:

调用一下
打印结果如下:

我们接着来看transformer层
2. transformer层
由n_layers(12)个transformer block组成。然后我们来分析每一个transformer block.
2.1 Multi-Head Attention多头注意力
先来看python如何实现吧
先定义一个multi-head attention类以及类参数
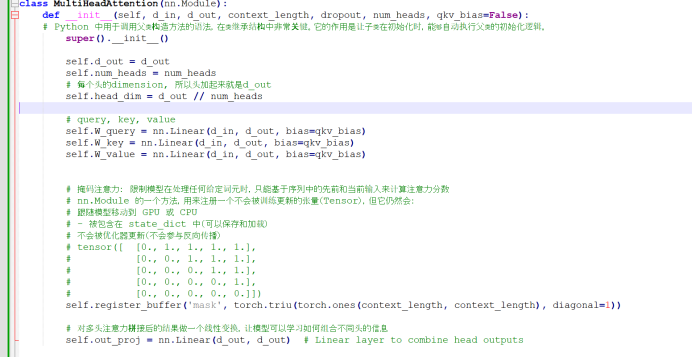
参数数量分析:
看的到有W_query, W_key, W_value, 三个参数需要训练,大小是d_in * d_out + bias(bias设置成了false, 那么数量就是0) = 768 * 768 = 589,824 个系数, 总共 3 * 589,824= 1769472个系数。
另外还有个投影层,out_proj, 其大小是d_out * d_out = 768 * 768 + 768 = 590,592 个系数。
再看下面的推理过程:
第一步: 输入的字符矩阵X 乘以 W_key, W_query, W_value系数

第二步:计算注意力分数 - attn_scores = queries * key
对于每个batch, 每个head, 其中每个头的query都要乘以所有上下文的key
attn_scores[num_tokens] = 0
for each query in queries:
attn_scores[query_index] += query * values
上面query dimension: {head_dim}, values dimension: {num_tokens, head_dim}

第三步: 用softmax()求注意力系数 - attn_weights
先用掩码把序列中比自己靠后的系数变成-inf
然后,用softmax(attn_scores / sqrt(keys.shape[-1]))
keys.shape[-1] == head_dim

第四步: 用求到的attn_weights * values 得到最后的结果

调用一下,

![]()
2.2 Layer norm 层归一化
层归一化的作用是,调整神经网络层的激活(输出),使其均值为0且方差为1.这种调整有助于加速权重的有效收敛,并确保训练过程的一致性和可靠性。
其python实现:

调用一下:


参数数量分析:
Scale 和shift: emb_dim, 就是768 x 2 = 1536 个系数
看GPT-2系统框架图,每一个transfromer block 有两个LayerNorm, 所以共1536 x 2 = 3072个系数。
2.3 Feedforward 前馈神经网络
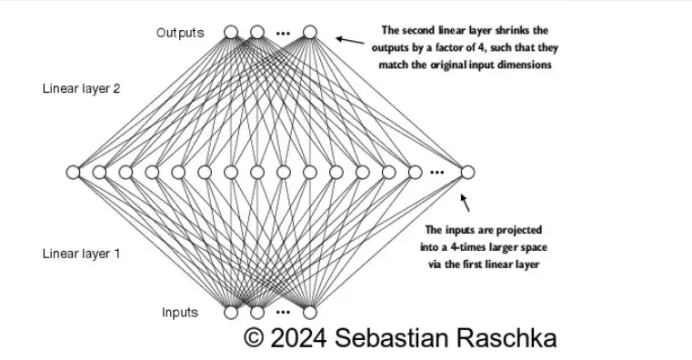
前馈神经网络整体构架:

线性层先把size 扩充4倍,然后激活函数,再用一个线性层缩减4倍至原大小。
其使用的激活函数:

先来定义一个Feedforward class:
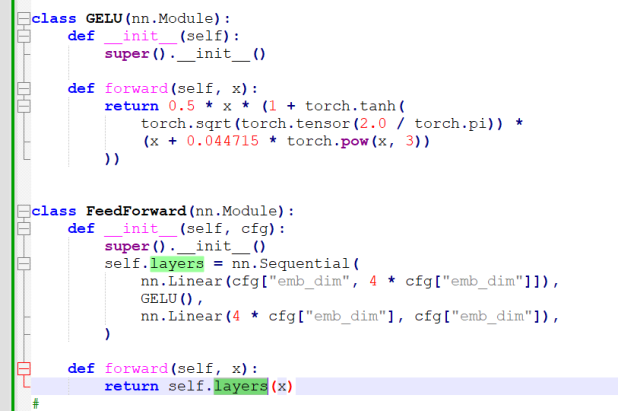
参数数量分析:
线性层一: emb_dim * (4 x emb_dim) + (4 x emb_dim), 就是768 x 4 x 768 + 4 x 768 = 2,362,368个系数
线性层二: (4 x emb_dim) * emb_dim + emb_dim, 就是768 x 4 x 768 + 768 = 2360064个系数
总共 4722432个系数。
2.4 Transformer block
先介绍一下快捷连接(shortcut connection),在深层网络中,梯度在反向传播时可能会逐层缩小(消失)或放大(爆炸),导致训练困难。残差连接提供了“捷径路径”,让梯度可以直接从后层传到前层,保持稳定的梯度流动。
在深度神经网络中,梯度通过链式法则逐层反向传播。如果每层的梯度都小于 1,那么多个层相乘后,梯度会迅速趋近于 0 ——这就是所谓的梯度消失。怎么实现的呢,残差连接的结构是这样的:y = x + F(x) 其中:x 是输入;F(x) 是子层的变换(比如注意力机制或前馈网络)
在前向传播中,残差连接让原始输入 x 直接参与输出计算,即使子层 F(x) 没有学到有用的变换,模型仍能保留原始信息。
这就像在一条复杂的高速公路上加了一条直通车道,哪怕主路堵了,信息也能顺畅通过。
单个transformer 块实现一下:
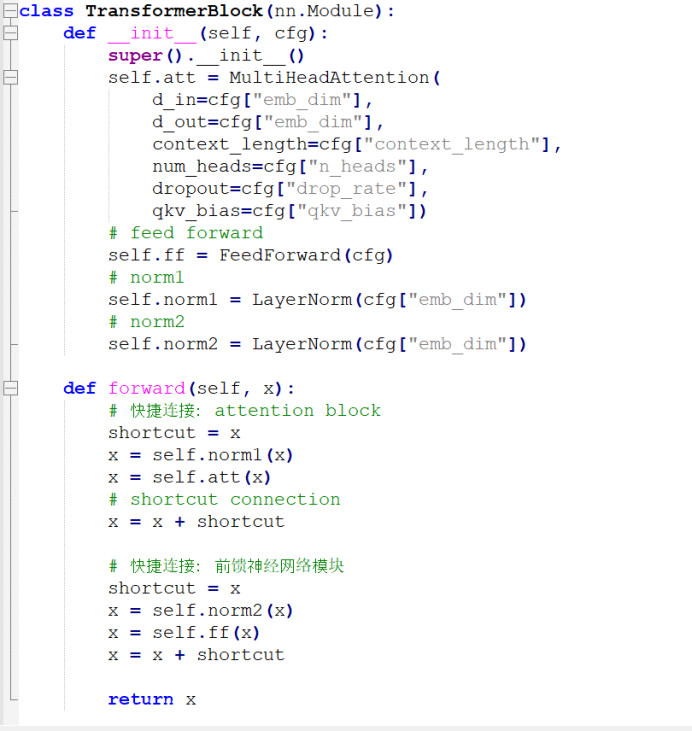
在GPT-2类里面添加多个transformer 块,每一层的output都是下一层的input:

3. 输出层
看GPT-2框架图,transformer 块之后还有一个最终层归一化和线性输出层。也是非常容易实现的。
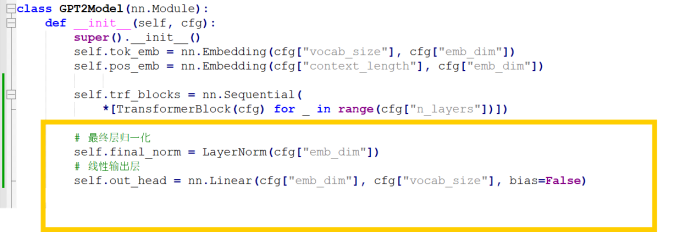
参数数量分析:
线性层: emb_dim * vocab_size, 就是768 x 50257 = 38597376个系数
归一化层:emb_dim * 2, 就是768 x 2 = 1536 个系数
4. 实现整个GPT-2模型
其实非常简单,就是把上面的嵌入层,transformer层,输出层顺序连起来就行。
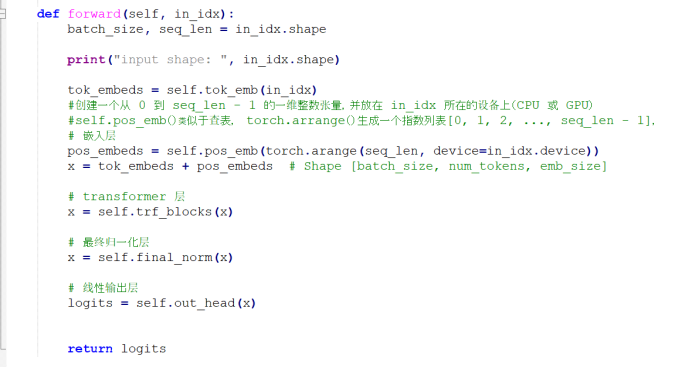
运行一下,

每一维有50257个元素,每个元素代表该词元ID的概率,找到最大概率的那个词元,我们就可以认为该词元就是我们要预测的word.
参数数量分析:
|
嵌入层 |
1 |
38,597,376 + 786,432 = 39,383,808 |
|
Transformer层 |
12 |
1769472 + 590,592 + 3,072 + 4722432 = 7085568 |
|
输出层 |
1 |
38597376 + 1536 = 38598912 |
总共: 39,383,808 + 12 * 7085568 + 38598912
= 39,383,808 + 85,026,816 + 38598912
= 163009536


但是,我们看到GPT-2讲的是1.24亿的参数,为什么我们算出来的是1.63亿呢?
参考书中4.6章节109页,原因在于原始的GPT-2使用了一个叫做权重共享的概念,将词元嵌入层作为输出层重复使用。也就是把self.out_head 和self.tok_emb共用(我不太明白在训练的时候如何用,一个是nn.embedding, 一个是nn.linear)。那么163009536减去38597376就是124,412,160个系数。如果每个系数是float类型的话,那么总共size是124,412,160 * 4 = 474.59 MB
5. 导入GPT-2权重
参考书中5.5节,可以从openAI网站下载GPT-2训练好的参数:
经过一系列的预处理(不详细看了,也是一个难点),然后把参数权重赋值给我们的GPT2 model。

![]()
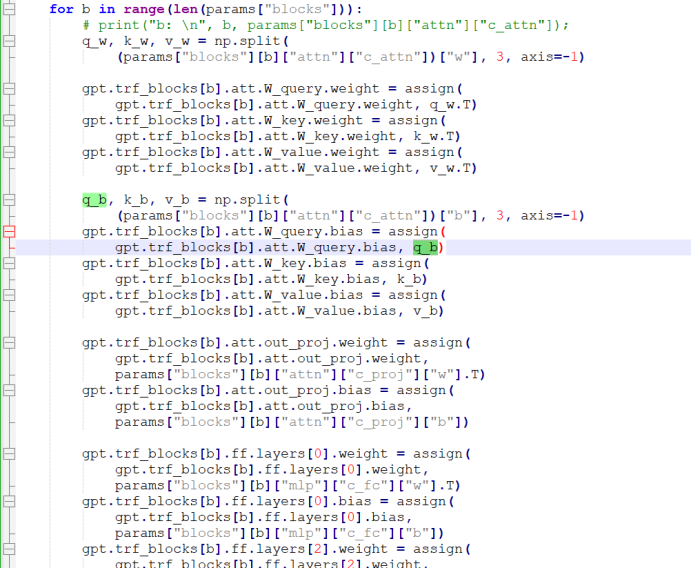
预处理之后,有5类参数:blocks (transformer层的参数), b,g(输出层的final_norm shift/scale), wpe (嵌入层的Positioning embedding layer), wte(嵌入层的Token embedding layer和输出层线性层out_head)。
![]()

看一下transformer layer, 一一对应。

时间原因,读取模型参数的具体细节没有深究,不过这个部分很重要,而且容易出错。以后有机会在细看吧。毕竟我们GPT-2只是一个基础的模型,换到其他模型,可能会有不同的组织形式,应该有流程图之类的东西,以后再说。
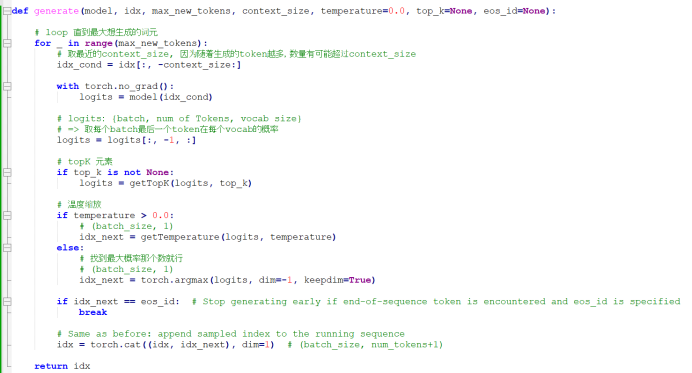
6. 文本生成
一般来说,当我们模型的输出每一维有50257个元素,每个元素代表该词元ID的概率,找到最大概率的那个词元,我们就可以认为该词元就是我们要预测的word。但是我们不想要确定性那么大,我们会添加概率选择过程,让其他非最大概率的词元有几率生成出来。
首先,我们通过Top-k采样,选出概率最大的k个元素。然后用-inf替换所有未选择的logits。因此在计算softmax值时,非前k词元的概率分数为0,剩下的概率综合为1。
具体实现如下:

我们通过一个叫温度缩放的概念,进一步控制发布和选择过程。其通过将生成的50257维的logic除以一个大于0的数(temperature),将概率分别改变。温度大于1,词元概率变得均匀发布,小于一,概率发布更集中。比如说,一个概率发布{0.1, 0.3, 0.6}, 如果温度缩放大于1, 那么会变得{0.2,0.35, 0.45}。温度缩放小于1,那么会变得{0.05, 0.1, 0.85}。
其实现如下:

整体实现:
没有load GPT-2权重效果:
![]()
有load GPT-2权重效果:
![]()
看起来效果还行。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)