【基于Transformer的预训练模型】BERT的掩码语言建模和GPT的自回归生成机制,基于HuggingFace的Transformers库,整合了多种预训练模型,支持PyTorch等框架
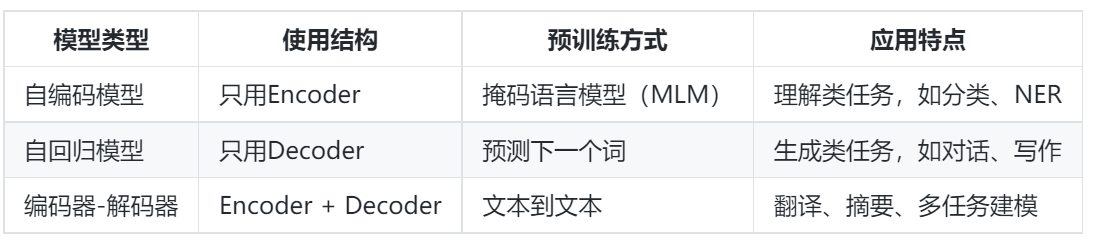
本文介绍了Transformer模型的三种主要应用方式:仅用编码器(如BERT)适合文本理解任务;仅用解码器(如GPT系列)擅长文本生成;同时使用编解码器(如T5)适用于翻译、摘要等任务。详细解析了BERT的掩码语言建模和GPT的自回归生成机制,并介绍了HuggingFace的Transformers库,该库整合了多种预训练模型,支持PyTorch等框架,通过pipeline接口可快速实现文本分类
一、Transformer的三种使用方式
📍Transformer结构可以根据任务需求灵活裁剪或组合,其在预训练模型中的三种主要使用方式如下:
-
只用编码器(Encoder)部分:自编码预训练语言模型
- 代表模型:BERT、RoBERTa、ALBERT
- 优势:擅长理解上下文,适合分类、序列标注等理解类任务。
-
只用解码器(Decoder)部分:自回归预训练语言模型
- 代表模型:GPT系列(GPT-2、GPT-3、GPT-4)
- 优势:擅长生成文本,适合对话系统、文本生成等生成类任务。
-
同时使用编码器和解码器:编码器-解码器结构的预训练语言模型
- 代表模型:T5(Text-To-Text Transfer Transformer)、mT5、BART
- 优势:统一输入输出为文本,适合多种任务(如摘要、翻译、问答等)。
二、自编码预训练模型
1. 什么是自编码预训练语言模型
自编码预训练语言模型(如BERT)利用上下文信息进行掩码预测,本质上是一种“填空”任务。它通过掩盖输入中的某些词,然后训练模型预测被掩盖的词,从而学习词与词之间的关系。
- 特点:
- 输入和输出的长度相同
- 适合处理句子级理解任务
- 预训练目标:Masked Language Modeling(MLM)
2. BERT模型结构
📍BERT(Bidirectional Encoder Representations from Transformers)由多层Transformer Encoder堆叠而成:
-
输入格式:
-
[CLS]token:分类任务使用 -
[SEP]token:区分句子 -
Token Embedding + Segment Embedding + Position Embedding
-
网络结构:
-
多层双向Transformer编码器
-
多头注意力机制 + 残差连接 + 层归一化
3. BERT预训练任务
- Masked Language Model(MLM):
- 随机掩盖输入的15%词语,让模型预测原始词语
- Next Sentence Prediction(NSP):
- 判断两个句子是否为连续句子(已被RoBERTa等模型移除)
4. BERT的应用方式
BERT可以通过两种方式应用到下游任务:
- 文本分类任务(如情感分析),在
[CLS]token后接一个全连接层进行分类 - 命名实体识别(NER),对每个token输出接线性层 + CRF,进行序列标注
- 机器阅读理解
三、自回归预训练模型
1. 自回归预训练语言模型
📍自回归模型采用从左到右逐词预测的方式进行训练。每一步的输入是前面生成的词,模型预测下一个词。
- 特点:
- 单向上下文建模(通常是左到右)
- 擅长生成流畅的文本
- 预训练目标:预测下一个词(Next Token Prediction)
2. GPT-1模型结构
GPT-1(Generative Pre-trained Transformer 1)是OpenAI在2018年提出的首个基于Transformer架构的大型语言模型。它的核心设计理念是使用Transformer的Decoder部分(进行了少量修改)来构建一个单向的、自回归的语言模型,专门用于生成文本。
📍以下是GPT-1网络结构的关键组成部分和特点:
-
核心架构:Transformer Decoder (Modified)
- GPT-1没有使用完整的Transformer架构(包含Encoder和Decoder),而是只使用了Transformer的Decoder部分,并对其进行了简化。
- 关键修改: 移除了原始Transformer Decoder中用于接收Encoder输出的第二个“Encoder-Decoder Attention”子层。这是因为GPT-1在预训练阶段是一个纯粹的无监督语言模型,它只需要根据上文预测下一个词,不需要处理来自另一个序列(如源语言句子)的信息。
-
堆叠的Decoder Blocks:
- 整个模型由 N 个相同的Decoder Block 堆叠而成(在GPT-1论文中,N = 12)。
- 每个Decoder Block包含两个核心子层:
- a. Masked Multi-Head Self-Attention:
- b. Position-wise Feed-Forward Network:
- c. 残差连接和层归一化:
-
输入表示:
- Token Embedding: 输入文本首先被分割成子词单元(如Byte Pair Encoding - BPE)。每个子词单元被映射成一个高维的稠密向量(Embedding)。
- Positional Embedding: 由于Transformer本身没有内置的顺序信息,需要额外添加位置编码来表示每个词在序列中的位置。GPT-1使用的是可学习的位置嵌入向量(与Transformer原论文中的固定正弦/余弦编码不同)。每个位置都有一个对应的向量,这些向量会在训练过程中学习得到。
- 输入向量: 对于序列中的每个位置
i,最终的输入表示是Token Embedding(i) + Positional Embedding(i)。
-
输出层:
- 最后一个Decoder Block的输出是一个高维向量序列(每个位置对应一个向量)。
- 这个序列会通过一个线性投影层(通常称为LM Head),将每个位置的向量映射到整个词汇表大小的维度。
- 然后应用 Softmax 函数,将线性层的输出转换为一个概率分布。这个分布表示在给定所有上文的情况下,下一个词是词汇表中每个词的概率。
总结GPT-1结构的关键特点:
- 单向性: 通过Masked Self-Attention实现,只能利用左侧的上文信息。
- 自回归: 预测下一个词时依赖于之前生成的所有词。
- Transformer Decoder Based: 核心是堆叠的、修改过的Transformer Decoder Blocks。
- 无Encoder-Decoder Attention: 移除了原始Decoder中用于跨序列注意力的部分。
- 位置嵌入: 使用可学习的位置嵌入。
- 深度堆叠: 由多个(12层)相同的Block组成。
四、Seq2Seq预训练模型
1. 什么是Seq2Seq预训练模型
📍Seq2Seq模型同时使用Transformer的编码器和解码器部分。它将输入序列编码为一个表示,然后由解码器将其解码成目标序列。
- 优势:
- 能同时理解输入文本与生成目标文本
- 广泛用于翻译、摘要、问答、代码生成等任务
2. 代表模型:T5(Text-To-Text Transfer Transformer)
T5统一了所有NLP任务为“文本到文本”格式:
-
输入:“任务描述:输入文本”
-
输出:“目标文本”
-
模型结构:
-
Encoder:将输入文本编码为隐表示
-
Decoder:根据表示生成输出文本
-
预训练目标:
-
采用“Span Corruption”策略进行训练(掩盖连续片段)
-
应用任务:
-
文本摘要、问答、文本生成、翻译、情感分析等
五、什么是 Transformers 库?
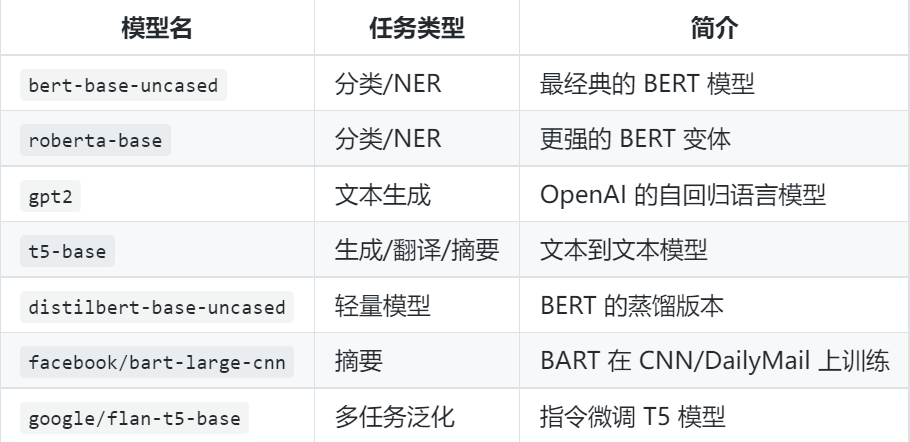
Transformers 是 Hugging Face 公司推出的一个开源 Python 库,提供了对 预训练语言模型(如 BERT、GPT、T5、RoBERTa 等) 的便捷访问和使用接口。它支持:
- 多种 NLP 任务:文本分类、命名实体识别、问答、文本生成等;
- 多种深度学习框架:支持 PyTorch、TensorFlow 和 JAX;
- 使用简单、模型丰富、社区活跃。
支持的预训练模型举例
Pipelines(管道接口)
封装了常见任务的使用流程,适合快速原型开发。
支持的任务包括:
sentiment-analysistext-classificationquestion-answeringtranslationtext-generationsummarizationtoken-classification(如命名实体识别)
from transformers import pipeline
# 快速使用 pipeline 执行情感分析任务
classifier = pipeline("sentiment-analysis")
result = classifier("I love using Hugging Face Transformers!")
print(result) # [{'label': 'POSITIVE', 'score': 0.9998}]Tokenizer(分词器)
- 将文本转为模型输入的 token ids;
- 支持批量编码、解码、添加特殊符号等
tokens = tokenizer("Transformers are amazing!", return_tensors="pt") print(tokens)四、使用案例:文本分类
from transformers import AutoTokenizer, AutoModelForSequenceClassification import torch model_name = "distilbert-base-uncased-finetuned-sst-2-english" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForSequenceClassification.from_pretrained(model_name) # 输入文本 inputs = tokenizer("I hate this movie.", return_tensors="pt") outputs = model(**inputs) # 获取预测类别 logits = outputs.logits predicted_class = torch.argmax(logits).item() print("Predicted label:", predicted_class)致谢˚༉‧✰༶🎐
谢谢大家的阅读,还有很多不足支出,欢迎大家在评论区指出,如果我的内容对你有帮助,可以点赞 , 收藏 ,大家的支持就是我坚持下去的动力!
“请赐予我平静,去接受我无法改变的 ;赐予我勇气,去改变我能改变的。”


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)