大模型直接优化偏好DPO学习笔记
DPO,DPOP,TDPO,KTO
·
【如果笔记对你有帮助,欢迎关注&点赞&收藏,收到正反馈会加快更新!谢谢支持!】
往期:
大模型RLHF强化学习笔记(一):强化学习基础梳理Part1_大模型强化学习入门-CSDN博客
大模型RLHF强化学习笔记(二):强化学习基础梳理Part2-CSDN博客
大模型RLHF强化学习笔记(三):RLHF介绍,PPO训练技巧-CSDN博客
大模型RLHF强化学习笔记(三):RLHF介绍,PPO训练技巧-CSDN博客
一、DPO(Direct Preference Optimization)
- 为什么DPO不是强化学习算法?DPO直接优化了RLHF的强化学习部分,没有显示的策略探索
- RLHF的问题(以PPO为例):
- PPO分两阶段训练:step1 用偏好数据训练Reward Model,step2 训练Critic和Policy【信息损失 → DPO直接用偏好数据训练策略】
- PPO训练资源需求量大:需要四个模型(Actor,Critic,Reward和Reference)都是基于LLM(经SFT训练)初始化或者改进,训练和推理需要大量的计算资源【资源消耗大,且误差累积 → DPO去掉Reward和Critic】
- DPO公式理解
奖励:策略模型(policy_model)与参考模型(ref_model)的对数概率差异(要求reward_chosen - reward_rejected > 0),转化为二元交叉熵损失
参数 β:控制策略更新的激进程度,类似于温度系数;β 值较大时,KL散度的惩罚增强,策略几乎紧贴参考策略 πref
- 如何理解DPO?
- 优化目标:win/chosen的回答概率上升,lose/reject的回答概率下降
- DPO是用优势函数来衡量人类偏好,而不是奖励
- DPO也可以看成一个正样本和一个负样本的对比学习
二、DPO的改进算法
2.1 DPOP
- DPO的问题:正样本和负样本被采样的概率同时变低(reward分数在同时下降),虽然负样本降得更多
- DPOP如何解决:添加正则项
- 当模型对“好答案”拟合不足时(chosen在Ref模型的采样概率比在Policy模型高),该正则项鼓励模型更多地学习“好答案” → 加正则限制策略更新
- 当模型对“好答案”拟合较好时,着重降低“坏答案”的采样概率
2.2 TDPO
- TDPO引入了前向KL散度约束,而不是DPO中使用的反向KL散度
- 前向KL散度:以SFT(Ref) Model计算采样概率,使策略分布 πθ 尽量集中在目标分布πtarget 的高概率区域 → 适用于需要高精度的任务
- 反向KL散度:以Policy Model计算采样概率,使策略分布 πθ 覆盖目标分布 πtarget → 适用于需要生成多样化样本的任务

2.3 KTO(Kahneman-Tversky Optimization)
- DPO的问题:
- 要收集大量的成对的偏好数据
- 对坏输出更敏感
- KTO的改进点:
- 直接优化模型生成的效用,而不是最大化偏好的对数似然
- 只需判断输出对于给定输入是可取的还是不可取的(只需要二元反馈)
- 前景理论(Prospect Theory):人在面对不确定时评估收益和损失的特点 1.依赖心理参考点 2. 损失厌恶 3. 非线性价值感知(小损失比小收益更敏感)
- KTO价值函数实现:
- 分段logits
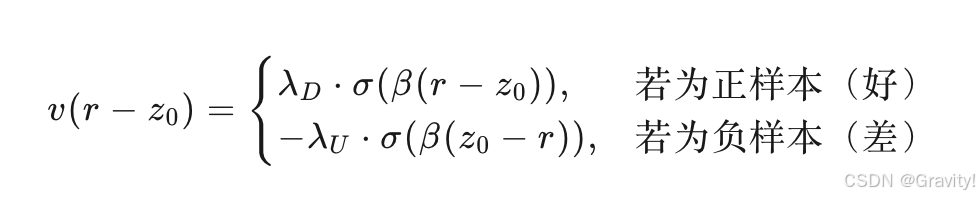
λD 和 λU:分别表示“对正向提升的敏感度”和“对负向惩罚的敏感度”,通常 λU>λD,体现损失厌恶 - 参考点选择:在同一个microbatch中对输出进行移位,以产生不匹配的样本对,为同一个microbatch的所有样本估计一个共享的参考
- 分段logits
- HALOs 目标函数
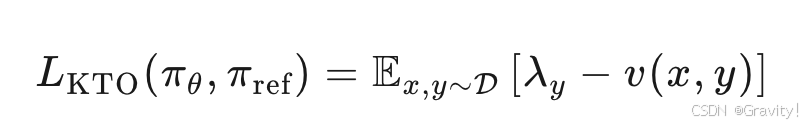
- KTO优势
- 更好地模拟人类的决策行为
- 真实地反映人类的损失厌恶和对不同结果的敏感度

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)