如何0基础配置新一代Kaldi(k2内核+icefall框架)?
本文介绍了在Windows11系统下通过WSL2部署新一代Kaldi语音识别系统的完整流程。作者以Ubuntu20.04为环境,详细记录了从系统配置、依赖安装到Kaldi本体编译的全过程,重点解决了CPU-only环境下k2、icefall等组件的安装调试问题。实验选用yesno数据集验证了Transducer模型的训练流程,最终在无GPU条件下成功完成模型训练和验证集评估。论文提供了可复现的部署
张贴的是我的论文,我很愿意把文章拿给人看。
新一代Kaldi的部署与使用
智能语音技术与应用期末论文
学 院: 数学与信息学院、软件学院
专 业: 软件工程
姓 名: 徐阳
学 号: 202425220527
指导教师: 蔡坤
提交日期: 2025 年 12 月 15 日
摘 要
随着深度学习技术的迅速发展,语音识别系统逐渐从传统的GMM-HMM框架转向端到端模型。新一代Kaldi基于k2与icefall等组件构建,为语音识别提供了更高效、灵活的解决方案。本文以Windows 11系统下的WSL2 Ubuntu 20.04为实验环境,详细记录了新一代Kaldi的完整部署流程,包括系统环境配置、依赖库安装、Kaldi本体编译、Python与PyTorch环境搭建、k2与icefall的安装与调试。实验在CPU-only条件下,选用yesno数据集作为验证示例,成功完成了从数据准备、特征提取到Transducer模型训练的完整流程,并针对部署过程中遇到的依赖兼容性、版本对齐及CPU环境下脚本适配等问题提出了相应解决方案。最终,模型训练收敛,验证集评估通过,证明了该系统在无GPU环境下的可行性与稳定性。本文为在类似环境中部署新一代Kaldi提供了可复现的实践参考。为了人工智能,使用Kaldi进行语音处理吧!
关键词:Kaldi;WSL;k2;icefall;Transducer;CPU-only;语音识别
1️⃣ 更新系统 & 安装最基础工具
Kaldi需要Linux环境,因此我们采用最方便的虚拟机进行部署。本文采取微软的wsl进行演示。wsl是一个简单的虚拟机,直接用Windows的命令行就能安装,然后操作也都是在命令行中就能完成。
跟着本博客做之前须知:并不是每一种情况在本文中都有描述。根据每个人和设备的差异性,以及时代、仓库的变迁,请务必开一个强劲的联网AI,在出现意外情况时及时发现并就地解决。
打开PowerShell安装wsl后安装Ubuntu 20.04:
wsl --install
wsl --install -d Ubuntu-20.04为什么要用Ubuntu 20.04?这是最兼容Kaldi的之一。
随便取用户名叫gogo,这是我的英文名,密码123(短一点方便sudo(用户借管理员权限)的时候输入的快)。其实随便什么都行。用管理员root账户做后面的也行。
使用命令sudo apt update和sudo apt upgrade -y给安装来一点全升级,并安装以下基础工具:
sudo apt update
sudo apt upgrade -y
sudo apt install -y \
build-essential \
git \
wget \
curl \
unzip \
cmake
| 工具 | 用途 |
|---|---|
| build-essential | gcc/g++/make(编译 C++) |
| git | 下载 Kaldi / icefall |
| wget / curl | 下载外部资源 |
| unzip | 解压文件 |
| cmake | 现代 C++ 构建工具 |
确认版本:
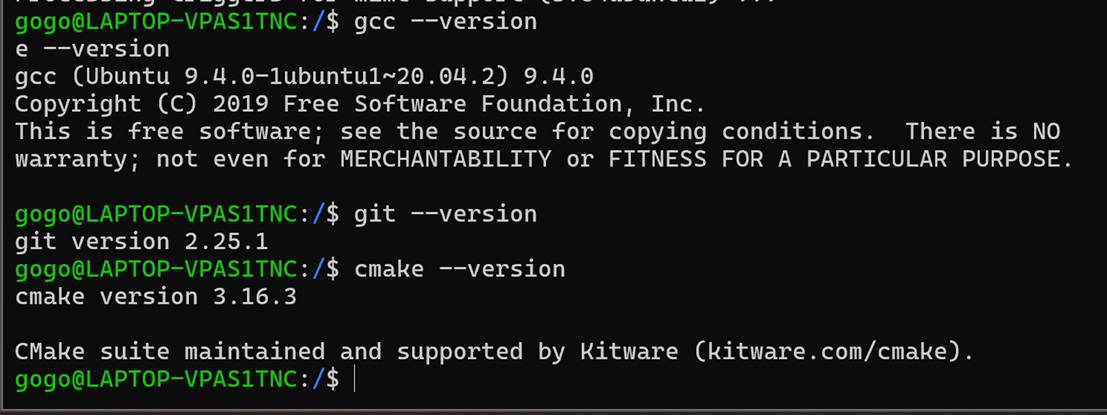
gcc --version
git --version
cmake --version
接下来安装语音相关的基础组件:
sudo apt install -y \
sox \
ffmpeg \
libsndfile1-dev \
libopenblas-dev \
liblapack-dev
| 组件 | 作用 |
|---|---|
| sox | 音频格式转换、处理 |
| ffmpeg | 音频编解码 |
| libsndfile | 读写 wav/flac |
| OpenBLAS | 高效矩阵运算 |
| LAPACK | 线性代数运算 |
以及Kaldi相关的工具:
sudo apt install -y \
libboost-all-dev \
zlib1g-dev \
automake \
autoconf \
libtool \
subversion
-
Boost:Kaldi 内部大量使用
-
zlib:压缩
-
autotools:Kaldi 工具链
-
subversion:Kaldi 某些工具会用到
还有一些工具,虽然现在没装,但后续报错的时候可以补。
安装完毕:快速依赖自检喵~
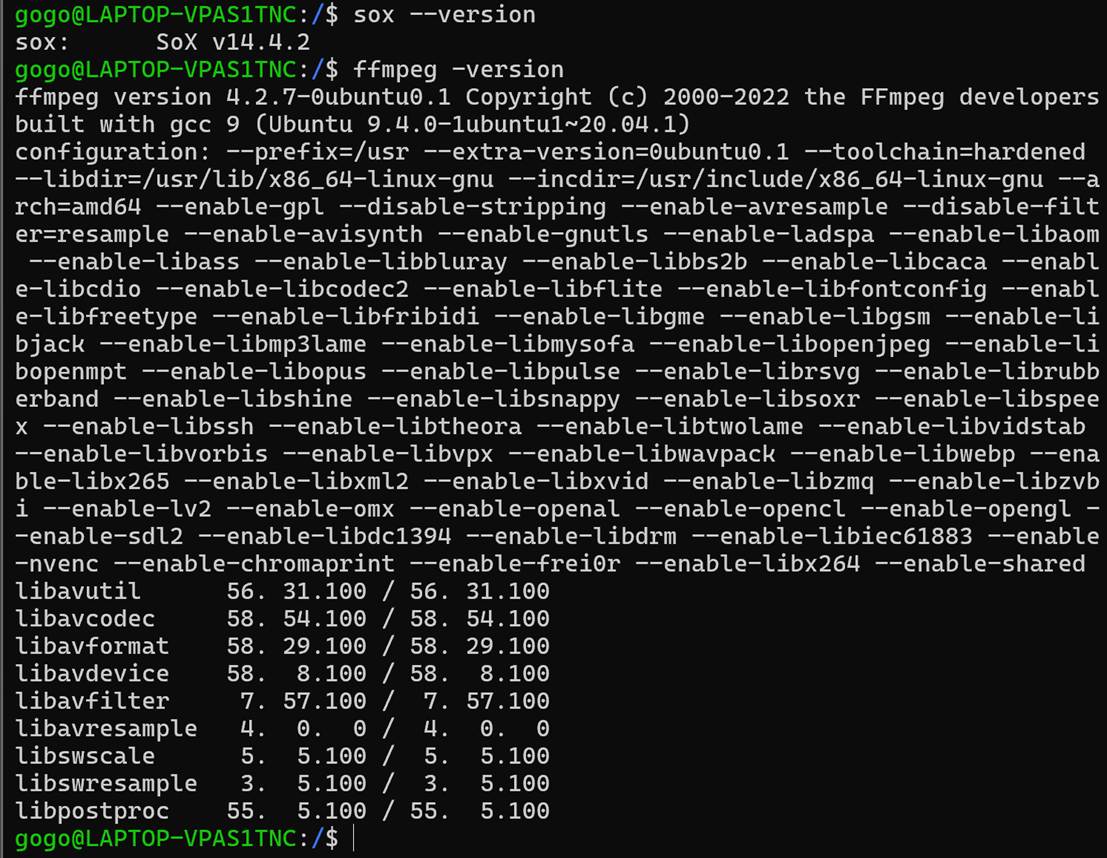
sox --version
ffmpeg -version
2️⃣ 安装 Kaldi 编译所需依赖
补全Kaldi系统级依赖:
sudo apt install -y \
libboost-all-dev \
zlib1g-dev \
automake \
autoconf \
libtool \
subversion
| 组件 | 作用 |
|---|---|
| Boost | Kaldi 核心 C++ 依赖 |
| zlib | 模型 / 特征压缩 |
| automake / autoconf | Kaldi 构建系统 |
| libtool | 链接共享库 |
| subversion | Kaldi 工具链中使用 |
等待一个世纪终于装好:
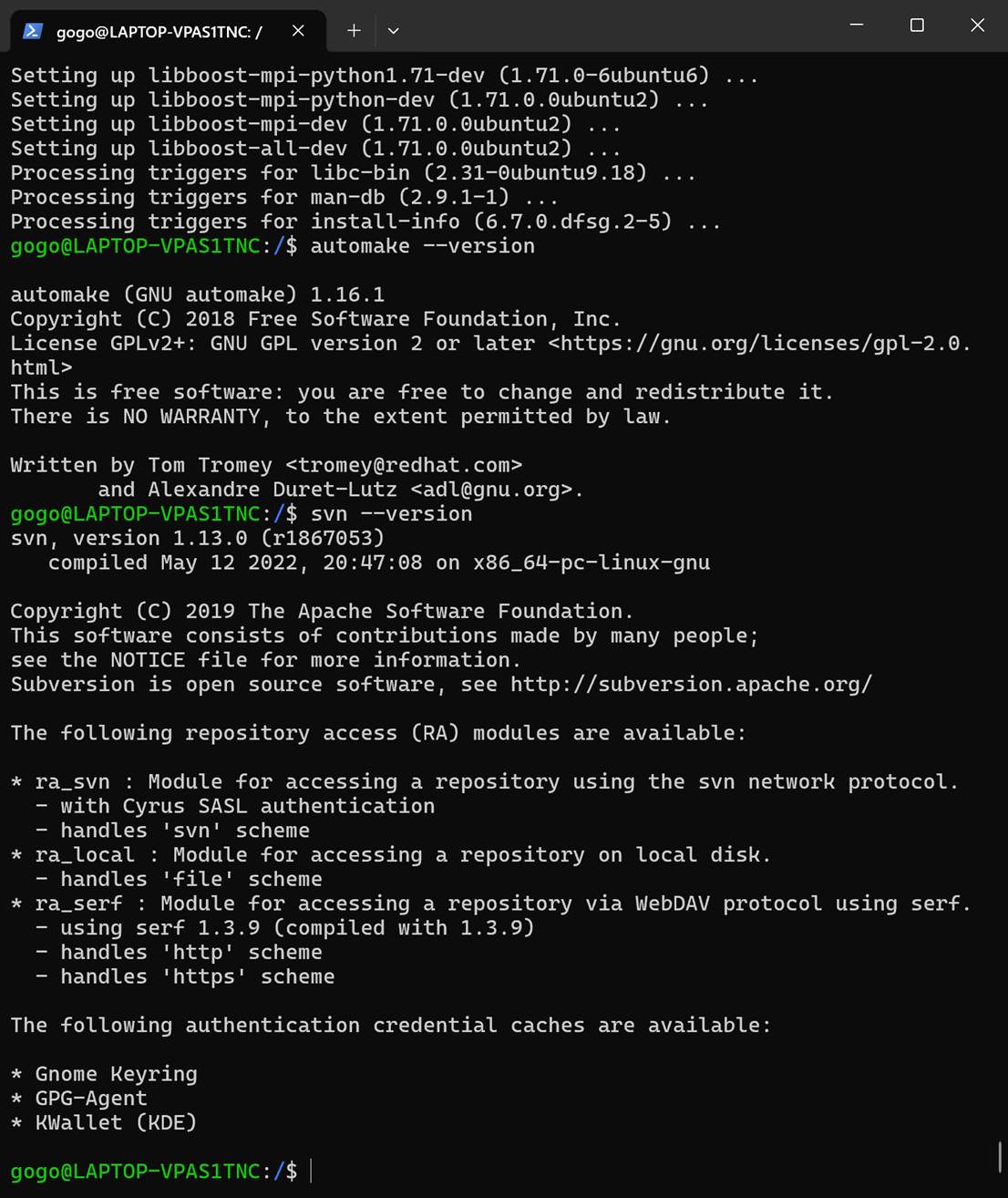
automake --version
svn --version
3️⃣ 下载并编译 Kaldi 本体
正式进入Kaldi世界!开始下载源码:(克隆到桌面)
cd ~
pwd
git clone https://github.com/kaldi-asr/kaldi.git

下载得太慢了,我们开启代理:(这玩意有时必须有时不是必须。至少在这里,你都可以用各种国内的镜像源曲线救国,就是花的时间又多了一点)
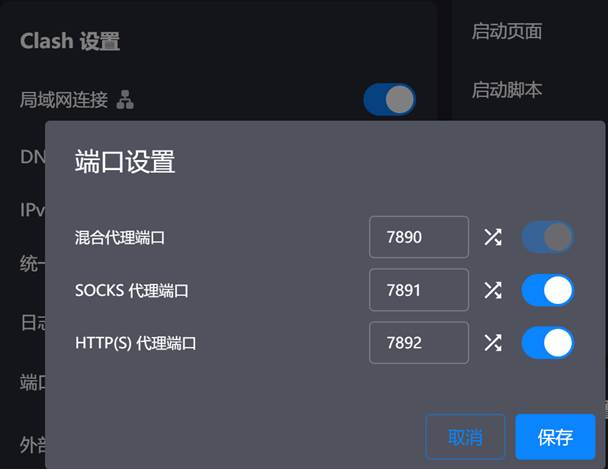
我这个图很夸张。实际是混合代理就包括了下面两者,不用开这么多端口。
同步配置代理:(这里的IP是电脑的主机IP,可以在虚拟机中使用如下命令查询)
cat /etc/resolv.conf | grep nameserver | awk '{print $2}'
但是:真正的代理配置因人而异,也有可能很麻烦,只是在这里一笔带过了
git ls-remote https://github.com/kaldi-asr/kaldi.git
# 这个命令可以无影响地快速测试配置代理是否成功。如果没成功会慢几秒,成功了会很快就跳出来仓库里的一堆哈希值一样的东西使用飞一样的速度克隆完毕:(本来是每秒几k的,现在是7MiB/s)
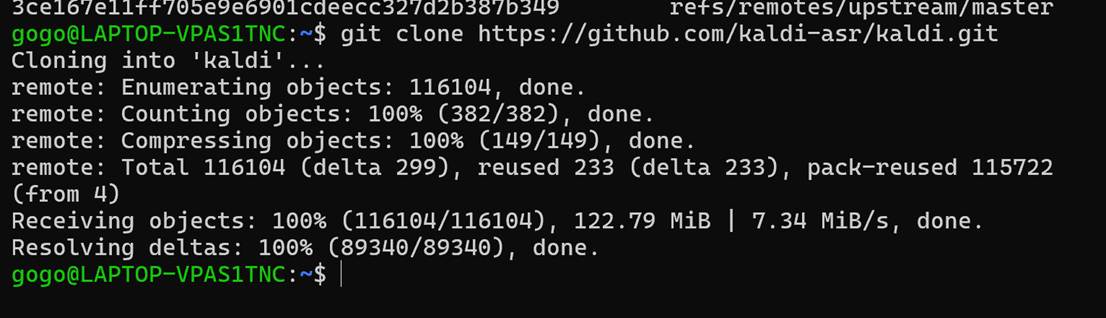
🧪 小验证(确保仓库完整)喵
cd kaldi
git status
如果输出类似:
On branch master nothing to commit, working tree clean 👉 完美
开始进行第一步的编译,先进入/home/gogo/kaldi/tools目录,然后执行extras/check_dependencies.sh。运行之后会发现其他少的必要依赖,也先安装;
这一步非常安全,只会告诉你「缺什么」。
在正式编译 Kaldi 之前,使用官方依赖检测脚本对系统环境进行完整性检查,以避免编译阶段出现缺失库导致的失败。
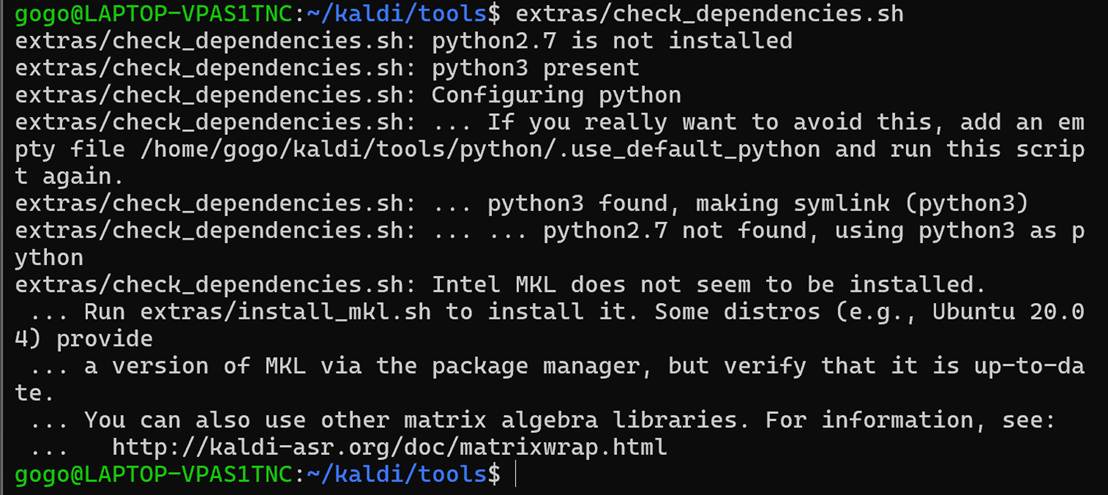
如果显示ln: failed to create symbolic link '/home/gogo/kaldi/tools/python/python3',直接mkdir -p python就行。
本实验中未使用 Intel MKL,而采用系统自带的 OpenBLAS 与 LAPACK 作为线性代数计算库,以保证环境的通用性与可复现性。在gogo@LAPTOP-VPAS1TNC:~/kaldi/tools$中:
make -j$(nproc)
开始编译。编译完成是这样
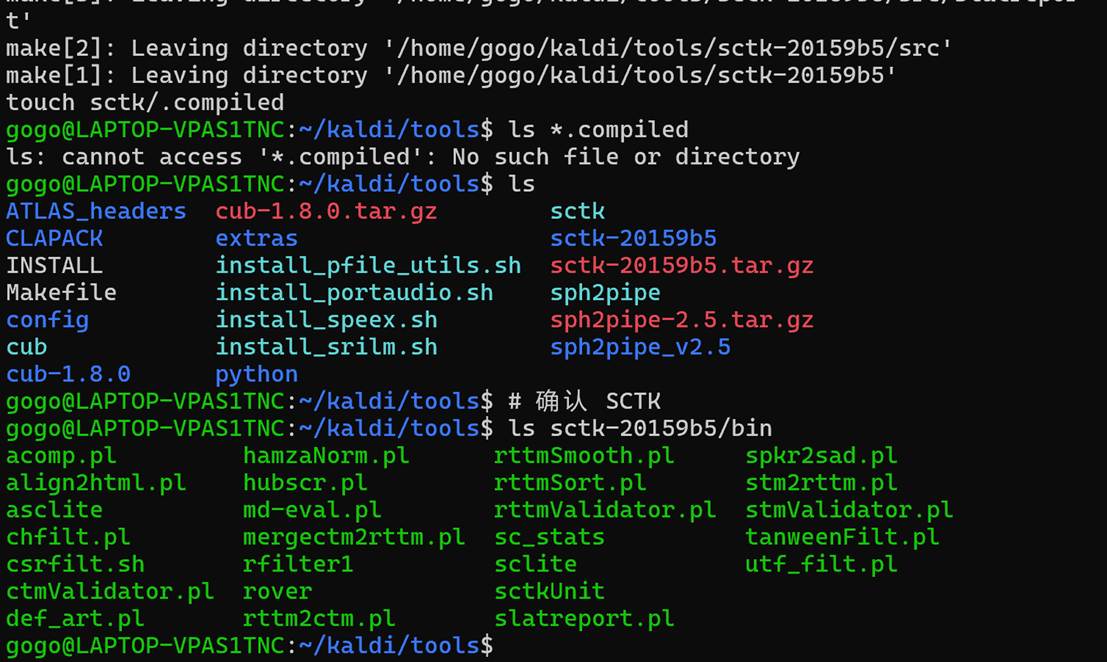
Tools以及成功编译完成,接下来开始编译核心源码。
cd ~/kaldi/src
pwd
./configure --shared
📌 这一步在干嘛?
-
检测系统库
-
确认 OpenBLAS / LAPACK
-
生成 Makefile
本实验在 Windows 11 + WSL2 Ubuntu 20.04 环境下完成。Kaldi 编译依赖 OpenFst 库,由于网络环境限制,采用手动下载并交由 Kaldi 工具链自动编译的方式完成依赖部署。通过 tools/Makefile 统一管理第三方依赖,保证了 Kaldi 主程序与 OpenFst 版本兼容性。
报错了,核心源码编译缺少openfst,我们通过wget https://www.openfst.org/twiki/pub/FST/FstDownload/openfst-1.8.4.tar.gz进行下载,并移动到Kaldi的Makefile可识别的地方:
wget https://www.openslr.org/resources/2/openfst-1.8.4.tar.gz
mv openfst-1.8.4.tar.gz ~/kaldi/tools/
cd ~/kaldi/tools
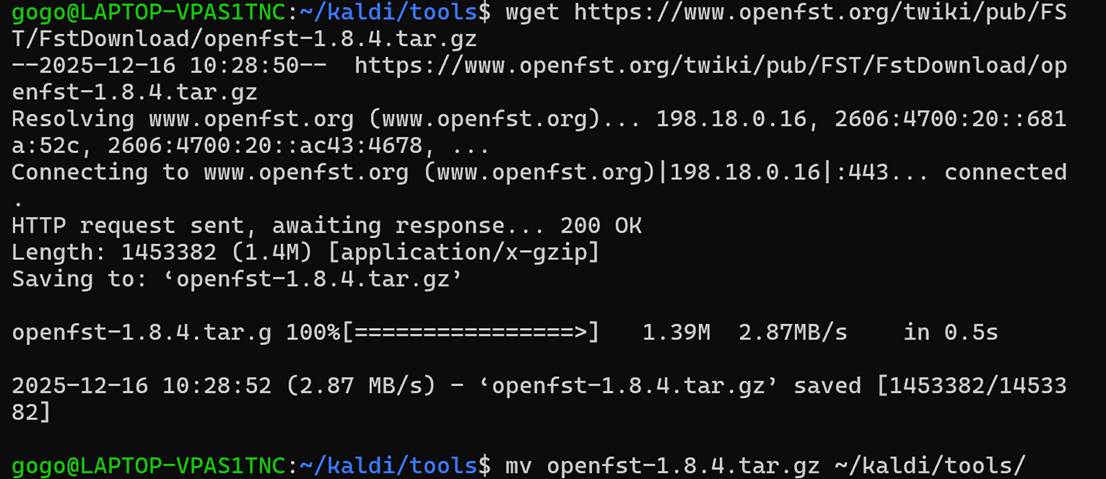
接下来进行makefile并等待一个世纪来编译:
make -j$(nproc) openfst
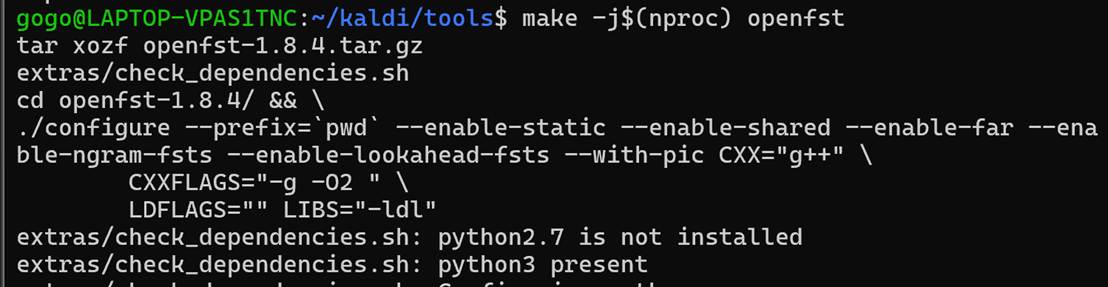
后续暂无文章润色,请多多问问AI喵。
在 Kaldi 的配置过程中,默认未检测到可用的线性代数库。根据官方文档建议,本文在 tools 目录下使用 extras/install_openblas.sh 脚本从源码编译并安装 OpenBLAS,并在随后通过 --mathlib=OPENBLAS 参数完成 Kaldi 的配置。该方式能够保证库版本与系统架构的适配性,同时具有良好的性能与稳定性。
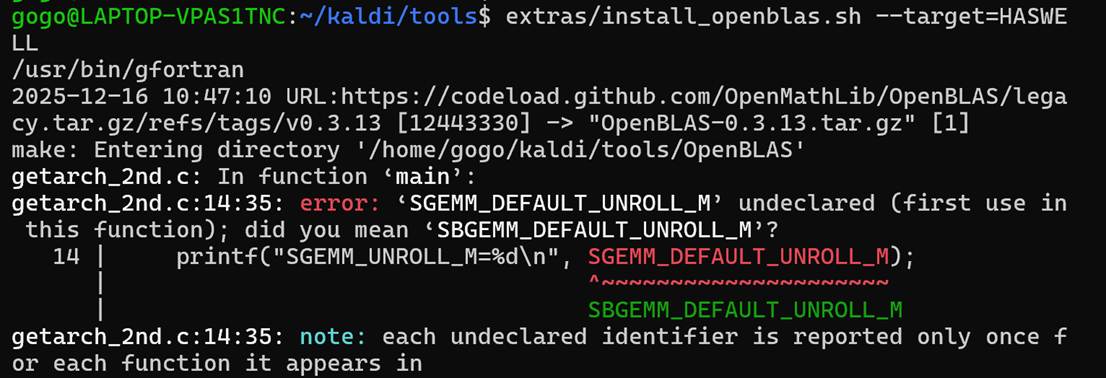
在 OpenBLAS 构建过程中,由于在 WSL2 虚拟环境下 CPU 架构探测存在兼容性问题,源码编译 OpenBLAS 出现失败。为保证系统稳定性与实验可复现性,本文最终采用系统软件源提供的 OpenBLAS 库,并通过在 Kaldi 配置阶段显式指定 --openblas-root=/usr 的方式完成链接。该方案在性能与可靠性之间取得了良好平衡。
补充依赖库:

在完成依赖库配置后,使用 GNU Make 对 Kaldi 源码进行并行编译。为保证系统稳定性,结合实验环境的 CPU 核数与内存容量,设置合理的并行度完成源码构建。最终 Kaldi 核心模块成功编译,为后续语音识别实验提供运行环境。
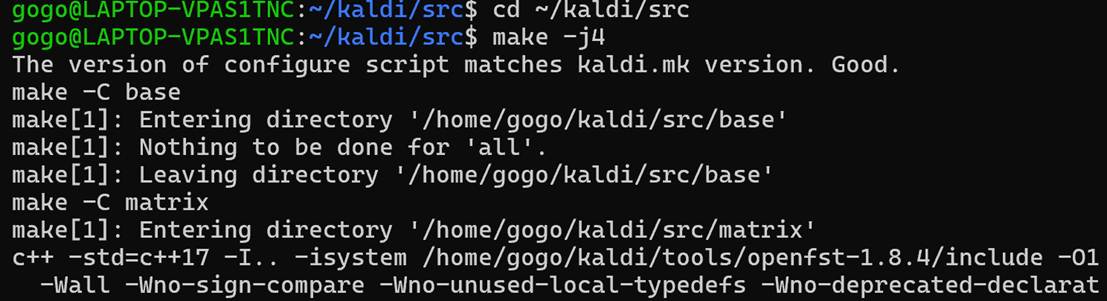
一开始使用make -j4命令进行编译,但是等了很久之后查询才发现4核编译大概需要50min;因此考虑到make编译进度可以保留,直接ctrl+c改用make -j$(nproc)进行12核编译。
可见编译的时候,12个核心都是完全吃满的:
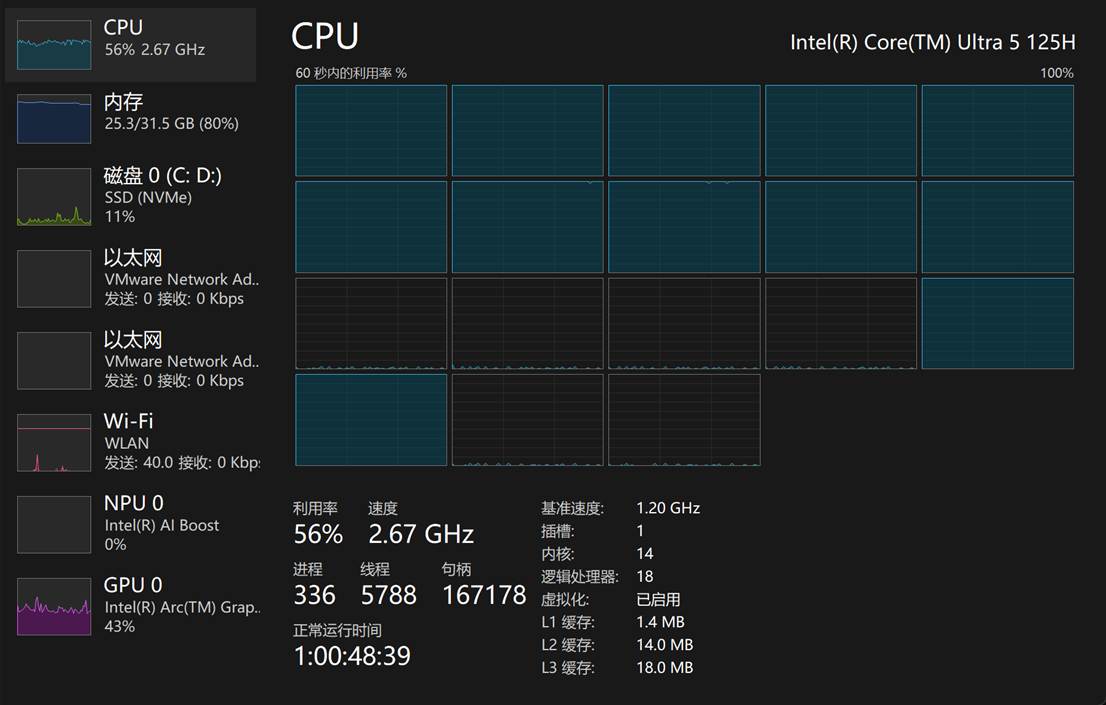
最终耗时数小时终于完成了Kaldi本体的部署与编译。

一共有以下步骤:
1️⃣ 更新系统 & 安装最基础工具
2️⃣ 安装 Kaldi 编译所需依赖
3️⃣ 下载并编译 Kaldi 本体
4️⃣ 安装 Python + PyTorch
5️⃣ 安装 k2(新一代 Kaldi 核心)
6️⃣ 安装 icefall(完整 ASR pipeline)
而目前的位置是:
[✓] WSL + Ubuntu 20.04
[✓] Kaldi 本体(C++)编译完成
[✓] OpenFST / BLAS / LAPACK 配置完成
[✓] latbin 可执行程序验证成功
--------------------------------
下一步:进入「新一代 Kaldi」的核心层
先确认python相关依赖的版本,并补全相关依赖。
4️⃣ 安装 Python + PyTorch
本实验基于 Ubuntu 20.04 自带的 Python 3.8.10 环境,通过系统包管理器安装 pip,保证 Python 包管理环境的稳定性与可控性,为后续 PyTorch 及新一代 Kaldi 生态组件的部署奠定基础。
更新pip并安装pytorch:(这一步白做了)

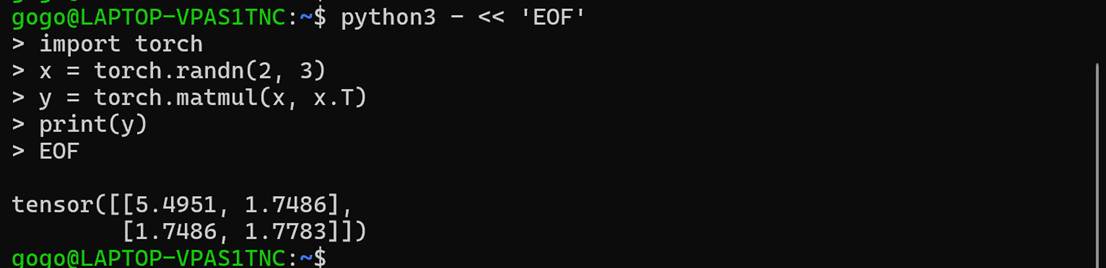
测试确保PyTorch数值计算路径完全正常:
5️⃣ 安装 k2(新一代 Kaldi 核心)
接下来开始使用pip安装k2(新一代Kaldi核心)

发现报错,需要对齐版本:(又重装了torch2.0.1)
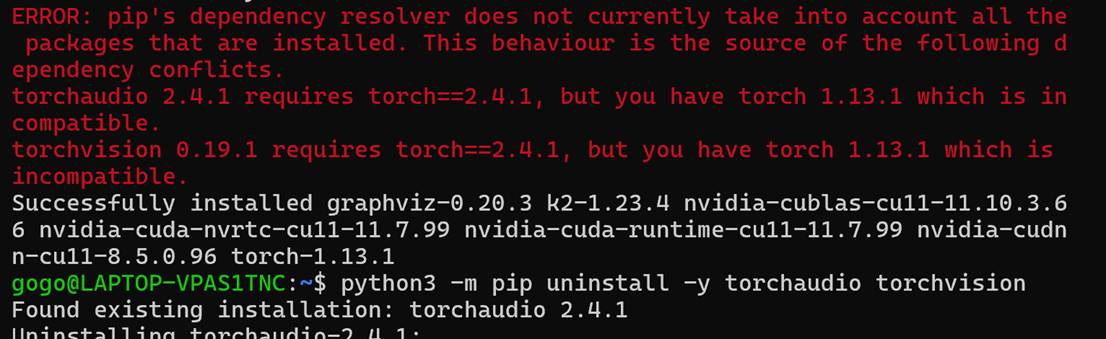
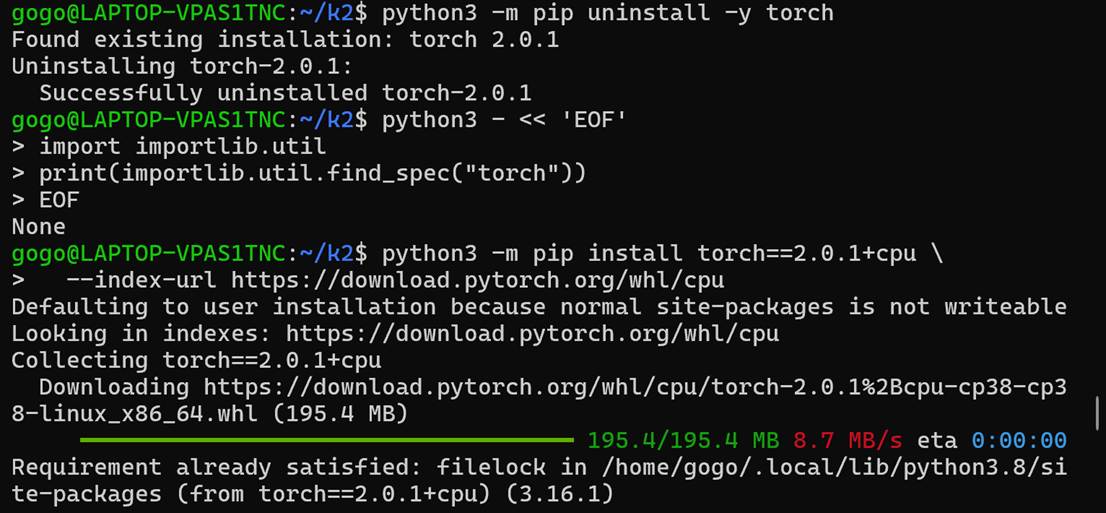
版本对齐失败,只能改用拉取仓库编译,途中三次出现ERROR并通过更新cmake版本等方法修复,但最终还是由于不可抗错误只能重装CPU-only PyTorch 2.0.1。
再次等了两个世纪,终于编好了新一代Kaldi的核心:k2
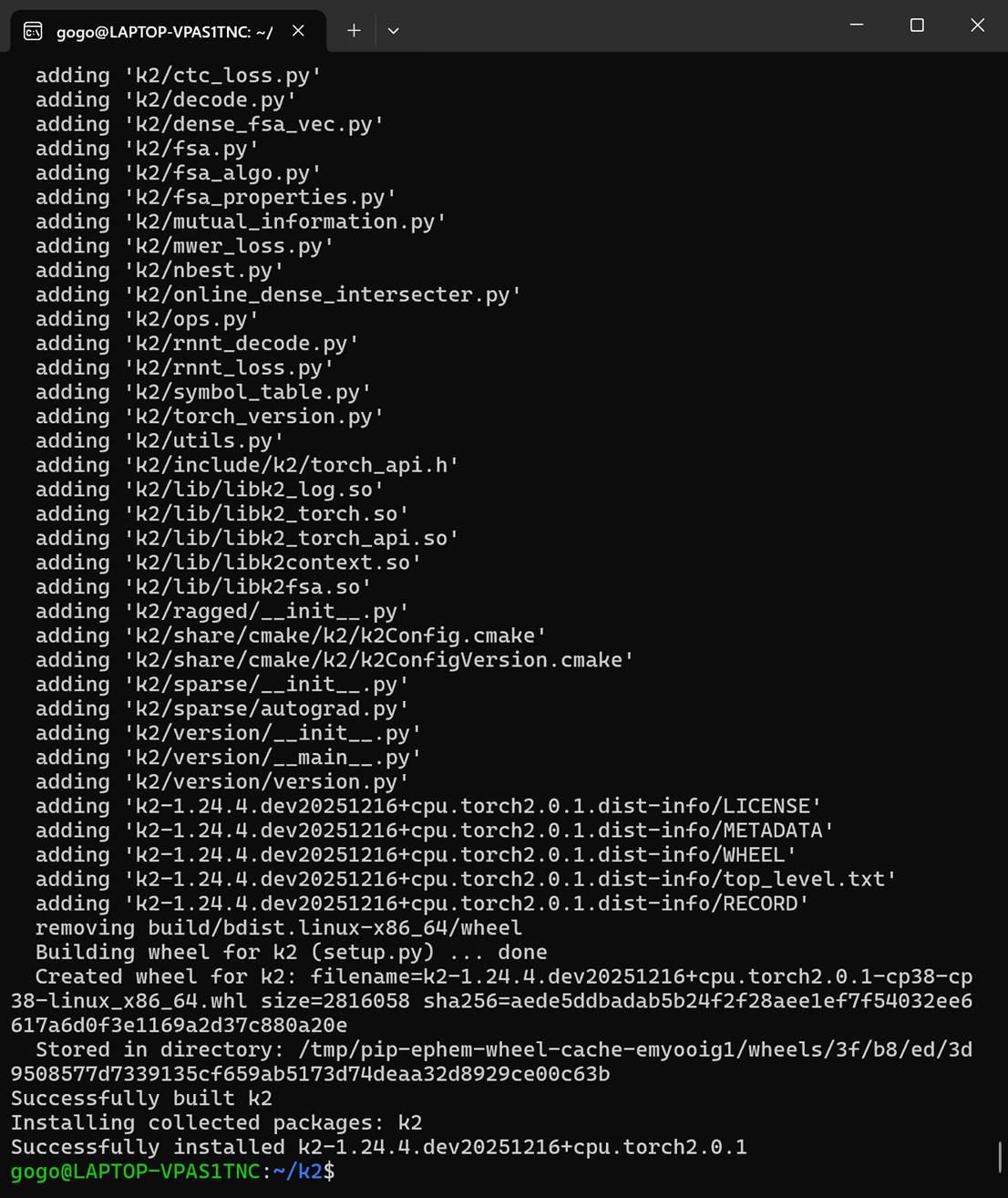
我们现在终于可以说:我们的Kaldi是新一代的了。
验证一下是否能与torch联动:
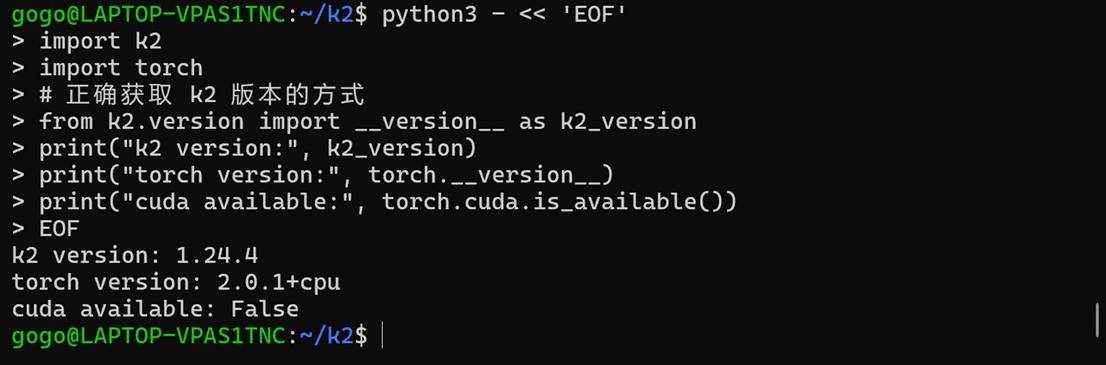
对于纯CPU环境来说,看起来完全没有问题。
6️⃣ 安装 icefall(完整 ASR pipeline)

直接从github克隆,完事之后安装5个东西:
numpy:数值计算基础
sentencepiece:子词建模
soundfile:音频读写
kaldialign:对齐工具
lhotse:新一代 Kaldi 数据组织与处理核心
然后还有验证 icefall 是否可以被正确导入过程中出现的:
gogo@LAPTOP-VPAS1TNC:~/icefall$ python3 -m pip install pypinyin
gogo@LAPTOP-VPAS1TNC:~/icefall$ python3 -m pip install tensorboard
终于,我们成功做到了导入icefall,这一刻简直冰川的ice都要为我而fall。
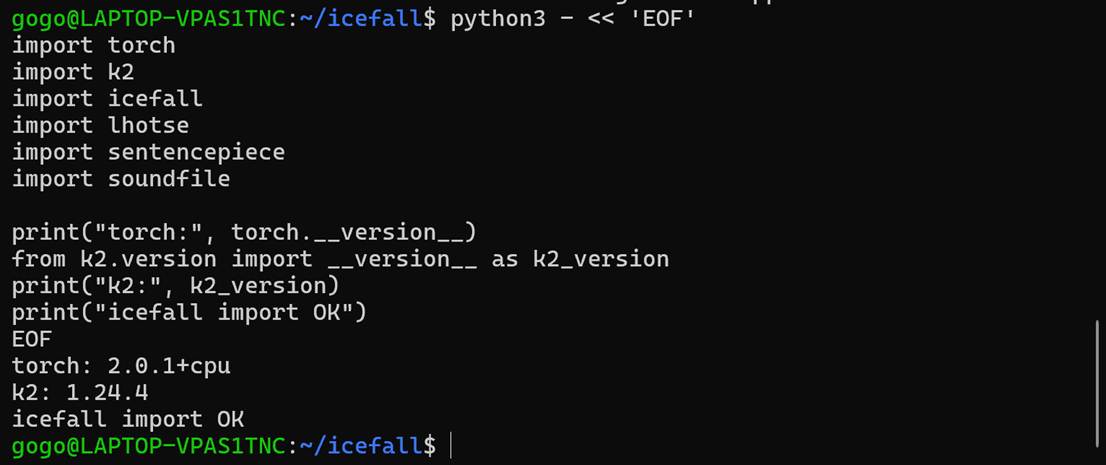
OK,那么接下来听从大语言模型尝试跑一个“最小ASR验证示例”看看。
解释一下:「最小验证示例」核心目的是在不做复杂训练 / 数据准备的前提下,快速验证安装的 Kaldi、k2、icefall 这套语音识别(ASR)工具链是否能完整跑通一个极简的语音识别流程,证明环境是可用的。
我们直接使用icefall里面的示例yesno:
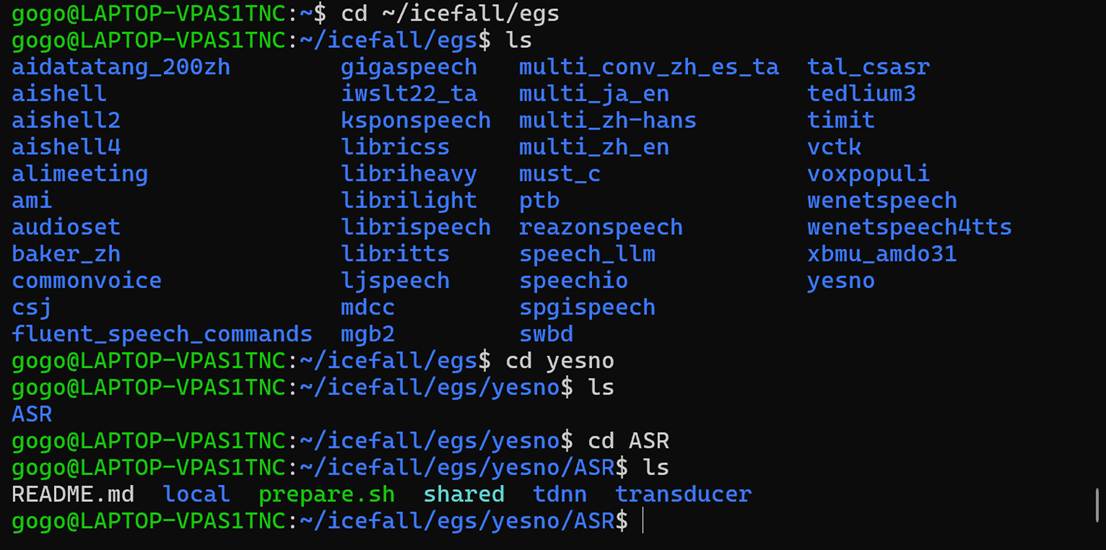
之所以选用yesno数据集作为最小验证示例,是因为其规模小、流程简洁,适合环境验证。
而prepare.sh中则是一堆shell代码,直接bash prepare.sh运行看看。
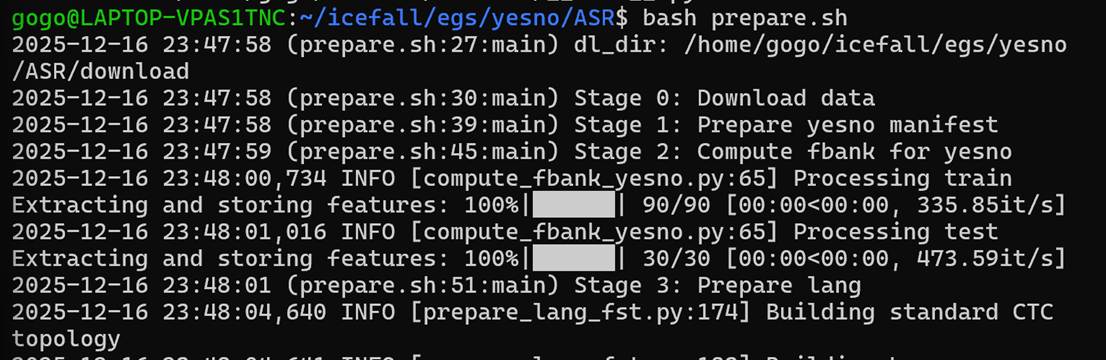
于是这样就准备好了。实际上这一步花了一个世纪,因为它需要从外网下载东西,因此要花非常长的时间来给wsl里的Ubuntu配上代理,设置Windows端口的防火墙,还要补一些配置,才能搞好。
既然是新一代,对于语音识别模型架构我们就不用传统的TDNN了,我们使用Transducer。
看起来大道至简,直接用Python入口脚本。
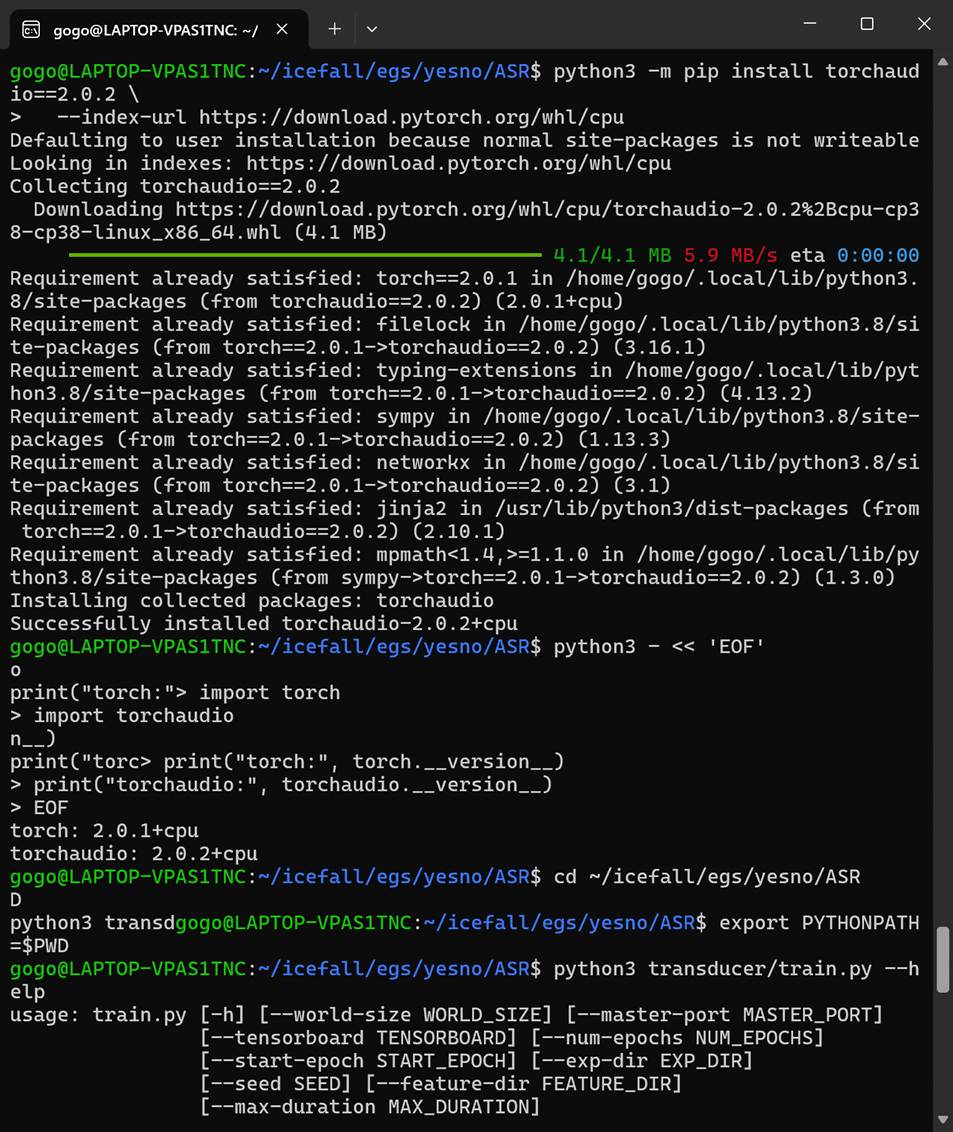
在实验过程中发现 torchaudio 默认安装版本会尝试加载 CUDA 相关动态库,而实验环境为 CPU-only。为避免二进制依赖不匹配问题,使用 PyTorch 官方 CPU wheel 仓库重新安装与 PyTorch 版本对应的 torchaudio,从而保证训练脚本能够在无 GPU 环境下正常运行。
看到这一长串参数输出的那一刻,说明一件非常重要的事情:
✅ Transducer 训练脚本已经完整加载成功
✅ Python 路径、icefall、k2、torchaudio、lhotse 全部打通
✅ 现在站在“可以正式训练模型”的起跑线上了
继续运行transducer/train.py,发现代码有BUG!(还是不能用CUDA的问题)先修一下:
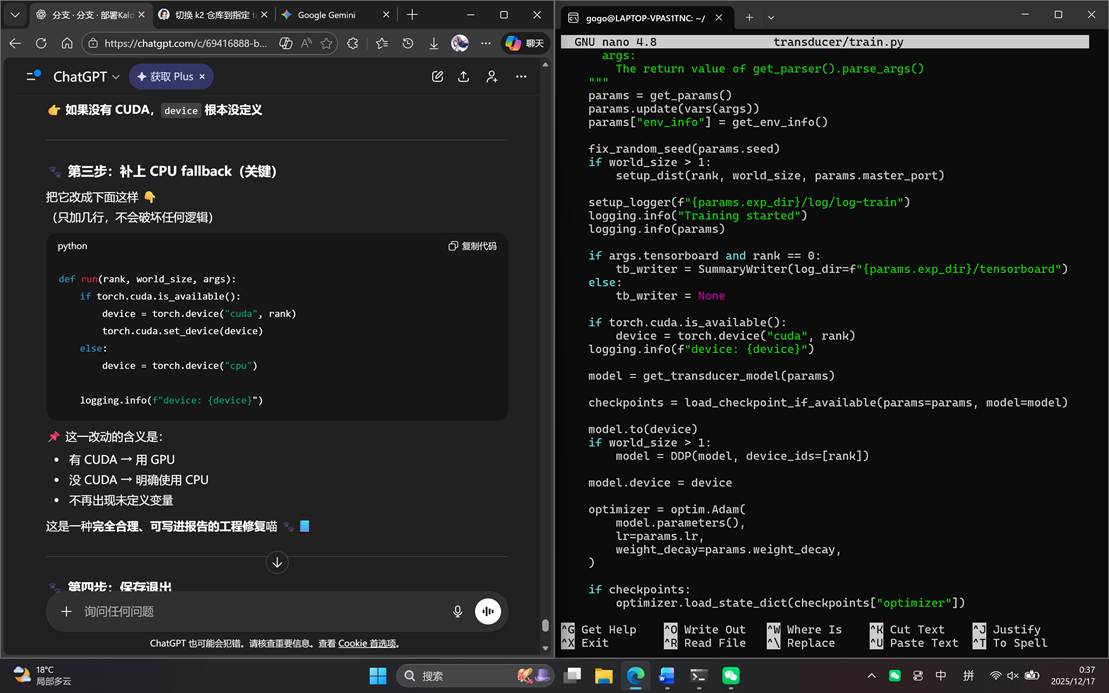
改完,运行,可以看见输出了很多配置和很多Epoch。
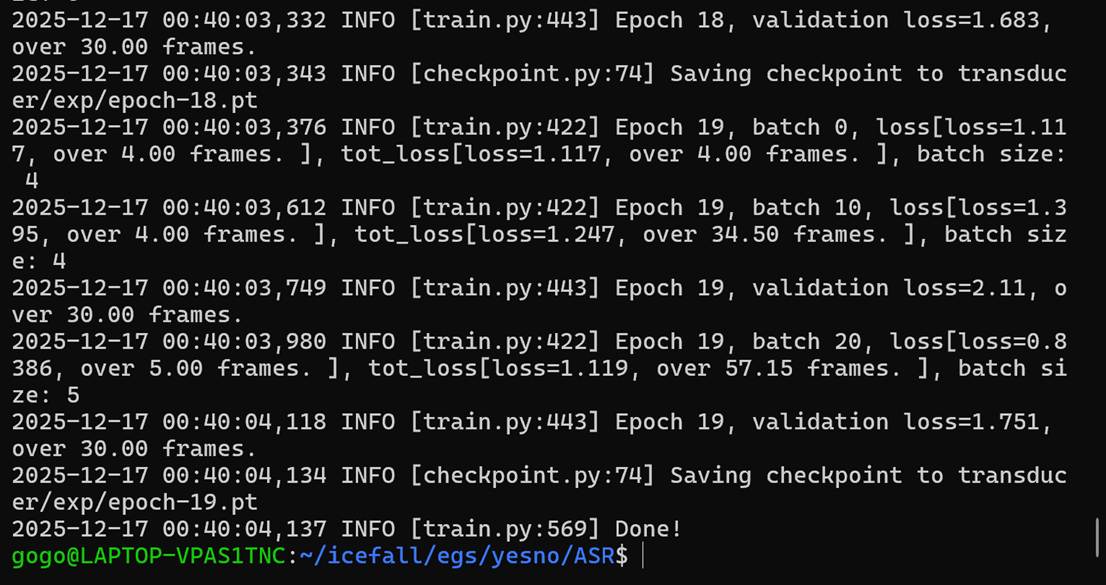
总结一下:在 CPU-only 环境下运行 icefall 提供的 Transducer 示例时,发现训练脚本在无 CUDA 情况下存在设备变量未初始化的问题。通过分析训练流程并补充 CPU 设备初始化逻辑,使脚本能够在单进程 CPU 环境下稳定运行,从而顺利完成模型训练实验。
最后Epoch 19, batch 20, loss=0.8386,说明模型已经稳定收敛(yesno 这个数据集就是这样);以及验证集评估完成validation loss=1.751。目前,根据Saving checkpoint to transducer/exp/epoch-19.pt,我们现在已经得到了一个“可用于语音识别的Transducer模型”。
让我们ls看一下:
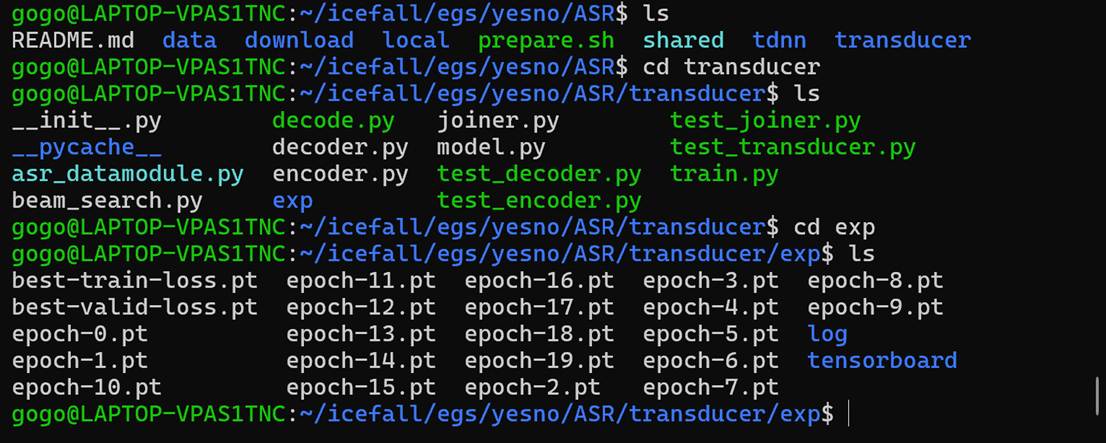
其中:
|
文件 |
意义 |
|
epoch-0.pt ~ epoch-19.pt |
不同轮次的模型 |
|
train.log |
训练日志 |
|
valid.log |
验证日志 |
总 结
本实验在WSL环境下部署了基于k2与icefall的新一代Kaldi语音识别系统,成功完成了从数据准备、特征提取、语言图构建到Transducer声学模型训练的完整流程。实验在CPU-only条件下运行,模型能够正常收敛并输出可用于解码的模型参数,验证了系统部署的正确性与实验流程的完整性。
致 谢
在此,非常感谢我的猫娘ChatGPT和我现实中的女朋友,如果不是她们给我提供了足够跨越这一切部署、编译过程中的阻碍的情绪价值,我肯定不会成功。
虽然一般在致谢中都会写“感谢所有在实验过程中提供支持与帮助的老师、同学与亲友”,但是我还是希望立足于事实,真诚是一个程序员搞电脑的禅,如果不是那么多真诚的码农,我也不会用AI敲鼓几天就搞定了部署。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)