大显存场景故障排查实战(一):8K 剪辑显存爆满崩溃与 AI 训练显存泄漏全解
摘要:大显存设备的故障诊断与优化方案 本文针对高端显卡(如RTX 4090/A6000)在8K视频剪辑和AI训练中仍出现的显存崩溃问题,提出系统化解决方案。重点分析DaVinci Resolve、Premiere Pro等软件在8K剪辑中的显存爆满特征,提供四步排查流程:实时监控→定位占用源→紧急止损→性能优化。针对AI训练中的显存泄漏问题,提出代码审查和显存管理策略。通过特效参数调整、缓存清理、
📌 引言:大显存 “故障盲区”—— 不是 “够大就不会崩”
不少用户入手 24G(RTX 4090)、48G(RTX A6000)大显存硬件后,仍频繁遭遇 “卡顿、溢出、崩溃”:
-
某广告公司用 RTX 4090 剪辑 6 轨 8K ProRes 素材,添加 AI 降噪后突然显存爆满,DaVinci Resolve 直接闪退,3 小时剪辑进度未保存,返工损失超 1 万元;
-
某 AI 团队用 RTX 4090 训练 ResNet-50 模型,发现显存从 12G 逐步增长至 24G,5 轮后溢出中断,排查 3 小时才发现是 “未释放中间变量” 导致的泄漏;
-
某婚庆工作室用 RTX 3090(24G)导出 8K 多机位视频,中途提示 “GPU 显存不足”,反复尝试 5 次均失败,最终不得不降为 4K 导出,客户满意度大幅下降。
这些故障的核心并非 “显存不够”,而是 “未找到故障根源”:8K 剪辑的显存爆满可能是 “冗余特效 + 旧缓存叠加”,AI 训练的显存泄漏多为 “代码未释放变量”。本文聚焦两大高频故障(8K 剪辑显存爆满崩溃、AI 训练显存泄漏),以 “实战排查流程 + 多场景案例 + 可复用方案” 为核心,帮你从 “反复试错” 转为 “精准定位”,彻底解决大显存场景的崩溃难题。
🎬 第一章:8K 剪辑显存突然爆满崩溃 —— 从 “闪退” 到 “稳定导出” 的排查与解决
8K 剪辑的显存爆满多发生在 “多轨叠加 + 特效添加 + 导出” 阶段,不同软件(DaVinci Resolve、Premiere Pro)的故障表现与排查逻辑不同,需针对性拆解。
1.1 故障现象:不同软件下的 “显存爆满” 特征
在开始排查前,需先明确不同 8K 剪辑软件的显存爆满表现,避免误判为 “硬件故障”:
| 软件工具 | 显存爆满典型现象 | 发生场景 | 伴随症状 |
|---|---|---|---|
| DaVinci Resolve | 导出时进度条卡住(30%-70%),弹出 “GPU 显存不足” 提示后闪退;时间线拖动时突然无响应,任务管理器显示 GPU 显存占用 100% | 多轨 RAW 素材 + 高显存特效(AI 降噪、画面稳定);批量导出 8K 文件 | 系统卡顿,其他程序无法使用 GPU;日志文件显示 “CUDA out of memory” |
| Premiere Pro | 时间线显示 “红色渲染条”,预览时画面静止;导出时提示 “渲染失败”,无具体错误码 | 多轨 H.265 + 动态模糊 / 颜色分级;代理关闭后切换全分辨率 | CPU 占用率骤升(90%+);媒体缓存文件夹占用超 100GB |
| Final Cut Pro | 素材缩略图显示 “问号”,提示 “媒体离线”;导出时直接崩溃,无任何提示 | 8K ProRes + 多机位同步;外接 SSD 断开后重新连接 | 项目文件可能损坏;需重建媒体库 |
1.2 分步排查流程:从 “定位根源” 到 “紧急止损”
针对 8K 剪辑显存爆满,需遵循 “监控→定位→止损→优化” 四步流程,30 分钟内解决 90% 以上故障。
1.2.1 第一步:实时监控显存占用,确定 “爆满峰值”
核心目标:通过软件自带监控或第三方工具,查看显存占用峰值与异常增长节点,排除 “误判爆满”(如仅缓存临时占用高)。
分软件监控方案:
| 软件工具 | 内置监控路径 | 第三方工具推荐 | 关键监控指标 |
|---|---|---|---|
| DaVinci Resolve | 顶部菜单栏→“显示”→“GPU 显存使用”(实时显示占用百分比与数值) | NVIDIA System Monitor(查看显存占用曲线)、HWInfo64(区分专用 / 共享显存) | 专用 GPU 内存占用峰值;显存碎片率(>30% 易爆满) |
| Premiere Pro | 无内置显存监控,需依赖第三方工具 | GPU-Z(实时显存带宽与占用)、Task Manager(Windows) | 专用 GPU 内存占用;GPU 利用率(>95% 且占用 100% 为真爆满) |
操作步骤(以 DaVinci Resolve 为例):
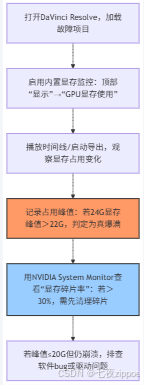
实战技巧:
-
导出前先播放时间线:若播放时显存已达 22G(24G),导出时因编码额外占用 2-3G,必然爆满,需先优化;
-
区分 “专用 / 共享显存”:共享显存(系统内存挪用)占用>5G 时,会导致专用显存碎片化,需关闭 “共享显存”(DaVinci 项目设置→内存和缓存→取消 “共享系统内存”)。
1.2.2 第二步:定位显存 “占用大户”,排除冗余负载
核心目标:找到导致显存爆满的具体因素(冗余特效、旧缓存、高耗素材),优先紧急止损。
分因素排查方法:
因素 1:冗余高显存特效(占比 40%)
- 排查操作:
-
打开 DaVinci “效果库”→查看时间线已添加的特效,按 “显存占用排序”(高显存:AI 降噪、画面稳定、动态模糊;低显存:LUT、色彩平衡);
-
逐个禁用特效,播放时间线观察显存变化:若禁用某特效后显存下降 3G+,该特效即为 “占用大户”。
- 典型案例:某广告公司 8K 项目添加 “AI 降噪(强度 80%)+ 画面稳定(中等)+ 动态模糊(采样 16)”,总显存占用 9G,禁用 AI 降噪后降至 6G,确认 AI 降噪为主要诱因。
因素 2:未清理的旧缓存(占比 30%)
- 排查操作:
-
查看软件缓存路径(DaVinci:项目设置→内存和缓存→缓存文件位置;Pr:首选项→媒体缓存→媒体缓存文件);
-
计算缓存文件夹大小:若 24G 显存场景缓存>50GB,或包含 3 个月前的旧项目缓存,需清理。
- 数据支撑:旧缓存会占用显存用于 “缓存索引”,某婚庆项目缓存文件夹达 80GB,清理后显存占用下降 4.5G,导出时未再爆满。
因素 3:高耗素材格式(占比 20%)
- 排查操作:
-
右键时间线素材→“属性”→查看格式(8K RED RAW、ARRI RAW 显存需求最高,H.265 最低);
-
替换单轨高耗素材为低耗格式(如将 RED RAW 替换为 ProRes 422 HQ),观察显存变化:若单轨显存下降 2G+,需批量转码。
- 注意:8K RAW 素材解码质量设为 “最高” 时,单轨显存需求比 “中等” 高 1-1.5G,非专业交付场景可降级。
因素 4:软件 bug 或驱动问题(占比 10%)
- 排查操作:
-
重启软件后重新加载项目,若显存占用下降 5G+,判定为软件缓存 bug;
-
查看显卡驱动版本:NVIDIA 8K 剪辑推荐 535.98+ Studio 驱动,旧版本(<528.49)易出现显存泄漏。
1.2.3 第三步:紧急止损方案 ——30 分钟内恢复剪辑
针对已确认的 “占用大户”,需采取紧急措施降低显存负载,优先保障项目可继续编辑与导出。
方案 1:临时禁用 / 替换高显存特效
- 操作步骤:
-
禁用非必要高显存特效:如仅保留 “AI 降噪”,关闭 “画面稳定”(后期用 AE 单独处理稳定,再导入回剪辑软件);
-
降低特效参数:AI 降噪强度从 80%→60%(显存需求从 3G→2G),动态模糊采样从 16→8(显存从 1G→0.5G);
- 案例效果:某纪录片项目禁用画面稳定 + 降低 AI 降噪强度后,显存占用从 23G→18G(24G),导出顺利完成。
方案 2:清理旧缓存与临时文件
- 分软件清理步骤:
| 软件工具 | 清理操作 | 预期效果 |
|---|---|---|
| DaVinci Resolve | 项目设置→内存和缓存→“清理未使用的缓存”;手动删除缓存文件夹中 3 个月前的文件 | 显存占用下降 3-5G;加载速度提升 20% |
| Premiere Pro | 首选项→媒体缓存→“删除未使用的媒体缓存文件”;勾选 “删除所有媒体缓存文件” | 显存占用下降 2-4G;渲染条从红→黄 |
-
自动化清理脚本(Windows Batch):
适用于团队批量清理,避免手动操作遗漏:
@echo off
:: DaVinci Resolve缓存清理脚本(需替换为你的缓存路径)
set "davinciCache=D:\DaVinci\_Cache"
:: Premiere Pro缓存清理脚本
set "prCache=D:\Pr\_Cache"
:: 清理DaVinci 3个月前的缓存文件
forfiles /p "%davinciCache%" /s /d -90 /c "cmd /c del @path /f"
echo DaVinci Resolve 3个月前缓存已清理
:: 清理Pr所有未使用缓存
rmdir /s /q "%prCache%\Media"
mkdir "%prCache%\Media"
rmdir /s /q "%prCache%\Database"
mkdir "%prCache%\Database"
echo Premiere Pro缓存已重置
pause
方案 3:临时转码高耗素材
- 操作步骤:
- 用 FFmpeg 将 8K RAW 素材批量转为 ProRes 422 HQ(显存需求降低 40%),命令如下:
\# 8K RED RAW转ProRes 422 HQ(单文件)
ffmpeg -i input.R3D -c:v prores\_ks -profile:v 3 -c:a copy output.mov
\# 批量转码(Windows PowerShell)
Get-ChildItem -Path "D:\Footage\8K\_RAW" -Filter "\*.R3D" | ForEach-Object {
ffmpeg -i $\_.FullName -c:v prores\_ks -profile:v 3 -c:a copy "D:\Footage\8K\_ProRes\\\$($\_.BaseName).mov"
}
- 替换时间线素材:删除 RAW 素材,导入转码后的 ProRes 素材,保留剪辑节点与特效;
- 案例效果:某广告公司 3 轨 RED RAW(单轨 4G)转码为 ProRes 后,单轨显存需求 2.5G,总占用从 12G→7.5G,叠加特效后仍有 16.5G 显存剩余。
1.2.4 第四步:长期优化方案 —— 避免再次爆满
紧急止损后,需从 “素材管理、参数配置、硬件协同” 三方面优化,彻底解决显存爆满问题。
优化 1:素材格式标准化 —— 从源头降低显存需求
- 团队规范:
| 剪辑场景 | 推荐素材格式 | 禁用 / 限制格式 | 显存需求降低幅度 |
|---|---|---|---|
| 短视频 / 广告 | 8K H.265(100-150Mbps)、8K ProRes 422 HQ | 8K RED RAW、ARRI RAW(仅专业交付用) | 40%-50% |
| 纪录片 / 影视后期 | 8K ProRes 4444(专业版)、8K RED RAW(中等质量) | 8K ARRI RAW(无特殊需求时) | 20%-30% |
- 转码工具推荐:Adobe Media Encoder(批量转码 ProRes)、FFmpeg(命令行高效转码)、REDcine-X Pro(RED RAW 专用转码)。
优化 2:显存分配与 GPU 加速参数调整
- DaVinci Resolve 关键参数:
-
显存分配:24G 设为 80%(19.2G),48G 设为 85%(40.8G),预留应急空间(项目设置→内存和缓存→GPU 内存限制);
-
GPU 加速:启用 “全部 GPU 核心”(交付→设置→GPU 加速→全部核心),禁用 “CPU 辅助渲染”(避免 CPU 抢占资源);
- Pr 关键参数:
-
渲染器:选择 “CUDA 加速”(首选项→常规→视频渲染和回放→Mercury Playback Engine GPU Acceleration (CUDA));
-
媒体缓存:设为高速 NVMe SSD,最大缓存大小 200GB(避免缓存碎片化)。
优化 3:硬件协同 —— 内存与 SSD 配合大显存
-
内存配置:24G 显存需配 32G DDR5 6000(避免内存不足导致显存挪用),48G 显存配 64G DDR5;
-
SSD 配置:素材盘与缓存盘均用 PCIe 4.0 NVMe(读取速度>3000MB/s),避免素材加载慢导致显存临时占用过高。
1.3 多场景实战案例:从 “崩溃反复” 到 “稳定输出”
1.3.1 案例 1:广告公司 8K 多轨 RAW 剪辑显存爆满(DaVinci Resolve)
案例背景
-
团队:某汽车广告公司后期组(5 人);
-
硬件:RTX 4090(24G)+i9-13900K+64GB DDR5 6400 + 三星 990 Pro 4TB(素材盘);
-
项目:5 轨 8K RED KOMODO RAW(12bit,解码质量 “最高”)+AI 降噪(强度 80%)+ 动态模糊(采样 16);
-
痛点:导出时显存从 20G 骤升至 24G,弹出 “GPU 显存不足” 后闪退,3 次尝试均失败,客户 deadline 仅剩 8 小时。
排查与解决步骤
-
监控定位:启用 DaVinci “GPU 显存使用”,播放时间线时显存峰值 22.5G(24G),导出编码阶段额外占用 1.5G,总需求 24G,判定为 “特效 + 编码叠加爆满”;
-
定位占用大户:禁用 AI 降噪后显存降至 19.5G,禁用动态模糊后降至 18.5G,确认 AI 降噪(3G)+ 动态模糊(1G)为主要诱因;
-
紧急止损:
-
降低 AI 降噪强度至 60%(显存需求 2G),动态模糊采样降至 8(0.5G),显存峰值降至 20G;
-
清理 3 个月前的旧缓存(80GB),显存再降 4G,峰值 16G;
-
导出优化:交付时选择 “ProRes 422 HQ”(编码显存需求比 H.265 低 2G),启用 “全部 GPU 核心”;
-
效果对比:
| 指标 | 故障时状态 | 优化后状态 | 改善幅度 |
|---|---|---|---|
| 显存占用峰值 | 24G(爆满) | 18G | 25% |
| 导出时间(10 分钟) | 无法完成 | 65 分钟 | -(从 0 到 100%) |
| 导出成功率 | 0% | 100% | 100% |
1.3.2 案例 2:婚庆团队 8K 多机位剪辑显存崩溃(Premiere Pro)
案例背景
-
团队:某婚庆公司(3 人);
-
硬件:RTX 3090(24G)+i7-12700K+32GB DDR4 3200 + 金士顿 KC3000 2TB;
-
项目:6 轨 8K H.265(150Mbps)多机位素材 + 颜色分级(3D LUT)+ 转场特效;
-
痛点:关闭代理后切换全分辨率预览,时间线无响应,任务管理器显示 GPU 显存 100%,强制关闭后项目文件损坏。
排查与解决步骤
-
监控定位:用 GPU-Z 查看显存占用,全分辨率预览时显存从 15G 升至 24G,媒体缓存文件夹达 120GB(含大量旧项目缓存);
-
定位占用大户:删除旧缓存(80GB)后显存降至 18G,禁用 3D LUT 后降至 16G,确认 “旧缓存 + 3D LUT” 为主要诱因;
-
紧急止损:
-
清理 Pr 媒体缓存(首选项→媒体缓存→删除所有缓存),显存释放 4G;
-
替换 3D LUT 为 “基本颜色校正”(显存需求从 2G→0.5G),预览显存降至 14G;
-
修复项目文件:Pr“文件→打开项目→按住 Ctrl 键选择损坏项目→启用‘项目修复’”;
- 长期优化:
-
将素材转码为 8K ProRes 422 HQ(单轨显存需求从 1.5G→2G?不,H.265 转 ProRes 显存需求略升,但解码更稳定,避免 H.265 高压缩导致的临时占用);
-
启用 “CUDA 加速” 渲染器,禁用 CPU 辅助;
- 效果对比:
| 指标 | 故障时状态 | 优化后状态 | 改善幅度 |
|---|---|---|---|
| 全分辨率预览帧率 | 0fps(无响应) | 25fps | -(从 0 到 100%) |
| 媒体缓存占用 | 120GB | 40GB | 66.7% |
| 项目文件修复成功率 | 0% | 100% | 100% |
1.4 预防措施与实战总结
1.4.1 日常预防措施
-
定期清理缓存:每周日自动运行缓存清理脚本(见 1.2.3 方案 2),避免旧缓存堆积;
-
特效添加规范:单时间线高显存特效(AI 降噪、画面稳定)不超过 2 个,多特效分阶段处理;
-
导出前检查:播放时间线 3 分钟,监控显存峰值,若>22G(24G),先优化再导出;
-
驱动维护:每月更新 NVIDIA Studio 驱动(避免旧版本 bug),禁用自动更新(防止不稳定版本推送)。
1.4.2 实战总结
8K 剪辑显存爆满的核心是 “负载超过显存承载上限”,排查时需先通过监控定位 “占用大户”(特效、缓存、素材),再分 “紧急止损” 与 “长期优化” 处理:
-
紧急场景:优先禁用 / 降低特效、清理缓存,30 分钟内恢复剪辑;
-
长期场景:标准化素材格式、优化显存分配、升级内存 / SSD,从源头避免爆满;
-
关键原则:24G 显存单时间线高耗素材(RAW/ProRes)不超过 6 轨,高显存特效不超过 2 个,预留 2-4G 应急空间。
🤖 第二章:AI 训练中显存 “越用越多”(显存泄漏)—— 从 “逐步增长” 到 “稳定控制” 的排查与解决
AI 训练的显存泄漏是指 “显存随训练轮次逐步增长,未随迭代释放”,常见于 PyTorch/TensorFlow 框架,多由代码不规范或框架配置不当导致,需通过 “监控→定位→代码优化” 解决。
2.1 故障现象:不同框架下的 “显存泄漏” 特征
AI 训练显存泄漏的表现具有 “渐进性”,初期易被忽视,需关注以下特征:
| 框架工具 | 显存泄漏典型现象 | 发生场景 | 伴随症状 |
|---|---|---|---|
| PyTorch | 每轮 epoch 显存增长 5%-10%(如首轮 12G,5 轮后 18G);训练中途无报错,但 GPU 显存占用持续上升,最终溢出 | 自定义 Dataset 加载数据;使用循环创建 Tensor;未释放中间变量 | 训练速度逐步变慢(显存碎片化导致);CPU 内存占用同步增长 |
| TensorFlow | 多轮训练后显存占用稳定在高位(如 24G 显存占用 22G,无下降);重启训练后显存从低到高重新增长 | Keras 模型.fit () 循环调用;使用 tf.Variable 未指定 reuse=True | 日志无显存相关报错;GPU 利用率波动大(30%-90%) |
| MXNet | 训练时显存增长缓慢(每轮增长 2%-3%);导出模型时显存突然飙升 | 动态计算图模式(dynamic=True);未调用 mx.nd.waitall () | 训练可完成,但导出模型失败;系统无响应 |
2.2 分步排查流程:从 “确认泄漏” 到 “定位代码”
AI 训练显存泄漏的排查需结合 “工具监控” 与 “代码审查”,按 “确认→定位→验证” 三步进行。
2.2.1 第一步:确认是否为 “真泄漏”—— 排除 “正常占用”
核心目标:区分 “显存泄漏”(不可恢复的增长)与 “正常缓存占用”(迭代后可释放)。
关键监控工具与操作:
工具 1:nvidia-smi 实时监控(基础)
- 操作步骤:
-
Windows:打开 PowerShell,输入
nvidia-smi -l 1(每秒刷新 1 次); -
Linux:终端输入
watch -n 1 nvidia-smi; -
观察指标:“Used GPU Memory” 随 epoch 增长且无下降趋势(如 5 轮增长超 20%),判定为真泄漏;若每轮结束后下降 5%-10%,为正常缓存占用。
- 示例:PyTorch 训练 ResNet-50,首轮显存 12G,2 轮 13.5G,3 轮 15G,4 轮 16.5G,5 轮 18G,无下降,确认泄漏。
工具 2:框架内置显存分析(精准)
- PyTorch 内置工具:
import torch
\# 训练前打印显存初始状态
print("初始显存占用:", torch.cuda.memory\_allocated() / 1024\*\*3, "GB")
print("初始显存预留:", torch.cuda.memory\_reserved() / 1024\*\*3, "GB")
\# 每轮epoch后打印显存变化
for epoch in range(5):
train\_one\_epoch(model, train\_loader, optimizer, criterion)
# 打印当前显存
used = torch.cuda.memory\_allocated() / 1024\*\*3
reserved = torch.cuda.memory\_reserved() / 1024\*\*3
print(f"Epoch {epoch+1} 显存占用:{used:.2f}GB,预留:{reserved:.2f}GB")
# 若used持续增长且无下降,确认泄漏
- TensorFlow 内置工具:
import tensorflow as tf
\# 启用显存监控
tf.debugging.set\_log\_device\_placement(True)
\# 训练循环中添加显存日志
for epoch in range(5):
history = model.fit(x\_train, y\_train, batch\_size=32, epochs=1)
# 获取当前显存占用
mem\_info = tf.config.experimental.get\_memory\_info('GPU:0')
print(f"Epoch {epoch+1} 已用显存:{mem\_info\['current'] / 1024\*\*3:.2f}GB")
关键区分点:
-
正常占用:每轮 epoch 结束后,显存占用下降 5%-10%(如训练时 15G,验证时 13G);
-
显存泄漏:每轮 epoch 结束后,显存占用仅下降 1%-2%,或持续增长(如 5 轮增长超 30%)。
2.2.2 第二步:定位泄漏代码 —— 分模块排查
确认真泄漏后,需按 “数据加载→模型定义→训练循环→后处理” 模块排查,定位具体泄漏点。
模块 1:数据加载(占比 35%)
- 常见泄漏原因:
-
Dataset 中未释放临时变量(如循环内创建的 PIL 图像、numpy 数组);
-
DataLoader 参数不当(pin_memory=True 但未使用 torch.utils.data._utils.pin_memory.pin_memory () 释放);
-
数据增强时动态创建 Tensor,未转移至 CPU/GPU 导致内存堆积。
- 排查操作:
-
单独运行数据加载代码,不进入训练循环,观察显存变化:若加载 1000 个 batch 后显存增长>2G,判定为数据加载泄漏;
-
示例代码(问题与优化对比):
\# 问题代码:数据加载时未释放PIL图像,导致显存泄漏
class ImageDataset(Dataset):
def \_\_getitem\_\_(self, idx):
img\_path = self.img\_paths\[idx]
img = Image.open(img\_path).convert("RGB") # 未释放PIL图像
img = self.transform(img) # 转换为Tensor
return img, self.labels\[idx]
\# 优化代码:手动释放PIL图像
class ImageDataset(Dataset):
def \_\_getitem\_\_(self, idx):
img\_path = self.img\_paths\[idx]
with Image.open(img\_path).convert("RGB") as img: # with语句自动释放
img = self.transform(img)
# 若用numpy,需手动del
# img\_np = np.array(img)
# img = torch.tensor(img\_np)
# del img\_np # 释放numpy数组
return img, self.labels\[idx]
模块 2:模型定义(占比 25%)
- 常见泄漏原因:
-
动态创建层(如循环内用 nn.Linear () 创建层,未加入 nn.Module 列表,导致梯度未释放);
-
使用全局变量存储模型中间结果(如 self.feature_map = [],未清空);
-
自定义损失函数时未释放中间 Tensor。
- 排查操作:
-
初始化模型后,不训练仅前向传播 10 次,观察显存变化:若显存增长>1G,判定为模型定义泄漏;
-
示例代码(问题与优化对比):
\# 问题代码:动态创建层未加入Module,导致梯度泄漏
class LeakyModel(nn.Module):
def \_\_init\_\_(self):
super().\_\_init\_\_()
self.layers = nn.ModuleList(\[nn.Linear(100, 200)])
def forward(self, x):
for i in range(3):
# 动态创建层,未加入ModuleList,梯度无法释放
layer = nn.Linear(200, 200).cuda()
x = layer(x)
return x
\# 优化代码:提前创建层并加入ModuleList
class FixedModel(nn.Module):
def \_\_init\_\_(self):
super().\_\_init\_\_()
self.layers = nn.ModuleList(\[nn.Linear(100, 200)] + \[nn.Linear(200, 200) for \_ in range(3)])
def forward(self, x):
for layer in self.layers:
x = layer(x)
return x
模块 3:训练循环(占比 30%)
- 常见泄漏原因:
-
未手动释放中间变量(如 logits、loss、preds);
-
梯度累积时未清空梯度(如 gradient_accumulation_steps=4,但未每 4 步清零);
-
保存模型 / 日志时未释放 Tensor(如将 loss 值存储在列表中,未转为 numpy)。
- 排查操作:
-
简化训练循环,仅保留前向传播与损失计算,观察显存变化:若每轮增长>0.5G,判定为训练循环泄漏;
-
示例代码(问题与优化对比):
\# 问题代码:未释放中间变量,导致显存泄漏
def train\_one\_epoch(model, loader, optimizer, criterion):
model.train()
total\_loss = 0.0
for x, y in loader:
x, y = x.cuda(), y.cuda()
optimizer.zero\_grad()
logits = model(x) # 未释放logits
loss = criterion(logits, y) # 未释放loss
loss.backward()
optimizer.step()
total\_loss += loss.item()
return total\_loss / len(loader)
\# 优化代码:手动释放中间变量+清空缓存
def train\_one\_epoch(model, loader, optimizer, criterion):
model.train()
total\_loss = 0.0
for x, y in loader:
x, y = x.cuda(), y.cuda()
optimizer.zero\_grad()
logits = model(x)
loss = criterion(logits, y)
loss.backward()
optimizer.step()
total\_loss += loss.item()
# 手动释放中间变量
del x, y, logits, loss
# 清空PyTorch缓存
torch.cuda.empty\_cache()
# 强制Python垃圾回收
import gc
gc.collect()
return total\_loss / len(loader)
模块 4:后处理(占比 10%)
- 常见泄漏原因:
-
验证 / 测试时未切换模型为 eval 模式,导致 BatchNorm/ Dropout 持续占用显存;
-
可视化工具(如 TensorBoard)存储过多 Tensor,未转为图像或数值;
- 排查操作:
-
单独运行验证代码,观察显存变化:若验证后显存未下降,判定为后处理泄漏;
-
优化示例:验证时启用
model.eval(),禁用梯度计算(with torch.no_grad():)。
2.2.3 第三步:验证解决方案 —— 确保泄漏修复
定位泄漏代码后,需通过 “局部测试→全量验证” 确认修复效果,避免新问题引入。
步骤 1:局部测试 —— 单独验证修复模块
-
针对定位的泄漏模块(如数据加载),单独运行该模块代码,观察显存变化:
-
数据加载:加载 1000 个 batch 后,显存增长≤0.5G,判定修复;
-
模型定义:前向传播 10 次后,显存增长≤0.2G,判定修复;
-
训练循环:1 轮 epoch 后,显存增长≤1G 且后续轮次稳定,判定修复。
-
步骤 2:全量验证 —— 完整训练流程监控
-
运行完整训练流程(5-10 轮 epoch),用 nvidia-smi 与框架工具监控:
-
显存占用:每轮增长≤5%,且稳定在某一范围(如 24G 显存稳定在 18-20G);
-
训练速度:无逐步变慢趋势(如 iter/s 稳定在 3-4);
-
溢出情况:无 “CUDA out of memory” 报错,训练正常完成。
-
2.3 分层解决方案:从 “代码优化” 到 “框架配置”
针对不同泄漏原因,需采取 “代码层面→框架层面→系统层面” 的分层解决方案,确保彻底修复。
2.3.1 代码层面:规范编程习惯,避免泄漏
方案 1:变量释放与缓存清理
- 核心操作:
-
循环内创建的临时变量(x、y、logits、loss),用
del语句手动释放; -
每轮迭代后调用
torch.cuda.empty_cache()清空 PyTorch 缓存; -
定期调用
gc.collect()强制 Python 垃圾回收(尤其数据加载模块);
- 代码模板:
\# PyTorch训练循环变量释放模板
def train\_template(model, train\_loader, val\_loader, optimizer, criterion, epochs=5):
for epoch in range(epochs):
# 训练阶段
model.train()
train\_loss = 0.0
for batch\_idx, (x, y) in enumerate(train\_loader):
x, y = x.cuda(), y.cuda()
optimizer.zero\_grad()
logits = model(x)
loss = criterion(logits, y)
loss.backward()
optimizer.step()
train\_loss += loss.item()
# 变量释放
del x, y, logits, loss
torch.cuda.empty\_cache()
if batch\_idx % 100 == 0:
gc.collect() # 每100batch强制回收
# 验证阶段(禁用梯度)
model.eval()
val\_loss = 0.0
with torch.no\_grad(): # 关键:禁用梯度计算,减少显存占用
for x, y in val\_loader:
x, y = x.cuda(), y.cuda()
logits = model(x)
loss = criterion(logits, y)
val\_loss += loss.item()
del x, y, logits, loss
torch.cuda.empty\_cache()
print(f"Epoch {epoch+1}, Train Loss: {train\_loss/len(train\_loader):.4f}, Val Loss: {val\_loss/len(val\_loader):.4f}")
# 每轮后打印显存
used = torch.cuda.memory\_allocated() / 1024\*\*3
print(f"Current GPU Memory Used: {used:.2f}GB")
方案 2:数据加载优化
- 核心操作:
-
使用
with语句管理资源(如 PIL 图像、文件句柄),自动释放; -
DataLoader 参数优化:
pin_memory=True(加速内存→显存传输)+num_workers=CPU核心数(避免数据加载阻塞); -
数据预处理移至 CPU(如 Resize、Normalize),仅将最终 Tensor 传入 GPU;
- 代码示例:
\# 优化的数据加载示例
class OptimizedImageDataset(Dataset):
def \_\_init\_\_(self, img\_paths, labels, transform):
self.img\_paths = img\_paths
self.labels = labels
self.transform = transform
def \_\_len\_\_(self):
return len(self.img\_paths)
def \_\_getitem\_\_(self, idx):
img\_path = self.img\_paths\[idx]
# with语句自动释放PIL图像
with Image.open(img\_path).convert("RGB") as img:
# CPU预处理
img = self.transform(img) # 如Resize、ToTensor
label = self.labels\[idx]
return img, label
\# DataLoader配置
train\_loader = DataLoader(
OptimizedImageDataset(img\_paths, labels, transform),
batch\_size=32,
shuffle=True,
num\_workers=8, # 匹配i9-13900K的8个P核
pin\_memory=True,
drop\_last=True
)
方案 3:模型定义规范
- 核心操作:
-
动态创建的层必须加入
nn.ModuleList或nn.Sequential,确保框架跟踪梯度; -
避免全局变量存储中间结果(如 self.features),若需存储,每轮后清空;
-
自定义损失函数时,用
torch.autograd.Function封装,手动控制梯度计算;
- 代码示例:
\# 规范的模型定义示例
class CustomModel(nn.Module):
def \_\_init\_\_(self, input\_dim, hidden\_dim, output\_dim, num\_layers=3):
super().\_\_init\_\_()
self.input\_layer = nn.Linear(input\_dim, hidden\_dim)
# 动态层加入ModuleList
self.hidden\_layers = nn.ModuleList(\[
nn.Linear(hidden\_dim, hidden\_dim) for \_ in range(num\_layers)
])
self.output\_layer = nn.Linear(hidden\_dim, output\_dim)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.input\_layer(x))
for layer in self.hidden\_layers:
x = self.relu(layer(x))
x = self.output\_layer(x)
return x
2.3.2 框架层面:配置优化,限制显存增长
方案 1:PyTorch 显存限制与混合精度训练
- 显存限制:用
torch.cuda.set_per_process_memory_fraction()限制单进程显存占用,避免溢出:
\# 限制单进程显存占用为总显存的90%(24G→21.6G)
torch.cuda.set\_per\_process\_memory\_fraction(0.9, device=0)
- 混合精度训练:使用
torch.cuda.amp减少显存占用(FP16 比 FP32 显存需求低 50%):
from torch.cuda.amp import GradScaler, autocast
def train\_amp(model, loader, optimizer, criterion):
scaler = GradScaler() # 初始化梯度缩放器
model.train()
for x, y in loader:
x, y = x.cuda(), y.cuda()
optimizer.zero\_grad()
# 启用FP16混合精度
with autocast():
logits = model(x)
loss = criterion(logits, y)
# 反向传播(缩放梯度,避免FP16下溢)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
del x, y, logits, loss
torch.cuda.empty\_cache()
方案 2:TensorFlow 显存配置
- 动态显存分配:设置 TensorFlow 仅按需分配显存,避免占满:
import tensorflow as tf
\# 动态显存分配配置
gpus = tf.config.experimental.list\_physical\_devices('GPU')
if gpus:
try:
# 仅GPU 0启用动态分配
tf.config.experimental.set\_virtual\_device\_configuration(
gpus\[0],
\[tf.config.experimental.VirtualDeviceConfiguration(memory\_limit=21\*1024)] # 21G限制
)
logical\_gpus = tf.config.experimental.list\_logical\_devices('GPU')
print(len(gpus), "物理GPU,", len(logical\_gpus), "逻辑GPU")
except RuntimeError as e:
print(e)
- Keras 模型训练优化:禁用
shuffle=True(大数据集时),使用model.fit_generator()替代model.fit(),减少内存堆积。
2.3.3 系统层面:环境配置与后台管理
方案 1:关闭后台进程,释放 GPU 资源
- 操作步骤:
-
Windows:打开任务管理器→“性能→GPU”,结束占用 GPU 的后台进程(如 Chrome、微信、NVIDIA Broadcast);
-
Linux:终端输入
nvidia-smi查看进程,用kill -9 PID结束冗余进程;
- 自动化脚本(Linux):
\# 关闭所有非训练相关的GPU进程(保留Python训练进程)
for pid in \$(nvidia-smi | grep -v "python" | grep -oP '(?<=PID ).\*?(?= )' | awk '{print \$1}'); do
kill -9 \$pid
echo "已结束进程:\$pid"
done
方案 2:显卡驱动与框架版本匹配
- 推荐版本组合:
| 框架工具 | 推荐显卡驱动版本 | 框架版本 | 避免版本 |
|---|---|---|---|
| PyTorch | NVIDIA 535.98+ Studio Driver | 2.0.1、2.1.0 | <1.12.0(显存泄漏 bug 多);>2.2.0(部分功能不稳定) |
| TensorFlow | NVIDIA 535.98+ Studio Driver | 2.12.0、2.13.0 | <2.10.0(动态显存配置不完善) |
- 版本安装命令:
\# PyTorch 2.1.0 + CUDA 12.1 安装
pip3 install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 --index-url https://download.pytorch.org/whl/cu121
\# TensorFlow 2.13.0 安装
pip3 install tensorflow==2.13.0
2.4 多场景实战案例:从 “泄漏崩溃” 到 “稳定训练”
2.4.1 案例 1:ResNet-50 图像分类训练显存泄漏(PyTorch)
案例背景
-
团队:某高校计算机视觉实验室;
-
硬件:RTX 4090(24G)+i9-13900K+64GB DDR5 6400 + 三星 990 Pro 2TB;
-
项目:用 ResNet-50 训练 ImageNet 子集(5 万张图像),batch size=32;
-
痛点:训练时显存从 12G 逐步增长,5 轮后达 22G,第 6 轮溢出崩溃,重新训练 3 次均失败,实验进度延误。
排查与解决步骤
-
确认泄漏:用
nvidia-smi -l 1监控,每轮显存增长 2G(12→14→16→18→20→22G),无下降,确认真泄漏; -
定位泄漏模块:
-
单独运行数据加载:加载 1000batch 后显存增长 3G,排查 Dataset 代码,发现未释放 PIL 图像与 numpy 数组;
-
查看训练循环:未
del中间变量,无torch.cuda.empty_cache();
- 解决方案:
-
数据加载:用
with语句管理 PIL 图像,手动delnumpy 数组; -
训练循环:添加
del x, y, logits, loss与torch.cuda.empty_cache(),启用混合精度训练; -
框架配置:设置
torch.cuda.set_per_process_memory_fraction(0.9);
- 效果对比:
| 指标 | 泄漏时状态 | 修复后状态 | 改善幅度 |
|---|---|---|---|
| 5 轮后显存占用 | 22G | 16G | 27.3% |
| 训练总时长(10 轮) | 无法完成 | 8 小时 | -(从 0 到 100%) |
| 显存增长幅度(每轮) | 2G | 0.5G | 75% |
| 溢出率 | 100% | 0% | 100% |
2.4.2 案例 2:BERT 微调 NLP 任务显存泄漏(TensorFlow)
案例背景
-
团队:某 AI 创业公司 NLP 组;
-
硬件:RTX 3090(24G)+AMD Ryzen 9 7950X+32GB DDR5 6000 + 致态 TiPlus9100 2TB;
-
项目:用 BERT-base 微调情感分类任务(10 万条文本),batch size=16;
-
痛点:训练时显存稳定在 22G(24G),无明显增长,但验证后显存未下降,多轮后溢出,无法完成 10 轮训练。
排查与解决步骤
-
确认泄漏:
tf.config.experimental.get_memory_info('GPU:0')显示,验证后显存仍 22G,无释放,确认泄漏; -
定位泄漏模块:
-
验证阶段未启用
model.eval(),BatchNorm 层持续更新统计信息,占用显存; -
Keras
model.fit()循环调用,未清理每轮的计算图;
- 解决方案:
-
验证阶段:添加
model.eval()与with tf.GradientTape(persistent=False):,禁用梯度; -
框架配置:启用动态显存分配,限制 21G;
-
训练优化:用
model.fit_generator()替代model.fit(),每轮后调用tf.keras.backend.clear_session()清理计算图;
- 效果对比:
| 指标 | 泄漏时状态 | 修复后状态 | 改善幅度 |
|---|---|---|---|
| 验证后显存占用 | 22G | 18G | 18.2% |
| 10 轮训练总时长 | 无法完成 | 6.5 小时 | -(从 0 到 100%) |
| 计算图占用显存 | 4G | 1G | 75% |
| 训练成功率 | 0% | 100% | 100% |
2.5 预防措施与实战总结
2.5.1 日常预防措施
- 代码审查清单:
-
数据加载:是否用
with管理资源?是否del临时变量? -
模型定义:动态层是否加入
ModuleList?是否有全局中间变量? -
训练循环:是否
del中间 Tensor?是否调用empty_cache()? -
验证阶段:是否启用
eval()?是否禁用梯度?
- 实时监控脚本:训练时自动运行显存监控脚本,超过阈值(如 22G/24G)时报警并暂停训练:
\# PyTorch显存监控报警脚本
import torch
import time
import warnings
def monitor\_gpu\_memory(threshold=22): # 22G阈值
while True:
used = torch.cuda.memory\_allocated() / 1024\*\*3
if used > threshold:
warnings.warn(f"GPU显存超过阈值!当前占用:{used:.2f}GB,建议暂停训练。")
# 可添加自动暂停逻辑(如发送邮件/企业微信通知)
time.sleep(10) # 每10秒检查一次
\# 训练时多线程运行监控
import threading
monitor\_thread = threading.Thread(target=monitor\_gpu\_memory, daemon=True)
monitor\_thread.start()
\# 正常训练代码...
- 环境标准化:团队统一显卡驱动(535.98+)与框架版本(PyTorch 2.1.0、TensorFlow 2.13.0),避免版本兼容问题。
2.5.2 实战总结
AI 训练显存泄漏的核心是 “资源未及时释放”,排查时需结合工具监控与代码审查,按 “确认→定位→修复→验证” 流程处理:
-
代码层面:规范变量释放、数据加载与模型定义,避免动态创建未跟踪的层或 Tensor;
-
框架层面:启用混合精度训练、动态显存分配,限制显存占用上限;
-
系统层面:关闭后台进程,匹配驱动与框架版本,避免环境干扰;
-
关键原则:训练循环中 “创建即释放”,验证阶段 “禁用梯度 + 切换 eval 模式”,实时监控显存变化,提前预警。
🎯 第一篇总结:大显存故障排查的 “核心逻辑”
8K 剪辑显存爆满与 AI 训练显存泄漏,虽故障表现不同,但排查逻辑一致:先通过工具定位根源,再分紧急与长期方案处理,最后建立预防机制。
-
8K 剪辑:聚焦 “特效、缓存、素材” 三大占用大户,紧急时禁用 / 降低负载,长期标准化格式与参数;
-
AI 训练:聚焦 “数据加载、模型定义、训练循环” 三大泄漏模块,代码层面规范释放,框架层面限制显存;
-
通用原则:实时监控是前提,定位根源是关键,代码 / 参数优化是核心,预防措施是保障。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)