知识蒸馏(Knowledge Distillation)技术概况及实现细节
知识蒸馏(Knowledge Distillation,KD)是深度学习中的一种模型压缩与知识迁移技术,核心思想是通过训练一个小型模型(学生模型,Student)模仿大型复杂模型(教师模型,Teacher)的输出行为,从而在保持性能的同时降低计算资源需求。:教师模型对输入数据输出的概率分布(非one-hot编码)包含更多“暗知识”(Dark Knowledge),例如不同类别间的相似性关系。:联合
知识蒸馏(Knowledge Distillation,KD)是深度学习中的一种模型压缩与知识迁移技术,核心思想是通过训练一个小型模型(学生模型,Student)模仿大型复杂模型(教师模型,Teacher)的输出行为,从而在保持性能的同时降低计算资源需求。该方法由Hinton等人于2015年提出,现广泛应用于模型轻量化、边缘计算等领域。
一、知识蒸馏的核心原理
1. 核心思想
-
软标签(Soft Labels):教师模型对输入数据输出的概率分布(非one-hot编码)包含更多“暗知识”(Dark Knowledge),例如不同类别间的相似性关系。
-
温度参数(Temperature Scaling):通过引入温度系数 �T 软化概率分布,放大低概率类别的信息。
-
损失函数设计:联合优化学生模型对教师输出的模仿(蒸馏损失)和对真实标签的拟合(传统损失)。
2. 数学表达
-
教师模型输出:
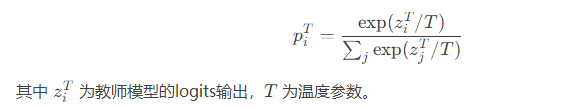
-
学生模型输出:
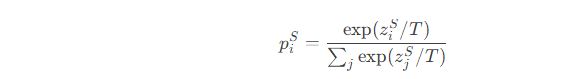
-
总损失函数:
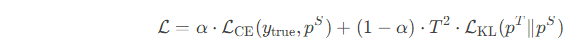

二、知识蒸馏的实现细节
1. 实现流程
python
复制
# 伪代码示例(以PyTorch为例)
import torch
import torch.nn as nn
import torch.optim as optim
# 定义教师模型(Teacher)和学生模型(Student)
teacher = load_pretrained_teacher()
student = StudentNet()
# 定义损失函数
criterion_ce = nn.CrossEntropyLoss() # 真实标签损失
criterion_kl = nn.KLDivLoss(reduction='batchmean') # 蒸馏损失
# 温度参数与优化器
T = 5
optimizer = optim.Adam(student.parameters(), lr=0.001)
# 训练循环
for inputs, labels in dataloader:
# 教师模型生成软标签(不更新梯度)
with torch.no_grad():
teacher_logits = teacher(inputs)
soft_labels = torch.softmax(teacher_logits / T, dim=1)
# 学生模型预测
student_logits = student(inputs)
student_probs = torch.log_softmax(student_logits / T, dim=1)
# 计算损失
loss_ce = criterion_ce(student_logits, labels) # 真实标签损失
loss_kl = criterion_kl(student_probs, soft_labels) # 蒸馏损失
total_loss = alpha * loss_ce + (1 - alpha) * (T**2) * loss_kl
# 反向传播与优化
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
2. 关键参数设置
-
温度参数 T:
-
通常取 T∈[3,10],温度越高,概率分布越平滑,适用于类别间相似性强的任务(如细粒度图像分类)。
-
推理时需将温度重置为1(即标准Softmax)。
-
-
平衡系数 α:
-
若教师模型精度远高于学生,可降低 α(如0.1),强化对教师知识的学习。
-
若学生模型容量较大,可提高 α(如0.5),避免过度依赖教师。
-
3. 蒸馏形式扩展
-
响应式蒸馏(Response-Based):直接对齐教师与学生的输出层(如分类概率)。
-
特征式蒸馏(Feature-Based):匹配中间层特征(如使用L2损失对齐某层的特征图)。
-
关系式蒸馏(Relation-Based):捕捉样本间关系(如样本对的相似性矩阵)。
三、知识蒸馏的变体与优化方法
1. 离线蒸馏 vs 在线蒸馏
| 类型 | 离线蒸馏 | 在线蒸馏 |
|---|---|---|
| 教师模型 | 预训练固定模型 | 教师与学生模型联合训练 |
| 优点 | 简单、稳定 | 避免教师模型性能瓶颈 |
| 缺点 | 依赖教师模型质量 | 训练复杂度高,易过拟合 |
2. 自蒸馏(Self-Distillation)
-
同一模型的不同阶段知识迁移(如深层网络指导浅层)。
-
典型方法:DML(Deep Mutual Learning),多个学生模型互相学习。
3. 对抗蒸馏(Adversarial Distillation)
-
引入生成对抗网络(GAN),通过判别器促使学生模仿教师分布。
-
应用场景:图像生成、语音合成等生成任务。
四、知识蒸馏的挑战与未来方向
1. 技术挑战
-
容量差距问题:学生模型过小可能导致无法有效模仿教师。
-
多模态与动态蒸馏:如何迁移跨模态(文本+图像)和时序动态知识。
-
无标签数据蒸馏:仅依赖教师生成伪标签时的误差累积问题。
2. 未来方向
-
自动化蒸馏:通过NAS(神经架构搜索)自动设计学生模型结构。
-
联邦蒸馏:在隐私保护场景下,跨设备协作蒸馏。
-
量子化蒸馏:结合模型压缩技术(如8-bit量化)实现极致轻量化。
总结
知识蒸馏通过“师生互动”机制,将复杂模型的知识迁移至轻量模型中,在移动端推理、实时系统等领域具有重要价值。其核心在于软标签的温度调节与多目标损失设计,未来结合自动化、联邦学习等技术,或将成为AI普惠化落地的关键支撑。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)