手都敲麻了!Transformer超详细全解!含代码实战!
第二步:将得到的单词表示向量矩阵 (如上图所示,每一行是一个单词的表示x)传入Encoder中,经过6个Encoder block (编码器块)后可以得到句子所有单词的编码信息矩阵C。第一步:获取输入句子的每一个单词的表示向量X,X由单词本身的Embedding(Embedding就是从原始数据提取出来的特征(Feature)) 和单词位置的Embedding相加得到。Transformer的内部
一. Transformer的整体架构
在开始之前,我要给大家分享一份非常详细的入门学习路线思维导图,学习顺序、怎么学、看什么、要注意什么都写的非常清楚大家如果需要的话,可以添加我的小助手,让她把配套资料一起无偿分享给大家。

Transformer由Encoder (编码器)和Decoder (解码器)两个部分组成,Encoder和Decoder都包含6个block(块)。Transformer的工作流程大体如下:
第一步:获取输入句子的每一个单词的表示向量X,X由单词本身的Embedding(Embedding就是从原始数据提取出来的特征(Feature)) 和单词位置的Embedding相加得到。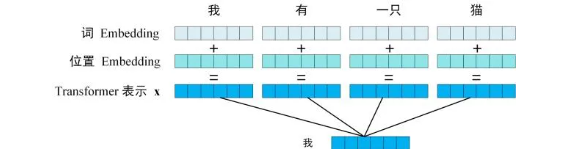
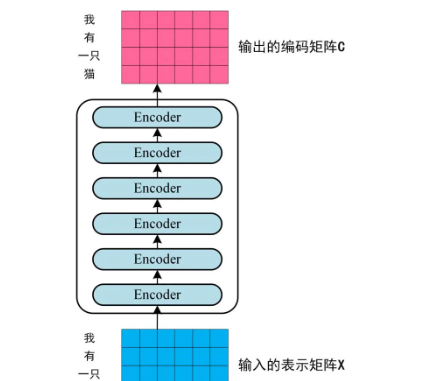
第二步:将得到的单词表示向量矩阵 (如上图所示,每一行是一个单词的表示x)传入Encoder中,经过6个Encoder block (编码器块)后可以得到句子所有单词的编码信息矩阵C。如下图,单词向量矩阵用
![]()
表示, n是句子中单词个数,d是表示向量的维度(论文中d=512)。每一个Encoder block (编码器块)输出的矩阵维度与输入完全一致。
第三步:将Encoder (编码器)输出的编码信息矩阵C传递到Decoder(解码器)中,Decoder(解码器) 依次会根据当前翻译过的单词1~i翻译下一个单词i+1,如下图所示。在使用的过程中,翻译到单词i+1的时候需要通过Mask (掩盖) 操作遮盖住i+1之后的单词。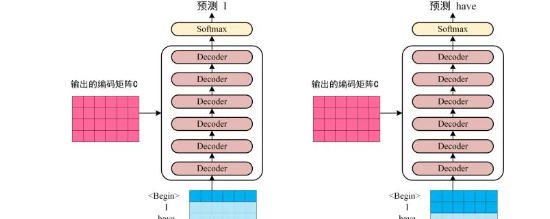
上图Decoder接收了Encoder的编码矩阵C,然后首先输入一个翻译开始符"<Begin>",预测第一个单词"I";然后输入翻译开始符"<Begin>"和单词"I",预测单词"have",以此类推。
二. Transformer 的输入
Transformer中单词的输入表示x由单词本身的Embedding和单词位置Embedding(Positional Encoding)相加得到。
2.1 单词 Embedding(词嵌入层)
单词本身的Embedding有很多种方式可以获取,例如可以采用Word2Vec、Glove等算法预训练得到,也可以在Transformer中训练得到。
self.embedding = nn.Embedding(vocabulary, dim)功能解释:
-
作用:将离散的整数索引(单词ID)转换为连续的向量表示
-
输入:形状为 [sequence_length] 的整数张量
-
输出:形状为 [sequence_length, dim] 的浮点数张量(,n是序列长度,d是特征维度)
工作原理:
-
创建一个可学习的嵌入矩阵[vocabulary, dim],例如当vocabulary=10000, dim=512时,是一个10000×512的矩阵;
-
每个整数索引对应矩阵中的一行:
# 假设单词"apple"的ID=42apple_vector = embedding_matrix[42] # 形状 [512]
在Transformer中的具体作用:
# 输入:src = torch.randint(0, 10000, (2, 10))# 形状:[batch_size=2, seq_len=10]src_embedded = self.embedding(src)# 输出形状变为:[2, 10, 512]# 每个整数单词ID被替换为512维的向量
可视化表现:
原始输入 (单词ID):[ [ 25, 198, 3000, ... ], # 句子1[ 1, 42, 999, ... ] ] # 句子2经过嵌入层后 (向量表示):[ [ [0.2, -0.5, ..., 1.3], # ID=25的向量[0.8, 0.1, ..., -0.9], # ID=198的向量... ],[ [0.9, -0.2, ..., 0.4], # ID=1的向量[0.3, 0.7, ..., -1.2], # ID=42的向量... ] ]
为什么需要词嵌入:
-
语义表示:相似的单词会有相似的向量表示
-
降维:将离散的ID映射到连续空间(one-hot编码需要10000维 → 嵌入只需512维)
-
可学习:在训练过程中,这些向量会不断调整以更好地表示语义关系
2.2 位置 Embedding(位置编码)
Transformer的位置编码(Positional Encoding,PE)是模型的关键创新之一,它解决了传统序列模型(如RNN)固有的顺序处理问题。Transformer的自注意力机制本身不具备感知序列位置的能力,位置编码通过向输入嵌入添加位置信息,使模型能够理解序列中元素的顺序关系。位置编码计算之后的输出维度和词嵌入层相同,均为(
![]()
)。
位置编码的核心作用:
-
注入位置信息:让模型区分不同位置的相同单词(如 "bank" 在句首vs句尾)
-
保持距离关系:编码相对位置和绝对位置信息
-
支持并行计算:避免像RNN那样依赖顺序处理
为什么需要位置编码?
-
自注意力的位置不变性:
![]()
,计算过程不包含位置信息
-
序列顺序的重要性:
-
自然语言:"猫追狗" ≠ "狗追猫"
-
时序数据:股价序列的顺序决定趋势替代方案对比
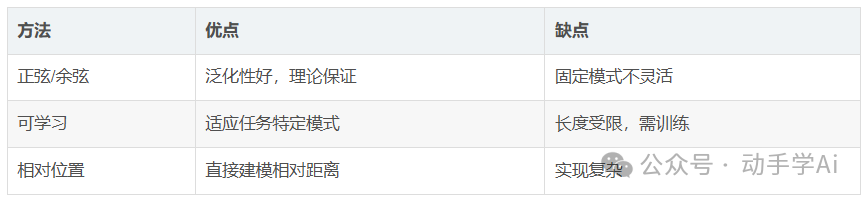
位置编码的实际效果
-
早期层作用:帮助模型建立位置感知
-
后期层作用:位置信息被融合到语义表示中
-
可视化示例
Input: [The, cat, sat, on, mat]Embed: [E_The, E_cat, E_sat, E_on, E_mat]Position: [P0, P1, P2, P3, P4]Final: [E_The+P0, E_cat+P1, ... E_mat+P4]
(1)正余弦位置编码(论文采用)
正余弦位置编码的计算公式:
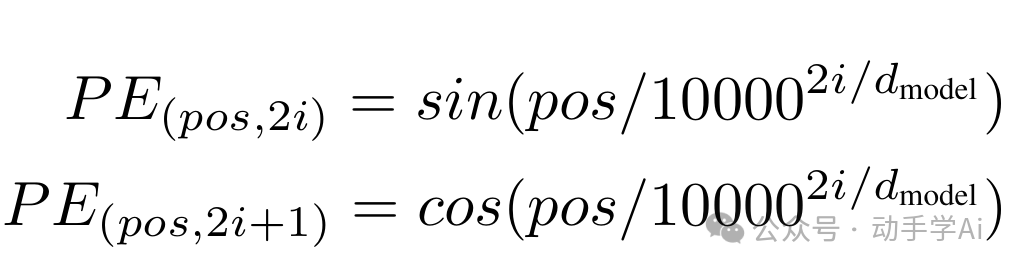
其中:
-
`pos` 是token在序列中的位置(从0开始)
-
`d_model` 是模型的嵌入维度(即每个token的向量维度)
-
`i` 是维度的索引(从0到d_model/2-1)
特点:
-
波长几何级数:覆盖不同频率
-
相对位置可学习:位置偏移的线性变换PE_{pos+k}可表示为PE_{pos}的线性函数
-
泛化性强:可处理比训练时更长的序列
-
对称性:sin/cos组合允许模型学习相对位置
代码实现:
class PositionalEncoding(nn.Module):# Sine-cosine positional codingdef __init__(self, emb_dim, max_len, freq=10000.0):super(PositionalEncoding, self).__init__()assert emb_dim > 0 and max_len > 0, 'emb_dim and max_len must be positive'self.emb_dim = emb_dimself.max_len = max_lenself.pe = torch.zeros(max_len, emb_dim)pos = torch.arange(0, max_len).unsqueeze(1)# pos: [max_len, 1]div = torch.pow(freq, torch.arange(0, emb_dim, 2) / emb_dim)# div: [ceil(emb_dim / 2)]self.pe[:, 0::2] = torch.sin(pos / div)# torch.sin(pos / div): [max_len, ceil(emb_dim / 2)]self.pe[:, 1::2] = torch.cos(pos / (div if emb_dim % 2 == 0 else div[:-1]))# torch.cos(pos / div): [max_len, floor(emb_dim / 2)]def forward(self, x, len=None):if len is None:len = x.size(-2)return x + self.pe[:len, :]
三. Self-Attention(自注意力机制)和Multi-Head Attention(多头自注意力)
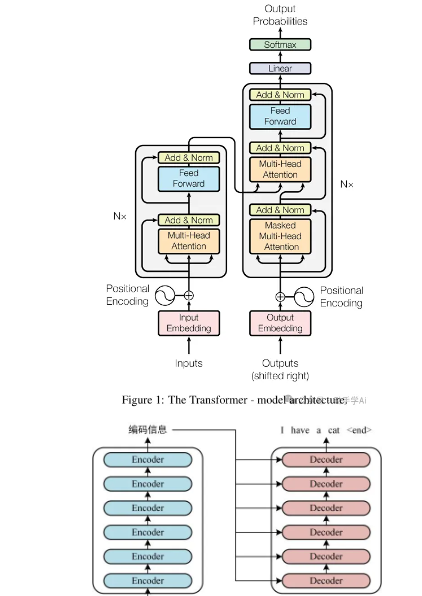
Transformer的内部结构图,左侧为Encoder block(编码器),右侧为Decoder block(解码器)。可以看到:
(1)Encoder block包含一个Multi-Head Attention;
(2)Decoder block包含两个Multi-Head Attention (其中有一个用到 Masked)。Multi-Head Attention上方还包括一个Add&Norm层,Add表示残差连接(Residual Connection),用于防止网络退化,Norm表Layer Normalization,用于对每一层的激活值进行归一化。
Multi-Head Attention是Transformer的重点,它由Self-Attention演变而来,我们先从 Self-Attention 讲起。
3.1 Self-Attention(自注意力机制)
Self-Attention(自注意力)是Transformer架构的核心创新,它彻底改变了序列建模的方式。与传统的循环神经网络(RNN)和卷积神经网络(CNN)不同,self-attention能够直接捕捉序列中任意两个元素之间的关系,无论它们之间的距离有多远:


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)