配送算法5 Decision models for order fulfillment processes of online food delivery platforms
这是一篇综述类型的论文,系统梳理了在线外卖平台(ODP)实时配送运营中的各类问题,并对现有的运筹学模型进行分类。研究将ODP运营划分为“配送前”与“配送”两阶段,指出现有文献主要聚焦于后者(分单、路径、调度、发单)。建模方法以优化与机器学习并重,机器学习应用呈上升趋势;求解方法从传统算法/启发式转向问题专属的新颖方法;绩效指标体系亦日趋多元。综述统一术语、厘清研究脉络,为后续研究奠定基础。
Decision models for order fulfillment processes of online food delivery platforms: a systematic review论文学习
这是一篇综述类型的论文,系统梳理了在线外卖平台(ODP)实时配送运营中的各类问题,并对现有的运筹学模型进行分类。研究将ODP运营划分为“配送前”与“配送”两阶段,指出现有文献主要聚焦于后者(分单、路径、调度、发单)。建模方法以优化与机器学习并重,机器学习应用呈上升趋势;求解方法从传统算法/启发式转向问题专属的新颖方法;绩效指标体系亦日趋多元。综述统一术语、厘清研究脉络,为后续研究奠定基础。

运营决策与建模
ODP 的每一次配送都需做出若干实时运营决策,这些决策普遍被抽象为运筹学(OR)模型。
最关键的决策是“指派(assignment)”和“路径(routing)”:
– 先决定由哪位骑手接单(assignment),
– 再为该骑手规划取餐-送餐的最优路线(routing)。
这些决策与车辆路径问题(VRP)及其子类“取送货问题”(PDP)同源,但 ODP 的独特之处在于:
– 指派与路径高度耦合,
– 需同时处理多单并发,
– 还涉及班次排班等额外决策。
ODP 与其他配送模式的区别
区别于生鲜电商:生鲜电商通常自营前置仓,骑手驻仓;ODP 则从分散的餐厅取餐,骑手初始位置不确定,使取餐指派更复杂。
区别于餐厅自营配送:本文仅聚焦“第三方”平台,不含餐厅自行配送的场景。
区别于同质化商品配送:ODP 配送的是易腐、异质的餐厅成品,对时效和品质要求更高。
ODP 订单履约问题(ODP-OFP)
定义为“从下单到送达”全过程中 ODP 必须依次解决的所有运营子问题。
两大阶段:
– 前置决策(Pre-delivery):服务范围、车队规模、骑手排班等;
– 即时决策(Delivery):对每一张订单循环执行指派、路径、调度、发单。
在 ODP 的“配送阶段”研究中,三大核心运营子问题——指派(Assignment)、路径(Routing)以及调度-发单(Scheduling & Dispatching)——各自扮演不同角色,并呈现出以下关键特征与研究热点:
首先,指派问题的核心任务是将新生成的订单与平台骑手进行匹配。现有文献主要围绕两个维度展开:一是决策发起方,既可以由平台根据距离、成本、骑手空闲状态等标准主动派单,也可以由骑手在系统内主动“抢单”或“选单”;二是决策时机,既可以订单一生成就立即指派再给骑手规划路线,也可以先把多个订单进行批处理(batching/bundling)后再统一指派给骑手,甚至先求解路径或调度,再反推指派结果。建模上,通常采用二分图匹配、层次分解法或 FIFO/优先级规则,并考虑骑手是否允许拒单、车辆异质性、时间窗与拥堵影响等因素。
其次,路径问题负责为已指派的骑手规划取餐-送餐的最优路线。研究者普遍将经典车辆路径问题(VRP)拓展为“带时间窗的取送货问题”(VRPPDTW)或专门针对外卖场景提出的“餐食配送路径问题”(MDRP/RMDP)。由于订单实时涌入,动态 VRP 与在线重算成为重点;同时,机器学习被用来预测行程时间,GIS/GPS 与 IoT 技术则提供了实时路况和餐品状态数据。实际应用中,平台既可以给出固定路线,也允许骑手基于自身经验微调或完全自行选择。
最后,调度-发单问题处理“多单并发”情境。调度关注为单个骑手排定多张订单的取送顺序,以最小化距离、时间或成本,并兼顾餐品新鲜度;发单则关注在每一决策窗口如何批量、有序地把众多任务分配给多位骑手,同时考虑公平性、骑手接单意愿及订单收益等多目标。实现方式上,常用滚动时域、博弈论或多目标优化,并尝试引入骑手偏好、公平性约束及实时反馈机制,以提高方案的可执行性和骑手满意度。
预配送问题(Pre-delivery problems)
在订单真正进入“配送阶段”之前,ODP 必须先完成一系列“预配送”决策,否则后续实时运营将无的放矢。文献将其归纳为四大核心问题:需求预测、服务范围划定、车队规模确定以及骑手排班,并附带讨论了无人机配送所需的设施选址等新兴议题。
-
需求预测(Demand Forecasting)
预测为所有后续决策提供输入。ODP 需要按地理网格、按天乃至按小时预测订单量,以决定资源投放。难点在于:- 数据源选择:历史数据便于提前部署,但精度低;实时数据预测更准确,却缺乏准备时间。
- 空间异质性:需求随地段、时段、天气、活动等剧烈波动。
- 方法:传统时序模型与机器学习(尤其融合 GIS 数据)并用;还借助仿真与实验评估动态定价、会员制等需求管理策略的效果。
-
服务覆盖范围(Service Coverage Area)
平台为每家餐厅划定可接单半径,既可直接按“距离圆”设定,也可依据顾客历史订单做动态重定向。- 静态划分便于骑手熟悉区域,但难以应对订单分布不确定性与拥堵;
- 动态调整则根据实时需求、骑手余量实时扩张或收缩区域,并支持跨区共享骑手。
当前研究尚未充分解决拥堵区域的定价与服务级别权衡问题。
-
车队规模(Fleet Sizing)
在已知预测需求与覆盖范围后,平台需决定各区域应投放多少骑手。- 目标是在满足服务水平(常用平均等候时间衡量)与最小化空驶/闲置间取得平衡。
- 手段包括:区域间共享骑手、动态增派、调整覆盖范围或提升拼单率以降低所需总人数。
- 行为挑战:“骑手流失”(courier drainage)导致热门区域骑手扎堆,冷门区域短缺;众包与混合运力模式为未来研究热点。
-
骑手排班(Shift Scheduling)
确定每位骑手的当班起止时间,以用最少人力覆盖波动需求。- 多数研究假设班次固定,但现实中平台提供不同灵活度(完全自由或部分约束)。
- 关键绩效指标:骑手成本、利用率、法规合规(各地劳动法差异)。
- 未来需结合众包骑手自排班行为及拒单不确定性,建立更贴合实际的排班模型。
-
无人机配送与设施选址(UAV & Facility Location)
疫情推动“无接触”配送,催生无人机送餐研究。- 新增预决策:无人机需在何处设置起降/充电站(facility location),其容量与布局直接影响后续路径。
- 地面设施:幽灵厨房、充电/停靠点同样需靠近需求中心,兼顾道路拥堵与空域安全。
- 未来方向:无人机-骑手混合运力、机器人协同及相应法规约束。
-
其他相关决策
车队构成(电动车/燃油车/无人机比例)、骑手预定位(re-positioning)、薪酬机制等虽常被归入车队规模或服务范围议题,但同样需要在预配送阶段一并考虑。
总体而言,预配送问题虽与实时运营同样关键,却受关注不足;大多数文献将其隐含在指派或路径模型中,仅有少数研究独立探讨。未来需加强对需求-资源-行为耦合的系统性建模,以支撑 ODP 在扩张与竞争中的盈利与效率目标。
ODP-OFP 问题延申
为将“ODP 订单履约问题(ODP-OFP)”嵌入不同业务场景,研究普遍通过两条主线对其进行扩展:
- 单次指派中同时考虑的订单-骑手匹配规模;
- 针对 ODP 特有运营情境所引入的假设与约束。
1. 匹配规模:1×1、m×1、m×n 三种范式
- 1×1:每来一张新订单,就立即在“当前所有空闲骑手中”挑一个最优者,完成指派+路径决策;不考虑后续订单。模型最简单,可重复求解,实时性好,但缺乏全局视野(图 5a)。
- m×1:在某一决策窗口内,先把 m 张订单“拼成”一个任务包(bundle),再为这个任务包挑一位最合适的骑手;只涉及“单骑手多订单”场景,可嵌套调度或路径优化(图 5b)。
- m×n:一次性把 m 张订单分配给 n 位骑手,即“多骑手-多订单”并发指派;通常以“发单(dispatching)”形式出现,可再细分为:
– 先打包再整体指派;
– 直接同时求解指派-路径-调度。
该范式最贴近真实高峰场景,但模型复杂度高,需要分解或滚动求解。
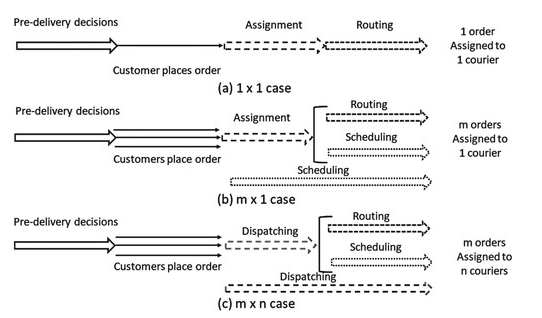
无论哪种范式,都可嵌入动态或随机要素:订单、骑手位置、路况持续更新;历史决策在下一轮迭代中可修正。
2. 关键假设与约束
这些假设把通用 VRP 改造成“真正属于 ODP”的问题,常见如下:
- 需求侧不确定性:订单到达率、下单前顾客/商家位置未知。
- 供给侧不确定性:众包骑手位置、在线状态、拒单或抢单行为。
- 订单处理特征:
– 拼单(bundling):上限由车辆容量或时空距离决定;需同时考虑多家餐厅的取餐点。
– 容量约束:每辆车同时可携带订单数上限。 - 骑手行为:
– 抢单(grabbing) vs 拒单(rejection) 两种模式互斥;前者为骑手主动选单,后者为平台派单后允许拒绝。 - 时间相关:
– 承诺送达时间(ETA)向顾客实时展示;
– 软时间窗,延迟罚金或提前奖励;
– 取餐-等餐-送餐三段时长的精确估计与动态更新。
通过组合上述假设,研究者可在 ODP-OFP 框架之上构建更贴近真实业务、但又不过度复杂的子模型,从而为不同规模、不同策略的 ODP 提供可操作、可解释的决策支持。
建模与求解方法的“三阶段进化”
2018-2019(起步期)
• 以 Reyes 等提出的 MDRP 为起点,研究集中在“如何把 ODP 流程公式化”;
• 主流工具:动态/整数规划 + 经典精确或启发式算法(branch-and-bound、ALNS 等)。
2020-2021(融合期)
• 机器学习首次大规模进入:监督学习、强化学习与优化模型嵌套;
• 同时出现 MDP、系统动力学等新范式;Ulmer 等提出 RMDP,成为与 MDRP 并列的两大标杆模型。
2022-2024(精修期)
• 优化与 ML 持续并存,但重点从“能否求解”转向“求解更快、更准”;
• 大量论文比拼算法效率与精度,ML 被用于加速组合优化、OR 用于提升 ML 策略的可行性;
• 绩效指标从“距离-时间-成本”扩展到“延迟订单-骑手空闲-模型复杂度-实时误差”等多维体系。
OR 提供结构化的决策模型,ML 提供高维行为/需求预测;
平台内部学者(尤其 Meituan 团队)率先把骑手轨迹、商家出餐数据喂给 ML,再把 ML 输出作为 OR 模型的实时输入,实现“预测-优化-闭环反馈”。
未来方向:统一框架下,ML 负责“感知+预测”,OR 负责“决策+控制”,以应对高动态、高不确定性的外卖网络。
ODP 运营没有“通用模板
不同市场在法规、劳动力结构、顾客期望、城市基础设施等方面差异显著,导致众包/专职骑手、无人机/人工配送、可拒单/强制派单等策略必须因地制宜;车辆容量、出餐时间、食品保鲜、时间窗、罚金、需求不确定性等参数也必须本地化校准。
方法论演进:OR + ML 成为主流
• 2018 以前:以 MDRP、RMDP 等整数规划/动态规划模型为主,用经典启发式求解。
• 2020 起:机器学习(监督、强化学习)与 MDP、系统动力学模型融合,用于预测需求、骑手行为并实时优化。
• 2022-2024:重点转向“毫秒级”算法效率与精度;绩效指标从“距离/时间/成本”扩展到“延迟订单、骑手空驶、模型复杂度”。
数据与地理高度集中
56.6 % 的论文使用真实 ODP 数据,其中中国(美团、饿了么)和美国(GrubHub)市场占绝对主导,印度(Swiggy)、意大利、土耳其等为补充。会议论文因与平台合作密切,提供了大量一手案例。
平台实践:研究反哺政策
美团、Swiggy 等平台已将最新 OR+ML 成果嵌入派单、调度、定价策略,实现持续迭代。
未来研究议程
• 实时计算瓶颈:需在毫秒级完成大规模组合优化,算法轻量化仍是刚需。
• 无人机配送:在基础设施允许的市场将进一步落地,但跨场景普适性仍待验证。
• 众包 vs 专职:高人力成本地区众包比例上升;低成本地区仍以专职为主。
• 研究空白:
– 骑手送完单后的“空驶/闲置”时间建模;
– 顾客当面拒收场景的应急策略;
– 将骑手满意度纳入多目标优化,实现平台-顾客-骑手三方共赢。
总体而言,本综述为对ODP 运营研究进行了结构化拆解,既总结了现有成果,也为后续研究与行业实践指明了可深耕的方向。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)