RAG优化:基于现代 SSD 的向量数据库性能优化总结
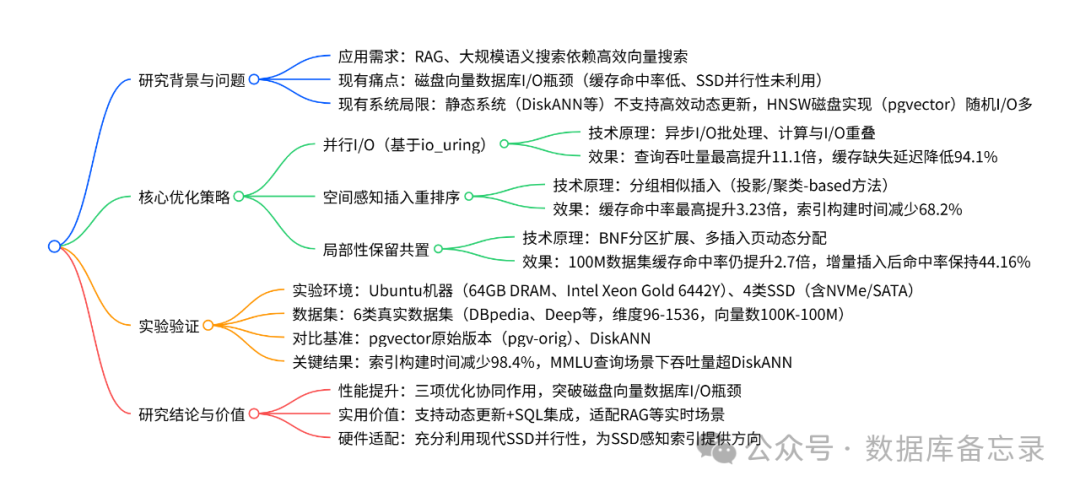
本文针对基于磁盘的向量数据库在AI应用中的I/O瓶颈问题,提出三项优化pgvector的核心技术:1)采用io_uring实现并行I/O,充分挖掘SSD并发性,查询QPS提升8.55倍;2)空间感知插入重排序提升缓存命中率,增量场景下保持74.35%命中率;3)局部性保留共置优化存储布局,使100M数据集缓存命中率仍提高2.7倍。实验表明,优化后的系统在真实数据集上实现查询吞吐量最高提升11.1倍
总览
针对基于磁盘的向量数据库在检索增强生成(RAG)等AI应用中面临的I/O瓶颈(如缓存命中率低、无法利用SSD并发性),提出了一套针对pgvector(PostgreSQL向量扩展)的优化方案。通过并行I/O(利用io_uring)、空间感知插入重排序和局部性保留共置三项核心技术,显著提升了系统性能。实验表明,优化后的系统在真实数据集上实现了查询吞吐量最高提升11.1倍、缓存命中率提高3.23倍、索引构建时间减少98.4%的卓越效果,同时支持动态更新,相比DiskANN等静态索引系统更贴近实际工业应用需求。
1. 研究背景与问题
- 需求驱动:大规模AI应用(如RAG)需要处理百亿级向量,内存数据库成本过高,因此基于磁盘的向量数据库成为必要选择。
- 现有局限:
- 静态索引系统(如DiskANN):不支持高效动态更新,更新困难且需周期性重建索引。
- 现有磁盘HNSW实现(如pgvector):存在严重性能瓶颈,包括贪心遍历导致频繁的随机I/O(底层缓存命中率仅57.49%)、顺序同步I/O无法利用现代SSD的高并发性(SSD利用率仅1.98%),导致整体性能低下。
2. 三项核心优化策略
研究团队提出了三项协同工作的优化技术,从I/O、数据和索引布局三个层面解决问题:
-
并行 I/O (Parallel I/O):
- 技术:采用Linux的
io_uring接口替代传统I/O,实现异步批处理,减少系统开销。并设计“计算-I/O重叠”机制,在计算时提前发起I/O请求,减少CPU等待时间。 - 效果:极大提升了SSD利用率。在DBpedia-1M数据集上,查询QPS提升8.55倍,增量插入时间减少85.07%。
- 技术:采用Linux的
-
空间感知插入重排序 (Spatially-Aware Insertion Reordering):
- 技术:利用相似向量遍历路径重叠的特性,对插入的向量进行重排序(使用PCA或K-means等方法),使空间上相近的向量在存储上也尽量接近,提高页面复用率和缓存效率。
- 效果:有效提升了缓存命中率。在增量插入场景下,缓存命中率显著优于原始版本。
-
局部性保留共置 (Locality-Preserving Co-location):
- 技术:重构索引存储布局。通过扩展BNF分区,将图节点与其邻居尽可能存放在同一存储页面;并采用“多插入页”策略,确保新增节点优先插入其邻居所在的分区,避免破坏局部性。
- 效果:在Deep数据集上,缓存命中率最高提升了3.23倍,且在1亿规模数据集上仍能保持2.7倍的提升。
3. 实验结果与价值
- 综合性能:在MMLU等查询场景下,优化后的pgvector吞吐量甚至超过了静态系统DiskANN。
- 动态更新优势:索引构建时间远少于DiskANN(如C4-100K数据集上,78秒 vs 823秒),并支持实时的增量插入和删除,无需重建索引。
- 实用价值:
- 实现了“高性能”与“支持动态更新”的双重目标。
- 作为PostgreSQL扩展,天然支持SQL,易于集成。
- 为如何针对现代SSD硬件特性优化向量索引提供了重要的设计思路和实践方向。
总而言之,该研究通过深入分析HNSW磁盘索引的性能瓶颈,并结合现代SSD的硬件特性,提出了一套行之有效的优化方案,极大地提升了基于磁盘的向量数据库的实用性,对推动RAG等实时AI应用的发展具有重要意义。
详细内容:
1. 一段话总结
为解决基于磁盘的向量数据库在检索增强生成(RAG) 和大规模语义搜索中面临的 I/O 瓶颈(如缓存命中率低、现代 SSD 架构利用效率不足),研究团队提出三项核心优化策略:一是利用io_uring实现并行 I/O,充分挖掘 SSD 并发性以降低检索延迟;二是空间感知插入重排序,基于局部性动态调整插入执行顺序提升缓存效率;三是局部性保留共置,重构索引布局减少高成本随机磁盘访问。这些优化在 pgvector(PostgreSQL 的向量搜索扩展)中实现后,在真实数据集上取得显著成效:查询吞吐量最高提升11.1 倍,缓存命中率提高3.23 倍,索引构建时间减少98.4%,且支持动态更新,相比 DiskANN 等静态索引系统更适配实际应用场景。
2. 思维导图(mindmap)
3. 详细总结
3.1 研究背景与核心问题
-
应用需求驱动
现代 AI 应用(如 RAG、大规模语义搜索)依赖密集向量嵌入的向量数据库,需兼顾效率与动态更新能力 —— 传统内存向量数据库因成本过高无法支撑百亿级向量,而磁盘向量数据库成为替代方案。 -
现有系统局限
- 静态索引系统
(如 DiskANN、ScaNN、SPANN):依赖乘积量化(PQ)或倒排文件索引(IVF),不支持高效动态更新,更新易导致召回率下降,需周期性重建索引(如 FreshDiskANN 需离线合并,存在延迟峰值)。
- HNSW 磁盘实现(pgvector)
:HNSW 作为支持动态更新的图索引,其磁盘版本存在两大问题:① 贪心图遍历导致频繁随机磁盘 I/O,低层索引缓存命中率极低(Layer 0 仅 57.49%);② 顺序同步 I/O 未利用现代 SSD 并行性,SSD 利用率仅 1.98%(表 2)。
- 静态索引系统
-
关键问题拆解
问题类型
具体表现
数据支撑
时间局部性低
50% 缓存分配下,pgvector 缓存命中率仅 59.24%
表 2(GloVe 数据集,50% 缓存)
空间局部性低
单查询访问 1961 个节点需加载 1887 个页面,页面复用率 0.96
2.3 节实验(GloVe 数据集)
SSD 并行性未利用
最新 SSD(SSD-A)单线程 118MB/s,64 线程 5606MB/s,但 pgvector 未利用
表 1(SSD-A 并行比 47.5 倍)
3.2 三项核心优化策略详解
3.2.1 并行 I/O:基于 io_uring 挖掘 SSD 并行性
- 技术原理
:
采用 Linux 内核的 io_uring 接口,通过用户态与内核态共享队列(提交队列 / 完成队列)实现异步 I/O 批处理,避免传统 AIO/epoll 的高开销;同时设计 “计算 - I/O 重叠” 机制,在缓存邻居距离计算前提前发起未缓存邻居的 I/O 请求,通过实时轮询(peeking)触发完成 I/O 的计算,减少 CPU 空闲时间。 - 关键参数
:io_uring 深度设为 2×m(m 为 HNSW 节点最大邻居数),min_complete 设为 6 以平衡响应性与 CPU 开销。
- 性能效果
:
-
在 DBpedia-1M 数据集上,10% 缓存下查询 QPS 从 13.02 提升至 111.4(8.55 倍),SSD-A 上缓存缺失延迟降低 94.1%;
-
索引增量插入(1% 数据)时间从 2566.29 秒降至 383.04 秒(减少 85.07%)。
-
3.2.2 空间感知插入重排序:提升缓存效率
- 技术原理
:
利用 “相似查询向量遍历重叠图区域” 的特性(图 5,余弦相似度高的向量路径重叠率高),通过重排序使相邻插入的向量空间距离更近,提升页面复用率。分为两类方法:- 投影 - based 方法
(如 PCA):低计算开销,重排序时间短(PCA 处理 DBpedia-1M 仅 10.39 秒);
- 聚类 - based 方法
(如 K-means):利用数据内在结构,缓存命中率更高(K-means 达 86.62%)。
- 投影 - based 方法
- 优化场景
:
-
全量索引:重排序整个数据集,索引构建时间减少 68.2%(PCA);
-
增量索引:仅重排序新增数据(5%),K-means 重排序时间 25.2 秒,缓存命中率保持 74.35%。
-
3.2.3 局部性保留共置:减少随机 I/O
- 技术原理
:
-
扩展 BNF(Block Neighbor Frequency)分区:将节点分配到邻居最多的页面,支持动态调整分区大小;
-
多插入页策略(算法 2):为每个分区分配插入页,新增节点优先放入邻居所在分区的插入页,满页则扩展,无适配分区时用备用页,避免顺序追加导致的局部性破坏。
-
- 性能效果
:
-
分区节点数 64 时效果饱和,Deep 数据集缓存命中率从 15.84% 升至 51.19%(3.23 倍);
-
100M 数据集(Deep)下,缓存命中率仍比原始版本高 2.7 倍;
-
90% 增量插入场景下,命中率保持 44.16%,是原始版本(19.14%)的 2.31 倍。
-
3.3 实验设计与关键结果
3.3.1 实验基础信息
|
类别 |
详情 |
|---|---|
|
硬件环境 |
CPU:Intel Xeon Gold 6442Y(24 核);内存:64GB DRAM;存储:4 类 SSD(SSD-A:Samsung PM1743(NVMe,4TB)、SSD-D:Samsung 850 Pro(SATA,512GB)) |
|
软件环境 |
数据库:PostgreSQL 17 + pgvector 0.8.0;I/O 工具:liburing 2.9、FIO 3.38;HNSW 参数:ef_construction=200,m=24 |
|
数据集 |
6 类真实数据集(表 4),覆盖文本、图像嵌入,维度 96-1536,向量数 100K-100M,查询数 10K-100K |
|
对比基准 |
1. pgv-orig:未优化的 pgvector;2. DiskANN:静态磁盘 ANN 系统(PQ 压缩,不支持动态更新) |
3.3.2 核心性能指标对比(部分关键结果)
|
优化方向 |
对比场景 |
关键指标 |
pgv-orig |
优化后(pgv-ours) |
提升幅度 |
|---|---|---|---|---|---|
|
并行 I/O |
DBpedia-1M(10% 缓存) |
查询 QPS |
13.02 |
111.4 |
8.55 倍 |
|
插入重排序 |
Deep-100K(全量索引) |
索引构建时间 |
- |
减少 68.2%(PCA) |
3.15 倍 |
|
局部性共置 |
Deep-100M |
缓存命中率 |
- |
2.7 倍 |
2.7 倍 |
|
综合优化 |
C4-5M(MMLU 查询) |
吞吐量 |
低于 DiskANN |
超 DiskANN |
- |
|
综合优化 |
Deep-1M |
索引构建时间 |
147 秒 |
77 秒 |
1.91 倍 |
3.3.3 与 DiskANN 的关键差异
|
特性 |
DiskANN |
pgv-ours(优化后 pgvector) |
|---|---|---|
|
动态更新 |
不支持(静态) |
支持(增量插入 / 删除) |
|
数据处理 |
PQ 压缩向量(精度损失) |
全精度向量 |
|
索引构建时间 |
C4-100K 需 823 秒 |
C4-100K 仅需 78 秒 |
|
缓存友好场景(MMLU) |
吞吐量低 |
吞吐量超 DiskANN |
|
SQL 集成 |
不支持 |
支持(PostgreSQL 扩展) |
3.4 研究结论与价值
- 性能突破
:三项优化从 I/O 并行性、数据局部性、索引布局三方面解决磁盘向量数据库瓶颈,实现 “动态更新 + 高性能” 双重目标;
- 实用价值
:适配 RAG 等需实时更新的场景,且支持 SQL 集成,比静态系统更贴近工业应用;
- 硬件适配
:首次系统研究 HNSW 索引的 SSD 感知优化,为现代 SSD 硬件特性与向量索引的协同设计提供方向。
4. 关键问题
问题 1:相比传统静态向量索引系统(如 DiskANN),本文提出的优化方案在动态更新场景下的核心优势是什么?如何通过实验验证这一优势?
答案:核心优势是支持高效动态增量更新,且更新后仍保持高查询性能,而 DiskANN 等静态系统需离线合并索引,存在延迟峰值和召回率下降问题。
实验验证方式:① 设计增量插入场景(95% 数据预索引,5% 增量插入),pgv-ours(优化后)在 Deep-100K 数据集上,增量插入后缓存命中率保持 74.35%(PCA)-86.58%(K-means),而 pgv-orig 仅 53.37%;② 对比索引构建时间,在 C4-100K 数据集上,DiskANN 构建时间 823 秒,pgv-ours 仅 78 秒,且支持边插入边查询,无需全量重建;③ 90% 增量插入场景下,pgv-ours 命中率仍达 44.16%,是 pgv-orig(19.14%)的 2.31 倍,证明动态更新后局部性未严重退化。
问题 2:本文提出的 “并行 I/O” 优化基于 io_uring 实现,其相比传统 I/O 机制(如 epoll、AIO)在向量搜索场景下的技术优势是什么?有哪些关键实验数据支撑这一优势?
答案:技术优势在于更低的 I/O 开销和更高的并行性利用率:① io_uring 通过用户态 - 内核态共享队列实现 I/O 批处理,减少系统调用和上下文切换;② 支持 “计算与 I/O 重叠”,避免 CPU 等待 I/O 空闲,而 epoll/AIO 难以高效实现这一协同。
关键实验数据:① SSD-A(最新 NVMe)上,pgv-async-iou(并行 I/O 优化)在 30 并发时达到 8902MB/s 带宽,而 pgv-orig(传统 I/O)需 200 并发才达 7984MB/s,证明低并发即可高效利用 SSD 带宽;② DBpedia-1M 数据集 10% 缓存场景下,pgv-async-iou 查询 QPS 达 111.4,是 pgv-orig(13.02)的 8.55 倍;③ 缓存缺失延迟方面,pgv-async-iou 在 SSD-A 上比 pgv-orig 降低 94.1%,在 SSD-D(老款 SATA)上降低 80.5%,验证并行 I/O 对不同 SSD 的普适性。
问题 3:“局部性保留共置” 优化旨在解决 HNSW 磁盘索引的空间局部性问题,其核心技术思路是什么?在大规模数据集(如 100M 向量)上的效果如何?为什么能在大规模场景下保持有效性?
答案:核心技术思路是基于图邻居关系优化存储布局:① 扩展 BNF(Block Neighbor Frequency)分区,将节点分配到 “包含其最多邻居” 的页面,确保强连接节点共置;② 引入 “多插入页” 机制,为每个分区动态分配插入页,新增节点优先放入邻居所在分区的插入页,避免顺序追加破坏局部性,仅在无适配分区时使用备用页。
大规模数据集效果:在 Deep-100M 数据集(96 维向量)上,pgv-ours 的缓存命中率仍比 pgv-orig 提升 2.7 倍,且索引页面增长仅 7%(90% 分区使用插入页时),未导致存储膨胀。
大规模场景有效性原因:① 分区策略基于 HNSW 的 “小世界特性”—— 节点邻居多集中在局部区域,分区切割的关键边少;② 多插入页动态调整,避免增量插入导致的 “邻居分散”,即使数据集增大,节点与邻居的共置率仍能维持;③ 分区粒度适配 SSD 页面大小(8KB),100M 数据下仍能通过预聚类减少跨页访问,故局部性提升效果稳定。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)