TIFS2024 | PE攻击: 基于Transformer模型中通用位置嵌入的漏洞
本文 “PE-Attack: On the Universal Positional Embedding Vulnerability in Transformer-Based Models” 指出 Transformer 模型中位置嵌入(PEs)存在潜在漏洞。
PE-Attack: On the Universal Positional Embedding Vulnerability in Transformer-Based Models

本文 “PE-Attack: On the Universal Positional Embedding Vulnerability in Transformer-Based Models” 指出 Transformer 模型中位置嵌入(PEs)存在潜在漏洞。研究人员开发了如 FreqHack、PhaseShift 和 PosTA 等输入感染技术,提出 PE-attack 对抗攻击方法。通过在时间序列分析、自然语言处理和计算机视觉任务上实验,发现 PEs 的脆弱性具有普遍性和迁移性,这为 Transformer 模型设计敲响警钟,同时文章还分析了攻击效果、计算开销并提出潜在缓解策略。
摘要-Abstract
The Transformer model has gained significant recognition for its remarkable computational capabilities and versatility, positioning itself as a fundamental component in numerous practical applications. However, the robustness of the Transformer model, specifically its stability and reliability under various types of adversarial attacks, is of utmost importance for its practical applicability. Furthermore, it offers valuable insights for the design of more efficient and secure models. In contrast with conventional investigations into adversarial robustness, our study focuses on the analysis of Positional Embeddings (PEs), a crucial component that sets the Transformer model apart from previous model architectures. Theoretical analysis of PEs has been limited due to previous predominantly empirical design, which includes features such as sinusoidal or linear patterns, learned or fixed characteristics, and absolute or relative measurements. Our investigation delves deep into potential vulnerabilities within PEs. Initially, we develop a set of input infection techniques that can be universally applied to exploit vulnerabilities present in the Transformer architecture and its variants. In addition, we propose a novel adversarial attack that manipulates the model by providing it with incorrect positional information, enabling an evasion attack. Significantly, in contrast to previous attacks that were limited to a single task, our conducted experiments involving time-series analysis, natural language processing, and computer vision indicate that the susceptibility of PEs could be universal and transferable. This finding serves as a significant warning for future Transformer-based model design, urging researchers to consider potential security risks inherent in the model’s structure.
Transformer 模型因其卓越的计算能力和通用性而获得广泛认可,已成为众多实际应用中的基础组件。然而,Transformer 模型的鲁棒性,尤其是在各类对抗攻击下的稳定性和可靠性,对其实际应用至关重要。此外,这也为设计更高效、更安全的模型提供了宝贵的见解。与传统的对抗鲁棒性研究不同,我们的研究重点在于分析位置嵌入(PEs)。位置嵌入是使 Transformer 模型区别于以往模型架构的关键组件。由于以往位置嵌入主要基于经验设计,包含正弦或线性模式、可学习或固定特性以及绝对或相对测量等特征,对其进行理论分析存在一定局限性。我们深入探究了位置嵌入中潜在的漏洞。首先,我们开发了一组输入干扰技术,这些技术可普遍应用于利用 Transformer 架构及其变体中存在的漏洞。此外,我们提出了一种新颖的对抗攻击方法,通过向模型提供错误的位置信息来操控模型,实现逃避攻击。值得注意的是,与以往局限于单一任务的攻击不同,我们在时间序列分析、自然语言处理和计算机视觉等领域开展的实验表明,位置嵌入的脆弱性可能具有普遍性和转移性。这一发现为未来基于 Transformer 的模型设计敲响了警钟,促使研究人员考虑模型结构中固有的潜在安全风险。
引言-Introduction
这部分内容主要介绍了研究背景和动机,具体如下:
- Transformer 模型的应用与挑战:Transformer 模型在自然语言处理、计算机视觉、时间序列数据分析和网络安全等众多领域取得了革命性进展,展现出卓越性能和广泛适用性。但在复杂现实任务中,其行为仍有待深入理解,在安全敏感应用里,模型对对抗数据的抗性评估至关重要。因此,设计对抗攻击是研究 Transformer 模型鲁棒性的有效途径。
- 位置嵌入(PEs)的重要性与问题:Transformer 模型依靠 PEs 捕捉序列输入的顺序信息,不同形式的 PEs 不断发展,对模型性能和适用性贡献显著。然而,现有针对 Transformer 模型的对抗攻击研究多局限于特定任务,对位置编码机制潜在漏洞的探索不足。已有研究虽发现 PEs 的脆弱性可能降低模型鲁棒性,但未从更根本和普遍的角度探究基于 Transformer 的模型为何出现此类问题。
- 研究目标与方法:本文旨在研究 PEs 所代表的位置信息,以及增强后的 PEs 是否存在导致模型失效的固有结构漏洞。为此,研究人员全面分析了现有主流 PEs,开发了 FreqHack、PhaseShift 和 PosTA 三种输入扰动方法(atom noise),并提出一种名为 PE-attack 的白盒逃避攻击,通过在多种数据类型上实验,检验对 Transformer 模型的潜在广泛影响。
- 研究贡献:全面分析了不同领域中 PEs 的漏洞;开发了多种可普遍应用的技术来利用 Transformer 架构及其衍生模型中的漏洞;研究了 PE 引导的对抗攻击对时间序列分析、计算机视觉和自然语言处理任务的影响,实验结果表明位置漏洞广泛存在,凸显了提升模型鲁棒性的紧迫性。

图1. PEs 攻击的一个实例。PEs 为找出最易受攻击的 patch 提供了非常有用的信息。在 CIFAR100 数据集上,仅对 4 个 patch 添加扰动,ViT 模型的准确率就可从 91.48% 迅速降至 24.32%。这种脆弱性可迁移到不同的任务和不同的基于 Transformer 的架构中。
相关工作-Related Work
这部分主要介绍了与本文研究相关的工作,包括位置嵌入和 Transformer 的对抗鲁棒性两个方面的研究进展与不足,为后续研究的开展提供了背景和基础,具体内容如下:
- 位置嵌入
- 传统方法:在数据表示中,顺序信息至关重要。传统上,循环神经网络(RNNs)如长短期记忆网络(LSTM)和门控循环单元(GRU),利用隐藏状态来表示序列信息,通过时间反向传播(BPTT)更新权重,从而有效捕捉顺序信息。
- Transformer 的位置嵌入:由于 RNNs 和 BPTT 在现代 GPU 计算中存在并行化挑战,效率较低。因此,诸如卷积 seq2seq 和 Transformer 等方法采用特征级位置编码。Transformer 模型引入可学习的位置嵌入来表示序列中的位置。有研究对 Transformer 在不同 NLP 任务中学习的位置信息进行了探索,也有研究发现位置编码在计算机视觉任务中可能导致模型鲁棒性降低。
- Transformer 的对抗鲁棒性
- 研究现状:神经网络模型的对抗攻击最早在基于 CNN 的图像分类中展开研究。此后,针对神经网络模型在对抗输入下的鲁棒性评估研究不断涌现,涵盖计算机视觉、NLP、预测任务等多个领域,同时也提出了多种攻击方法来生成对抗样本。在 Transformer 模型成功应用后,其对抗攻击的概念得到进一步探索,研究表明 Transformer 模型在某些攻击方式下比 RNN 模型更鲁棒,且在对抗鲁棒性方面优于 CNNs。此外,还有研究从理论上构建了更严格边界的鲁棒性验证方法。
- 存在问题:关于 Transformer 模型独特的鲁棒性漏洞,有研究指出其在嵌入空间中存在激进更新和缺乏平滑性的问题,导致无法实现鲁棒性。也有研究提出了一些攻击方法来提高对抗样本在不同 ViT 模型间的迁移性,同时观察到 PEs 的脆弱性可能降低模型鲁棒性。然而,目前对 Transformer 模型结构的研究仍存在许多未解决的问题,本文旨在进一步探究其架构弱点,评估 Transformer 模型的鲁棒性。
预备知识-Preliminaries
该部分主要介绍了 Transformer 模型及输入表示的相关基础知识,为后续理解攻击方法的设计和实验分析做铺垫,具体内容如下:
- Transformer 模型:Transformer 模型处理的序列输入通常表示为向量序列 X = { x 1 , . . . , x T x } X = \{x_{1},..., x_{T_{x}}\} X={x1,...,xTx},用矩阵 x x x 表示输入,输出为 Y = { y 1 , . . . , y T y } Y = \{y_{1},..., y_{T_{y}}\} Y={y1,...,yTy},其核心是学习从 X X X 到 Y Y Y 的映射 f f f 。该模型基于自注意力机制,将输入通过线性变换投影为查询 Q Q Q、键 K K K 和值 V V V,计算注意力分数 S ( Q , K , V ) S(Q, K, V) S(Q,K,V)。实际应用中,会在自注意力层添加输入 x x x 的残差连接并进行层归一化,再将特征图输入两层全连接前馈网络。通过堆叠多个类似的自注意力层构建解码器,并利用掩码自注意力机制建立通用映射 f f f,编码器的特征图作为解码器的输入。
- 输入表示:自注意力机制无法捕捉序列输入的级联属性,因此引入位置嵌入来注入输入上下文的相对或绝对位置信息。不同任务中,Transformer 模型的输入表示有所不同,一般公式为 x ^ i = g ( x i ) + E p o s ( i ) + E e x t r a ( x i ) \hat{x}_{i} = g(x_{i}) + E_{pos}(i) + E_{extra}(x_{i}) x^i=g(xi)+Epos(i)+Eextra(xi) ,其中 g ( − ) g(-) g(−) 是输入的预处理函数, E p o s E_{pos} Epos 表示位置嵌入, E e x t r a E_{extra} Eextra 是 Transformer 变体带来的额外嵌入。在 NLP 任务中, g ( x ) = x g(x)=x g(x)=x;时间序列任务中, g ( x ) g(x) g(x) 用于对齐特征维度和增强局部信息;视觉任务中,输入图像会先被划分为 patch, E p o s E_{pos} Epos 表示 patch 间的相对距离。经典 Transformer 使用正弦和余弦函数作为预计算位置嵌入(PPE),其定义基于不同频率的正弦函数,能使每个输入项具有独特的位置嵌入,并通过仿射变换捕捉位置关系。
PE-Attck的设计-Design Of PE-Attack
PE-Attck的直觉-Intuition of PE-Attacks
这部分内容通过直观示例引入 PE 攻击的概念,阐述攻击者能力限制,分析不同任务中攻击输入表示时噪声的处理方式,并提出在避免直接扰动PEs的情况下思考攻击策略的问题,具体如下:
- PE攻击的直观示例:以邮递员送信为例,形象地展示了 PE 攻击的原理。在这个类比中,位置嵌入就像邮编,Transformer 模型如同地址,通过篡改位置嵌入(邮编被篡改)来欺骗模型(信件被送到错误地址),从而改变注意力分数(信件被错误转发),直观呈现了 PE 攻击对输入嵌入、位置嵌入和注意力分数的影响。
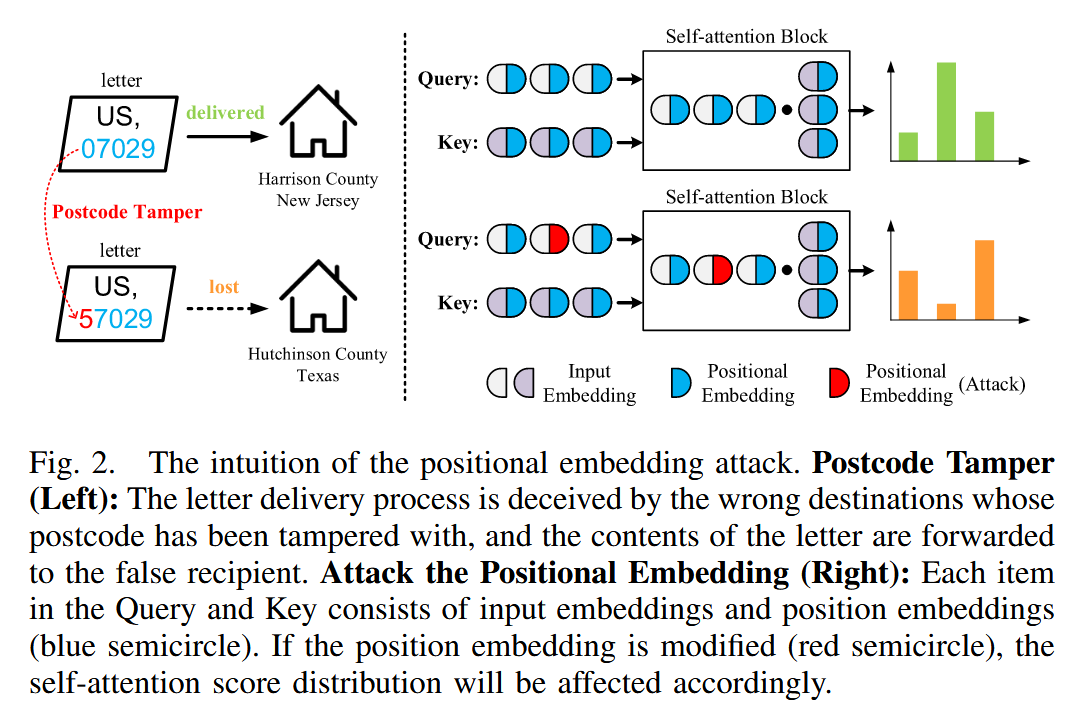
图2. 位置嵌入攻击的直观示意。邮编篡改(左图):信件投递过程被邮编遭篡改的错误地址所误导,信件内容被转发给错误的收件人。攻击位置嵌入(右图):查询(Query)和键(Key)中的每个元素都由输入嵌入和位置嵌入(蓝色半圆)组成。如果位置嵌入被修改(红色半圆),自注意力分数分布将相应受到影响。 - 攻击者的能力限制:研究设定攻击者仅能对输入数据进行篡改,在模型推理过程中无法更改中间参数。在此限制下,先推导输入特征与 PEs 之间的关系,以此深入了解模型在面对输入受限的攻击者时,潜在的漏洞以及模型的鲁棒性表现。
- 不同任务中攻击输入表示的方式:在对输入表示进行测试时的逃避攻击(test-time evasions),主要通过向输入添加噪声实现,公式为 x i ′ = x i + Δ x i x_{i}' = x_{i}+\Delta x_{i} xi′=xi+Δxi,并且噪声会聚合到相应的位置嵌入 E p o s ( i ) E_{pos}(i) Epos(i) 中 。不同任务中,噪声的处理方式有所不同:
- 在 NLP 问题里, g ( x ) = x g(x)=x g(x)=x,噪声直接附加到位置嵌入上。
- 对于视觉问题,噪声首先通过图像分块操作进行聚合。
- 时间序列任务中,则需要像 1D 卷积这样的位置变换 g ( − ) g(-) g(−),对每个位置应用相同的线性变换。
- 攻击策略的思考:由于在正向传播阶段不能简单地直接向 PEs 引入扰动,所以需要思考其他可行的攻击策略,为后续介绍具体的攻击方法做铺垫。
威胁模型-Threat Model
这部分内容主要定义了在 PE 攻击场景下的威胁模型,包括对手的攻击目标和所具备的知识,具体如下:
- 对手目标:聚焦于逃避攻击,在机器翻译、分类、时间序列预测等机器学习任务中,这些任务在处理良性测试样本时通常表现良好。对手虽无权修改模型架构或参数,但试图创建欺骗性样本,使机器学习模型做出错误预测,进而破坏模型的正常功能和准确性。
- 对手知识:假设对手能够获取目标神经网络的所有信息,涵盖模型架构、参数、梯度等。基于这些全面的信息,对手可以充分利用网络特性,精心设计和构造对抗样本。白盒攻击受到广泛研究主要有两个原因:其一,模型架构和参数的披露有助于人们清晰认识网络的薄弱环节,因此机器学习模型具备对白盒攻击的抵抗能力是理想的特性;其二,即便只能通过黑盒方式访问目标模型,也可以训练一个替代模型,在白盒环境下对替代模型发起攻击,且攻击效果能够迁移到目标模型上。
逐位置噪声注入-Position-Wise Noise Injection
这部分内容主要介绍了通过位置噪声注入攻击 Transformer 模型中位置嵌入的方法,旨在破坏其线性属性,进而影响模型性能,具体内容如下:
- 攻击原理:Transformer 模型依赖位置嵌入的线性属性来处理序列顺序,两个输入项的位置关系可通过其位置嵌入 E p o s E_{pos} Epos 的仿射变换来建模。若能破坏这种线性属性,就能干扰模型对位置信息的处理,导致其性能下降。通过对输入添加噪声,研究线性变换 g ( ⋅ ) g(\cdot) g(⋅) 在噪声注入后的影响,以此来设计攻击方法。
- 具体攻击方法
- FreqHack:现有针对 Transformer 模型的攻击方法多为替换或修改部分输入,而 FreqHack 专注于位置嵌入的鲁棒性。预计算位置嵌入(PPE)在测量局部位置信息相似性时呈现明显周期性模式,FreqHack 通过在输入表示中添加随机正弦符号来误导 Transformer 模型的顺序信息。具体做法是在一定范围内采样 m j m_{j} mj,为位置嵌入添加随机频率的正弦符号,公式为 Δ x i , 2 j = s i n ( i / ϕ ( m j ) ) \Delta x_{i, 2j} = sin(i / \phi(m_{j})) Δxi,2j=sin(i/ϕ(mj)), Δ x i , 2 j + 1 = c o s ( i / ϕ ( m j ) ) \Delta x_{i, 2j + 1} = cos(i / \phi(m_{j})) Δxi,2j+1=cos(i/ϕ(mj)).
- PhaseShift:添加随机正弦符号虽会给模型学习带来困难,但线性属性仍可能保持。为打破线性属性,PhaseShift 采用 “未见” 的正弦符号作为噪声注入目标。通过重新表述输入噪声,使噪声项 N ( i , 2 j ) N(i,2j) N(i,2j) 添加具有不同相位的正弦信号到嵌入 E ( i + j ) 2 k E(i + j)_{2k} E(i+j)2k 中,从而破坏其与原始嵌入的线性组合关系。通过设定系数条件,推导出噪声的计算公式为 Δ x i , 2 j = t a n ( m i / ϕ ( j ) ) 1 / ( σ ( t a n 2 ( m i / ϕ ( j ) ) + 1 ) ) \Delta x_{i, 2j} = tan(m_{i} / \phi(j)) \sqrt{1 / (\sigma(tan^{2}(m_{i} / \phi(j)) + 1))} Δxi,2j=tan(mi/ϕ(j))1/(σ(tan2(mi/ϕ(j))+1)), Δ x i , 2 j + 1 = 1 / ( σ ( t a n 2 ( m i / ϕ ( j ) ) + 1 ) ) \Delta x_{i, 2j + 1} = \sqrt{1 / (\sigma(tan^{2}(m_{i} / \phi(j)) + 1))} Δxi,2j+1=1/(σ(tan2(mi/ϕ(j))+1)).
- PosTA:前两种攻击方法对正弦 PPE 有一定效果,但 Transformer 对局部位置有自适应能力,且像 BERT 变体采用的可学习位置嵌入(LPE)更关注局部位置信息。PosTA 受可解释模型启发,引入高斯混合模型(GMM)来近似攻击分布。通过用两种原子噪声对选定样本进行攻击并收集输出,使用 EM 算法训练 GMM,以更有效地攻击可学习位置嵌入。
位置嵌入引导的对抗攻击-PEs-Guided Adversarial Attack
这部分内容主要介绍了 PEs 引导的对抗攻击方法,通过改进传统对抗攻击方式,利用PEs的位置信号来增强攻击效果,具体内容如下:
- 攻击思路:旨在探究 PEs 是否有助于生成对抗样本,将传统的对抗攻击转换为基于位置的公式。以著名的 FGSM 攻击为例,把生成对抗样本的噪声项 ϵ ∗ s i g n ( ∇ x J ( θ , ( x ) , y ) ) \epsilon * sign(\nabla_{x}J(\theta,(x), y)) ϵ∗sign(∇xJ(θ,(x),y)) 转换为与位置相关的 ϵ ∗ s i g n ( ∇ P E J ( θ , P E , y ) ) \epsilon * sign(\nabla_{PE}J(\theta, PE, y)) ϵ∗sign(∇PEJ(θ,PE,y)),以此发起逐位置攻击。
- 攻击实施:通过算法实现攻击过程。首先计算关于位置嵌入的损失梯度 ∇ P E J ( θ , P E , y ) \nabla_{PE}J(\theta, PE, y) ∇PEJ(θ,PE,y),并进行投影操作(如使用快速傅里叶变换 FFT 或主成分分析 PCA);接着根据投影后的结果选择激活特征排名前 k k k的 token 或 patch;最后,仅对选定的输入子集(如在图像分类任务中的部分图像 patch)应用现有的扰动生成方法,生成对抗样本。这样的攻击方式聚焦于输入的薄弱位置,能够减少对抗样本与原始样本的差异,提高攻击效率,同时使攻击效果更具可解释性。
- 攻击优势:与在整个输入上生成对抗扰动不同,PEs 引导的对抗攻击通过关注输入的位置弱点,仅在部分输入上生成扰动。这种方式不仅提高了攻击的效率,还使得攻击在人类感知层面更易理解,因为它更有针对性地对可能影响模型判断的关键位置进行干扰,从而在保持样本外观相似的情况下,更有效地使模型做出错误预测。
更广泛的影响-Broader Impact
这部分内容主要阐述了文章所提攻击方法在多方面的拓展应用及其产生的广泛影响,涵盖攻击方法增强、适用场景以及对模型发展和相关平台的影响,具体内容如下:
- 攻击方法的增强途径
- 结合 LIME 方法:在 PE 攻击中,可利用 LIME 方法增强基于高斯混合模型的 PosTA 攻击。LIME 方法基于给定的高斯分布参数生成随机数,记录随机数出现频率并返回最频繁的值,以此在模拟攻击过程中根据数据分布特征选择最具影响力的攻击强度或特征。
- 使用其他噪声生成器:在某些位置信息重要性较低的任务(如部分图像分类任务)中,可先利用 PEs 引导的对抗攻击定位敏感位置,再使用如 LaVAN 和 PGD 等先进噪声生成器向每个选定的敏感位置(如图像 patch)单独注入噪声,从而增强攻击效果。
- 优化 NLP 任务中的扰动:在 NLP 任务里,为实现更细微的扰动,从所有候选攻击采样标记中选择影响最小的标记。通过比较扰动前后文本的 BLEU 分数,确保噪声注入不易被人察觉,在降低文本质量影响的同时达到攻击目的。
- 攻击方法的适用场景与影响
- 广泛的适用性:所提出的一系列针对 PE 的攻击方法适用于多种攻击场景,包括白盒和黑盒环境,随着深度学习应用的普及,这些方法可能对各类在线服务(如在线翻译服务)产生影响。
- 推动模型发展:该攻击方法能够识别 Transformer 模型的漏洞,有助于推动各领域(如 NLP、CV 等)开发更鲁棒的模型。例如,像 BERT 和 Swin-Transformer 这样的大规模预训练模型,可通过使用受该方法扰动的样本进行对抗训练,提升自身的鲁棒性。
- 影响模型供应链:文章所提方法为预训练模型供应链(如 Huggingface 和 TensorHub 等平台)带来新的关注点。这些平台可能需要采用额外的攻击技术,评估提供给开发者的模型的可靠性,确保模型能够抵御此类攻击。
实验验证-Experimental Evaluation
这部分主要对提出的攻击方法进行实验评估,通过在多种任务上的实验,验证攻击方法对 Transformer 模型的有效性,具体内容如下:
-
实验设置:在配备 NVIDIA Tesla V100 GPU 的高性能计算集群上,基于 PyTorch 深度学习框架开展实验。为保证结果的可重复性和可比性,实验中保持超参数一致,并使用广泛认可的基准数据集。对比了包括正常 Transformer 模型、无位置嵌入的 Transformer 模型、GS-EC、MORPHEUS 以及本文提出的多种攻击方法等8种方法。
-
攻击后位置编码向量的可视化:对采用绝对位置编码的 Transformer 模型和基于 BERT-base 的可学习位置嵌入模型进行攻击可视化。结果显示,FreqHack 和 PhaseShift 攻击会破坏模型对位置编码信息的获取,即使是可学习位置嵌入模型,受到 PosTA-F 和 PosTA-P 攻击后,其位置编码向量也会发生变化,进而导致模型性能下降。
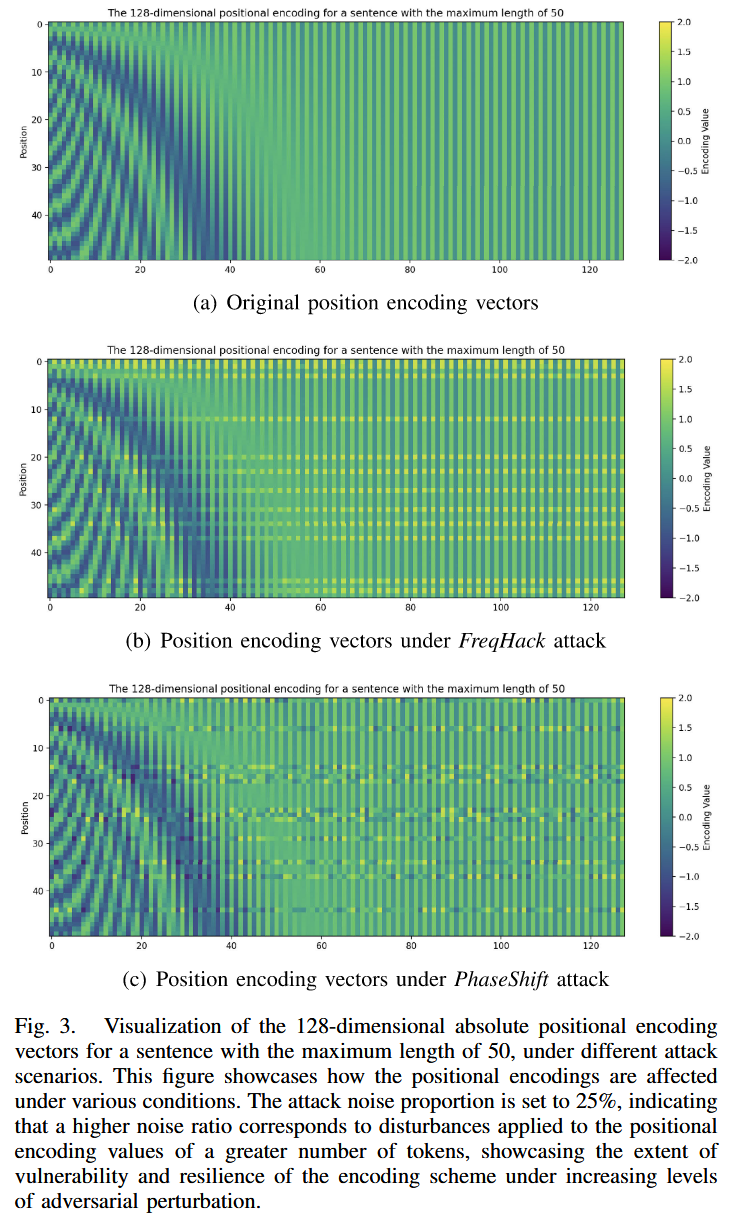
图3. 不同攻击场景下,最大长度为 50 的句子的 128 维绝对位置编码向量的可视化。此图展示了在各种条件下位置编码是如何受到影响的。攻击噪声比例设置为25%,这意味着更高的噪声比例对应于对更多标记的位置编码值施加干扰,展示了编码方案在对抗扰动水平不断增加的情况下的脆弱程度和恢复能力。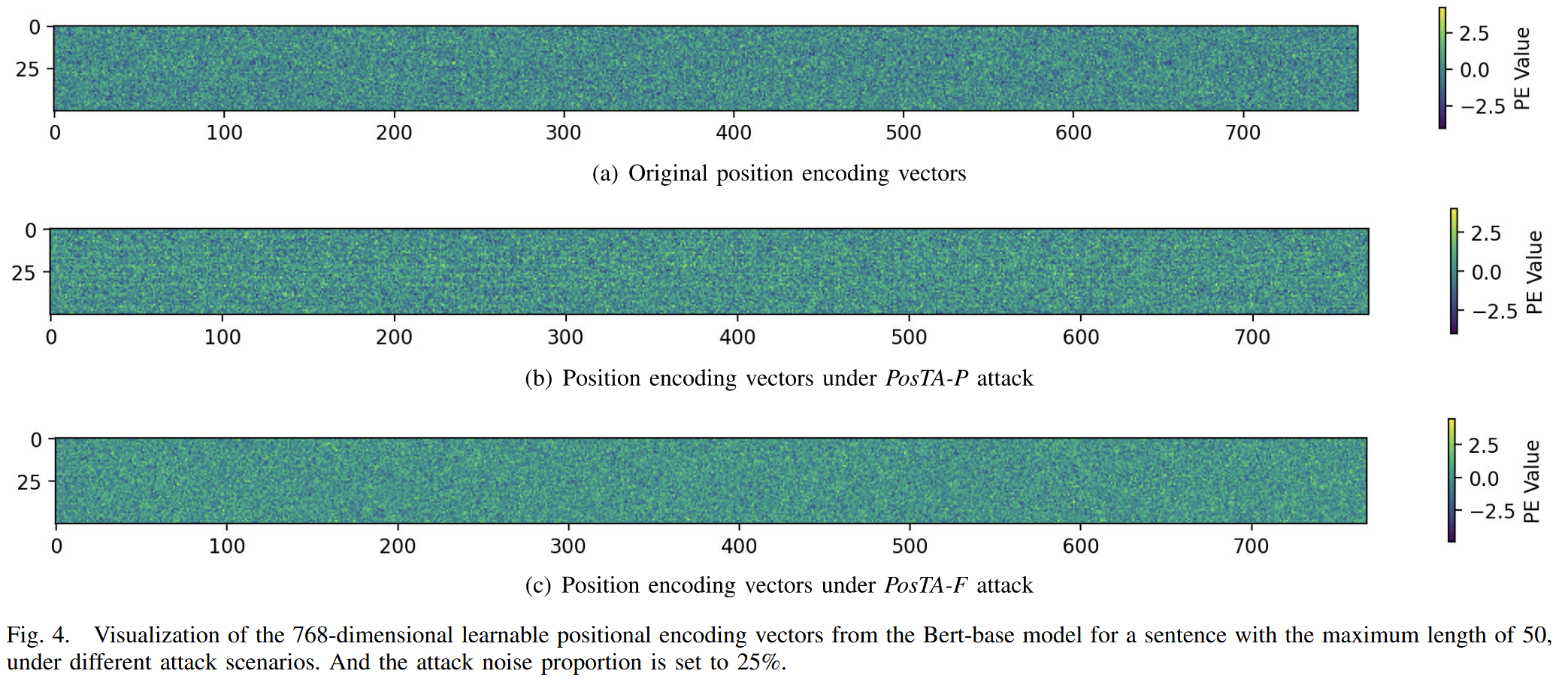
图4. 不同攻击场景下,Bert-base 模型针对最大长度为 50 的句子的 768 维可学习位置编码向量的可视化结果。攻击噪声比例设置为 25%. -
实验一:时间序列分类
- 实验设置:使用 UCR Time series classification archive 中的 Synthetic Control 数据集,包含 300 个训练样本和 300 个测试样本,共 6 个类别,时间序列长度为 60。选择 Informer 模型评估攻击方法,以分类准确率为指标,准确率越低,攻击方法越有效。
- 实验结果:随着噪声比例增加,攻击效果愈发显著。例如,在噪声比例为 25% 时,PosTA-F + LIME 就能使准确率降低 8 个百分点,证明了攻击方法的有效性,也凸显了时间序列 Transformer 模型中 PE 机制的脆弱性。
表1. 对时间序列数据集上的Informer 模型进行攻击的准确率。PE 指位置嵌入。噪声比例表示受到原子噪声注入的标记所占的比例。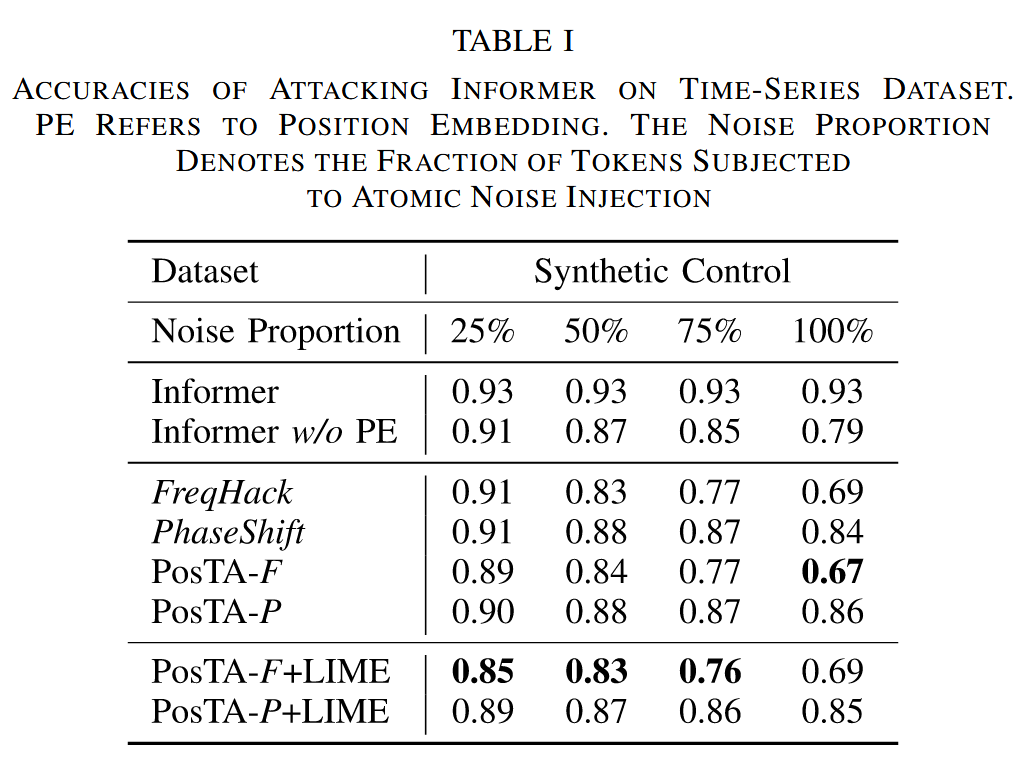
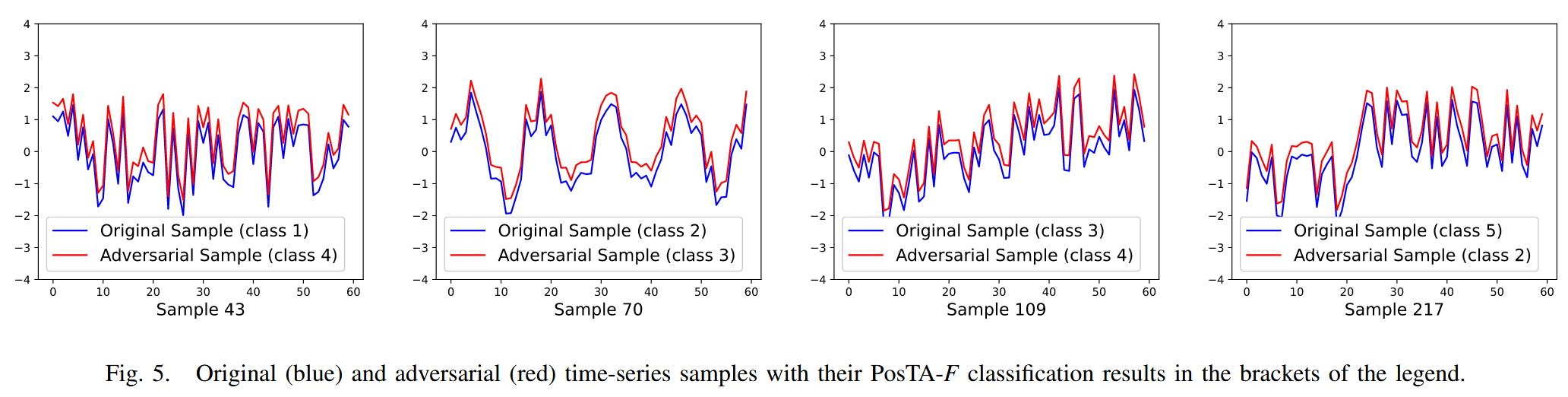
图5. 原始(蓝色)和对抗(红色)时间序列样本,其 PosTA-F 分类结果标注在图例括号内。
-
实验二:机器翻译
- 实验设置:在 wmt13 和 wmt16 两个机器翻译数据集上进行实验,分别攻击从头训练的 Transformer 模型和微调后的预训练 mBart 模型。使用 BLEU 分数和人类无感知攻击准确率作为评估指标,分数越低或准确率越高,攻击方法越有效。
- 实验结果:攻击 Transformer 模型的位置嵌入是有效的;本文提出的基于位置嵌入的攻击方法在高噪声比例下比基线方法效果更好;频率攻击方法 FreqHack 和 PosTA-F + LIME 在多数任务中表现更优;虽然本文攻击方法的噪声比例设置较低,但仍比基线方法效果好,体现了其鲁棒性;PhaseShift 在 wmt16 数据集上获得了最高的人类无感知攻击准确率和较好的攻击效果,但稳定性不如 FreqHack 和 PosTA-F,而 PosTA 系列方法性能更稳定。
**表二 针对在预计算位置嵌入的模型(在WMT13小型数据集和WMT16小型数据集上)进行攻击后的Transformer模型的BLEU分数。PPE指的是预计算的位置嵌入 **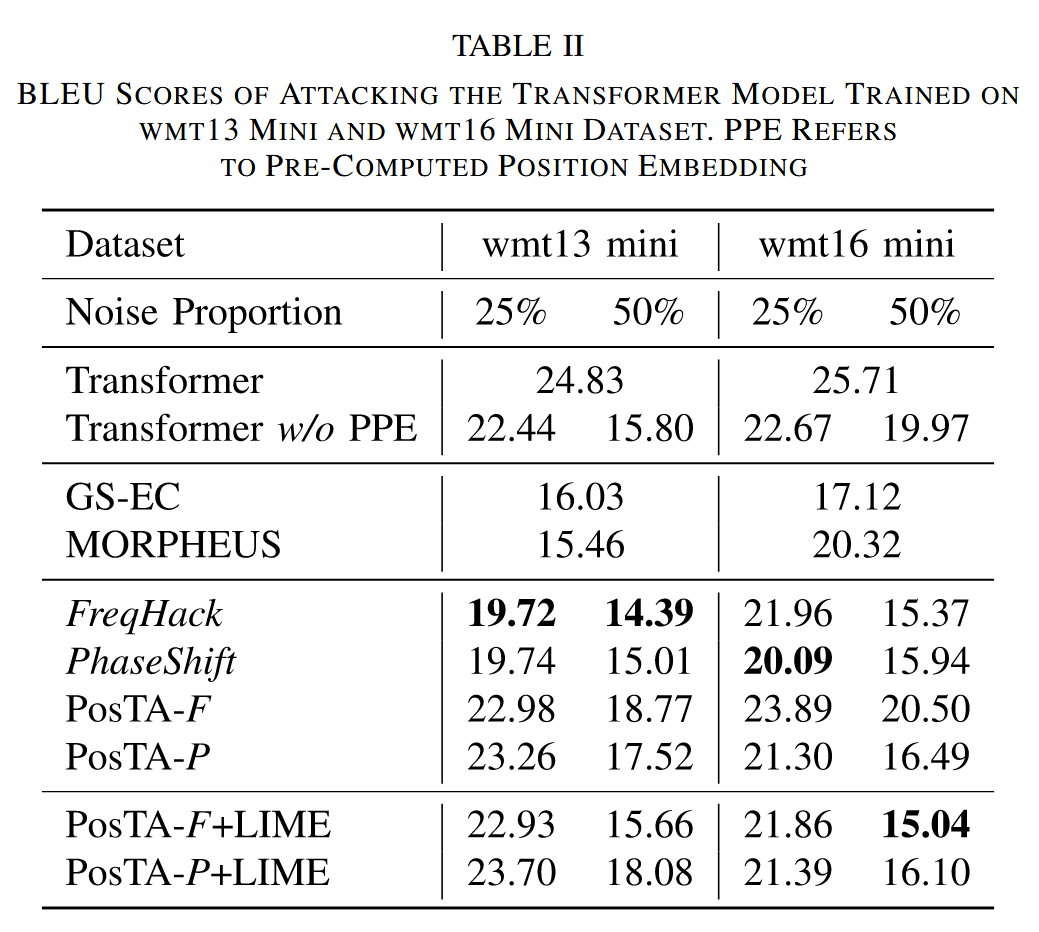
表3. 在 WMT16 数据集上对预训练的 mBart 模型进行攻击后的 BLEU 分数。LPE 指可学习的位置嵌入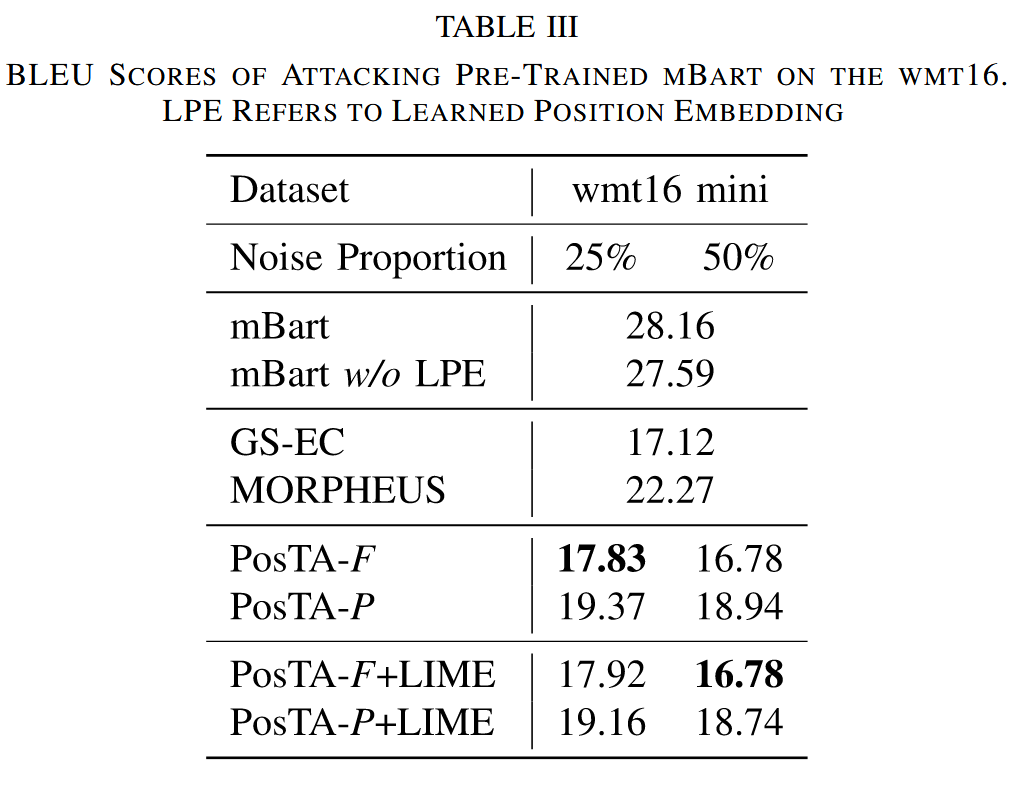
表4. 由我们的方法生成的对抗性示例以及在 WMT16 数据集上受攻击模型的输出
表5. 人类无察觉攻击准确率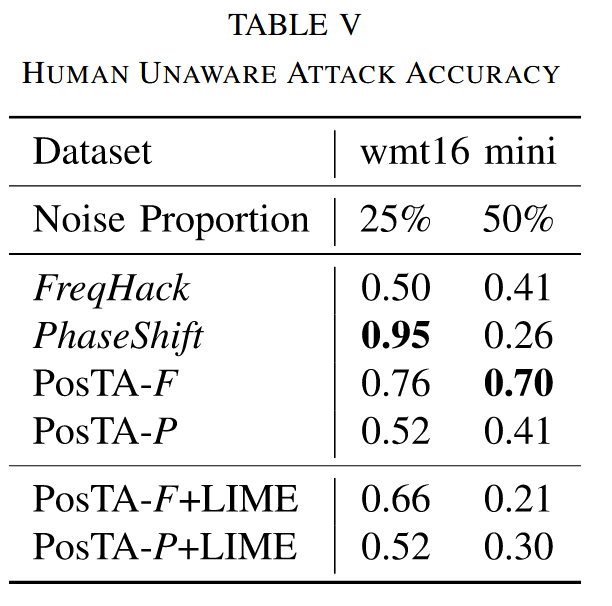
-
实验三:文本分类
- 实验设置:使用 GLUE 基准进行文本分类任务,对预训练的 BERT 模型在多个数据集上进行微调后开展攻击实验,不同数据集采用不同的评估指标,如分类准确率、马修斯相关系数、斯皮尔曼相关系数等。
- 实验结果:攻击位置嵌入可有效欺骗预训练的 BERT 模型;本文提出的四种攻击方法与无位置嵌入的 BERT 模型相比,能取得相当的攻击效果;频率攻击方法和相位攻击方法表现较为一致;在部分数据集(如CoLA)上,本文方法攻击效果最佳,因为 CoLA 任务是判断句子语法正确性,攻击位置嵌入对该任务影响较大。
表6. 在 GLUE 数据集上对预训练模型 BERT 应用攻击方法的结果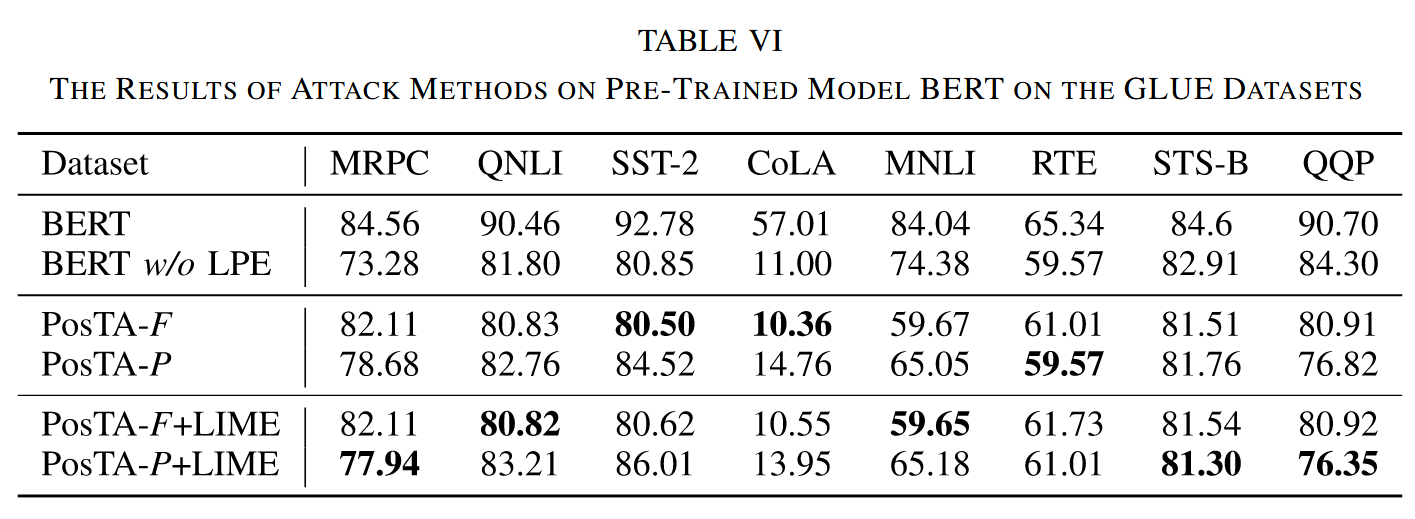
表7. 由我们的方法生成的对抗样本,以及在 SST-2 数据集上受攻击的 BERT 模型计算出的分类概率。红色条形代表正类概率,蓝色条形代表负类概率。
-
实验四:图像分类
- 实验设置:在 Food-101、CIFAR100 和 ImageNet 数据集上,选择 ViT、DEIT 和 BEIT 三种视觉 Transformer 模型进行实验。使用 PEs 引导的对抗攻击定位图像中最薄弱的 patch,选择 LaVAN 和 PGD 生成扰动,以分类准确率为评估指标。
- 实验结果:PEs 能有效定位最薄弱 patch,对这些 patch 添加扰动可大幅降低模型准确率,如在 CIFAR100 数据集上,ViT 模型准确率从 91.48% 降至 24.32%;PEs 引导选择的 patch 攻击效果优于随机选择;该攻击在不同数据集和不同大小模型间具有转移性,且 LaVAN 扰动生成器的转移性更强。
表8. 使用 LaVAN 方法在 ImageNet 数据集上攻击不同模型的准确率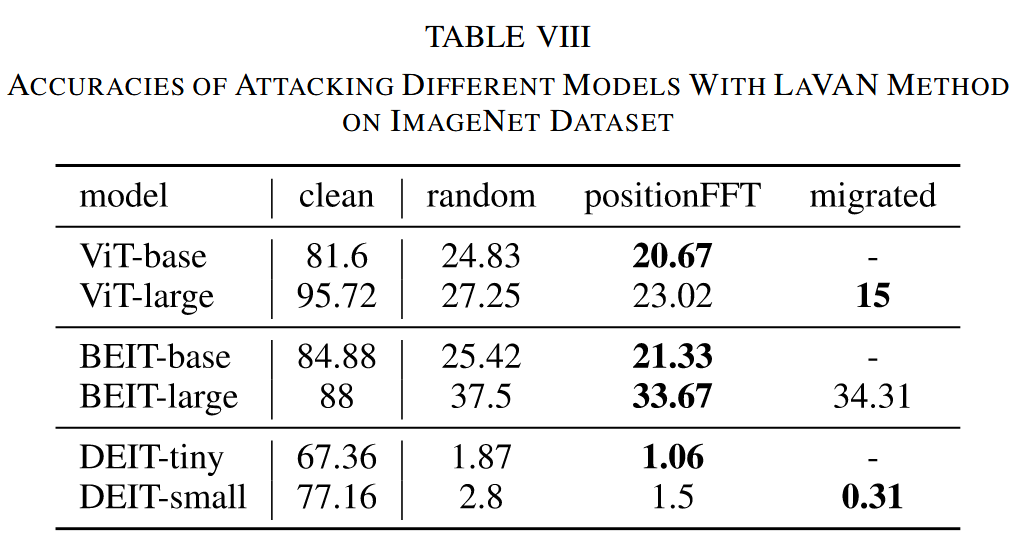
表9. 使用投影梯度下降(PGD)方法在 ImageNet 数据集上攻击不同模型的准确率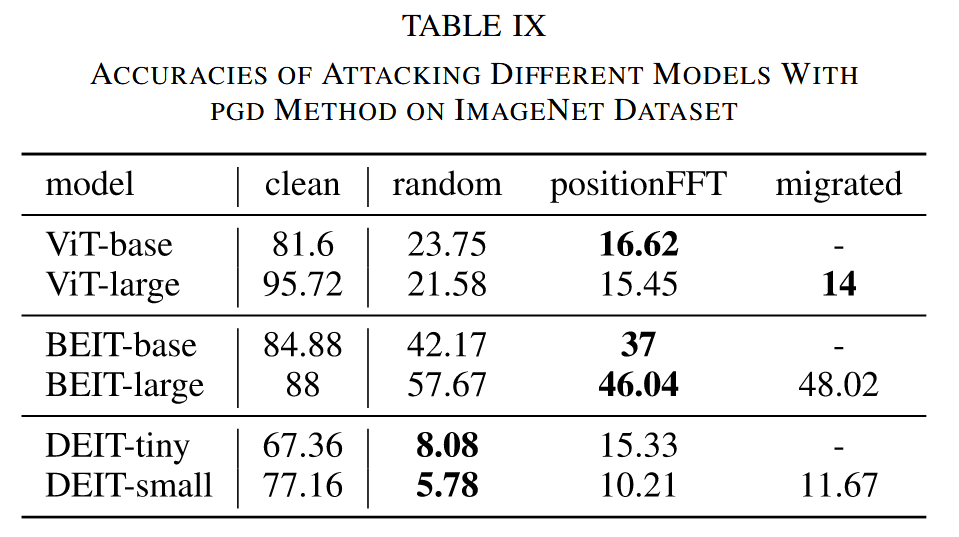
表10. 使用 LaVAN 方法在不同数据集上攻击 ViT-Base 模型的准确率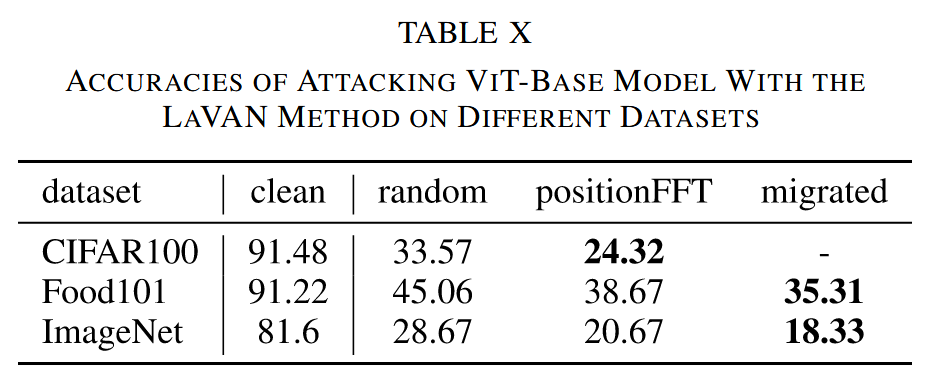
分析-Analysis
这部分主要从攻击有效性、计算开销、潜在缓解策略三个方面,对基于位置嵌入(PEs)的攻击进行深入分析,旨在全面评估攻击效果、成本及应对方法,具体内容如下:
- PE-Attack有效性分析
- 不同任务的攻击效果差异:在时间序列分类任务中,数据点间的序列和时间关系依赖程度高,FreqHack 和 PosTA-F 攻击效果显著,随着噪声比例增加,模型准确率明显下降,而 PhaseShift 和 PosTA-P 效果相对较弱;在机器翻译任务里,PosTA-F 和 PosTA-P在高噪声水平下攻击性能出色,FreqHack 和 PhaseShift 效果欠佳,这是因为机器翻译模型处理位置信息复杂,简单频率或相位干扰难以产生有效影响;文本分类任务中,针对 BERT 模型,攻击位置嵌入能有效降低准确率,尤其是 PosTA-F 和 PosTA-P 结合 LIME 方法时,但 BERT 的双向注意力机制在一定程度上缓解了位置嵌入攻击的负面影响;图像分类任务中,虽然PEs重要性相对低于 NLP 任务,但基于 Transformer 的模型对位置攻击敏感,如 ViT 和 BEIT 模型准确率显著下降,且位置信息干扰效果在不同模型间可迁移。
- 攻击效果差异的原因及假设:综合上述实验结果,研究人员提出两点假设:一是序列到序列模型对位置干扰更敏感,错误位置信息对其性能影响大于位置信息缺失;二是攻击前检测敏感位置能提升攻击效果,PosTA 类攻击在时间序列和机器翻译任务中的稳定性和有效性可证明这点。
- PE-Attacks 计算开销分析
- 不同攻击方法的计算复杂度:FreqHack 通过生成正弦噪声并添加到输入中,计算复杂度为 O ( T x ⋅ d m o d e l ) O(T_{x} \cdot d_{model }) O(Tx⋅dmodel);PhaseShift 添加相移正弦噪声,计算复杂度也是 O ( T x ⋅ d m o d e l ) O(T_{x} \cdot d_{model }) O(Tx⋅dmodel);PosTA 需训练高斯混合模型(GMM),每次 EM 迭代的计算复杂度为 O ( U ⋅ N ⋅ d m o d e l ) O(U \cdot N \cdot d_{model }) O(U⋅N⋅dmodel),多次迭代后总复杂度为 O ( I ⋅ U ⋅ N ⋅ d m o d e l ) O(I \cdot U \cdot N \cdot d_{model }) O(I⋅U⋅N⋅dmodel);PE 引导的对抗攻击,使用 FFT 投影时计算复杂度为 O ( T x ⋅ d m o d e l ) + O ( T x l o g T x ) + O ( T x l o g K ) + O ( K ⋅ G ) O(T_{x} \cdot d_{model })+O(T_{x} log T_{x})+O(T_{x} log K)+O(K \cdot G) O(Tx⋅dmodel)+O(TxlogTx)+O(TxlogK)+O(K⋅G),使用 PCA 投影时复杂度更高。
- 计算开销对攻击方法适用性的影响:FreqHack 和 PhaseShift 攻击简单高效,适用于大规模数据和复杂模型;PosTA 由于 GMM 和 EM 算法的复杂性,计算复杂度最高;PE 引导的对抗攻击在使用 FFT 时,对视觉 Transformer 模型具有较好的扩展性。
- 潜在缓解策略
- 训练过程增强:在训练过程中融入噪声增强技术,如对视觉任务进行随机裁剪、旋转等,对 NLP 任务进行随机插入或删除操作,使模型对 FreqHack、PhaseShift 和 PosTA 攻击产生抗性,但可能增加训练时间并降低模型整体性能。
- 重新设计 PEs:采用固定 PEs 替代可学习 PEs 可抵御 PosTA 攻击,使用更复杂的模式替换正弦模式能防范 FreqHack 和 PhaseShift 攻击,引入相对位置编码(RPE)或动态位置编码(DPE)专注元素相对位置,提升模型鲁棒性。
- 对抗训练:将 PE-attack 等针对PEs的对抗样本纳入训练数据,使模型学习识别和抵抗攻击,增强鲁棒性,但该方法计算资源需求大,训练时间长,且无法完全防御未知攻击。
- 优化输入预处理:实施位置扰动检测方法,在模型受影响前识别和纠正异常PEs;训练时对 PEs 添加 L2 正则化项,确保编码稳定,降低对小扰动的敏感性。
- 异常检测:利用异常检测方法识别和过滤对抗样本,如训练单独的分类器或使用去噪自动编码器,但检测效果依赖训练数据质量和多样性,无法检测所有类型的对抗样本。
结论-Conclusion
这部分是对整篇论文的总结,强调了研究成果、研究意义以及对未来研究的启示,具体内容如下:
- 研究成果总结:本文对 Transformer 模型中位置嵌入(PEs)的漏洞进行了全面分析,提出了可普遍应用的攻击技术来利用这些漏洞,并介绍了新型对抗攻击方法 PE-attack。通过在时间序列分析、自然语言处理和计算机视觉等多个领域进行大量实验,验证了这些攻击在不同任务间具有转移性。
- 研究意义阐述:研究成果揭示了 PEs 的脆弱性,强调了 Transformer 模型在实际应用中的安全风险,这对研究人员和从业者在设计和实现基于 Transformer 的模型时具有重要警示作用,促使他们重视模型结构中的潜在安全问题。
- 对未来研究的启示:本文的研究为对抗攻击的理解提供了新视角,凸显了改进防御措施的必要性,以保障 Transformer 模型在实际场景中的可靠性和鲁棒性。未来研究应致力于开发更复杂的技术,进一步增强基于 Transformer 模型的安全性和稳定性,应对不断变化的安全挑战。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 55
55 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)