论文阅读——SmoothQuant: 大型语言模型的精确高效后训练量化
SmoothQuant:大型语言模型的高效后训练量化方法 本研究提出SmoothQuant方法,解决大型语言模型(LLMs)量化中的激活值异常值问题。通过分析发现,LLMs激活值中存在系统性异常值,导致传统量化方法失效。SmoothQuant创新性地将量化难度从激活值迁移到权重,利用通道级平滑因子调整两者的比例关系。数学上通过$Y = (X\text{diag}(s)^{-1}) \cdot (\
SmoothQuant: 大型语言模型的精确高效后训练量化
Xiao G, Lin J, Seznec M, et al. Smoothquant: Accurate and efficient post-training quantization for large language models[C]//International conference on machine learning. PMLR, 2023: 38087-38099.
1. 引言与动机
大型语言模型(LLMs)在各种任务上展现出卓越的性能,但服务这些模型需要巨大的预算和能源消耗。GPT-3模型包含1750亿参数,在FP16精度下至少需要350GB内存来存储和运行,需要8块48GB的A6000 GPU或5块80GB的A100 GPU仅用于推理。由于巨大的计算和通信开销,推理延迟对实际应用来说可能无法接受。
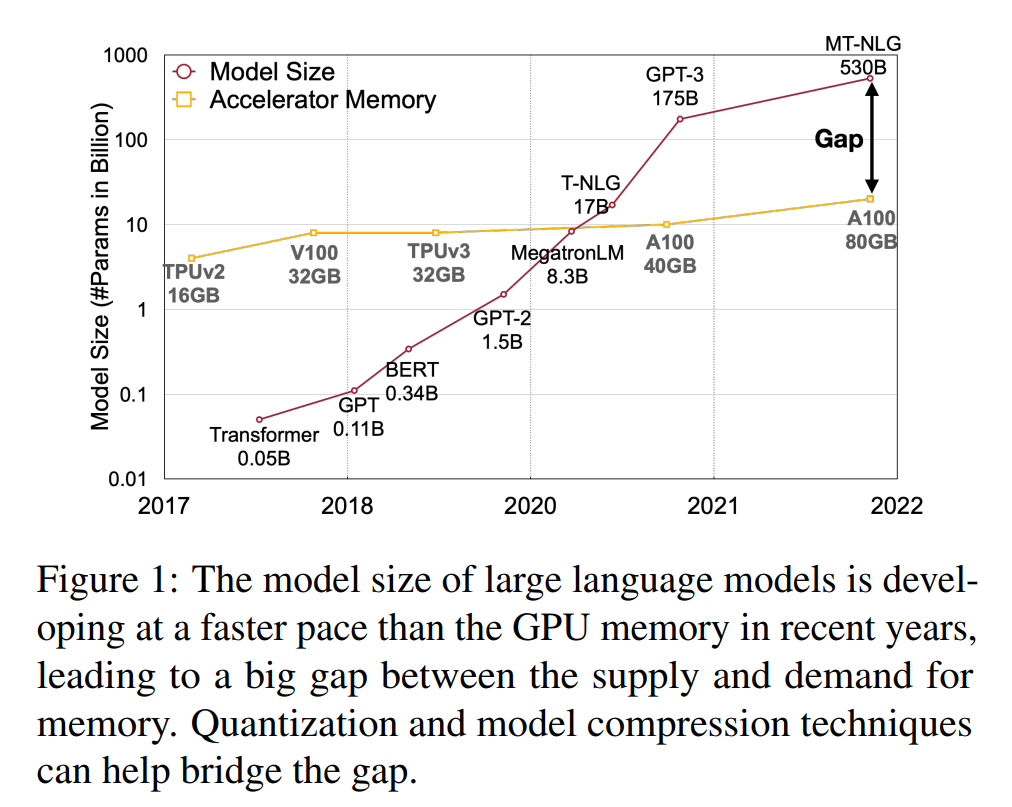
图1描述:该图展示了近年来大型语言模型规模与GPU内存的发展对比。横轴为年份(2017-2022),左纵轴显示模型大小(参数量,对数刻度),右纵轴显示加速器内存。图中显示了各个模型的发展轨迹,包括GPT-3(175B)、MT-NLG(530B)等,以及A100(80GB)等GPU的内存容量。可以明显看出模型规模的增长速度远超GPU内存的增长,形成了日益扩大的供需缺口。
量化是减少LLMs成本的有效方法。通过将权重和激活值量化为低位整数,我们可以减少GPU内存需求(包括大小和带宽),并加速计算密集型操作(如线性层中的GEMM和注意力机制中的BMM)。例如,权重和激活值的INT8量化相比FP16可以将GPU内存使用减半,矩阵乘法的吞吐量几乎翻倍。然而,与CNN模型或BERT等较小的transformer模型不同,LLMs的激活值极难量化。当我们将LLMs扩展到超过67亿参数时,激活值中会出现具有大幅度的系统性异常值,导致大的量化误差和精度下降。
2. 预备知识与量化理论
2.1 量化的数学定义
量化将高精度值映射到离散级别。我们研究整数均匀量化(特别是INT8)以获得更好的硬件支持和效率。量化过程可以表示为:
XˉINT8=⌈XFP16Δ⌋,Δ=max(∣X∣)2N−1−1\bar{X}^{\text{INT8}} = \left\lceil \frac{X^{\text{FP16}}}{\Delta} \right\rfloor, \quad \Delta = \frac{\max(|X|)}{2^{N-1} - 1}XˉINT8=⌈ΔXFP16⌋,Δ=2N−1−1max(∣X∣)
其中XXX是浮点张量,Xˉ\bar{X}Xˉ是量化后的对应值,Δ\DeltaΔ是量化步长,⌈⋅⌋\lceil \cdot \rfloor⌈⋅⌋是舍入函数,NNN是位数(本文为8)。这里为简化起见假设张量关于0对称;对于非对称情况(如ReLU后),讨论类似,只需添加零点。
这种量化器使用最大绝对值来计算Δ\DeltaΔ,以保留激活值中的异常值,这些异常值被发现对精度很重要。我们可以使用一些校准样本的激活值离线计算Δ\DeltaΔ,称为静态量化。我们也可以使用激活值的运行时统计来获得Δ\DeltaΔ,称为动态量化。
2.2 量化粒度级别
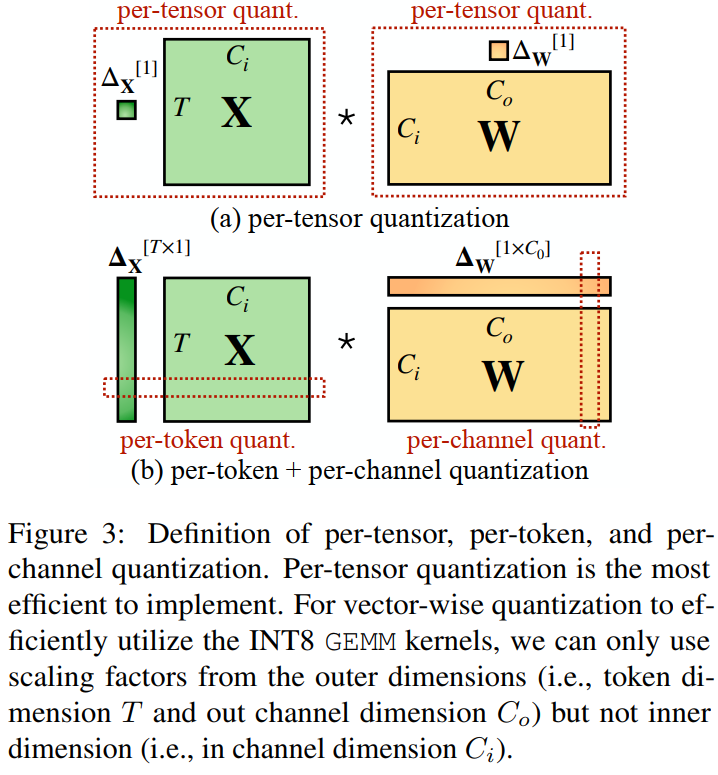
图3描述:该图展示了per-tensor、per-token和per-channel量化的定义。图中显示了输入激活矩阵XXX(维度T×CiT \times C_iT×Ci)和权重矩阵WWW(维度Ci×CoC_i \times C_oCi×Co)的乘法操作。(a) per-tensor量化:整个张量使用单一量化步长ΔX[1]\Delta_X^{[1]}ΔX[1]和ΔW[1]\Delta_W^{[1]}ΔW[1]。(b) per-token + per-channel量化:激活值使用per-token量化(ΔX[T×1]\Delta_X^{[T \times 1]}ΔX[T×1]),权重使用per-channel量化(ΔW[1×Co]\Delta_W^{[1 \times C_o]}ΔW[1×Co])。
对于Transformer中的线性层:
Y=X⋅W,Y∈RT×Co,X∈RT×Ci,W∈RCi×CoY = X \cdot W, \quad Y \in \mathbb{R}^{T \times C_o}, X \in \mathbb{R}^{T \times C_i}, W \in \mathbb{R}^{C_i \times C_o}Y=X⋅W,Y∈RT×Co,X∈RT×Ci,W∈RCi×Co
其中TTT是token数量,CiC_iCi是输入通道,CoC_oCo是输出通道(为简化省略了批次维度)。
3. 量化难度的深入分析
3.1 激活值异常值的特征
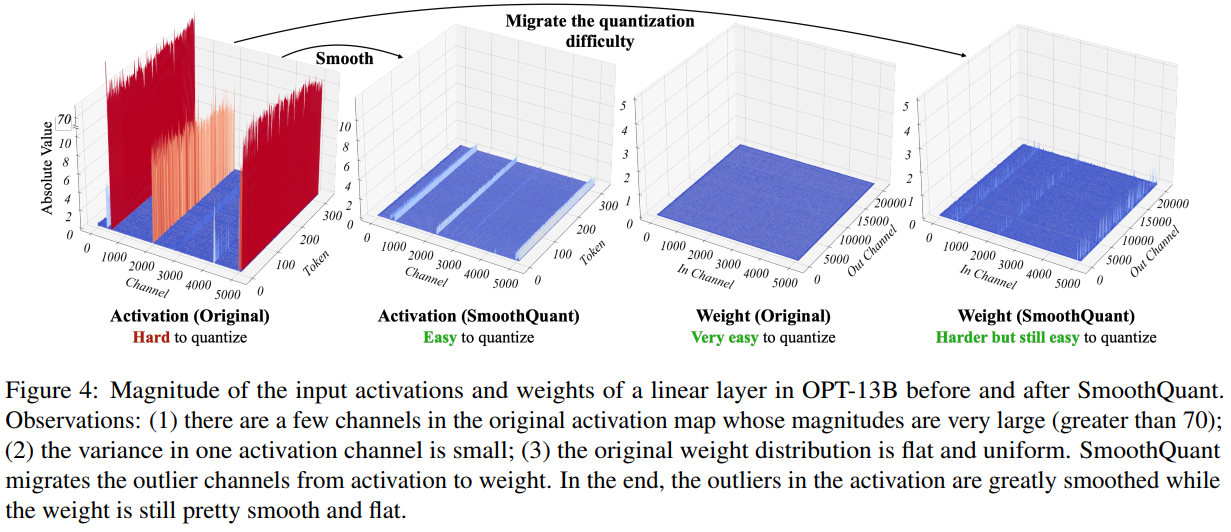
图4描述:该图展示了OPT-13B模型中某个线性层的输入激活值和权重在SmoothQuant前后的幅度分布。图分为四个部分:
- 左上:原始激活值,显示某些通道存在极大的异常值(>70),难以量化
- 右上:SmoothQuant后的激活值,异常值被平滑,易于量化
- 左下:原始权重,分布平坦均匀,非常容易量化
- 右下:SmoothQuant后的权重,虽然仍然易于量化,但比原始权重稍难
通过可视化分析,我们发现了几个关键模式:
-
激活值比权重更难量化:权重分布相当均匀和平坦,易于量化。之前的工作已经表明,使用INT8甚至INT4量化LLMs的权重不会降低精度,这与我们的观察一致。
-
异常值使激活量化困难:激活值中异常值的规模比大多数激活值大约100倍。在per-tensor量化的情况下,大的异常值主导了最大幅度测量,导致非异常通道的有效量化位数/级别很低。
-
异常值持续出现在固定通道中:异常值出现在一小部分通道中。如果某个通道有异常值,它会持续出现在所有token中。给定token的各通道间方差很大,但给定通道在不同token间的幅度方差很小。
3.2 有效量化位数分析
假设通道iii的最大幅度为mim_imi,整个矩阵的最大值为mmm,则通道iii的有效量化级别为:
Leff(i)=28⋅mimL_{\text{eff}}^{(i)} = 2^8 \cdot \frac{m_i}{m}Leff(i)=28⋅mmi
对于非异常通道,有效量化级别会非常小(2-3个级别),导致大的量化误差。
4. SmoothQuant方法详解
4.1 核心思想与数学原理
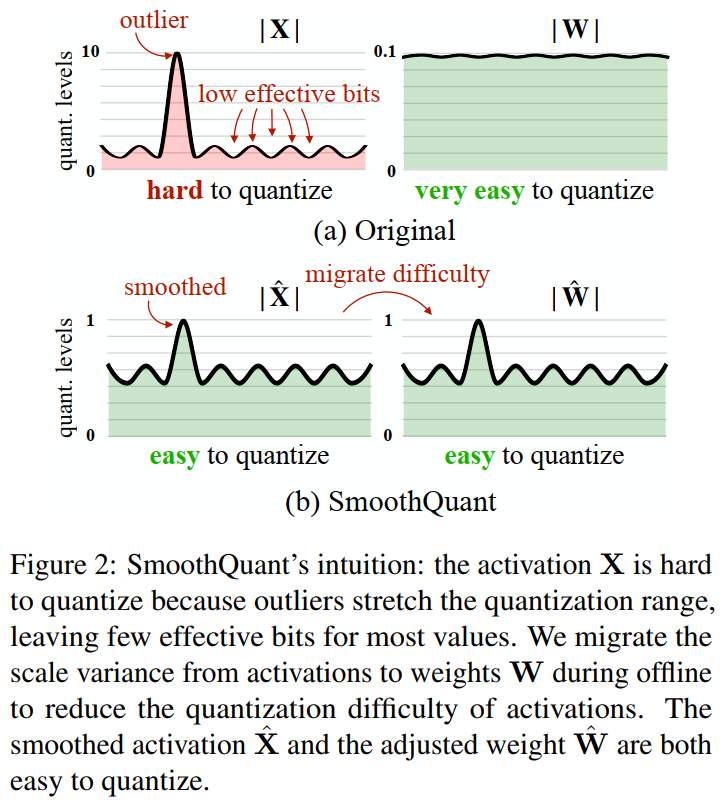
图2描述:该图说明了SmoothQuant的直觉。左侧显示原始情况:激活值XXX由于异常值拉伸了量化范围而难以量化,导致大多数值的有效位数很少;权重WWW非常容易量化。右侧显示SmoothQuant后:通过离线迁移尺度方差,平滑后的激活值X^\hat{X}X^和调整后的权重W^\hat{W}W^都变得易于量化。
SmoothQuant的关键观察是:即使由于异常值的存在,激活值比权重更难量化,但不同token在其通道上表现出相似的变化。基于这一观察,SmoothQuant离线地将量化难度从激活值迁移到权重。
我们通过除以per-channel平滑因子s∈RCis \in \mathbb{R}^{C_i}s∈RCi来"平滑"输入激活值。为保持线性层的数学等价性,我们相应地在相反方向缩放权重:
Y=(Xdiag(s)−1)⋅(diag(s)W)=X^W^Y = (X\text{diag}(s)^{-1}) \cdot (\text{diag}(s)W) = \hat{X}\hat{W}Y=(Xdiag(s)−1)⋅(diag(s)W)=X^W^
4.2 平滑因子的选择策略

图5描述:该图展示了α=0.5\alpha = 0.5α=0.5时SmoothQuant的主要思想。平滑因子sss在校准样本上获得,整个变换离线执行。在运行时,激活值已经平滑,无需缩放。图中显示了从原始激活值和权重到平滑后版本的转换过程,以及相应的量化难度迁移。
我们的目标是选择per-channel平滑因子sss使得X^=Xdiag(s)−1\hat{X} = X\text{diag}(s)^{-1}X^=Xdiag(s)−1易于量化。为了减少量化误差,应该增加所有通道的有效量化位数。当所有通道具有相同的最大幅度时,总的有效量化位数最大。
引入超参数迁移强度α\alphaα来控制从激活值迁移到权重的难度程度:
sj=(max(∣Xj∣))α(max(∣Wj∣))1−αs_j = \frac{(\max(|X_j|))^{\alpha}}{(\max(|W_j|))^{1-\alpha}}sj=(max(∣Wj∣))1−α(max(∣Xj∣))α
该公式确保权重和激活值在对应通道上共享相似的最大值,从而共享相同的量化难度。
4.3 应用于Transformer块
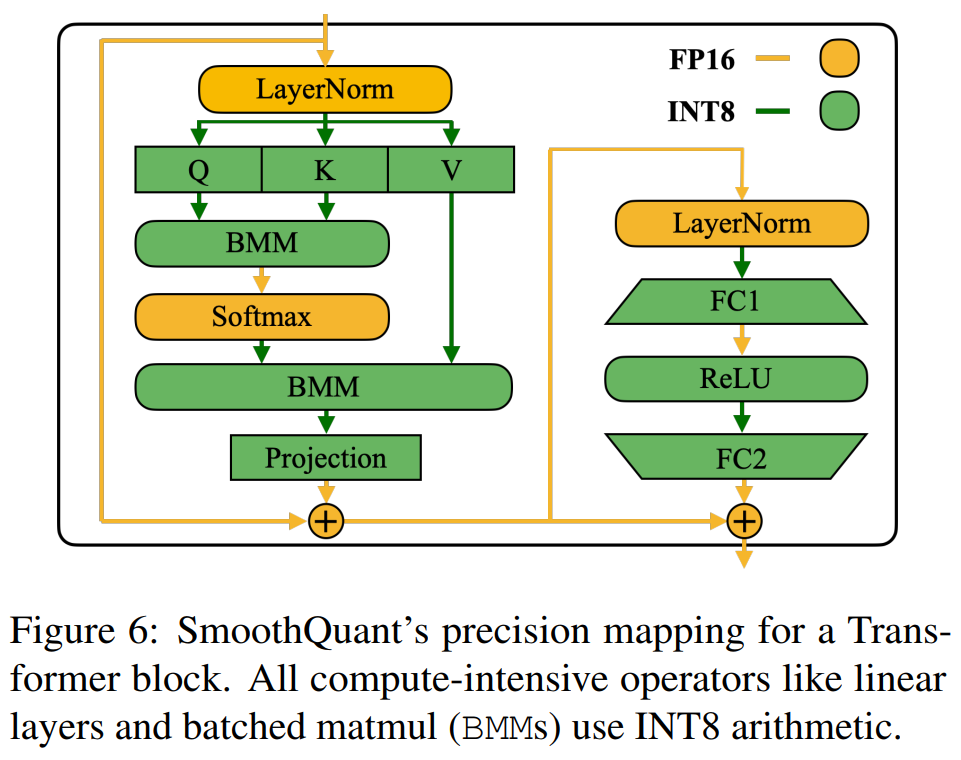
图6描述:该图展示了SmoothQuant对Transformer块的精度映射。所有计算密集型操作如线性层和批量矩阵乘法(BMMs)都使用INT8算术。图中显示了LayerNorm、线性投影、BMM、Softmax、ReLU等操作的精度配置,其中主要的计算密集型操作使用INT8,而轻量级的逐元素操作保持FP16。
线性层占据了LLM模型的大部分参数和计算。默认情况下,我们对自注意力和前馈层的输入激活值执行尺度平滑,并使用W8A8量化所有线性层。我们还量化注意力计算中的BMM操作。
5. 实验结果与分析
5.1 不同规模模型的精度保持
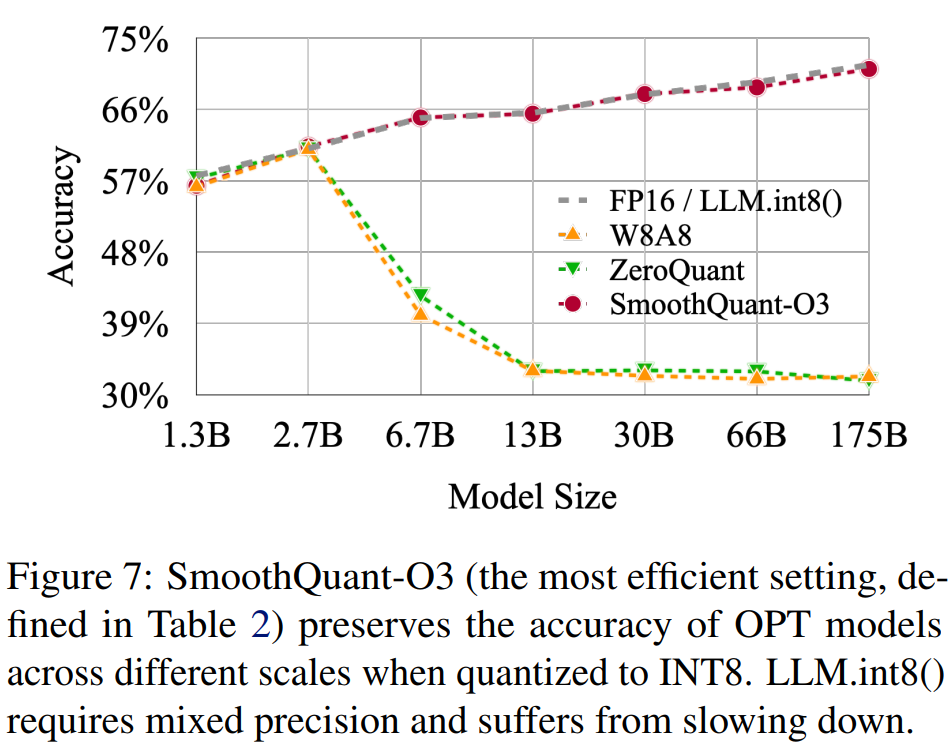
图7描述:该图展示了SmoothQuant-O3(表2中定义的最高效设置)在不同规模OPT模型上量化为INT8时保持精度的能力。横轴为模型大小(1.3B到175B),纵轴为精度。图中比较了FP16/LLM.int8()、W8A8、ZeroQuant和SmoothQuant-O3的性能。可以看到SmoothQuant在所有规模上都保持了与FP16相当的精度,而其他基线方法在大模型上失败。
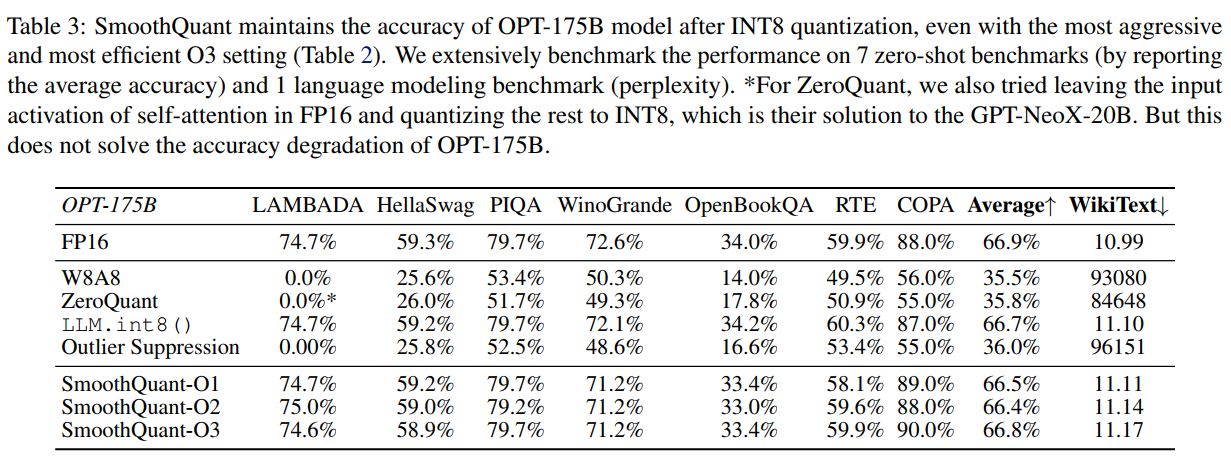
表3展示了OPT-175B模型在INT8量化后的详细结果。SmoothQuant即使使用最激进的O3设置,也能在所有7个零样本基准测试和1个语言建模基准上保持精度。
5.2 速度提升和内存节省
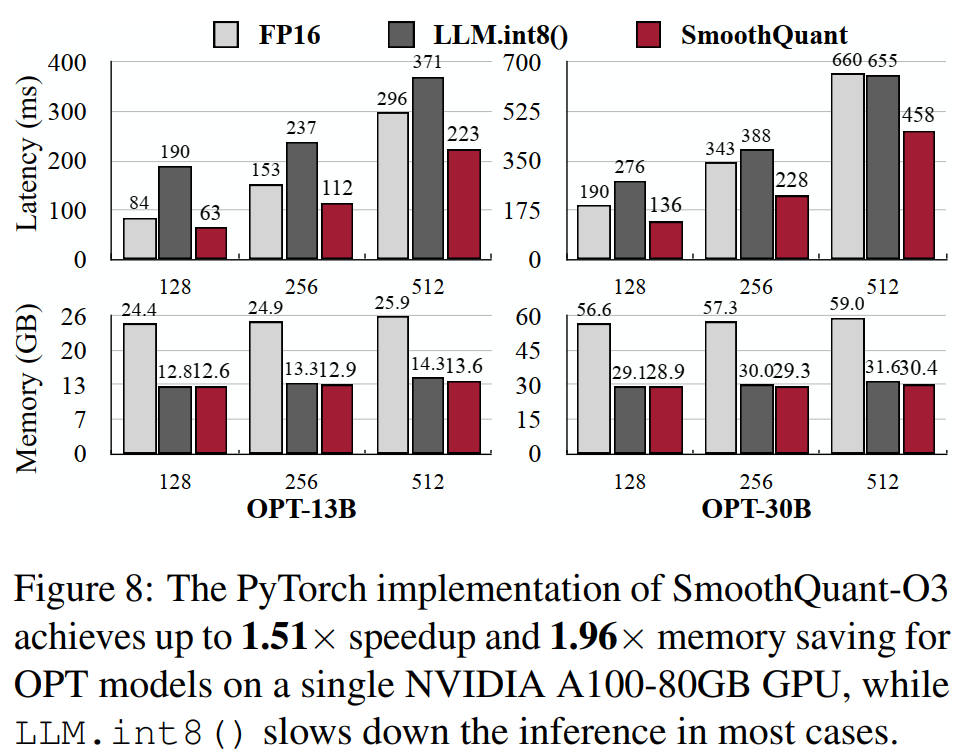
图8描述:该图展示了PyTorch实现的SmoothQuant-O3在单个NVIDIA A100-80GB GPU上对OPT模型的性能。图分为两行:上行显示延迟(毫秒),下行显示内存(GB)。每个子图比较了不同序列长度(128、256、512、1024)下FP16、LLM.int8()和SmoothQuant的性能。SmoothQuant实现了高达1.51倍的加速和1.96倍的内存节省。
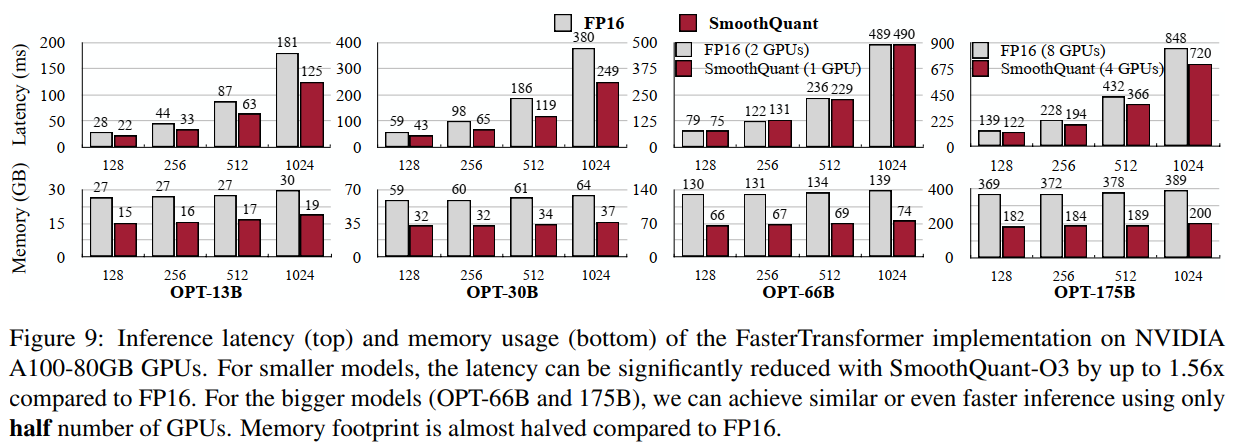
图9描述:该图展示了FasterTransformer实现在NVIDIA A100-80GB GPU上的推理延迟(上)和内存使用(下)。对于较小的模型,SmoothQuant-O3相比FP16可以显著减少延迟,最高达1.56倍。对于更大的模型(OPT-66B和175B),使用一半数量的GPU可以实现相似甚至更快的推理。内存占用几乎减半。
5.3 消融研究
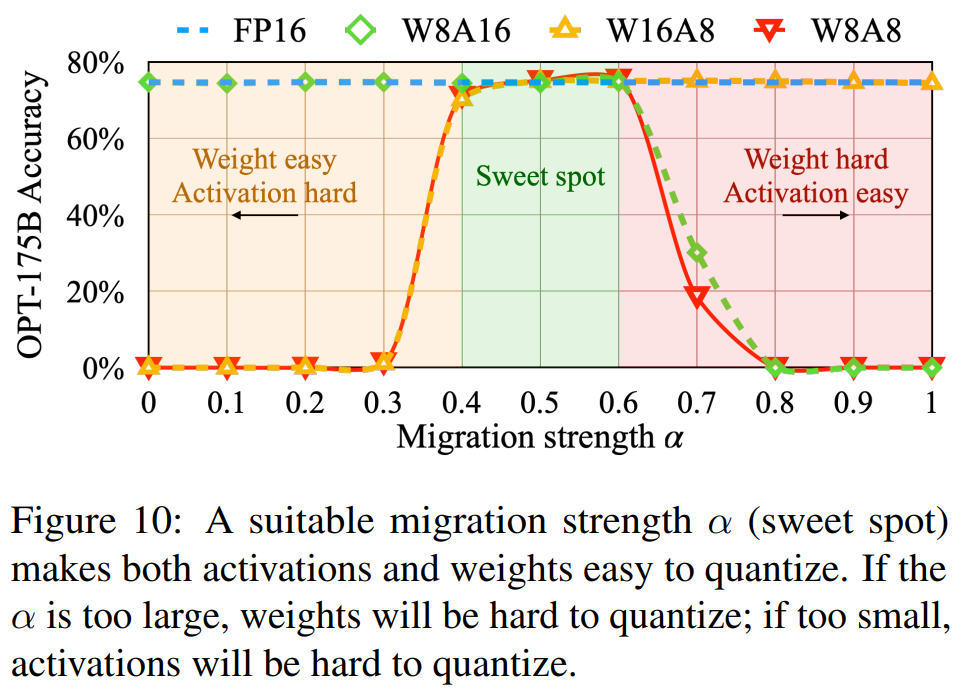
图10描述:该图展示了迁移强度α\alphaα对OPT-175B在LAMBADA数据集上精度的影响。横轴为α\alphaα值(0到1),纵轴分别显示了延迟和内存。图中标注了不同α\alphaα值下的权重和激活值量化难度。当α=0.5\alpha = 0.5α=0.5时达到最佳平衡点,权重和激活值都易于量化。
6. 扩展到超大规模模型
我们将SmoothQuant扩展到MT-NLG 530B模型,首次实现了在单个节点内服务超过5000亿参数的模型。表9显示SmoothQuant能够以可忽略的精度损失(平均精度从73.1%保持在73.1%)对530B模型进行W8A8量化。
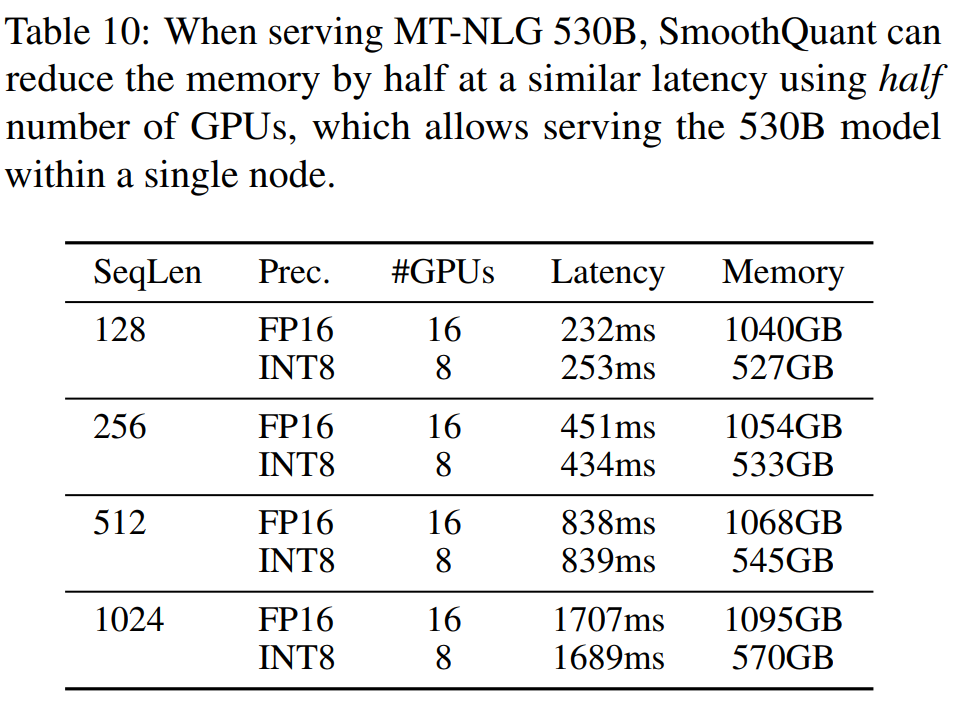
表10展示了服务MT-NLG 530B时的性能对比。SmoothQuant使用一半数量的GPU(8个而不是16个)在相似的延迟下将内存减少一半,实现了在单个8-GPU节点内服务530B模型的目标。
附录:数学推导
A. 有效量化位数的理论分析
考虑一个激活张量X∈RT×CiX \in \mathbb{R}^{T \times C_i}X∈RT×Ci,其中每个通道jjj的值范围为[−mj,mj][-m_j, m_j][−mj,mj]。在per-tensor量化下,量化步长为:
Δ=maxj(mj)2N−1−1\Delta = \frac{\max_j(m_j)}{2^{N-1} - 1}Δ=2N−1−1maxj(mj)
对于通道jjj,其有效量化范围为[−Δ⋅(2N−1−1),Δ⋅(2N−1−1)][-\Delta \cdot (2^{N-1} - 1), \Delta \cdot (2^{N-1} - 1)][−Δ⋅(2N−1−1),Δ⋅(2N−1−1)],但实际值范围仅为[−mj,mj][-m_j, m_j][−mj,mj]。因此,有效量化级别数为:
Leff(j)=2mjΔ=2mj(2N−1−1)maxk(mk)≈2N⋅mjmaxk(mk)L_{\text{eff}}^{(j)} = \frac{2m_j}{\Delta} = \frac{2m_j(2^{N-1} - 1)}{\max_k(m_k)} \approx 2^N \cdot \frac{m_j}{\max_k(m_k)}Leff(j)=Δ2mj=maxk(mk)2mj(2N−1−1)≈2N⋅maxk(mk)mj
当mj≪maxk(mk)m_j \ll \max_k(m_k)mj≪maxk(mk)时(非异常通道的情况),Leff(j)≪2NL_{\text{eff}}^{(j)} \ll 2^NLeff(j)≪2N,导致严重的量化误差。
B. 平滑变换的优化目标
给定激活值XXX和权重WWW,我们希望找到平滑因子sss使得量化误差最小。定义量化误差为:
E(s)=∥Q(X^)−X^∥F2+∥Q(W^)−W^∥F2E(s) = \|Q(\hat{X}) - \hat{X}\|_F^2 + \|Q(\hat{W}) - \hat{W}\|_F^2E(s)=∥Q(X^)−X^∥F2+∥Q(W^)−W^∥F2
其中Q(⋅)Q(\cdot)Q(⋅)表示量化操作,X^=Xdiag(s)−1\hat{X} = X\text{diag}(s)^{-1}X^=Xdiag(s)−1,W^=diag(s)W\hat{W} = \text{diag}(s)WW^=diag(s)W。
在per-channel量化假设下,第jjj个通道的量化误差近似正比于其值范围的平方:
Ej(sj)∝(max(∣Xj∣)sj)2+(sj⋅max(∣Wj∣))2E_j(s_j) \propto \left(\frac{\max(|X_j|)}{s_j}\right)^2 + (s_j \cdot \max(|W_j|))^2Ej(sj)∝(sjmax(∣Xj∣))2+(sj⋅max(∣Wj∣))2
对sjs_jsj求导并令其为零:
∂Ej∂sj=−2(max(∣Xj∣))2sj3+2sj(max(∣Wj∣))2=0\frac{\partial E_j}{\partial s_j} = -2\frac{(\max(|X_j|))^2}{s_j^3} + 2s_j(\max(|W_j|))^2 = 0∂sj∂Ej=−2sj3(max(∣Xj∣))2+2sj(max(∣Wj∣))2=0
解得最优平滑因子:
sj∗=(max(∣Xj∣)max(∣Wj∣))1/2s_j^* = \left(\frac{\max(|X_j|)}{\max(|W_j|)}\right)^{1/2}sj∗=(max(∣Wj∣)max(∣Xj∣))1/2
这对应于α=0.5\alpha = 0.5α=0.5的情况。引入α\alphaα参数允许我们在不同的硬件约束和模型特性下调整权重-激活量化难度的平衡。
C. 量化感知的矩阵乘法
在硬件加速的GEMM内核中,缩放只能在矩阵乘法的外部维度上执行。对于量化的矩阵乘法:
Y=diag(ΔXFP16)⋅(XˉINT8⋅WˉINT8)⋅diag(ΔWFP16)Y = \text{diag}(\Delta_X^{\text{FP16}}) \cdot (\bar{X}^{\text{INT8}} \cdot \bar{W}^{\text{INT8}}) \cdot \text{diag}(\Delta_W^{\text{FP16}})Y=diag(ΔXFP16)⋅(XˉINT8⋅WˉINT8)⋅diag(ΔWFP16)
其中ΔX∈RT\Delta_X \in \mathbb{R}^TΔX∈RT和ΔW∈RCo\Delta_W \in \mathbb{R}^{C_o}ΔW∈RCo分别是激活值和权重的量化步长。这种形式允许我们使用高效的INT8 GEMM内核执行主要计算,同时保持数值精度。
D. 静态vs动态量化的权衡
动态量化在运行时计算量化参数:
Δdynamic=max(∣Xruntime∣)2N−1−1\Delta_{\text{dynamic}} = \frac{\max(|X_{\text{runtime}}|)}{2^{N-1} - 1}Δdynamic=2N−1−1max(∣Xruntime∣)
静态量化使用校准数据预先计算:
Δstatic=EX∼Dcalib[max(∣X∣)2N−1−1]\Delta_{\text{static}} = \mathbb{E}_{X \sim \mathcal{D}_{\text{calib}}}\left[\frac{\max(|X|)}{2^{N-1} - 1}\right]Δstatic=EX∼Dcalib[2N−1−1max(∣X∣)]
静态量化的优势在于避免了运行时开销,但可能因校准数据与实际输入的分布差异而引入误差。我们的实验表明,对于大多数LLMs,使用512个校准样本的静态量化可以在保持精度的同时显著提高推理速度。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)