八、使用LoRA进行参数高效微调
LoRA(低秩自适应)是一种高效的参数微调技术,通过引入低秩矩阵A和B来调整预训练模型权重,大幅减少需训练参数数量(从1.24亿降至266万)。该方法冻结原始权重,仅更新低秩矩阵,既保留预训练知识又降低计算成本。实验将LoRA应用于GPT-2模型的垃圾邮件分类任务,展示了其在保持模型性能的同时显著提升训练效率的优势。结果表明LoRA特别适合大模型微调,通过调整rank和alpha参数可平衡模型性能
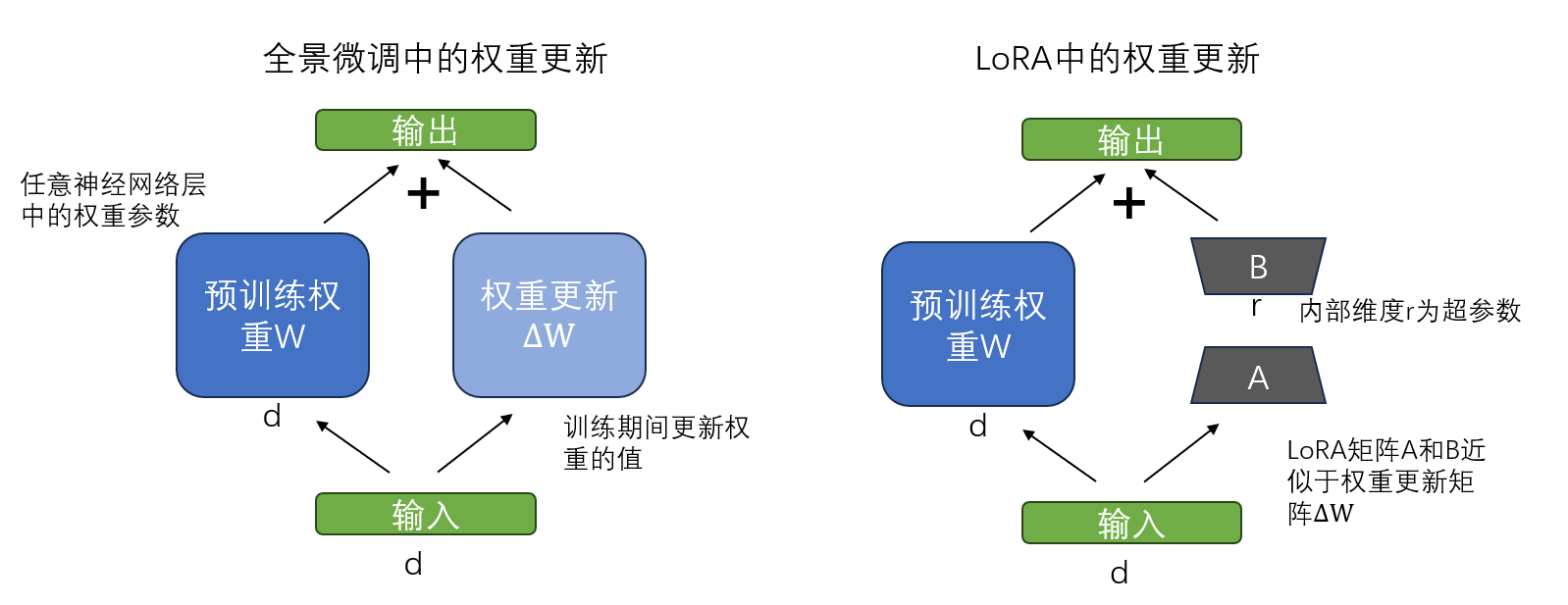
LoRA(低秩自适应)是最常用的参数高效微调技术之一。它可以应用于分类微调中,也可以应用于监督指令微调中。LoRA是一种通过仅调整模型权重参数的一小部分,使预训练模型更好地适应特定且通常较小的数据集的技术。
低秩指的是将模型调整限制在总权重参数空间的较小维度子空间,从而有效捕获训练过程中对权重参数变化影响最大的方向。LoRA之所以有用且受到广泛欢迎,是因为它能够高效地对大模型进行特定任务地微调,显著降低了通常所需地计算成本和资源。
在常规地训练和微调中。在更新权重时,会得到更新值,权重更新后
。在LoRA中,提出一种近似替代权重更新值
,即
,
。其中A,B是两个比W小得多的矩阵。
通过引入了两个低秩矩阵后,就可以把原始的预训练权重参数W冻结起来,不参与梯度更新,只训练低秩矩阵A和B。这样一来,仅需训练少量参数,避免了预训练知识被覆盖,提高了训练效率地同时,又降低了储存需求。
接下来,将LoRA应用于垃圾消息分类中。
1、准备数据集
可以直接使用第六讲地数据准备部分代码。
from pathlib import Path
import pandas as pd
import torch
from torch.utils.data import Dataset, DataLoader
import tiktoken
from classificationFine_tuning import download_and_unzip_spam_data, crate_balanced_dataset, \
random_split, SpamDataset
if __name__ == "__main__":
###准备数据
url = "https://archive.ics.uci.edu/static/public/228/sms+spam+collection.zip"
zip_path = "sms+spam+collection.zip"
extracted_path = "sms_spam_collection"
data_file_path = Path(extracted_path) / "SMSSpamCollection.tsv"
download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path)
# 加载文件并且查看类别分布
df = pd.read_csv(data_file_path, sep="\t", header=None, names=["Label", "Text"])
balanced_df = crate_balanced_dataset(df)
# 调整标签为0、1
balanced_df["Label"] = balanced_df["Label"].map({"ham": 0, "spam": 1})
# 划分数据集
train_df, val_df, test_df = random_split(balanced_df, 0.7, 0.1)
# 保存为csv文件
train_df.to_csv("train.csv", index=None)
val_df.to_csv("val.csv", index=None)
test_df.to_csv("test.csv", index=None)
###实例化数据集
tokenizer = tiktoken.get_encoding("gpt2")
train_dataset = SpamDataset("train.csv", max_length=None, tokenizer=tokenizer)
val_dataset = SpamDataset("val.csv", max_length=None, tokenizer=tokenizer)
test_dataset = SpamDataset("test.csv", max_length=None, tokenizer=tokenizer)
###创建数据加载器
num_workers = 0
batch_size = 4
torch.manual_seed(123)
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True,
drop_last=True,
num_workers=num_workers)
val_loader = DataLoader(dataset=val_dataset,
batch_size=batch_size,
shuffle=False,
drop_last=False,
num_workers=num_workers)
test_loader = DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False,
drop_last=False,
num_workers=num_workers)2、初始化模型
复用第六讲地代码来加载和准备预训练的GPT模型。下载权重后加载到模型中。
from gpt_download import download_and_load_gpt2
from gpt2 import GPTModel
from PreTrain import load_weight_into_gpt
# 设置模型配置
CHOOSE_MODEL = "gpt2-small (124M)"
INPUT_PROMPT = "Every effort moves"
BASE_CONFIG = {
"vocab_size": 50257,
"context_length": 1024,
"drop_rate": 0.0,
"qkv_bias": True
}
model_configs = {
"gpt2-small (124M)": {"emb_dim": 768, "num_layers": 12, "num_heads": 12},
"gpt2-medium (355M)": {"emb_dim": 1024, "num_layers": 24, "num_heads": 16},
"gpt2-large (774M)": {"emb_dim": 1280, "num_layers": 36, "num_heads": 20},
"gpt2-xl (1558M)": {"emb_dim": 1600, "num_layers": 48, "num_heads": 25}
}
BASE_CONFIG.update(model_configs[CHOOSE_MODEL])
model_size = CHOOSE_MODEL.split(" ")[-1].lstrip("(").rstrip(")")
settings, params = download_and_load_gpt2(model_size=model_size, models_dir="gpt2")
model = GPTModel(BASE_CONFIG)
load_weight_into_gpt(model, params)替换最后的输出层,为微调做准备
#替换输出层
num_classes = 2
model.out_head = torch.nn.Linear(in_features=768, out_features=num_classes)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)3、LoRA进行参数高效微调
使用LoRA来微调大模型时,首先初始化一个LoRA层。它创建了矩阵A和B,并设置了alpha缩放因子和内部维度rank(r)。该层可以接受输入并计算相应的输出。rank决定了LoRA引入的额外参数量,可以通过调整r的大小来平衡参数量和模型性能。而alpha作为低秩自适应输出的缩放因子,决定了适应层的输出对原始层输出的影响程度。
class LoRALayer(nn.Module):
def __init__(self, in_dim, out_dim, rank, alpha):
super().__init__()
self.A = nn.Parameter(torch.empty(in_dim, rank))
#对线性层基于 He/Kaiming 初始化
nn.init.kaiming_uniform(self.A, a=math.sqrt(5))
self.B = nn.Parameter(torch.zeros(rank, out_dim))
self.alpha = alpha
def forward(self, x):
x = self.alpha * (x @ self.A @ self.B)
return x为了整合原始线性层的权重,创建一个LinearWithLoRA层,用于替换神经网络中的现有线性层。
class LinearWithLoRA(nn.Module):
def __init__(self, linear, rank, alpha):
super().__init__()
self.linear = linear
self.lora = LoRALayer(linear.in_features, linear.out_features, rank, alpha)
def forward(self, x):
return self.linear(x) + self.lora(x)
#替换线性层函数
def replace_linear_with_lora(model, rank, alpha):
for name, module in model.named_children():
if isinstance(module, nn.Linear):
setattr(model, name, LinearWithLoRA(module, rank, alpha))
else: #递归 处理子模块
replace_linear_with_lora(module, rank, alpha)在前面给B矩阵初始化为0,这样AB矩阵乘积就是零矩阵,加上原始权重后,也不会改变原始权重。接下来就是应用replace_linear_with_lora方法将GPTModel模型中的多头注意力模块、前馈模块和输出层中所有的Linear层替换成带有LoRA层。
#Linear替换成LoRAwithLoRA层
#冻结原始模型参数
total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"Total trainable params before: {total_params}") #Total trainable params before: 124441346
for param in model.parameters():
param.requires_grad = False
total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"Total trainable params after: {total_params}") #Total trainable params after: 0
replace_linear_with_lora(model, rank=16, alpha=16)
total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"Total trainable LoRA params before: {total_params}") #Total trainable LoRA params before: 2666528可以看到模型参数得到大幅度降低。通常会将alpha设置为rank的一半、两倍或相等的值。最后就是微调修改后的LoRA层。这里继续调用第六讲的train_classifier_simple方法训练模型。
#开始微调LoRA层参数
import time
from classificationFine_tuning import train_classifier_simple
model.to(device)
start_time = time.time()
torch.manual_seed(123)
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5, weight_decay=0.1)
epochs = 5
train_losses, val_losses, train_accs, val_accs, examples_seen = train_classifier_simple(
model, train_loader, val_loader, optimizer, device, epochs,
eval_freq=50, eval_iter=5
)
end_time = time.time()
print("Training completed in {(end_time - start_time) / 60:.2f} minutes.")在这里,使用LoRA训练模型比不使用LoRA时,花费的时间可能要更长,因为LoRA层在前向传播过程中引入了额外的计算。但是,对于较大的模型,反向传播的成本更高,此时使用LoRA的模型通常比不使用LoRA的模型训练速度更快。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)