Lora原理、图解及实现
LoRA (Low-Rank Adaptation) 是一种非常高效的微调(Fine-tuning)技术,目前广泛应用于大语言模型(LLM)和图像生成模型(如 Stable Diffusion)的定制化训练中。
LoRA (Low-Rank Adaptation) 是一种非常高效的微调(Fine-tuning)技术,目前广泛应用于大语言模型(LLM)和图像生成模型(如 Stable Diffusion)的定制化训练中。
简单来说,它的核心思想是:在大模型微调过程中,并不需要更新所有的参数,只需要更新极少量的参数就能达到很好的效果。
1. 核心直觉:为什么要用 LoRA?
在 LoRA 出现之前,微调一个大模型(比如 GPT-3 或 LLaMA)面临着巨大的算力挑战:
-
全量微调 (Full Fine-tuning): 需要更新模型中的每一个参数。如果模型有 70 亿参数(7B),你需要巨大的显存来存储梯度和优化器状态(Optimizer States)。这通常只有大公司玩得起。
-
内在维度假设 (Intrinsic Dimension Hypothesis): 有研究表明,大模型虽然参数众多,但在处理特定任务时,其参数矩阵的变化其实是低秩 (Low-Rank) 的。这意味着,实际上起作用的参数变化并不需要那么高的维度,可以用更少的信息量来描述。
LoRA 的灵感: 既然参数的变化是低秩的,那我们为什么不直接训练这个“变化的量”,并且用两个小矩阵相乘来近似它呢?
2. LoRA 的技术原理与数学推导
假设我们有一个预训练好的权重矩阵![]() (例如 Transformer 中的 Wq, Wk, Wv 等层)。
(例如 Transformer 中的 Wq, Wk, Wv 等层)。
2.1 传统的微调
在全量微调中,我们通过反向传播计算梯度,得到权重的更新量 ΔW。新的权重 W 为:
W = W₀ + ΔW
这里 ΔW 的维度和 W₀ 一样,都是 d * k。
2.2 LoRA 的做法
LoRA 冻结 了 W₀(即在训练时不更新 W₀),而是对 ΔW 进行低秩分解。
LoRA 假设 ΔW 可以分解为两个极小的矩阵 B 和 A 的乘积:
ΔW = B · A
其中:
-
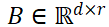
-
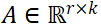
-
r 是秩 (Rank),通常选得很小(例如 r=4, 8, 16, 64),远小于 d 和 k。
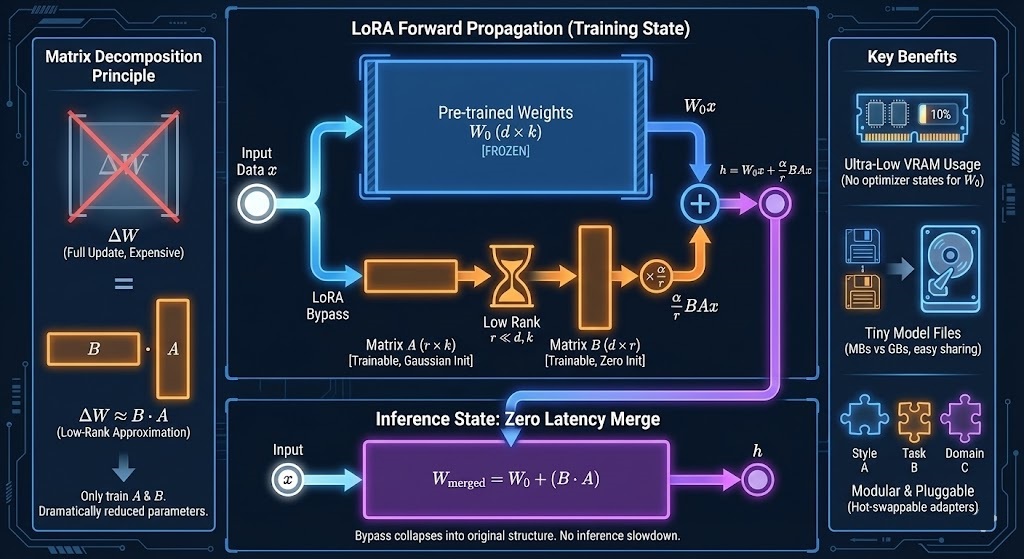
2.3 前向传播过程
当输入数据 x 进入该层时,计算过程变为:
![]()
-
W₀x:利用预训练的原始权重处理输入(这部分参数冻结)。
-
BAx:利用 LoRA 旁路处理输入(这部分参数可训练)。
-
最后将两者的结果相加。
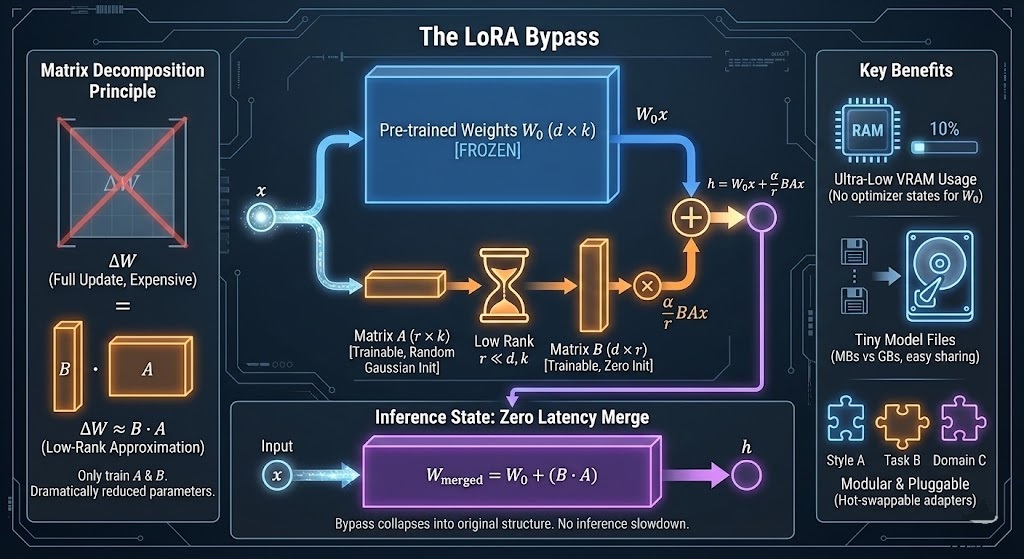
[Image Concept]: 想象一个“旁路”结构。左边是巨大的原始模型(冻结),右边搭了一座很窄的桥(LoRA Adapter)。数据同时流过两边,最后汇合。
3. 关键细节:初始化与缩放
为了保证训练开始时模型的表现和预训练模型完全一致,LoRA 对矩阵 A and B 的初始化有特殊要求:
-
矩阵 A: 使用随机高斯分布初始化(Random Gaussian Initialization)。
-
矩阵 B: 初始化为全 0。
为什么?
因为初始状态下 ![]()
这意味着在训练的第一步,![]() ,模型完全等同于原始预训练模型。这保证了微调过程是平滑启动的,不会一开始就破坏模型原有的能力。
,模型完全等同于原始预训练模型。这保证了微调过程是平滑启动的,不会一开始就破坏模型原有的能力。
-
缩放系数 (Scaling Factor)
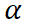 :
:实际计算中,ΔW 还会乘以一个系数
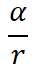 :
: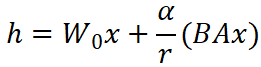
-
r 是你设定的秩。
-
是一个常数超参数。
-
这样做的好处是,当你改变 r 的大小时,不需要重新去精细调整学习率(Learning Rate)。
-
4. LoRA 的巨大优势
-
显存占用极低:
-
因为冻结了 W₀,我们不需要存储 W₀ 的梯度和优化器状态。
-
只需要存储极小的 A 和 B 的梯度。显存占用通常可以降低到全量微调的 1/3 甚至更少。
-
-
模型文件极小:
-
训练好的 LoRA 权重文件通常只有几 MB 到几百 MB(取决于 r 的大小),而全量微调的模型可能高达几十 GB。
-
这使得分享和切换风格(如 Stable Diffusion 中的各种画风 LoRA)变得非常容易。
-
-
推理无延迟 (Zero Inference Latency):
-
这是 LoRA 最聪明的地方。虽然训练时是旁路结构,但在推理(部署)时,我们可以利用矩阵分配律,直接将训练好的 B · A 加回到 W₀ 中:
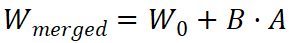
-
部署时直接使用
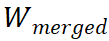 ,结构与原模型完全一致,推理速度没有任何损失。
,结构与原模型完全一致,推理速度没有任何损失。
-
-
可插拔与模块化:
-
你可以针对不同的任务训练不同的 LoRA(例如一个负责写代码,一个负责写小说)。
-
运行时可以动态替换 B · A 部分,或者混合多个 LoRA。
-
5. LoRA 的局限性与改进
虽然 LoRA 很强,但也不是完美的:
-
信息容量限制: 由于 r 限制了参数更新的秩,对于需要极其复杂的知识注入或逻辑重构的任务,LoRA 的效果可能不如全量微调。
-
超参数敏感: 选择合适的 r(秩)和目标模块(Target Modules,即要把 LoRA 加在哪一层,如 q, v 还是全加)对效果影响很大。
衍生变体:
为了解决这些问题,出现了很多变体,例如:
-
QLoRA: 结合了 4-bit 量化技术,进一步大幅降低显存需求(单卡 24G 显存即可微调 33B 模型)。
-
LoRA+ / AdaLoRA: 动态调整秩 r 或优化学习率策略。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)