多模态大模型:视觉模型与LLM的结合之路一:Blip2、LLaVA
模型结构上:LLaVA仅用简单的线性链接层就完成了视觉模型与LLM的结合,结合方法简单但有效。训练数据上:LLaVA给出了一种使用ChatGPT造训练数据的方法。虽然类似的方法在语言大模型的训练中较为常见,但该文是在多模态大模型上的首次尝试。训练方法上:作者先采用了大量的易学数据训练少量参数让模型学会认图,再用少量难学的数据训练大量参数让模型学会基于图像的多轮对话和逻辑推理能力。
本文首发于微信公众号:人工智能与图像处理
多模态大模型:视觉模型与LLM的结合之路一:Blip2、LLaVA (qq.com)
一、背景介绍
2023年随着ChatGPT的问世,大模型 + 小样本Lora微调的范式在各类NLP任务上均取得了不错的效果。计算机视觉也迫切地想与大模型结合,从而提高模型准确率和模型泛化性。
二、结合方式的探索
目前大模型和视觉的主流结合方式主要分以下三步:
-
将图片经过一个Pretrained VIT,获取视觉特征。
-
将该视觉特征通过某种变换层(Adapter)对齐到大模型 Input Embedding的维度上
-
将对齐后的视觉特征concat到Input Embedding,输入到大模型(Large Language Model, LLM)
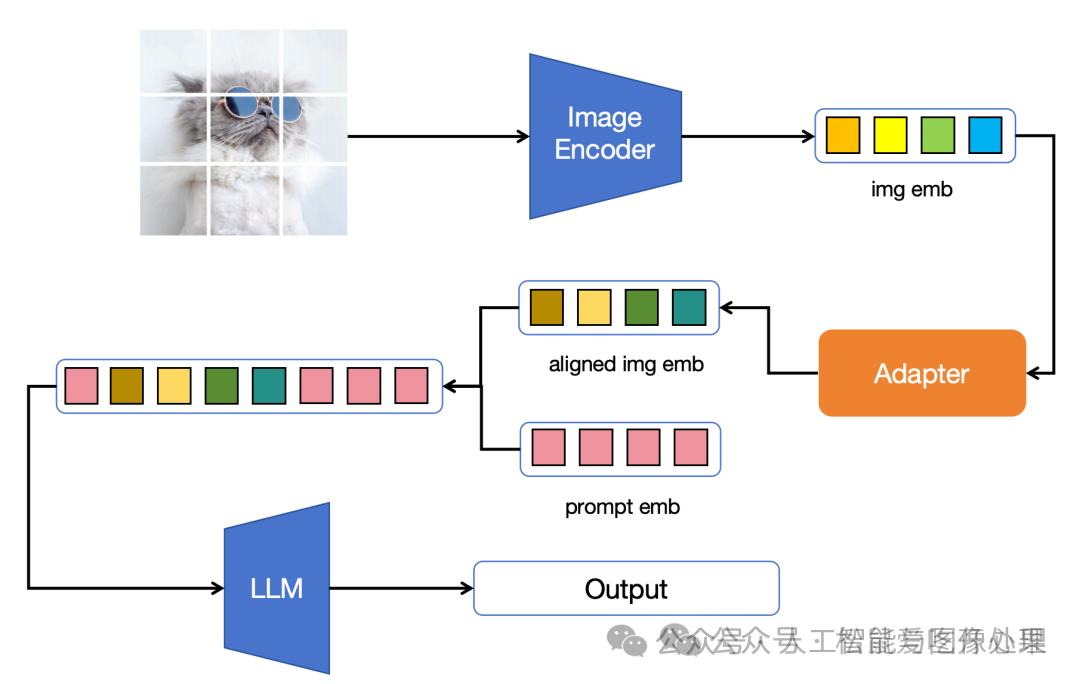
图1:图像与大模型的主流结合方式
三、 尝试多模态的现有Adapter(Blip2)
在ChatGPT发布之前,已经有Clip,Blip等多种多模态模型,llm无非就是一个大一点的语言模型,那么尝试现有多模态Adapter就是一个很自然的想法。
3.1 模型结构
Blip2的Adapter使用Query-Transformer(Q-Former) + 全连接层(Fully Connected)的结构
- 主旨思想:将img和prompt同时输入到Transformer中,同时利用Cross Attention 将vision emb 与可学习的,序列长度较短的learnable querys进行交互。最后将交互后的learnable querys作为视觉特征,输入到大模型,从而达到降低视觉特征序列长度的目的。
- 目的:利用这样一个类似BottleNeck的结构,提升学习效果,减小视觉特征的seq len,这样能在有限的资源下,加快大模型的训练。
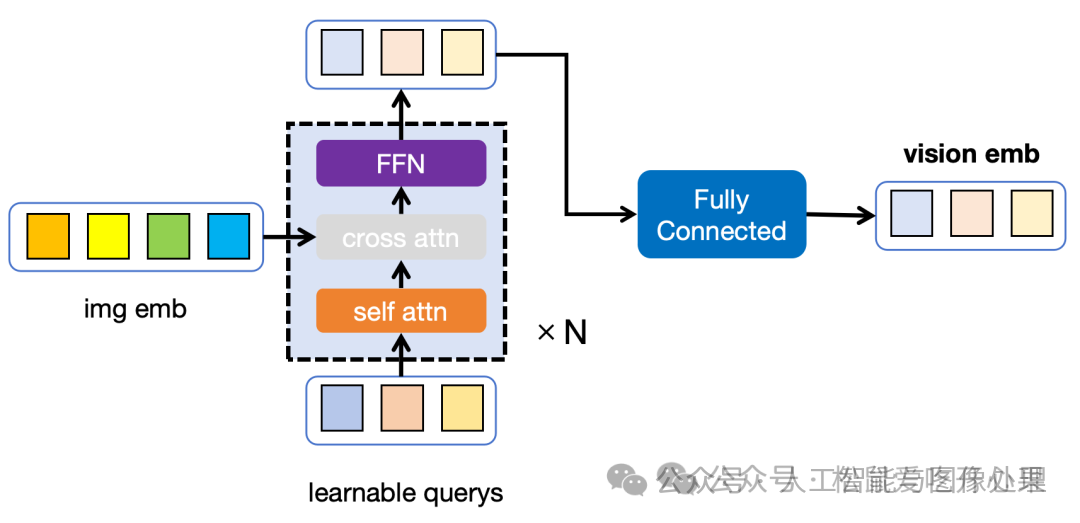
图2:Blip2的Adapter,分为Q-Former(虚线框)和Fully Connected两部分
Q-Former来自多模态模型Blip,是一个魔改的Transformer,其输入部分增加了可学习的输入(learnable querys)。learnable querys和img emb通过cross attn进行交互,最后网络把模型输出的learnable query作为图像特征,喂给大模型。作者试图使用Q-Former实现图像的压缩感知,即缩短表示图像emb序列长度的同时,尽可能保留对生成文字有用的图像信息。最后 Fully Connect 模块用于讲Q-Former输出的维度对齐到大模型的维度。
3.2 模型训练
模型训练分为两个阶段,分别是 图片表示学习(Vision-Language Representation Learning from a Frozen Image Encoder)和图生文预训练(vision-to-language generative pre-training)。训练数据为图文对。
3.2.1 图片表示学习(训练Q-Former的图像表示能力)
图片表示学习只训练Adapter中的Q-Former结构,训练目的是将Image-Encoder输出的视觉特征进行压缩感知,提取最能生成文字的视觉特征。其仅用到了Image Encoder 和 Q-Former且并未使用LLM。为了节省显存,进行图片表示学习时,Image Encoder的参数不做更新。
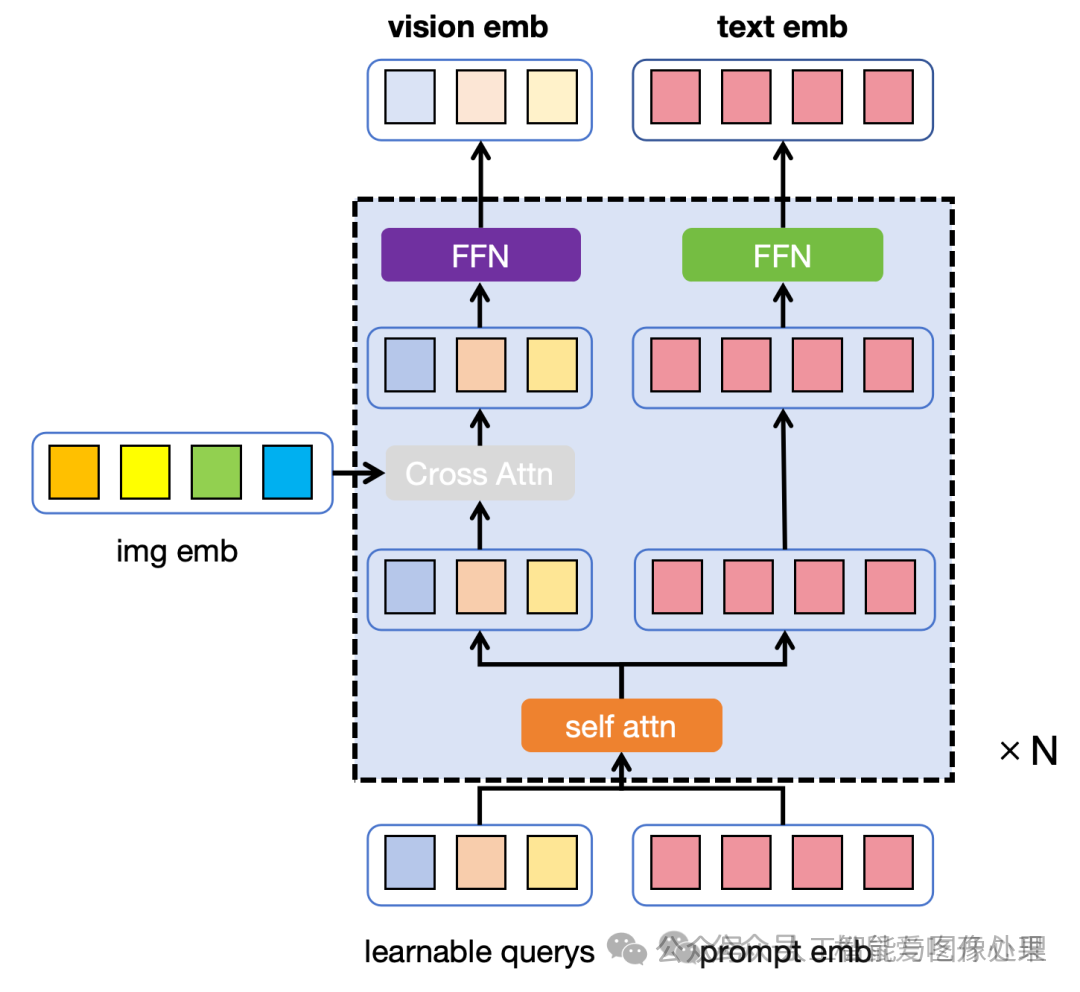
图3:图片表示学习时Q-Former的模型结构,不同的颜色表示不同的权重,橙\灰\紫是Adapter中Q-Former的权重
在这里除了Q-Former外,还引入了额外的权重用于处理文字(图三右上,绿色部分),训练时Q-Former加载的是Bert的权重(cross attn随机初始化)。
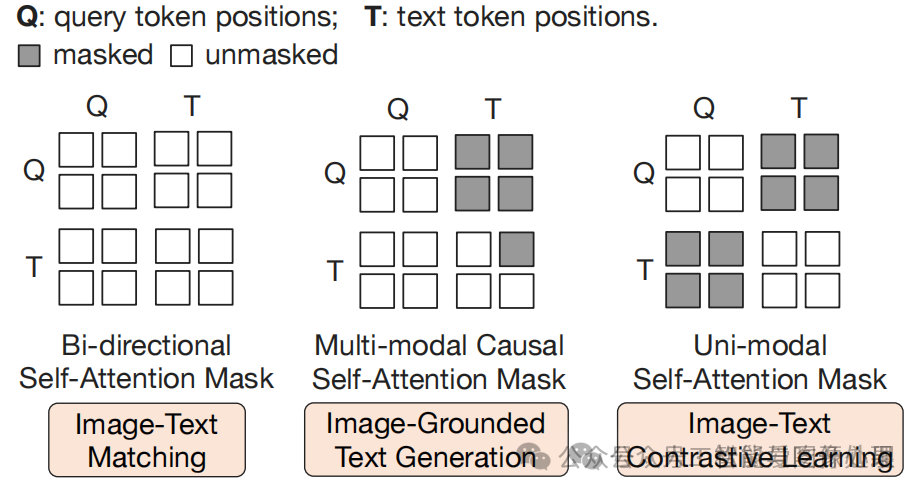
图4:不同训练任务的attn-mask
其具体有三个训练任务,使用的训练数据集为一系列图文对(文字是图片的一个描述),每个训练任务的attn-mask均不同。
- 图文对比学习(Image-Text Contrastive Learning, ITC)该任务输入图像(img emb)和一段文字(prompt emb),在经过img_encoder和Q-Former后,我们使用一个emb表示图像,用另一个emb表示文字。输入的文字会额外带一个[CLS]token, 文字的emb即用[CLS] token 对应的emb。图像的emb是从vis emb 的多个query中与text emb相似度最高的query作为图像的emb。在计算loss时,使用图四最右侧的attn mask 能保证图像和文字的emb生成互不干扰。正样本为图文对,负样本将文字换为数据集中随机的某段文字。我们希望正样本的图像emb和文字emb尽可能相似,负样本的图像emb和文字emb尽可能远离。
- 基于图像的文字生成(Image-Grounded Text Generation, ITG)该任务使用图像生成对应的文字描述,使用图四中间的attn mask,在文字能看到图片的同时保证文字部分使用 transformer decoder的causal attn mask。
- 图文匹配(Image-Text Matching, ITM)该任务类似ITC,但与ITC不同的是,该任务不再要求对齐图像和文字的表示,而是直接做一个分类任务,判断图像和文字是否是一对。attn mask使用图四左边的attn mask,保证图像和文字互相之间都可以看到。
3.2.2图生文预训练(训练整个多模态大模型的Image-Caption能力)
图生文是为了将Q-Former学习到的视觉特征与大模型相结合,利用大模型的生成能力更好的完成VQA任务。该阶段将Q-Former生成的。
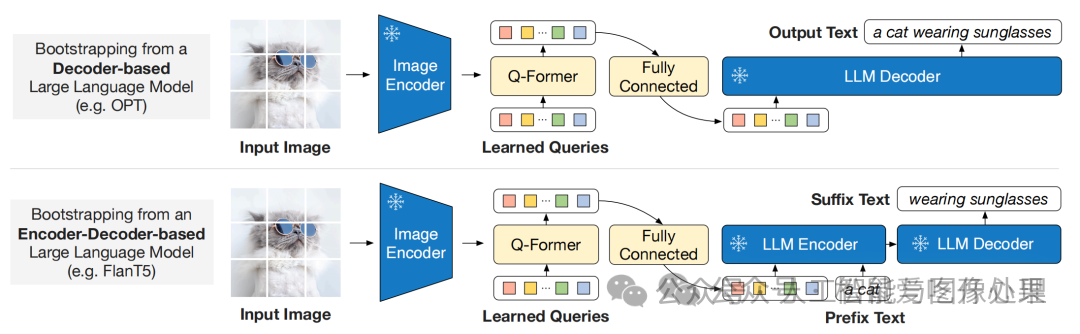
图5: Blip与大模型结合的两种方法
大模型分为两种分别是Decoder only类型的大模型和Encoder-Decoder类型的大模型。Blip2分别尝试与这两种大模型相结合。对于Decoder Only形式的大模型,输入为图片,输出为图文对的文字;对于Encoder-Decoder类的大模型,文字会被拆分成前缀和后缀,输入为图片和前缀,输出为后缀。为了节省显存并加速训练,该训练阶段图像Encoder和LLM的权重均不做更新。
模型总结
Blip2通过尝试Blip中模态融合的方式,通过冻住大模型权重和两阶段预训练的方法,将视觉特征与大模型对齐,借助大模型的生成能力,利用有限的资源提升了视觉VAQ任务的效果。
----------------------------分割线------------------------------------------------
一、上期回顾
上期我们介绍了多模态大模型的一般架构和首个将视觉模型与大模型结合的尝试(Blip2)。本期我们介绍更激进的尝试:LLaVA
二、LLaVA
Blip2的出现表示,这种将视觉模态经过一个Adapter对齐到大模型输入的架构是可行的。于是研究者开始考虑,除了繁琐的Q-Former对齐方式外,是否存在更简单的方式来对齐图像特征?LLaVA使用单个线性连接层完成了视觉模态与大模型的结合。除此之外,LLaVA还首次实现了多模态大模型的多轮对话能力。
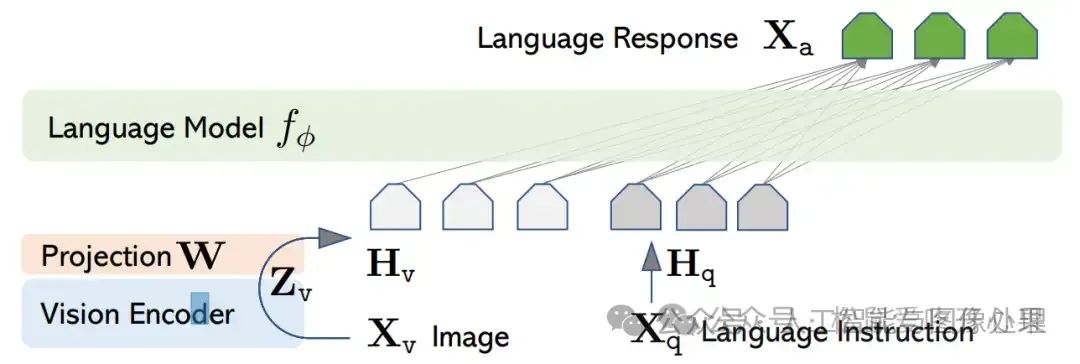
图1:LLaVA的模型结构,使用单个线性全连接层(W)作为Adapter
2.1 训练数据
在LLaVA产生的时代,开源的图像大模型训练数据几乎都是图文对(img, caption pair)其中文字是图片内容的一个描述。几乎没有开源的 instruction-tuning 数据集。为了让多模态大模型更好的与人类进行对话。LLaVA利用图文对创建了两个数据集:简单的对话数据集(低质量,数据量大,标注成本低),复杂的对话数据集(高质量,数据量小,标注成本高)。
2.1.1 图文对 --> 简单的对话数据
作者利用chat-gpt生成如下的问题,并将caption作为问题的答案
"Describe the image concisely."
"Provide a brief description of the given image."
"Offer a succinct explanation of the picture presented."
"Summarize the visual content of the image."
"Give a short and clear explanation of the subsequent image."
"Share a concise interpretation of the image provided."
"Present a compact description of the photo’s key features."
"Relay a brief, clear account of the picture shown."
"Render a clear and concise summary of the photo."
"Write a terse but informative summary of the picture."
"Create a compact narrative representing the image presented." 这些生成的问题就是换着法子问"请描述一下这个图像",这样就生成了如下格式的训练数据 <img, question for caption, caption>。这些训练数据较为简单,只能用于单轮对话且缺少多样性,但生成成本较低。
2.1.2 图文对 --> 更复杂的对话数据
为了使用chat-gpt生成带图片的多轮对话数据,作者使用目标检测将图片变成chat-gpt可以读懂的图片描述。

图2:利用目标检测将图文对转换为chat-gpt能读懂的图片描述
基于这些图片描述作者使用chat-gpt生成了三类训练数据:
-
基于图片进行多轮对话
-
给出图片的详细描述
-
基于图片的复杂逻辑推理(如 “图2中的图片显示 这群人在做什么?”)
下面详细给出了多轮对话类数据的生成方法,其他两类的生成方法与多轮对话类的生成方法类似。作者首先手动标注了了几个例子

图3:作者标注的例子,其中Captions是利用图2所示的方法结合chatgpt生成的图片描述,Conversions是作者的标注
可以利用上述例子生成Prompt:
# 生成对话类的Prompt
messages=[
{"role":"system",
"content":"""
You are an AI visual assistant, and you are
seeing a single image. What you see are provided with five sentences, describing the same image you
are looking at. Answer all questions as you are seeing the image.
Design a conversation between you and a person asking about this photo. The answers should be in a
tone that a visual AI assistant is seeing the image and answering the question. Ask diverse questions
and give corresponding answers.
Include questions asking about the visual content of the image, including the object types, counting
the objects, object actions, object locations, relative positions between objects, etc. Only include
questions that have definite answers:
(1) one can see the content in the image that the question asks about and can answer confidently;
(2) one can determine confidently from the image that it is not in the image. Do not ask any question
that cannot be answered confidently.
Also include complex questions that are relevant to the content in the image, for example, asking
about background knowledge of the objects in the image, asking to discuss about events happening in
the image, etc. Again, do not ask about uncertain details. Provide detailed answers when answering
complex questions. For example, give detailed examples or reasoning steps to make the content more
convincing and well-organized. You can include multiple paragraphs if necessary. """}
]
forsampleinfewshot_samples:
messages.append({"role":"user","content":sample[‘Captions’]})
messages.append({"role":"assistant","content":sample[‘Conversion’]})
messages.append({"role":"user","content":"Img Content"})
基于上述方法,作者共生成了158K复杂对话数据,其中包含58K多轮对话数据,22K详细描述数据和78K的复杂逻辑推理数据,这些训练数据生成成本较高。
2.2 模型训练
对于多轮对话训练数据{img, [(Q1,A1), ..., (QT, AT)]},作者将其转换为如下序列
img
User: Q1
Assistant: A1
...
User: QT
Assistant: AT
在计算损失时,只计算AI部分的损失,这样就将多轮对话数据和单轮对话数据统一了起来(统一成sequence),方便用于模型训练。模型训练分为两个阶段分别为”图像特征对齐预训练“和”模型对话/读图能力训练“。
2.2.1 图像特征对齐预训练
该阶段只训练线性链接层,使用相对较为简单易学的训练数据,将Adapter生成的图像特征与LLM的input Embedding对齐,让模型拥有初步的读图能力。
- 训练数据:利用2.1.1节的数据构造方法 和 595K图文对 生成的 简单对话数据 (使用各种不同的问法 问该图片描述了什么东西)。
- 可学习参数:LLM和Vision Encoder均不训练,只训练线性链接层。
- 训练目的:让模型拥有初步的读图能力。
2.2.2 模型对话/读图能力训练
该阶段训练Adapter和LLM对参数,使用较难学习的多轮对话和科学问答数据,让模型具有对话能力。
- 训练数据:利用2.1.2节的数据构造方法生产的158K复杂对话数据 + Since QA banchmark中的训练数据。
- 可学习参数:Vision Encoder不训练,训练线性链接层和LLM。
- 训练目的:让模型拥有基于图片进行多轮对话和逻辑推理的能力。
三、小结
- 模型结构上:LLaVA仅用简单的线性链接层就完成了视觉模型与LLM的结合,结合方法简单但有效。
- 训练数据上:LLaVA给出了一种使用ChatGPT造训练数据的方法。虽然类似的方法在语言大模型的训练中较为常见,但该文是在多模态大模型上的首次尝试。
- 训练方法上:作者先采用了大量的易学数据训练少量参数让模型学会认图,再用少量难学的数据训练大量参数让模型学会基于图像的多轮对话和逻辑推理能力。


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 40
40 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)