G-LLaVA:使用多模态大语言模型求解几何问题
本文提出了G-LLaVA智能体,通过构建增强的几何数据集Geo170K,显著提高了多模态大语言模型在几何问题解决中的表现。论文题目: G-LLaVA: Solving Geometric Problem with Multi-Modal Large Language Model论文链接: https://arxiv.org/abs/2312.11370PS: 欢迎大家扫码关注公众号,我们一起在AI
文章介绍了多模态大语言模型(MLLMs)在解决几何问题中的应用和挑战。尽管LLMs在语言推理方面表现出色,但它们在处理几何图形时仍然存在困难,主要体现在无法准确理解几何元素及其关系。为了解决这一问题,作者提出了一个新的多模态几何数据集Geo170K,结合了几何问题的独特逻辑形式和表现方式,利用现有的数据生成技术进行增强。基于这个数据集,作者开发了G-LLaVA模型,在解决几何问题上表现出色,显著超越了现有的其他模型。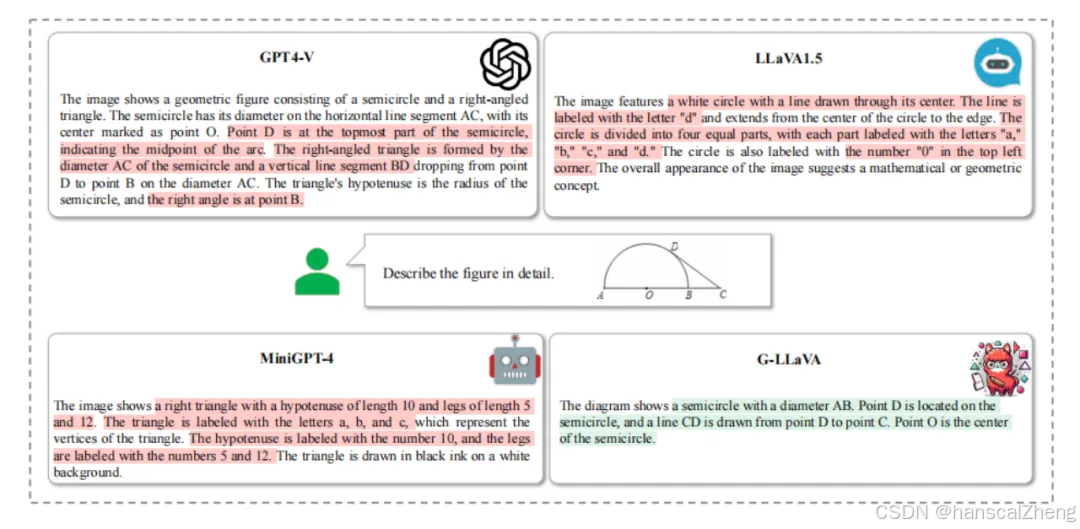
1 多模态几何数据生成框架
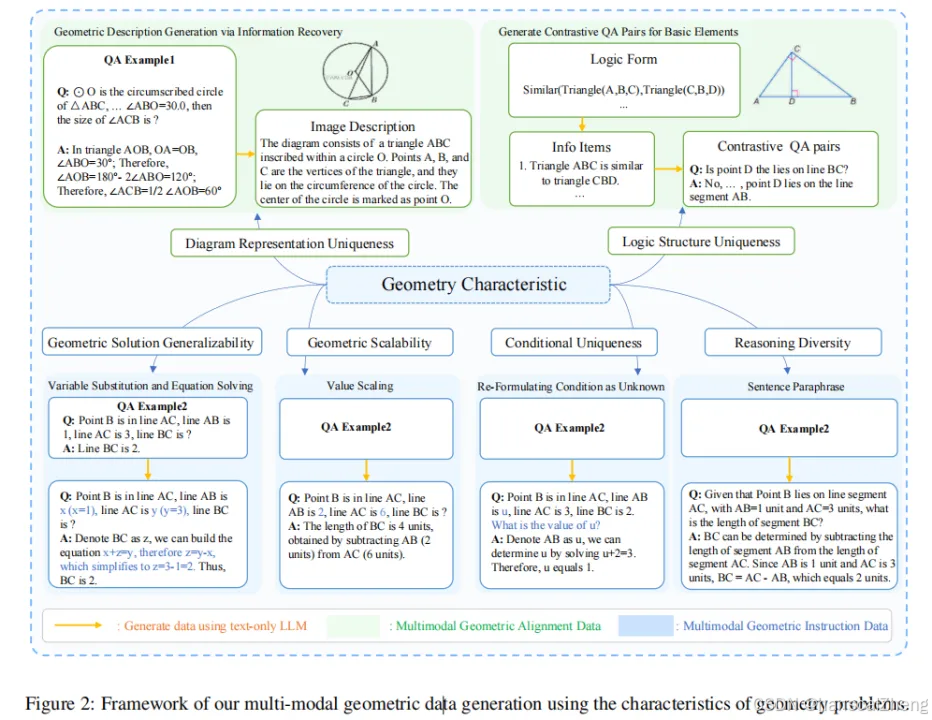
多模态几何数据生成框架是通过现有的几何数据集和几何问题的特征,来构建的一个多模态几何数据集。该数据集包含图像-文本配对和问题-答案对,旨在为智能体提供丰富的几何信息。数据生成过程包括提取几何问题的逻辑特征,并通过文本生成模型生成与图像匹配的描述信息。
以下是生成框架的一些简要特点:
· 几何问题特征提取:利用几何问题的独特逻辑形式和表现特点(如几何推理结构、几何元素的相互关系、几何图形的可扩展性等),对几何问题进行分析和建模。
· 生成图像-文本数据对:根据几何问题的描述,生成包含几何图形和相应文字说明的图像-文本配对。使用文本生成模型(如ChatGPT)生成描述性的图像标签和问题解答对,确保生成的文本能够准确反映图像中的几何关系。
· 生成对比性问答对:通过对几何图形进行深度解析,生成不同的问答对。这些问题可以考察几何元素的存在性、关系及图形特性。例如,检查特定点是否位于某一条线段上,或确定角度和长度之间的关系。
· 生成数据集:通过上述步骤生成大量带有几何描述的图像-文本配对及相应的问答对,构建一个大规模的多模态几何数据集。该数据集结合了几何图形的视觉信息与文本信息,为多模态智能体提供了足够的训练数据。
2 G-LLaVA智能体
多模态对齐(Cross-Modal Alignment):G-LLaVA智能体采用了多模态对齐技术,通过将图像信息和文本信息映射到统一的嵌入空间。具体来说,图像通过视觉编码器(如视觉Transformer)进行处理,文本通过语言模型(如LLaMA)进行编码,然后将这两种信息融合到统一的空间中,以实现图像与文本的有效结合。
· 指令调优(Instruction Tuning):在完成对齐后,G-LLaVA智能体进一步通过指令调优提高其在几何问题解决中的能力。通过基于已有几何数据集的问答对进行训练,智能体能够更好地理解用户输入的几何问题,并根据图像和文字提供合理的解答。
· 知识增强与推理:在模型训练过程中,G-LLaVA还通过增强数据的方式(如生成更多的对比性问答对、改变问题描述等),进一步提升其推理能力。这样可以确保智能体能够处理更复杂的几何问题,并在解决过程中展现出更强的逻辑推理能力。

3 结语
本文提出了G-LLaVA智能体,通过构建增强的几何数据集Geo170K,显著提高了多模态大语言模型在几何问题解决中的表现。
论文题目: G-LLaVA: Solving Geometric Problem with Multi-Modal Large Language Model
论文链接: https://arxiv.org/abs/2312.11370
PS: 欢迎大家扫码关注公众号_,我们一起在AI的世界中探索前行,期待共同进步!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)