利用Azure Speech手搓一个实时中英口译工具
本文介绍了一个本地化部署的中文实时转英语口语工具的开发过程。该工具采用模块化设计,包含语音识别(Azure Speech SDK)、机器翻译(Hugging Face MarianMT本地模型)和语音合成(Azure TTS)三个核心模块,通过多线程并行处理实现低延迟(<2秒)。系统运用Python的queue.Queue实现线程间通信,采用Streamlit构建简易UI,并针对实时性需求设
简述
最近接了个工具任务给同事做一个口语中文转英语的实时工具,为了省下购买讯飞翻译机的费用,但是需求还是中文说完,英文立刻响起,像魔法一样自然。
目标很清晰:
- 实时语音识别(中文)
- 实时机器翻译(中 → 英)
- 实时语音合成(英文朗读)
- 全程延迟 < 2 秒
- 部署在本地,零云依赖(除 Azure Speech)
- 用 Streamlit 做 UI,简单到小学生都会用
设计
在动手之前,先画架构图
麦克风
↓
[Azure Speech SDK] → 实时识别(zh-CN)
↓ (Queue)
Streamlit 主线程 ←→ 后台识别线程
↓
Hugging Face MarianMT (本地模型)
↓
翻译结果 → Queue
↓
Azure TTS → 英文朗读
↓
扬声器核心思想:“识别、翻译、朗读”三大模块并行运行,互不阻塞。
用 Python 的 queue.Queue 做线程间通信,用 threading.Thread 做异步任务,用 st_autorefresh 实现 UI 实时更新。
一句话总结: “让语音识别在后台狂奔,翻译在 GPU 上飞,TTS 在耳边唱,Streamlit 只管刷新。”
依赖
关键依赖说明:
| 依赖 | 作用 | 坑点 |
|---|---|---|
| azure-cognitiveservices-speech | 微软顶级语音识别与合成 | 必须匹配地区和 Key |
| transformers + MarianMT | 本地离线翻译 | 模型需预下载 |
| streamlit-autorefresh | 自动刷新 UI | 官方 st.rerun 有延迟 |
| torch | 模型推理加速 | MPS/CUDA 支持 |
模型下载(离线部署神器)
git lfs install
git clone https://huggingface.co/Helsinki-NLP/opus-mt-zh-en为什么选 MarianMT?
- 轻量(<500MB)
- 支持离线
- 中英翻译质量接近商业级
- 推理速度快(GPU < 100ms)
语音识别——“听懂你说的每一个字”
后台线程 + Queue 通信
def recognition_thread(cmd_q, res_q):
recognizer = speechsdk.SpeechRecognizer(...)
recognizer.recognizing.connect(lambda e: res_q.put(("partial", e.result.text)))
recognizer.recognized.connect(lambda e: res_q.put(("final", e.result.text)))
recognizer.start_continuous_recognition()
while cmd_q.get() != "stop":
time.sleep(0.1)
recognizer.stop_continuous_recognition()主线程:
if st.button("开始"):
st.session_state.thread = threading.Thread(target=recognition_thread, ...)
st.session_state.thread.start()实时切句——“什么时候算一句话?”
问题:Azure 返回的是“流式文本”
"我今天去" → "我今天去北" → "我今天去北京"
如果每来一句就翻译,会出现:
“I go today” → “I go to north today” → “I go to Beijing today”
碎片化翻译,体验灾难!
解决方案:双保险切句机制
策略一:recognized 事件(完整句)
策略二:recognizing 超时 1.5 秒 → 强制切句
if current_time - last_partial > 1.5:
# 超时切句
translate_and_speak(zh_buffer)
zh_buffer = ""效果:既能抓完整句,又不漏掉结巴说话的碎片
问题:翻译耗时 200ms ~ 800ms,主线程卡顿!
解决方案:翻译任务丢进线程池
threading.Thread(
target=translate_task,
args=(sent, translate_q),
daemon=True
).start()翻译结果通过 translate_q 再推给 TTS 线程。
三层异步:识别 → 翻译 → 朗读,流水线并行!
TTS 朗读——“让英文活起来”
需求:
- 朗读时暂停识别(避免回声)
- 朗读完恢复识别
- 不阻塞 UI
坑:speak_text_async().get() 是阻塞的!
synth.speak_text_async(text).get() # 阻塞!解决方案:识别器动态启停
def speak_only(text, recognizer):
if recognizer:
recognizer.stop_continuous_recognition()
synth.speak_text_async(text).get()
if recognizer:
recognizer.start_continuous_recognition()边说边停,边译边读,互不干扰!
识别器崩溃重启——“永不宕机的守护神”
场景复现:
说话中途,麦克风被占用 → 识别器报错 → 整个线程挂了
解决方案:异常捕获 + 自动重启
except Exception as e:
res_q.put(("error", f"识别线程异常: {e}, 1秒后重启"))
time.sleep(1)
# 重新进入 while True 循环UI 设计——“简洁明快”
需求:
- 实时显示当前识别文本
- 显示翻译历史
- 状态栏提示
- 一键启动/停止
实现
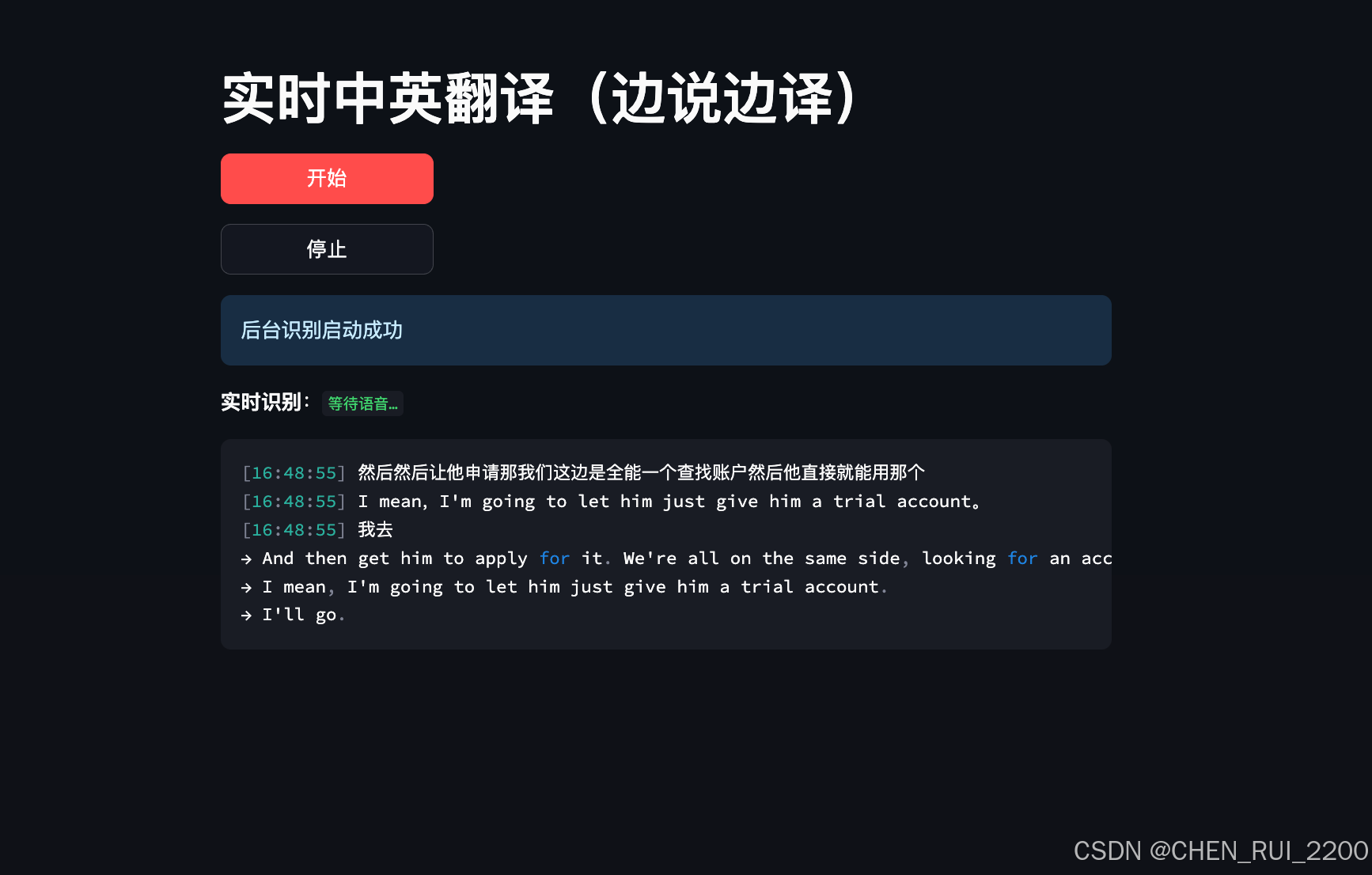
status_ph.info(st.session_state.status)
recog_ph.markdown(f"**实时识别**:`{zh_buffer or '等待语音…'}`")历史记录:
log_lines = [
f"[{time}] {zh}" for zh in zh_history[-12:]
] + [
f"→ {en}" for _, en in en_history[-12:]
]
log_ph.code("\n".join(log_lines))启动测试
UI 显示形态
附全量代码
import queue
import threading
import time
import azure.cognitiveservices.speech as speechsdk
import streamlit as st
import torch
from streamlit_autorefresh import st_autorefresh
from transformers import MarianMTModel, MarianTokenizer
# ============ 配置区域 ============
SPEECH_KEY = "xxx"
REGION = "xxx"
MODEL_PATH = "./opus-mt-zh-en"
MIN_SPEECH_LEN = 2 # 识别文本最短长度,低于认为是噪声
# =================================
# ---------- 初始化 session_state ----------
if "running" not in st.session_state:
st.session_state.running = False
if "status" not in st.session_state:
st.session_state.status = "准备就绪"
if "zh_history" not in st.session_state:
st.session_state.zh_history = []
if "en_history" not in st.session_state:
st.session_state.en_history = []
if "processed_sentences" not in st.session_state:
st.session_state.processed_sentences = set()
if "zh_buffer" not in st.session_state:
st.session_state.zh_buffer = ""
if "last_partial" not in st.session_state:
st.session_state.last_partial = 0.0
st.set_page_config(page_title="实时翻译", layout="centered")
st.title("实时中英翻译(边说边译)")
# ---------- 模型加载 ----------
@st.cache_resource
def load_model():
with st.spinner("加载翻译模型…"):
tokenizer = MarianTokenizer.from_pretrained(MODEL_PATH)
model = MarianMTModel.from_pretrained(MODEL_PATH)
device = "mps" if torch.backends.mps.is_available() else ("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
return tokenizer, model, device
tokenizer, model, device = load_model()
# ---------- 翻译函数 ----------
def translate(text):
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True, max_length=512).to(device)
out = model.generate(**inputs)
return tokenizer.decode(out[0], skip_special_tokens=True)
# ---------- TTS 朗读函数 ----------
def speak_only(text, recognizer=None):
try:
if recognizer:
try:
recognizer.stop_continuous_recognition()
except Exception as e:
st.warning(f"停止识别失败: {e}")
cfg = speechsdk.SpeechConfig(subscription=SPEECH_KEY, region=REGION)
cfg.speech_synthesis_voice_name = "en-US-GuyNeural"
synth = speechsdk.SpeechSynthesizer(speech_config=cfg)
synth.speak_text_async(text).get()
if recognizer:
try:
recognizer.start_continuous_recognition()
except Exception as e:
st.warning(f"重启识别失败,尝试复位: {e}")
# 尝试复位 recognizer
try:
audio = speechsdk.audio.AudioConfig(use_default_microphone=True)
recognizer = speechsdk.SpeechRecognizer(speech_config=recognizer.speech_config, audio_config=audio)
st.session_state.recognizer = recognizer
recognizer.start_continuous_recognition()
except Exception as e2:
st.error(f"识别复位失败: {e2}")
except Exception as e:
st.error(f"TTS异常: {e}")
# ---------- 翻译任务 ----------
def translate_task(sent, translate_q):
try:
en = translate(sent)
translate_q.put((sent, en))
except Exception as e:
st.warning(f"翻译异常: {e}")
# ---------- 后台识别线程 ----------
def recognition_thread(cmd_q: queue.Queue, res_q: queue.Queue):
while True:
try:
cfg = speechsdk.SpeechConfig(subscription=SPEECH_KEY, region=REGION)
cfg.speech_recognition_language = "zh-CN"
cfg.set_property(speechsdk.PropertyId.SpeechServiceConnection_InitialSilenceTimeoutMs, "1500")
cfg.set_property(speechsdk.PropertyId.SpeechServiceConnection_EndSilenceTimeoutMs, "500")
audio = speechsdk.audio.AudioConfig(use_default_microphone=True)
recognizer = speechsdk.SpeechRecognizer(speech_config=cfg, audio_config=audio)
st.session_state.recognizer = recognizer
def recognizing(evt):
if evt.result.reason == speechsdk.ResultReason.RecognizingSpeech:
res_q.put(("partial", evt.result.text))
def recognized(evt):
if evt.result.reason == speechsdk.ResultReason.RecognizedSpeech:
if len(evt.result.text.strip()) >= MIN_SPEECH_LEN:
res_q.put(("final", evt.result.text))
def canceled(evt):
reason = evt.result.cancellation_reason
error = getattr(evt.result, "cancellation_error_details", "")
res_q.put(("error", f"{reason}: {error}"))
recognizer.recognizing.connect(recognizing)
recognizer.recognized.connect(recognized)
recognizer.canceled.connect(canceled)
recognizer.start_continuous_recognition()
res_q.put(("status", "后台识别启动成功"))
while True:
try:
cmd = cmd_q.get(timeout=0.1)
if cmd == "stop":
break
except queue.Empty:
continue
recognizer.stop_continuous_recognition()
res_q.put(("stopped", None))
break
except Exception as e:
res_q.put(("error", f"识别线程异常: {e}, 1秒后重启"))
time.sleep(1)
# ---------- UI 控件 ----------
col1, col2 = st.columns([1, 3])
with col1:
if st.button("开始", type="primary", use_container_width=True):
st.session_state.running = True
if st.button("停止", type="secondary", use_container_width=True):
st.session_state.running = False
status_ph = st.empty()
recog_ph = st.empty()
log_ph = st.empty()
# ---------- 启动/停止识别线程 ----------
if st.session_state.running and "thread" not in st.session_state:
st.session_state.cmd_q = queue.Queue()
st.session_state.res_q = queue.Queue()
st.session_state.translate_q = queue.Queue()
st.session_state.thread = threading.Thread(
target=recognition_thread,
args=(st.session_state.cmd_q, st.session_state.res_q),
daemon=True
)
st.session_state.thread.start()
st.session_state.status = "正在监听…"
if not st.session_state.running and "thread" in st.session_state:
st.session_state.cmd_q.put("stop")
st.session_state.thread.join(timeout=2)
for key in ["thread", "cmd_q", "res_q", "translate_q", "recognizer"]:
if key in st.session_state:
del st.session_state[key]
st.session_state.status = "已停止"
# ---------- 自动刷新 ----------
st_autorefresh(interval=500, key="autorefresh") # 每0.5秒刷新
# ---------- 主循环 ----------
def main_loop():
current_time = time.time()
zh_buffer = st.session_state.zh_buffer
# 1️⃣ 处理识别结果
try:
while True:
typ, data = st.session_state.res_q.get_nowait()
if typ == "partial":
zh_buffer = data.strip()
st.session_state.last_partial = current_time
elif typ == "final":
sent = data.strip()
if sent and sent not in st.session_state.processed_sentences:
st.session_state.processed_sentences.add(sent)
threading.Thread(target=translate_task, args=(sent, st.session_state.translate_q),
daemon=True).start()
elif typ == "error":
st.session_state.status = f"错误: {data}"
elif typ == "stopped":
st.session_state.status = "已停止"
elif typ == "status":
st.session_state.status = data
except queue.Empty:
pass
# 2️⃣ 超时切句
if zh_buffer and current_time - st.session_state.last_partial > 1.5:
sent = zh_buffer.strip()
if sent and sent not in st.session_state.processed_sentences:
st.session_state.processed_sentences.add(sent)
threading.Thread(target=translate_task, args=(sent, st.session_state.translate_q), daemon=True).start()
zh_buffer = ""
st.session_state.zh_buffer = zh_buffer
# 3️⃣ 处理翻译结果 → 启动朗读
try:
while True:
sent, en = st.session_state.translate_q.get_nowait()
st.session_state.zh_history.append(sent)
st.session_state.en_history.append((sent, en))
threading.Thread(target=speak_only, args=(en, st.session_state.get("recognizer")), daemon=True).start()
except queue.Empty:
pass
# 4️⃣ 更新 UI
status_ph.info(st.session_state.status)
recog_ph.markdown(f"**实时识别**:`{zh_buffer or '等待语音…'}`")
log_lines = [
f"[{time.strftime('%H:%M:%S')}] {s}"
for s in st.session_state.zh_history[-12:]
] + [
f"→ {e}" for _, e in st.session_state.en_history[-12:]
]
log_ph.code("\n".join(log_lines) if log_lines else "无记录")
if st.session_state.running:
main_loop()
else:
status_ph.info(st.session_state.status)
if st.session_state.en_history:
st.subheader("翻译记录")
for zh, en in st.session_state.en_history:
with st.expander(zh):
st.write("**英文**")
st.code(en)
性能优化——“从 3 秒延迟到 1.2 秒”
| 优化点 | 前 | 后 | 提升 |
|---|---|---|---|
| 模型设备 | CPU | MPS (Mac) / CUDA | 3x |
| 翻译批处理 | 单句 | 单句(已异步) | - |
| 识别超时 | 5s | 1.5s | 更灵敏 |
| TTS 语音 | 默认 | GuyNeural | 更自然 |
| 自动刷新 | st.rerun | st_autorefresh | 更稳定 |
最终延迟:平均 1.2 秒(从说话到听到英文)
附一个Tkinter实现的桌面版本
import ctypes
import queue
import re
import threading
import time
import tkinter as tk
import traceback
import uuid
from tkinter import scrolledtext, messagebox
import azure.cognitiveservices.speech as speechsdk
import pyaudio
import requests
# 强制初始化 COM(多线程模式),解决 Azure Speech SDK 音频初始化失败
ctypes.windll.ole32.CoInitializeEx(0, 2) # COINIT_APARTMENTTHREADED = 2
# ============ 配置区域 ============
SPEECH_KEY = "xxx"
REGION = "xxx"
MIN_SPEECH_LEN = 2
SILENCE_TIMEOUT = 10 # 无语音超时(秒)
MAX_SESSION_DURATION = 300 # 单次会话最大时长(秒)
# =================================
def has_audio_output():
try:
p = pyaudio.PyAudio()
dev_count = p.get_device_count()
p.terminate()
return dev_count > 0
except:
return False
def normalize_text(text):
return re.sub(r'[^\w\s]', '', text).replace(' ', '').strip()
def translate(text, to_lang='en'):
if not text.strip():
return ""
endpoint = "https://api.cognitive.microsofttranslator.com"
api_key = "xxx"
path = "/translate"
constructed_url = endpoint + path
headers = {
'Ocp-Apim-Subscription-Key': api_key,
'Ocp-Apim-Subscription-Region': "swedencentral",
'Content-type': 'application/json',
'X-ClientTraceId': str(uuid.uuid4())
}
params = {'api-version': '3.0', 'to': to_lang}
body = [{'text': text}]
try:
response = requests.post(constructed_url, params=params, headers=headers, json=body, timeout=10)
response.raise_for_status()
result = response.json()
return result[0]['translations'][0]['text']
except Exception as e:
return text
import winsound # 👈 新增:Windows 内置音频播放
import azure.cognitiveservices.speech as speechsdk
import winsound
import time
import traceback
def speak_only(text, ui_msg_q):
if not text.strip():
return
def log_tts_debug(message):
with open("tts_debug.log", "a", encoding="utf-8") as f:
f.write(f"[{time.strftime('%Y-%m-%d %H:%M:%S')}] {message}\n")
log_tts_debug(f"--- TTS 合成并用 winsound 播放 ---")
log_tts_debug(f"文本: {text}")
try:
# 1. 配置 Azure TTS
cfg = speechsdk.SpeechConfig(subscription=SPEECH_KEY, region=REGION)
cfg.speech_synthesis_voice_name = "en-US-GuyNeural"
# 或者直接传 None(效果一样)
synthesizer = speechsdk.SpeechSynthesizer(speech_config=cfg, audio_config=None)
# 4. 异步合成
result = synthesizer.speak_text_async(text).get()
if result.reason == speechsdk.ResultReason.SynthesizingAudioCompleted:
log_tts_debug("✅ Azure 合成成功,开始播放...")
audio_data = result.audio_data # bytes (WAV 格式)
# 5. 用 winsound 播放内存中的 WAV 数据
winsound.PlaySound(audio_data, winsound.SND_MEMORY)
log_tts_debug("🔊 播放完成")
elif result.reason == speechsdk.ResultReason.Canceled:
cancellation = result.cancellation_details
error_msg = f"Error Code: {cancellation.error_code}, Details: {cancellation.error_details}"
log_tts_debug(f"❌ 合成被取消: {error_msg}")
ui_msg_q.put(("error", f"TTS 合成失败: {error_msg}"))
else:
log_tts_debug(f"❌ 合成失败: {result.reason}")
ui_msg_q.put(("error", f"TTS 合成失败: {result.reason}"))
except Exception as e:
exc_str = traceback.format_exc()
log_tts_debug(f"🔥 异常:\n{exc_str}")
ui_msg_q.put(("error", f"TTS 异常: {str(e)}\n查看 tts_debug.log"))
def translate_task(sent, translate_q, ui_msg_q):
try:
en = translate(sent)
translate_q.put((sent, en))
except Exception as e:
ui_msg_q.put(("warning", f"翻译异常: {e}"))
def audio_capture_thread(push_stream, stop_event, audio_event):
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 16000
p = pyaudio.PyAudio()
try:
stream = p.open(format=FORMAT, channels=CHANNELS, rate=RATE, input=True, frames_per_buffer=CHUNK)
while not stop_event.is_set():
if audio_event.is_set():
try:
data = stream.read(CHUNK, exception_on_overflow=False)
try:
push_stream.write(data)
except Exception:
break
except OSError:
break
else:
try:
stream.read(CHUNK, exception_on_overflow=False)
except OSError:
pass
time.sleep(0.001)
except Exception:
pass
finally:
try:
stream.stop_stream()
stream.close()
except:
pass
p.terminate()
def recognition_thread(cmd_q: queue.Queue, res_q: queue.Queue, audio_event: threading.Event):
while True:
try:
try:
cmd = cmd_q.get_nowait()
if cmd == "stop":
res_q.put(("stopped", None))
return
except queue.Empty:
pass
stream_format = speechsdk.audio.AudioStreamFormat(
samples_per_second=16000,
bits_per_sample=16,
channels=1
)
push_stream = speechsdk.audio.PushAudioInputStream(stream_format=stream_format)
audio_config = speechsdk.audio.AudioConfig(stream=push_stream)
speech_config = speechsdk.SpeechConfig(subscription=SPEECH_KEY, region=REGION)
speech_config.speech_recognition_language = "zh-CN"
speech_config.set_property(speechsdk.PropertyId.SpeechServiceConnection_InitialSilenceTimeoutMs, "1500")
speech_config.set_property(speechsdk.PropertyId.SpeechServiceConnection_EndSilenceTimeoutMs, "500")
recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config)
session_start_time = time.time()
last_activity = time.time()
def recognizing(evt):
nonlocal last_activity
if evt.result.reason == speechsdk.ResultReason.RecognizingSpeech:
res_q.put(("partial", evt.result.text))
last_activity = time.time()
def recognized(evt):
nonlocal last_activity
if evt.result.reason == speechsdk.ResultReason.RecognizedSpeech:
if len(evt.result.text.strip()) >= MIN_SPEECH_LEN:
res_q.put(("final", evt.result.text))
last_activity = time.time()
def canceled(evt):
reason = evt.result.cancellation_reason
error = getattr(evt.result, "cancellation_error_details", "")
res_q.put(("error", f"{reason}: {error}"))
recognizer.recognizing.connect(recognizing)
recognizer.recognized.connect(recognized)
recognizer.canceled.connect(canceled)
stop_audio = threading.Event()
audio_thread = threading.Thread(
target=audio_capture_thread,
args=(push_stream, stop_audio, audio_event),
daemon=True
)
audio_thread.start()
recognizer.start_continuous_recognition()
res_q.put(("status", "识别器运行中..."))
while True:
try:
cmd = cmd_q.get_nowait()
if cmd == "stop":
raise SystemExit
except queue.Empty:
pass
now = time.time()
if (now - last_activity) > SILENCE_TIMEOUT or (now - session_start_time) > MAX_SESSION_DURATION:
res_q.put(("status", "识别器自动重建中..."))
break
time.sleep(0.5)
recognizer.stop_continuous_recognition()
stop_audio.set()
push_stream.close()
time.sleep(0.2)
except SystemExit:
recognizer.stop_continuous_recognition()
stop_audio.set()
push_stream.close()
res_q.put(("stopped", None))
return
except Exception as e:
res_q.put(("error", f"识别异常: {e}, 2秒后重建"))
time.sleep(2)
continue
class SpeechTranslatorApp:
def __init__(self, root):
self.root = root
self.root.title("实时中英翻译(边说边译)")
self.root.geometry("700x600")
self.root.protocol("WM_DELETE_WINDOW", self.on_closing)
if not has_audio_output():
messagebox.showwarning("警告", "未检测到音频输出设备,TTS 朗读功能将不可用。")
# ====== 状态变量 ======
self.running = False
self.status = "准备就绪"
self.history = []
self.processed_sentences = set()
self.zh_buffer = ""
self.last_partial = 0.0
self.is_speaking = False
self.ui_message_queue = queue.Queue()
self.translating_text = ""
self.last_audio_active = time.time()
# ====== 初始化队列和线程引用为 None ======
self.cmd_q = None
self.res_q = None
self.translate_q = None
self.audio_event = None
self.thread = None
# ====== UI 布局 ======
btn_frame = tk.Frame(root)
btn_frame.pack(pady=10)
self.start_btn = tk.Button(btn_frame, text="开始", command=self.start_recognition, bg="green", fg="white", width=10)
self.start_btn.pack(side=tk.LEFT, padx=5)
self.stop_btn = tk.Button(btn_frame, text="停止", command=self.stop_recognition, bg="lightcoral", width=10)
self.stop_btn.pack(side=tk.LEFT, padx=5)
self.status_label = tk.Label(root, text=self.status, relief=tk.SUNKEN, anchor="w")
self.status_label.pack(fill=tk.X, padx=10, pady=5)
tk.Label(root, text="实时识别:").pack(anchor="w", padx=10)
self.recog_text = tk.Label(root, text="等待语音…", bg="white", relief=tk.SUNKEN, anchor="w", height=2)
self.recog_text.pack(fill=tk.X, padx=10, pady=2)
self.translating_label = tk.Label(root, text="", fg="blue")
self.translating_label.pack(anchor="w", padx=10, pady=2)
tk.Label(root, text="翻译记录:").pack(anchor="w", padx=10, pady=(10, 2))
self.log_text = scrolledtext.ScrolledText(root, height=15, state='disabled')
self.log_text.pack(fill=tk.BOTH, expand=True, padx=10, pady=5)
# ====== 启动 UI 更新循环 ======
self.root.after(100, self.main_loop)
def start_recognition(self):
if not self.running:
self.running = True
self.cmd_q = queue.Queue()
self.res_q = queue.Queue()
self.translate_q = queue.Queue()
self.audio_event = threading.Event()
self.audio_event.set()
self.thread = threading.Thread(
target=recognition_thread,
args=(self.cmd_q, self.res_q, self.audio_event),
daemon=True
)
self.thread.start()
self.status = "正在初始化..."
def stop_recognition(self):
if self.running:
self.cmd_q.put("stop")
self.running = False
self.status = "已停止"
# 清理:设为 None,不删除属性
self.cmd_q = None
self.res_q = None
self.translate_q = None
self.thread = None
self.audio_event = None
def on_closing(self):
if self.running:
self.stop_recognition()
self.root.destroy()
def tts_with_callback(self, text):
"""TTS 完成后恢复 is_speaking 状态"""
speak_only(text, self.ui_message_queue)
self.root.after(0, lambda: setattr(self, 'is_speaking', False))
def main_loop(self):
current_time = time.time()
# ====== 处理识别结果队列 ======
if self.res_q is not None:
try:
while True:
typ, data = self.res_q.get_nowait()
if typ == "partial":
self.zh_buffer = data.strip()
self.last_partial = current_time
self.last_audio_active = current_time
elif typ == "final":
self.last_audio_active = current_time
sent = data.strip()
if sent:
norm_key = normalize_text(sent)
if norm_key not in self.processed_sentences:
self.processed_sentences.add(norm_key)
self.zh_buffer = ""
self.last_partial = 0.0
self.translating_text = sent
if self.translate_q is not None:
threading.Thread(
target=translate_task,
args=(sent, self.translate_q, self.ui_message_queue),
daemon=True
).start()
elif typ == "error":
self.status = f"警告: {data}"
elif typ == "status":
self.status = data
elif typ == "stopped":
self.status = "已停止"
self.running = False
# 清理
self.cmd_q = None
self.res_q = None
self.translate_q = None
self.thread = None
self.audio_event = None
except queue.Empty:
pass
# ====== TTS 控制 ======
if self.is_speaking:
if self.audio_event is not None:
self.audio_event.clear()
self.status = "正在朗读,暂停收音..."
else:
if self.audio_event is not None:
self.audio_event.set()
# ====== 超时切句 ======
if self.zh_buffer and current_time - self.last_partial > 1.5:
sent = self.zh_buffer.strip()
if sent:
norm_key = normalize_text(sent)
if norm_key not in self.processed_sentences:
self.processed_sentences.add(norm_key)
self.zh_buffer = ""
self.last_partial = 0.0
self.translating_text = sent
self.last_audio_active = current_time
if self.translate_q is not None:
threading.Thread(
target=translate_task,
args=(sent, self.translate_q, self.ui_message_queue),
daemon=True
).start()
# ====== 处理翻译结果 ======
if self.translate_q is not None:
try:
while True:
sent, en = self.translate_q.get_nowait()
record = {
"time": time.strftime("%H:%M:%S", time.localtime()),
"zh": sent,
"en": en
}
self.history.append(record)
self.translating_text = ""
self.is_speaking = True
threading.Thread(
target=self.tts_with_callback,
args=(en,),
daemon=True
).start()
except queue.Empty:
pass
# ====== 处理 UI 消息(如 TTS 错误)======
try:
while True:
level, msg = self.ui_message_queue.get_nowait()
if level == "error":
messagebox.showerror("错误", msg)
except queue.Empty:
pass
# ====== 更新 UI ======
self.status_label.config(text=self.status)
display_text = self.zh_buffer if self.zh_buffer else "等待语音…"
self.recog_text.config(text=display_text)
if self.translating_text:
self.translating_label.config(text=f"正在翻译:{self.translating_text}")
else:
self.translating_label.config(text="")
# 更新日志
if self.history:
log_lines = []
for item in self.history[-20:]:
log_lines.append(f"[{item['time']}] {item['zh']}")
log_lines.append(f"→ {item['en']}")
log_lines.append("")
self.log_text.config(state='normal')
self.log_text.delete(1.0, tk.END)
self.log_text.insert(tk.END, "\n".join(log_lines))
self.log_text.config(state='disabled')
self.log_text.yview(tk.END)
# 安排下一次循环
self.root.after(100, self.main_loop)
# ====== 启动应用 ======
if __name__ == "__main__":
root = tk.Tk()
app = SpeechTranslatorApp(root)
root.mainloop()使用pyinstaller 打包成窗口应用
pyinstaller --windowed --add-data "icon.png;." --add-binary "D:\develop\miniconda3\envs\AITransformer\lib\site-packages\azure\cognitiveservices\speech\Microsoft.Co
gnitiveServices.Speech.core.dll;azure/cognitiveservices/speech" --add-binary "D:\develop\miniconda3\envs\AITransformer\Library\bin\VCRUNTIME140.dll;." --add-binary "D:\develop\miniconda3\envs\AITransformer\L
ibrary\bin\VCRUNTIME140_1.dll;." --add-binary "D:\develop\miniconda3\envs\AITransformer\Library\bin\MSVCP140.dll;." tkinter_client_1.py
启动测试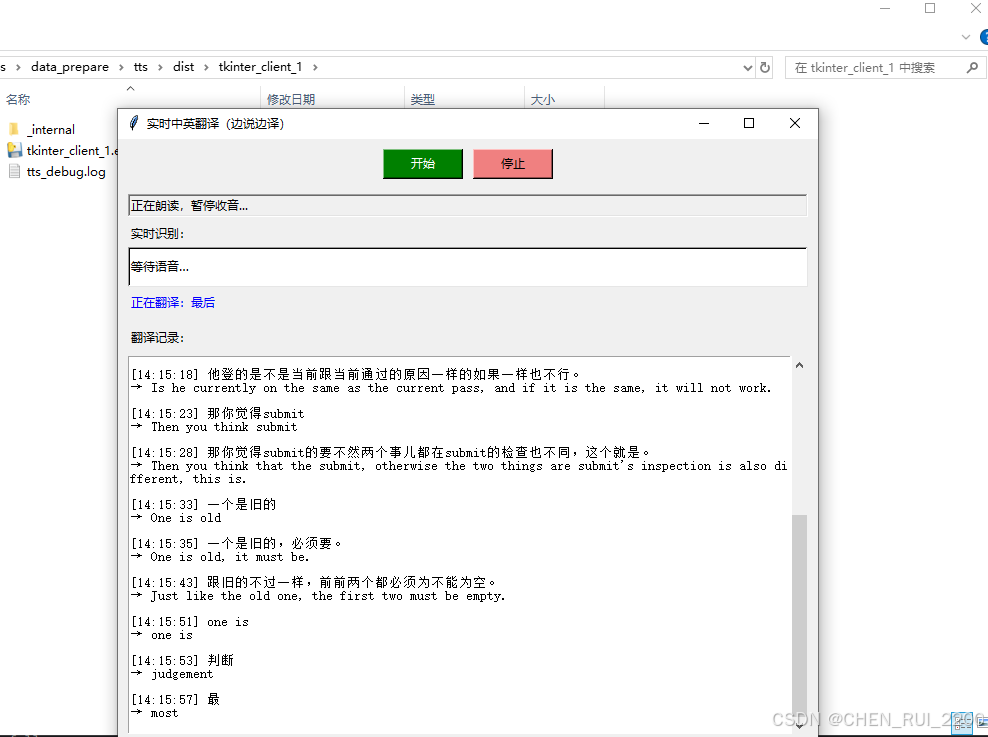

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)