简洁理解 self-attention 和 cross-attention
Attention机制是一种动态加权融合信息的机制,广泛应用于深度学习模型中。Self-Attention和Cross-Attention是两种常见的注意力机制。Self-Attention的输入是同一个序列,通过计算序列内部元素之间的相关性来加权融合信息。Cross-Attention则处理两个不同的序列,通常用于序列间的信息交互,如文本到图像的生成任务。两者的核心步骤相似,包括线性变换、计算注
通俗理解什么是attention?
一句话讲:attention 就是一种信息动态加权融合的机制
self-attention、Multi-head-attention、transformer
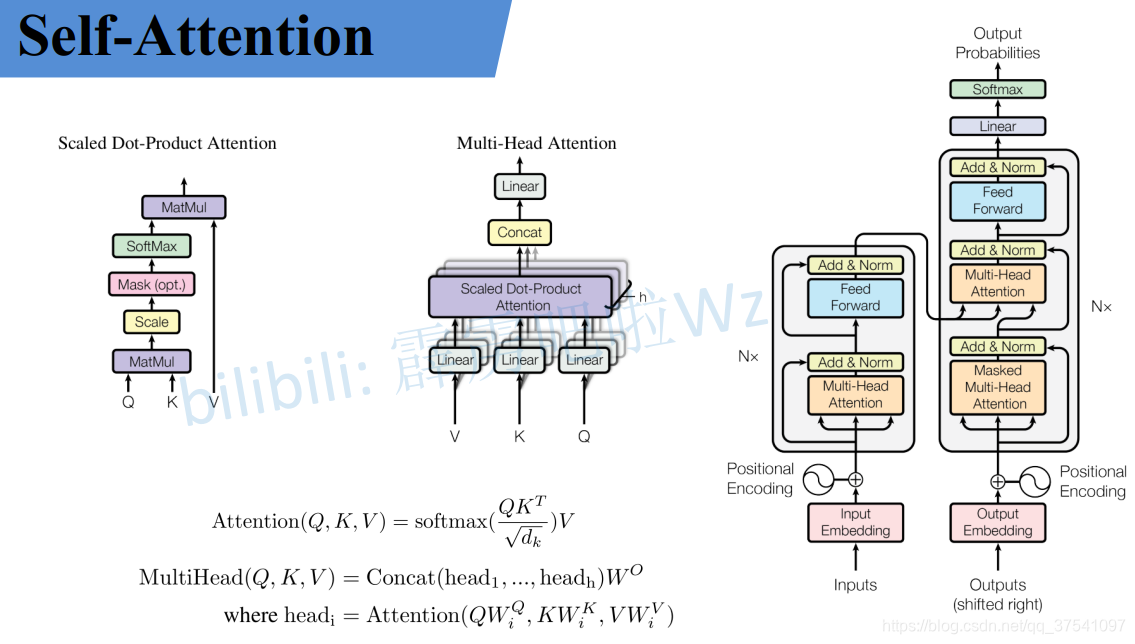
self-attention
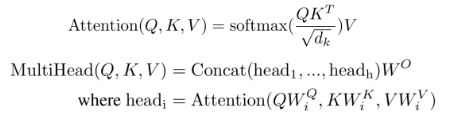
不多讲,博客太多了,以上就是全部精华,整个过程可以分成以下几步:
- 准备好输入向量Q,K,V(self-att的话QKV输入就是同一个)
- 分别输入到各自的线性层,即 linear(Q), linear(K), linear(V);
- 为每个向量计算一个score:score=q·k;
- 为了梯度的稳定,Transformer使用了scorel归一化,即除以√d_k
- 对score施以softmax激活函数;
- softmax点乘Value值 v ,得到的每个输入向量的评分u=softmax(score) * v;
- 加权求和得到最终的输出结果 z=∑u。
cross-attention
Cross Attention,顾名思义,是一种“交叉”的注意力机制。与 Self-Attention 不同,Self-Attention 是让一个序列自己内部的元素相互关注(比如一个句子中的单词互相计算关系),而 Cross Attention 则是让两个不同的序列(或者数据来源)之间建立关注关系。换句话说,Cross Attention 的核心在于:它允许一个序列(称为 Query,查询)去关注另一个序列(称为 Key 和 Value,键和值),从而实现信息的融合。
Cross Attention 的“交叉”发生在两个不同的实体之间。具体来说:
- 一方是 Query 的来源:通常是一个需要补充信息、被修改生成的目标序列。
- 另一方是 Key/Value 的来源:通常是一个提供信息的参考序列。
举几个例子:
1. 机器翻译(Seq2Seq with Attention):
Query:解码器(Decoder)当前生成的单词。
Key/Value:编码器(Encoder)输出的源语言句子。
交叉关系:解码器在生成目标语言时,关注源语言的每个单词,决定当前应该翻译什么。
2. 图像描述生成(Image Captioning):
Query:语言模型生成的当前单词。
Key/Value:图像特征(由 CNN 或 Vision Transformer 提取)。
交叉关系:语言模型在生成描述时,关注图像的不同区域。
3. 多模态任务(Vision-Language Models):
Query:文本输入(比如问题)。
Key/Value:图像或视频特征。
交叉关系:文本去“询问”视觉信息,完成任务如视觉问答(VQA)。
4. 文本生成图像(text to image):
Query: 图像
Key/Value:文本
交叉关系:图像特征去“询问”文本信息,哪里重要/需要修改
cross-attention 在计算上,跟self-attention非常相似,只有一点有差别,就是 self-att 的 QKV 输入是同一个,cross-att 的Q输入是一个,KV输入是另外一个,且输入长度可以不同。
而使用构造cross-attention时,注意 cross-attention 的输出长度是由Q ([batch_size, query_len, d_model])输入决定的,这点来区分谁来作为Q,谁作为 K, V 输入进行信息融合;比如在stable diffusion中,cross-att 后输出还是 隐特征图,那么 Q输入就是隐特征图,如果是图文问答,那么 cross-att 后,输出是文字,那么 图片特征就作为 K, V 进行融合。
简单代码
以下是一个简单的代码,包含了向量维度的变化,非常清晰。
import torch
import torch.nn as nn
import torch.nn.functional as F
class CrossAttention(nn.Module):
def __init__(self, d_model, n_heads):
"""
初始化 Cross Attention 模块
参数:
d_model: 输入的特征维度
n_heads: 多头注意力的头数
"""
super(CrossAttention, self).__init__()
assert d_model % n_heads == 0, "d_model 必须能被 n_heads 整除"
self.d_model = d_model
self.n_heads = n_heads
self.d_k = d_model // n_heads # 每个头的维度
# 定义 Q、K、V 的线性变换层
self.W_q = nn.Linear(d_model, d_model) # Query 的线性变换
self.W_k = nn.Linear(d_model, d_model) # Key 的线性变换
self.W_v = nn.Linear(d_model, d_model) # Value 的线性变换
self.W_o = nn.Linear(d_model, d_model) # 输出线性变换
def forward(self, query, key, value, mask=None):
"""
前向传播
参数:
query: 查询序列,形状 [batch_size, query_len, d_model]
key: 键序列,形状 [batch_size, key_len, d_model]
value: 值序列,形状 [batch_size, key_len, d_model]
mask: 可选的注意力掩码,形状 [batch_size, query_len, key_len]
返回:
输出: 经过 Cross Attention 的结果,形状 [batch_size, query_len, d_model]
"""
batch_size = query.size(0)
# 1. 线性变换生成 Q、K、V
Q = self.W_q(query) # [batch_size, query_len, d_model]
K = self.W_k(key) # [batch_size, key_len, d_model]
V = self.W_v(value) # [batch_size, key_len, d_model]
# 2. 将 Q、K、V 分成多头
Q = Q.view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
K = K.view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
V = V.view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
# Q, K, V 的形状变为 [batch_size, n_heads, seq_len, d_k]
# 3. 计算注意力分数
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5)
# scores 形状: [batch_size, n_heads, query_len, key_len]
# 4. 如果有掩码,应用掩码(比如在解码器中避免关注未来位置)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 5. 应用 Softmax 得到注意力权重
attn_weights = F.softmax(scores, dim=-1)
# 6. 用注意力权重加权 Value
attn_output = torch.matmul(attn_weights, V)
# attn_output 形状: [batch_size, n_heads, query_len, d_k]
# 7. 合并多头结果
attn_output = attn_output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
# 形状变为 [batch_size, query_len, d_model]
# 8. 最后通过线性层输出
output = self.W_o(attn_output)
return output, attn_weights # 返回输出和注意力权重(用于可视化或调试)
# 示例用法
if __name__ == "__main__":
# 设置参数
batch_size = 2
query_len = 3 # 查询序列长度
key_len = 4 # 键/值序列长度
d_model = 64 # 特征维度
n_heads = 8 # 注意力头数
# 创建随机输入数据
query = torch.rand(batch_size, query_len, d_model) # 模拟目标序列
key = torch.rand(batch_size, key_len, d_model) # 模拟源序列
value = torch.rand(batch_size, key_len, d_model) # 模拟源序列
# 初始化 Cross Attention 模块
cross_attn = CrossAttention(d_model=d_model, n_heads=n_heads)
# 前向传播
output, attn_weights = cross_attn(query, key, value)
# 输出结果形状
print("Output shape:", output.shape) # [batch_size, query_len, d_model]
print("Attention weights shape:", attn_weights.shape) # [batch_size, n_heads, query_len, key_len]
在Stable Diffusion的cross-attention机制中:Q (Query):输入来源:U-Net中处理的图像潜在空间特征(latent features)
具体来说,是当前去噪步骤中U-Net处理的中间特征图,通过reshape把 HxW 维度展开成 seq_len,channel_size 当做 embedding维度。
# 获取输入张量 x 的基本信息
batch_size, channels, height, width = x.shape
# 根据 context 的最后一个维度得到 dim
dim = context.shape[-1]
# 将 x reshape 后交换维度,使其形状为 (b, num_tokens, channels)
x_flat = x.view(batch_size, channels, -1).permute(0, 2, 1) # (b, h*w, c)
q = nn.Linear(channels, dim)(x_flat) # (b, h*w, dim)
...其他一样...
K, V (Key, Value):输入来源:文本提示(prompt)通过CLIP文本编码器处理后的特征向量
这种设计允许模型在图像生成过程中"关注"文本描述中的相关信息,从而实现文本到图像的精确引导。U-Net的图像特征(Q)通过注意力机制与文本特征(K,V)交互,使得生成的图像能够符合文本描述的要求。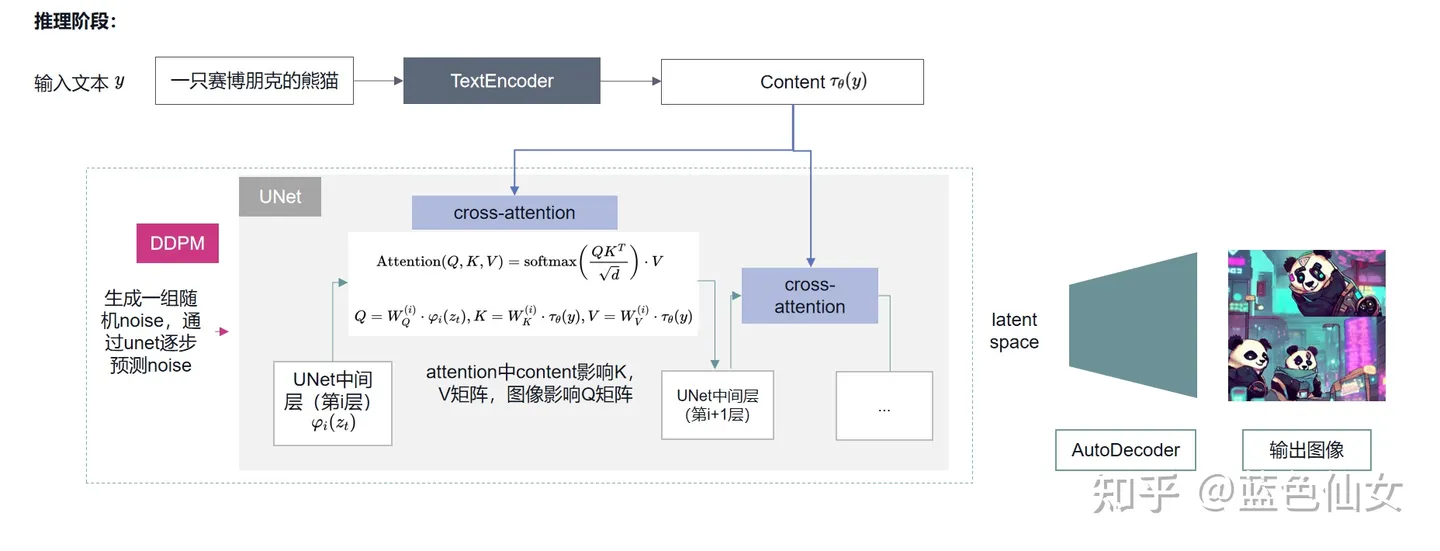
Cross Attention 和 Self Attention 的异同
Cross Attention 和 Self Attention 都是基于注意力机制的,以下是它们的相同点和不同点的分析:
相同点:
机制:两者都使用了点积注意力机制(scaled dot-product attention)来计算注意力权重。
参数:无论是自注意力还是交叉注意力,它们都有查询(Query)、键(Key)和值(Value)的概念。
计算:两者都使用查询和键之间的点积,然后应用softmax函数来计算注意力权重。
输出:在计算完注意力权重后,两者都将这些权重应用于值来得到输出。
可变性:两者都可以通过掩码(masking)来控制某些位置不被其他位置关注。
不同点:
Self Attention: 查询、键和值都来自同一个输入序列。这使得模型能够关注输入序列中的其他部分以产生一个位置的输出。主要目的是捕捉输入序列内部的依赖关系。在Transformer的编码器(Encoder)和解码器(Decoder)的每一层都有自注意力。它允许输入序列的每个部分关注序列中的其他部分。
Cross Attention: 查询来自一个输入序列,而键和值来自另一个输入序列。这在诸如序列到序列模型(如机器翻译、跨模态融合)中很常见,其中一个序列需要“关注”另一个序列。目的是使一个序列能够关注另一个不同的序列。主要出现在Transformer的解码器。它允许解码器关注编码器的输出,这在机器翻译等任务中尤为重要。
总的来说,自注意力和交叉注意力都是基于相同的核心机制,但它们的应用和目的有所不同。自注意力旨在处理单一序列内部的关系,而交叉注意力则旨在处理两个不同序列之间的关系。
参考
- https://blog.csdn.net/qq_37541097/article/details/117691873
- https://blog.csdn.net/shizheng_Li/article/details/146213459 (写的很好)
- https://zhuanlan.zhihu.com/p/648248676

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 27
27 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)