Neurlps2024论文解析|KVQuant Towards 10 Million Context Length LLM Inference with KV Cache Quantization
本文提出了KVQuant,一个针对大型语言模型(LLMs)推理的低精度KV缓存量化方法,旨在支持长达1000万上下文长度的推理。随着LLMs在需要大上下文窗口的应用中的广泛使用,KV缓存激活成为推理过程中内存消耗的主要来源。现有的量化方法在低于4位精度时无法准确表示激活。KVQuant通过四种新方法来解决这一问题:逐通道键量化、预RoPE键量化、非均匀KV缓存量化和逐向量稠密与稀疏量化。
论文标题
KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization KVQuant:面向千万级上下文长度的 LLM 推理的 KV 缓存量化
论文链接
KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization论文下载
论文作者
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W. Mahoney, Yakun Sophia Shao, Kurt Keutzer, Amir Gholami
内容简介
本文提出了KVQuant,一个针对大型语言模型(LLMs)推理的低精度KV缓存量化方法,旨在支持长达1000万上下文长度的推理。随着LLMs在需要大上下文窗口的应用中的广泛使用,KV缓存激活成为推理过程中内存消耗的主要来源。现有的量化方法在低于4位精度时无法准确表示激活。KVQuant通过四种新方法来解决这一问题:逐通道键量化、预RoPE键量化、非均匀KV缓存量化和逐向量稠密与稀疏量化。通过将这些方法应用于LLaMA、Llama-2、Llama-3和Mistral模型,KVQuant在Wikitext-2和C4数据集上实现了小于0.1的困惑度下降,且在单个A100-80GB GPU上支持高达100万的上下文长度,在8个GPU系统上支持高达1000万的上下文长度。此外,KVQuant还通过定制的CUDA内核实现了约1.7倍的加速。
分点关键点
-
KVQuant框架
- KVQuant通过四种创新方法实现低精度KV缓存量化,分别是逐通道键量化、预RoPE键量化、非均匀KV缓存量化和逐向量稠密与稀疏量化。这些方法旨在提高量化精度,减少内存消耗,并支持更长的上下文长度。
-
逐通道键量化
- 逐通道键量化通过在通道维度上共享缩放因子和零点,能够更好地匹配激活的分布,从而提高量化精度。该方法在Wikitext-2上实现了3.82的困惑度提升。
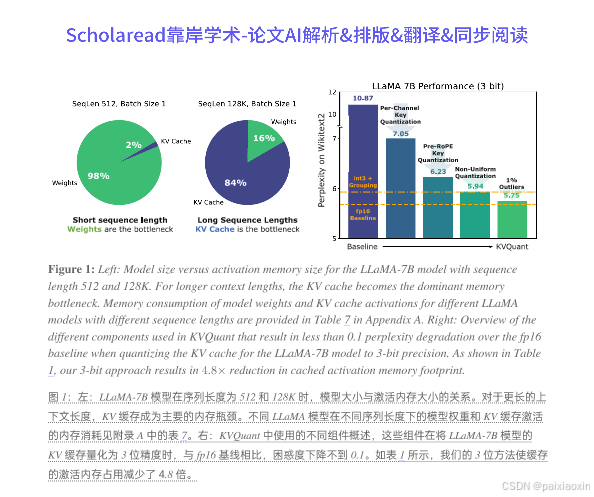
- 逐通道键量化通过在通道维度上共享缩放因子和零点,能够更好地匹配激活的分布,从而提高量化精度。该方法在Wikitext-2上实现了3.82的困惑度提升。
-
预RoPE键量化
- 在应用旋转位置嵌入(RoPE)之前对键进行量化,可以减少RoPE对量化的影响,从而提高量化精度。该方法在Wikitext-2上实现了0.82的困惑度提升。
-
非均匀KV缓存量化
- 通过使用敏感度加权的非均匀量化方法,KVQuant能够更准确地表示键和值的分布,进而提高量化精度。该方法在Wikitext-2上相较于均匀量化方法实现了0.29的困惑度提升。
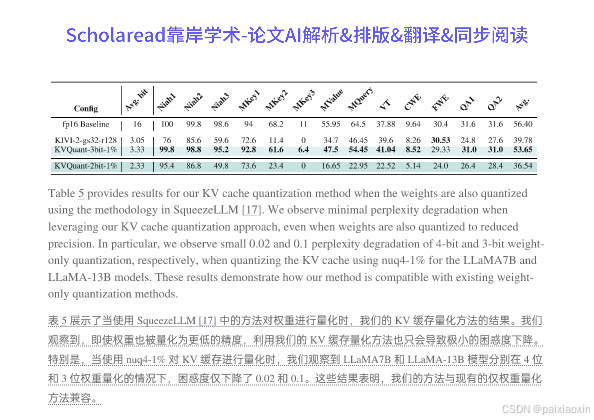
- 通过使用敏感度加权的非均匀量化方法,KVQuant能够更准确地表示键和值的分布,进而提高量化精度。该方法在Wikitext-2上相较于均匀量化方法实现了0.29的困惑度提升。
-
逐向量稠密与稀疏量化
- 该方法通过为每个向量使用不同的异常值阈值,能够更有效地识别和压缩异常值,从而提高量化精度。通过移除1%的异常值,KVQuant在Wikitext-2上实现了额外的0.19困惑度提升。
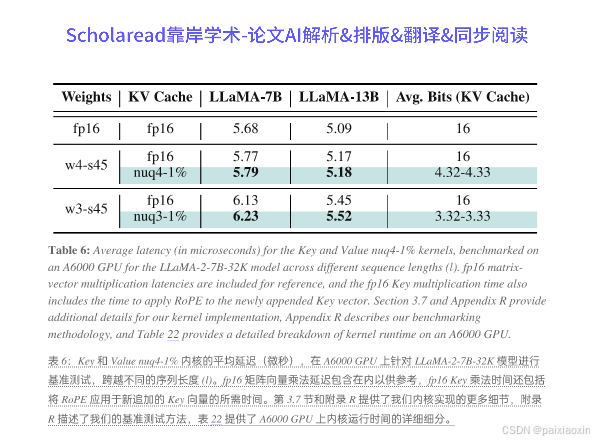
- 该方法通过为每个向量使用不同的异常值阈值,能够更有效地识别和压缩异常值,从而提高量化精度。通过移除1%的异常值,KVQuant在Wikitext-2上实现了额外的0.19困惑度提升。
论文代码
代码链接:https://github.com/SqueezeAILab/KVQuant
中文关键词
- 大型语言模型
- KV缓存
- 量化
- 上下文长度
- CUDA内核
- 非均匀量化
Neurlps2024论文合集:
希望这些论文能帮到你!如果觉得有用,记得点赞关注哦~ 后续还会更新更多论文合集!!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)