VLA 论文精读(十五)Lift3D Foundation Policy: Lifting 2D Large-Scale Pretrained Models for Robust 3D Robotic
这篇论文是2024年发表在arxiv上关于3D DP的论文,主要讲了如何将3D点云嵌入到DP模型中,但这里作者对3D点云信息嵌入有一些巧思,没有直接对整个点云进行编码,而是用2D多模态模型先计算注意力区域,然后将这些mask中的点云进行编码,最后再生成机械臂动作。按照作者的描述这样做可以大幅减少有效空间信息缺失;
这篇论文是2024年发表在arxiv上关于3D DP的论文,主要讲了如何将3D点云嵌入到DP模型中,但这里作者对3D点云信息嵌入有一些巧思,没有直接对整个点云进行编码,而是用2D多模态模型先计算注意力区域,然后将这些mask中的点云进行编码,最后再生成机械臂动作。按照作者的描述这样做可以大幅减少有效空间信息缺失;
【Note】我这里将其归纳到VLA领域,因为后期我会开拓图像与视频领域的DP论文,所以将视觉模型输出动作的论文统一分类到VLA中。
写在最前面
为了方便你的阅读,以下几点的注意事项请务必了解:
- 该系列文章每个字都是我理解后自行翻译并写上去的,可能会存在笔误与理解错误,如果发现了希望读者能够在评论区指正,我会在第一时间修正错误。
- 阅读这个系列需要你有基本的 VLN, LLM, VLM 相关基础知识,有时候我会直接使用英文名词,因为这些词汇实在不容易找到符合语境的翻译。
- 原文可能因为版面限制存在图像表格与段落不同步的问题,为了更方便阅读,我会在博文中重新对图像表格进行排版,并做到引用图表的文字下方就能看到被引用的图表。因此可能会出现一张图片在博客中多处位置重复出现的情况。
- 对于原文中的图像,我会在必要时对图像描述进行翻译并附上我自己的理解,但如果图像描述不值得翻译我也不会强行写上去。
Basic Information
- 论文标题:Lift3D Foundation Policy: Lifting 2D Large-Scale Pretrained Models for Robust 3D Robotic Manipulation
- 原文链接: https://arxiv.org/abs/2411.18623
- 发表时间:2024年12月14日
- 发表平台:arxiv
- 预印版本号:[v2] Sat, 14 Dec 2024 18:38:03 UTC (11,105 KB)
- 作者团队:Yueru Jia, Jiaming Liu, Sixiang Chen, Chenyang Gu, Zhilue Wang, Longzan Luo, Lily Lee, Pengwei Wang, Zhongyuan Wang, Renrui Zhang, Shanghang Zhang
- 院校机构:
- Peking University;
- Beijing Academy of Artificial Intelligence (BAAI);
- The Chinese University of Hong Kong;
- 项目链接: http://lift3d-web.github.io
- GitHub仓库: https://github.com/PKU-HMI-Lab/LIFT3D?tab=readme-ov-file
Abstract
3D 几何信息对于操作任务至关重要,因为机器人需要感知 3D 环境、推理空间关系以及与复杂的空间配置交互。最近的研究越来越多地集中于 3D 特征的显式提取,但仍然面临着诸如缺乏大规模机器人 3D 数据和潜在空间几何丢失等挑战。为了解决这些限制,作者提出了 Lift3D 框架,该框架使用隐式和显式 3D 机器人表示逐步增强 2D 基础模型,以构建鲁棒的 3D 操作策略。具体而言,首先设计一个任务感知的掩码自编码器,该编码器掩盖与任务相关的可供性块并重建深度信息,从而增强 2D 基础模型的隐式 3D 机器人表示。自监督微调之后,引入了一种 2D 模型提升策略,该策略在输入的 3D 点和 2D 模型的位置嵌入之间建立位置映射。基于映射结果,Lift3D 利用二维基础模型直接编码点云数据,依托大规模预训练知识构建清晰的 3D 机器人表征,同时最大限度地减少空间信息丢失。在实验中,Lift3D 在多个仿真基准测试和实际场景中始终优于以往的先进方法。
1. Introduction
基于视觉的操控策略的一个基本目标是理解场景并预测相应的 3D 姿态。一些现有方法利用 2D 图像作为输入,通过强化学习或模仿学习直接预测 3D 末端执行器姿态。虽然这些方法可以有效地处理一系列操控任务,但它们不足以完全理解物理世界中的空间关系和 3D 结构。在机器人操控中,3D 几何信息对于处理复杂任务至关重要,因为机器人必须感知 3D 环境、推理几何关系并与复杂的空间配置进行交互。
最近的研究越来越多地集中在机器人操作任务中3D特征表示的显式提取上,这些方法可以分为两类:
- 直接编码点云数据,要么从头开始训练3D策略模型,要么微调预训练的点云编码器(例如
PointNet和PointNext)。然而,大规模机器人3D数据和基础模型的可用性有限,限制了它们的泛化能力。此外,处理3D或体素特征会产生大量的计算成本,从而阻碍其在实际应用中的可扩展性和实用性; - 对输入进行模态转换,例如将预训练的二维特征提升到三维空间,或将三维点云投影到多视角图像中,作为二维预训练模型的输入。尽管这些模态转换在多个下游操作任务中表现出色,但它们不可避免地会导致空间信息的丢失,从而阻碍机器人理解三维空间关系的能力。
基于上述3D策略面临的挑战,作者提出一个问题:“能否开发一个能够集成大规模预训练知识,同时包含完整三维空间数据输入的三维策略模型。”
为了解决这个问题,作者提出了 Lift3D 框架,该框架提升了基于 Transformer 的二维基础模型(例如 DINOV2 或 CLIP),以逐步构建鲁棒的 3D 操作策略。Lift3D 的关键思想是首先增强隐式 3D 表示,然后对点云数据进行显式编码以进行策略模仿学习。对于隐式 3D 机器人表示,设计了一个任务感知的掩蔽自编码器 (MAE),处理二维图像并以自监督的方式重建三维几何信息,如Fig1. (a)所示,利用来自机器人操作的大规模未标记数据集与多模态模型 CLIP 根据任务文本描述提取图像注意力图。这些注意力图随后被反向投影到二维输入上,以指导 MAE mask策略,重点关注与任务相关的可供性区域。重建掩蔽标记的深度增强了二维基础模型的三维空间感知能力,从而促进后续的点云模仿学习。
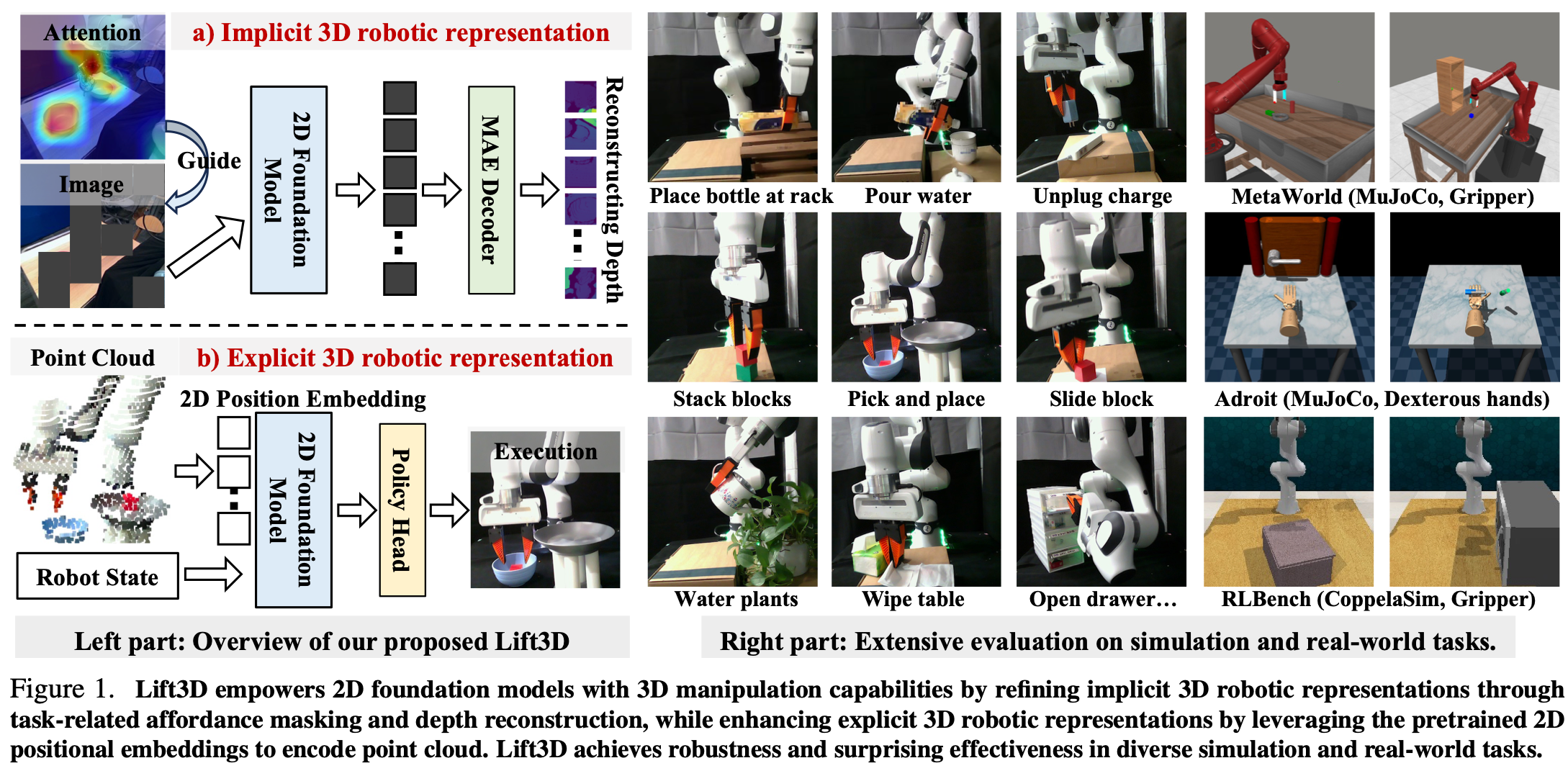
对于显式的 3D 机器人表示,作者提出了一种 2D 模型提升策略,该策略直接利用 2D 基础模型对 3D 点云数据进行编码,如Fig.1 b所示。具体而言,受虚拟相机的启发,首先将点云数据投影到多个虚拟平面上,但投影过程并非旨在构建策略模型的输入,而是在输入的 3D 点和每个虚拟平面的预训练 2D 位置嵌入 (PE) 之间建立位置对应关系。在这种位置映射的指导下,2D 基础模型可以使用其原始 PE 来编码点云数据,从而使模型能够基于其大规模预训练知识提取 3D 特征。与以前的方法不同,Lift3D 消除了模仿学习过程中的模态变换,最大限度地减少了机器人空间信息的丢失,同时通过直接利用 2D 基础模型前向传播来降低计算成本。通过两阶段训练过程,Lift3D 通过系统地改进隐式和显式 3D 机器人表示,增强了 2D 基础模型的强大 3D 机器人操作能力。
为了全面评估提出的 Lift3D,作者在三个仿真基准和几个真实场景中开展了大量实验,包括 30 多种不同的夹持器和灵巧手操作任务,如Fig.1 所示。比较了各种基线方法,例如机器人 2D 表示方法、3D 表示方法、3D 模仿学习策略。即使在使用最简单的 MLP 策略头和单视角点云时,Lift3D 的性能也始终优于其他方法,证明了模型的操作能力及其对机器人 3D 空间感知的理解的稳健性。例如,在 Meta-World 和 Adroit 基准测试中,Lift3D 的平均成功率分别比之前最先进的 3D 策略方法提高了 18.2% 和 21.3%。作者还探索了模型在多个复杂任务中的可扩展性,逐渐增加了 2D 基础模型的参数。在真机实验中,Lift3D 只需对每个任务进行 30 次训练就能学习新的操作技能。为了评估 Lift3D 的泛化能力,将训练集中不同的操作实例、背景场景、光照条件融入到实际测试过程中。Lift3D 表现出很强的泛化能力,有效地利用了 2D 基础模型的大规模预训练知识和全面的 3D 机器人表示。总之,作者的贡献如下:
- 提出了
Lift3D,它通过系统地改进隐式和显式 3D 机器人表示,将 2D 基础模型提升到构建 3D 操作策略; - 对于隐式 3D 机器人表征,设计了一个任务感知的 MAE 屏蔽与任务相关的可供性区域并重建深度几何信息,从而增强了 2D 基础模型的 3D 空间感知能力;
- 对于明确的 3D 机器人表示,提出了一种 2D 模型提升策略,该策略利用 2D 基础模型的预训练 PE 对 3D 点云数据进行编码,以进行操作模仿学习;
2. Related work
Robotic Representation Learning
近年来,预训练视觉表征领域取得了实质性进展,主要集中于自监督学习范式,如对比学习、自蒸馏和掩蔽自编码器 (MAE)。此外,多模态对齐方法利用大规模成对VL数据来学习更多语义感知的表征。基于此,更多研究致力于增强机器人领域的 2D 表征。R3M 利用对比学习从不同的人类视频数据中学习通用的具身表征;Vip 为从未见过的机器人任务生成密集、平滑的奖励函数;MVP、VC-1和Voltron深入研究了MAE策略在机器人预训练中的有效性。还有研究考虑了多帧对当前状态的影响。然而,2D表示通常难以捕捉复杂机器人任务所需的空间上下文,这促使其他预训练工作探索3D机器人表示。MV-MWM、3D-MVP和SPA利用多视图MAE来学习3D视觉表示。SUGAR和Point Cloud Matters引入了基于点云的3D表示,表明这些观察结果通常可以提高策略性能和泛化能力。DPR利用深度信息作为预训练的辅助知识。与以前的机器人预训练方法不同,Lift3D充分利用了现有的2D基础模型,通过使用隐式3D机器人表示来增强它们。该方法首次尝试mask与任务相关可供性区域并重建深度信息,不仅提高了 3D 空间感知能力,而且促进了后续的点云模仿学习。
Robotic Manipulation
传统的机器人操作通常依赖于基于状态的强化学习。相比之下,最近的方法利用视觉观察作为输入来进行预测。受多模态大型语言模型成功的启发,一些VLA被设计用于任务规划和操作。然而,明确的 3D 表示对于复杂的机器人任务至关重要,它对各种变化具有很强的鲁棒性。另一类工作侧重于直接编码 3D 信息来预测末端执行器的姿态,Anygrasp 使用点云数据在大规模数据集上学习抓握姿势;还有研究将 3D 点云投影到多视角图像中,以输入到大规模 2D 预训练模型中;或者将预训练的 2D 特征提升到 3D 空间;PolarNet 和 M2T2 直接利用从 RGB-D 数据重建的点云,通过编码器-trasnformer 组合对其进行处理以进行动作预测;C2F-ARM 和 PerAct 具有 3D backbone 的体素化点云进行动作推理;Act3D 和 ChainedDiffuser 采用不同的方法,将场景表示为多尺度 3D 特征;3D DP Actor和 3D DP 利用扩散模型在 3D 空间中生成精确的动作。与之前的 3D 策略不同,Lift3D 使用预训练的 2D 基础模型及其位置嵌入直接对点云数据进行编码,从而最大限度地减少空间信息损失并增强泛化能力。
3. Lift3D Method
第 3.1 节介绍 Lift3D 框架的问题描述;3.2 节和第 3.3 节介绍任务感知 MAE 和 2D 模型提升策略的技术细节,它们分别增强了隐式和显式的 3D 机器人表征。
3.1 Problem Statement
For implicit 3D robotic representation
对于隐式 3D 机器人表示,借鉴先前的 MAE 方法,首先将掩蔽图像 I ∈ R W × H × 3 I\in R^{W\times H\times 3} I∈RW×H×3 输入到二维基础模型 2 D e 2D_{e} 2De 中,然后将输出特征输入解码器 2 D d 2D_{d} 2Dd 进行深度重建 D = 2 D d ( 2 D e ( I ) ) D=2D_{d}(2D_{e}(I)) D=2Dd(2De(I)),其中 D ∈ R W × H × 1 D\in R^{W\times H\times 1} D∈RW×H×1。此过程增强了 2 D e 2D_{e} 2De 模型的三维空间感知能力,并有助于后续的三维模仿学习。
For explicit 3D robotic representation
对于明确的三维机器人表征,直接利用二维基础模型 2 D e 2D_{e} 2De 来编码三维点云数据 P ∈ R N × 6 P\in R^{N\times6} P∈RN×6 和机器人状态 R S R_{S} RS。然后,使用一个简单的策略头 π \pi π 来预测动作 a = π ( 2 D e ( P , R S ) ) a=\pi(2D_{e}(P,R_{S})) a=π(2De(P,RS))。借鉴前人的操作研究,采用 7 自由度动作来表达机械臂的末端执行器姿态,其中包括 3 自由度平移、3 自由度旋转、1 自由度夹持器状态(张开或闭合)。
3.2 Task-aware Masked Autoencoder
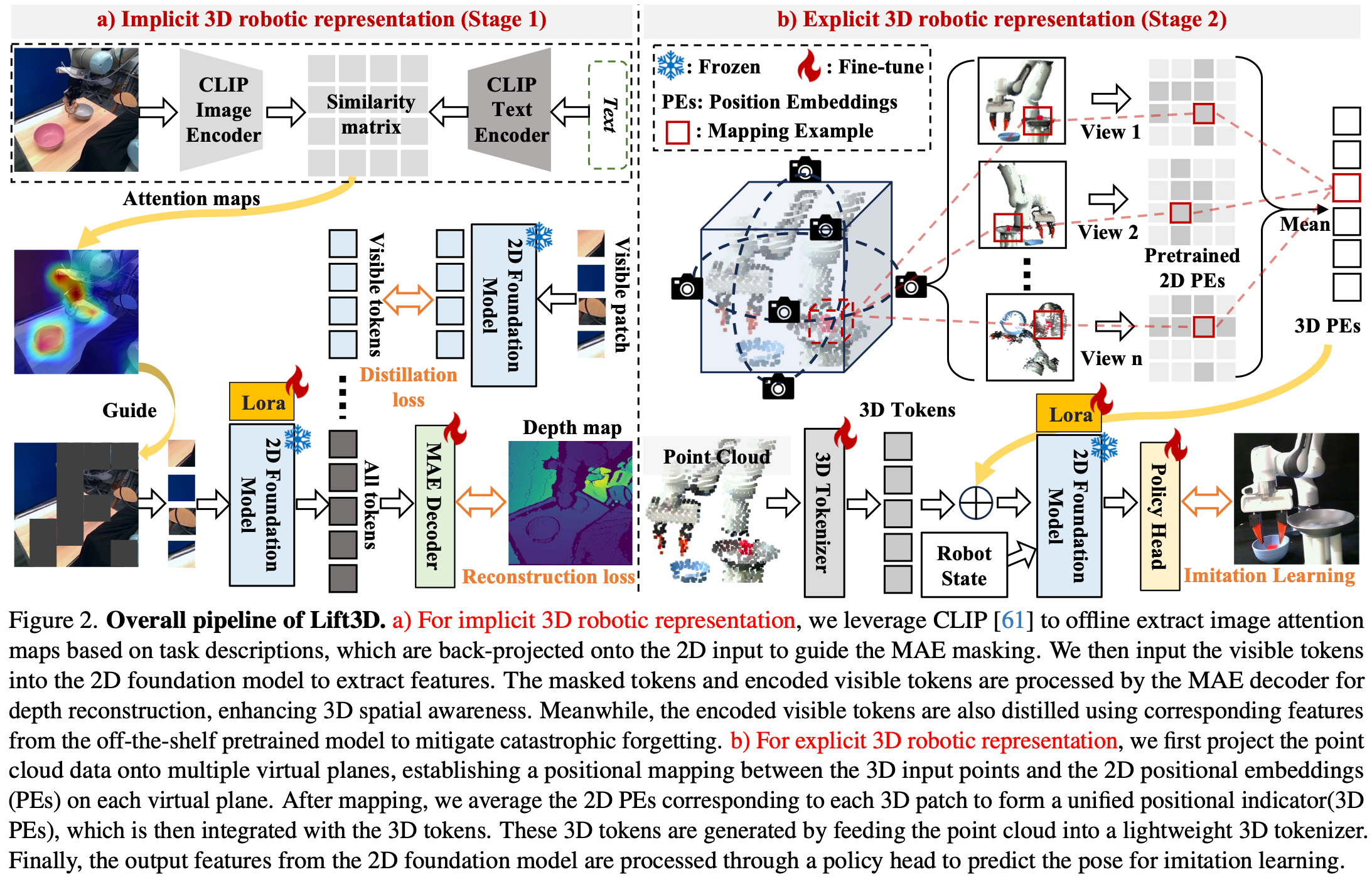
多项研究表明,2D 基础模型在各种下游机器人任务中展现出强大的表示和泛化能力。在此基础上,Lift3D 首先增强了 2D 基础模型中隐含的 3D 机器人表示。现有的机器人 MAE 重建方法采用了激进的掩蔽策略,即随机掩蔽大部分输入图像块。然而,被mask的块可能大多包含不相关的背景信息,阻碍了前景物体表示的有效学习。与以前的方法不同,Lift3D 旨在掩蔽与任务相关的可供性块并重建深度几何信息,从而增强 2D 基础模型的 3D 空间感知能力。具体而言,利用来自机器人操作的大规模数据集来构建我们的 MAE 训练数据集,其中包括从视频中随机采样的 100 万个训练样本,由成对的图像和深度数据组成。重建数据集的更多细节见Appendix. A。如Fig.2 (a)所示,获取数据后,使用多模态模型CLIP 根据任务特定的文本描述生成图像注意力图。例如,Fig.2 中用于提取注意力图的文本提示是“机械臂拿起红色碗并将其放入灰色碗中”。然后,对这些注意力图进行双线性调整大小并反投影到输入图像上,以指导 MAE 掩蔽策略。为了区分与任务相关的可供性标记和背景标记,我们应用阈值(即 θ = 0.5 \theta= 0.5 θ=0.5)来过滤所有标记的注意力值。请注意,每个标记的注意力值是通过对其像素级值取平均值来计算的。与以前的方法中使用的掩蔽率一致,我们还随机掩蔽背景标记以达到所需比例(即 r = 75.0 r = 75.0 r=75.0)。
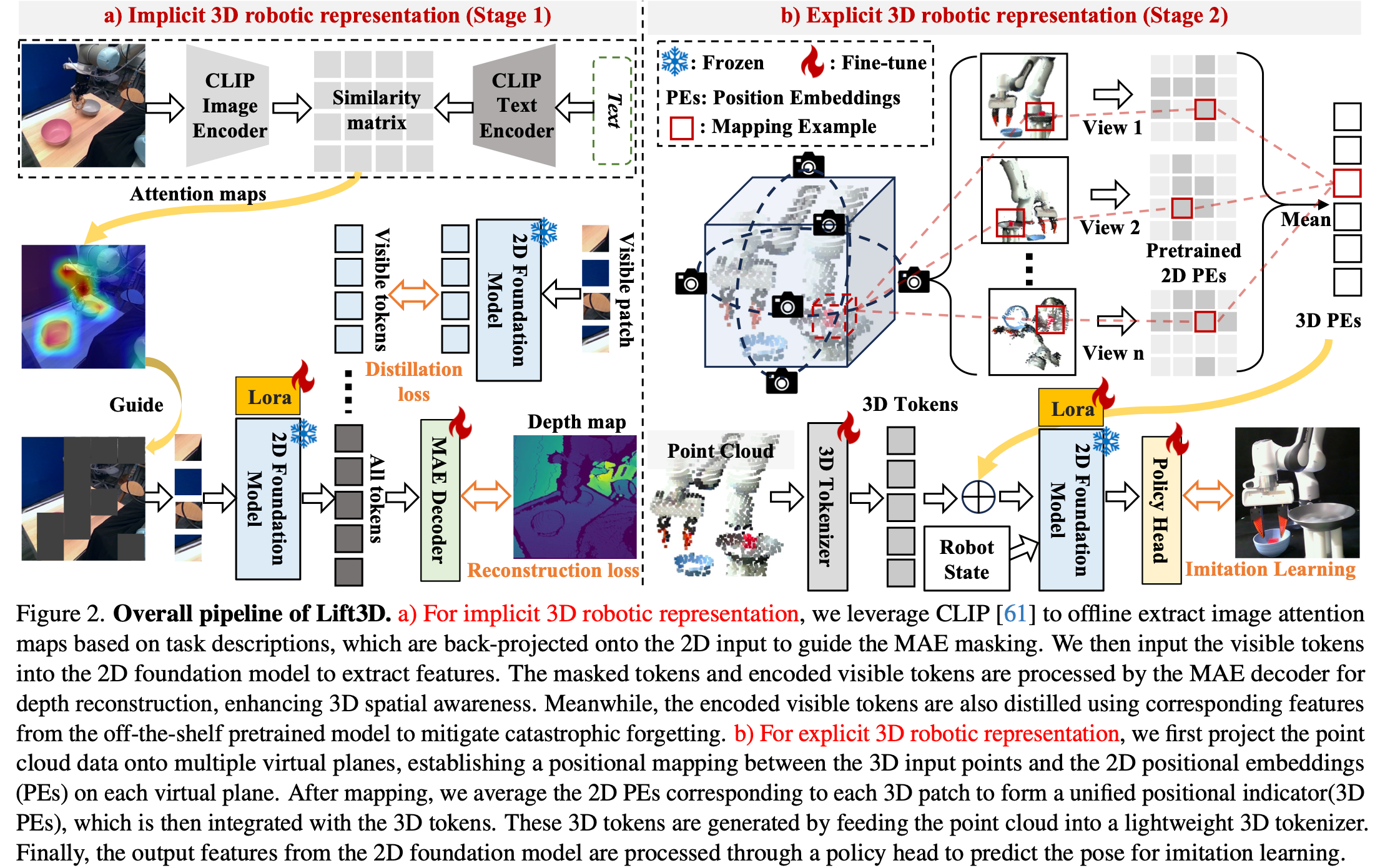
可见的( x v i s x_{vis} xvis)token 被输入到二维基础模型中,然后与masked token( x m a s k x_{mask} xmask)拼接起来,送往解码器进行重建。重建目标在蒙版图像建模中起着至关重要的作用,直接影响特征表示的学习。以前的机器人MAE方法通常使用低级RGB信息作为重建目标。为了增强二维基础模型的三维空间感知,作者重建了与任务相关的可供性块和随机选择的背景块的深度信息( D t a r g e t D_{target} Dtarget)。最后,为了保留基础模型的固有功能,引入了一个蒸馏损失,用于限制模型的可见token输出与现成的预训练模型( 2 D e 2D_{e} 2De)中相应特征之间的距离。如Fig.2 (a)所示,在第 1 阶段的训练过程中,使用重建和蒸馏损失对注入的适配器[29]和解码器进行微调,其公式如下:
L i m p l i c i t = ∥ 2 D e ( x v i s ) − 2 D e p r e ( x v i s ) ∥ 1 + ∥ 2 D d ( 2 D e ( x v i s ) ∣ ∣ x m a s k ) − D t a r g e t ∥ 1 \begin{equation} L_{implicit}= \|2D_{e}(x_{vis})-2D_{e}^{pre}(x_{vis})\|_{1} + \|2D_{d}(2D_{e}(x_{vis})|| x_{mask})-D_{target}\|_{1} \end{equation} Limplicit=∥2De(xvis)−2Depre(xvis)∥1+∥2Dd(2De(xvis)∣∣xmask)−Dtarget∥1
3.2 Model-lifting Strategy
在给 2D 基础模型隐式 3D 机器人感知能力后,作者引入了一种提升策略,使 2D 模型能够显式理解点云数据。近期的研究,无论是将 3D 点云投影到多视图图像还是将 2D 特征提升到 3D 空间,都面临着因模态变换而丢失空间信息的挑战。因此,高效编码 3D 数据一直是 3D 机器人领域的研究重点。对于基于 Transformer 的 2D 模型,位置嵌入 (PE) 起着重要作用,因为它们为注意机制中的输入 token 提供位置指示。然而,直接创建新的 3D PE 来编码 3D token 可能会在预训练的 2D 基础模型和新添加的 3D PE 之间引入语义差异,从而可能导致大规模预训练知识的丢失。
因此,作者 将3D token投影到多个虚拟平面上,投影过程并非旨在构建模型的输入,而是用于在输入的3D点和每个虚拟平面的预训练2D PE之间建立位置对应关系。然后,这些2D PE会直接用于编码3D token。具体来说,如Fig.2 (b)所示将原始点云转换为高维空间(即 B × 128 × 768 B\times128\times768 B×128×768),并通过一个轻量级的3D tokenizer获得 k ( 128 ) k(128) k(128)个3D token。 3D 标记器由用于降低点数的最远点采样、局部聚合 k 最近邻算法、特征编码的可学习线性层组成。使用 { C 3 D i } i = 1 k \{C_{3D}^{i}\}^{k}_{i=1} {C3Di}i=1k 表示每个 3D 标记的 3D 坐标。随后将每个 3D 坐标投影到 n n n 个虚拟平面上,得到相应的 3D-to-2D 坐标 { C 2 D i j } j = 1 n \{C^{ij}_{2D}\}^{n}_{j=1} {C2Dij}j=1n。这里采用 6 个面的立方体投影方法,可以有效地捕获空间信息。 n n n 个虚拟平面对应 n n n 个原始 2D PE,使用 3D-to-2D 坐标将每个 3D 标记分配给 n n n 个原始 2D PE,表示为 { P E 2 D ( C 2 D i j ) } j = 1 n \{PE_{2D}(C^{ij}_{2D})\}^{n}_{j=1} {PE2D(C2Dij)}j=1n。
将每个 3D token 与 n n n 个 2D PE 对齐后,简单地对它们取平均值,以创建一个统一的位置指示器,记为 P E3D ,其公式如下:
P E 3 D = 1 n ∑ j = 1 n ( P E 2 D ( C 2 D i j ) ) \begin{equation} PE_{3D}=\frac{1}{n}\sum^{n}_{j=1}(PE_{2D}(C^{ij}_{2D})) \end{equation} PE3D=n1j=1∑n(PE2D(C2Dij))
将 P E 3 D PE_{3D} PE3D 与 3D 标记结合起来,并将它们输入到 2D 基础模型中。利用 n n n 个组合的原始 2D PEs 来编码 3D 标记,提供了 2D 空间内的多样化位置关系并减轻了空间信息丢失。来自 2D 基础模型的输出特征 B × 128 × 768 B\times128\times768 B×128×768 通过一个简单的策略头进行处理,以预测模仿学习的姿势。一个三层多层感知器 (MLP) 来构建策略头。Lift3D 编码器可以轻松适配不同的解码器或策略头;这里使用 MLP 头进行简单的验证,最终监督损失公式为:
L e x p l i c i t = M S E ( T p r e d , T g t ) + ( 1 − R p r e d ⋅ R g t ∥ R p r e d ∥ ∥ R g t ∥ ) + B C E ( G p r e d , G g t ) L_{explicit}=MSE(T_{pred},T_{gt})+\left(1-\frac{R_{pred}\cdot R_{gt}}{\|R_{pred}\| \|R_{gt}\|}\right) + BCE(G_{pred}, G_{gt}) Lexplicit=MSE(Tpred,Tgt)+(1−∥Rpred∥∥Rgt∥Rpred⋅Rgt)+BCE(Gpred,Ggt)
其中 T T T、 R R R、 G G G 分别代表 7 自由度末端执行器姿态下的平移、旋转、夹持状态。如Fig.2 (b)所示,在第 2 阶段模仿学习中,冻结 2D 基础模型的参数仅更新 3D 分词器、注入适配器、策略头。Lift3D 也可以在不注入适配器的情况下运行,但这会导致操作性能略有下降。其他验证见Appendix. B4。
4. Experiments
在第 4.1 节和 4.2 节中分别通过仿真与真机实验来评估 Lift3D 模型的可操作性;第 4.3 节的消融研究验证了每个组件的有效性;第 4.4 节考察了 Lift3D 的泛化能力,并在不同的可操作实例、背景场景、光照条件下测试了该模型;在第 4.5 节中,通过逐步增加二维基础模型的参数来探索模型的可扩展性。
4.1 Simulation Experiment
Benchmarks
从三个广泛使用的操作仿真基准测试中选择了 30 多个任务:MuJoCo 模拟器中的 MetaWorld 和 Adroit、CoppeliaSim 模拟器中的 RLBench。点云数据来自使用相机内部函数和外部函数的单视图 RGBD 数据。对于 MetaWorld(一个带有 Sawyer 机械臂和双指夹持器的桌面环境)选择 15 个不同难度级别的任务。这些任务从两个角落摄像机视角拍摄,分类如下:简单任务包括按下按钮、打开抽屉、伸手、拉动手柄、从侧面拔出挂钩、拉动杠杆、转动拨盘;中等任务包括锤击、扫入、拾取箱子、推墙、关上箱子;困难和极难任务包括组装、手动插入、放置货架。Adroit 专注于灵巧手部操作,包含三个任务:锤子、门、笔。RLBench 使用 Franka Panda 机器人和前视摄像头。由于篇幅限制,RLBench 的结果和详细信息在Appendix. B1 中提供。
Data collection
Meta-World 使用脚本策略,收集了 25 个演示,每个演示包含 200 个步骤。对于 Adroit 任务,轨迹由使用强化学习算法训练的智能体获取。具体来说,DAPG 用于门和锤子任务,而 VRL3 用于笔任务。采集了 100 个演示,每个演示包含 100 个步骤。RLBench 中的演示通过预定义的路径点和 Open Motion Planning Library 收集,共收集了 100 个情节,每个情节包含多个关键帧。
Baselines
Lift3D 的创新之处在于系统地增强了隐式和显式 3D 机器人表示。为了评估其有效性,将 Lift3D 与以下三类中的 9 种方法进行了比较:
- 2D 机器人表示方法:选择2D 基础模型
CLIP (ViT-base),包括R3M和VC-1,两者都是 2D 机器人预训练方法; - 3D 表示方法:结合了基础 3D 模型,包括
PointNet、PointNet++、PointNext。此外,还研究了SPA,这是之前的 SOTA 3D 机器人预训练方法。所有机器人表示方法都使用与Lift3D相同的三层策略头和训练损失; - 3D 策略:在
MetaWorld和Adroit上,Lift3D与之前的 SOTA 3D 扩散策略(DP3)进行比较,在RLBench上与RVT-2进行了比较;
Training and Evaluation Details
为了公平比较,所有基线均在相同配置下训练和评估,而 3D 策略方法则遵循其原始设置。2D 和 3D 视觉输入分别由 224 × 224 224\times224 224×224 RGB 图像和包含 1,024 个点的单视角点云组成。机器人状态包括末端执行器姿态、关节位置、速度,这些与视觉特征连接在一起。使用 CLIP 和 DINOV2(ViT-base) 作为的 2D 基础模型。根据先前的研究,采用 Adam 优化器,参数为 ( β 1 , β 2 ) = ( 0.9 , 0.999 ) (\beta_{1},\beta_{2})= (0.9, 0.999) (β1,β2)=(0.9,0.999),学习率为 1 e − 3 1e-3 1e−3。MetaWorld 使用恒定学习率,而 Adroit 使用 0.1 预热因子的余弦退火调度程序。每种方法训练 100 个 epoch,每 10 个 epoch 进行 25 次 rollout。对于 MetaWorld 进一步对两个摄像机视角的得分进行平均。
Quantitative Results
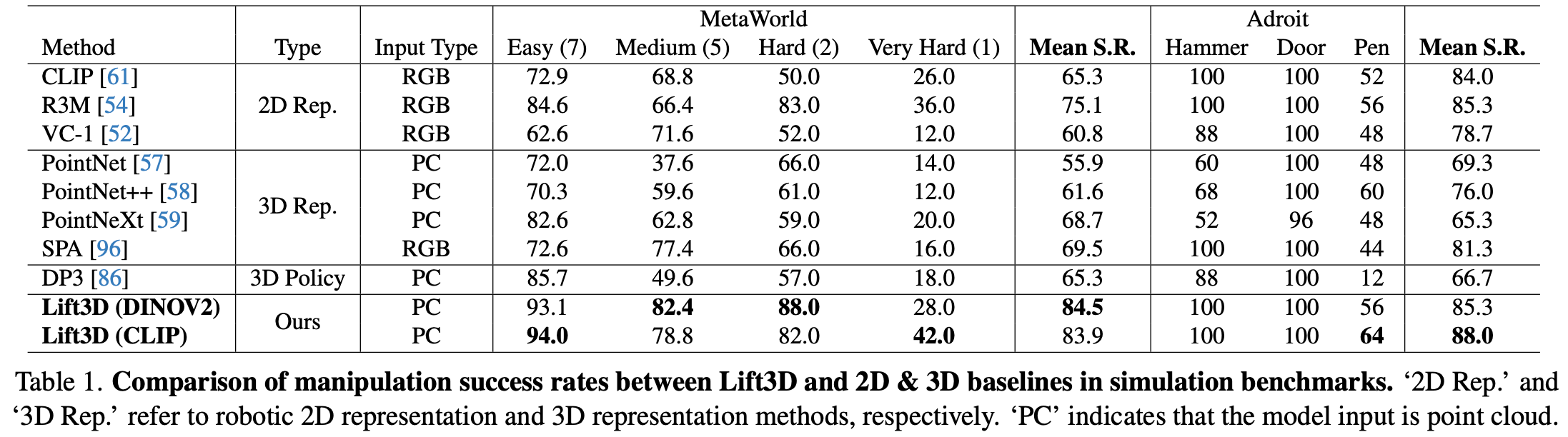
Table.1中 Lift3D (CLIP) 在 MetaWorld 基准测试中的平均成功率为 83.9,其中中等任务准确率为 78.8,困难任务准确率为 82.0。与其他机器人表示方法相比,Lift3D 的平均成功率比表现最好的 2D 方法提高了 8.8,比表现最好的 3D 方法提高了 14.4;与之前的 SOTA 3D 策略 (DP3) 相比,Lift3D 的准确率提高了 18.6。这些结果表明,Lift3D 有效地增强了具有鲁棒操作能力的 2D 基础模型,通过利用大规模预训练知识,可以更深入地理解机器人 3D 场景;与之前的机器人表示和策略方法相比,Lift3D 在灵巧手任务上也取得了卓越的性能。需要注意的是,灵巧手的自由度在不同任务中有所不同,锤子、门、笔任务的自由度分别为 26、28 和 24。结果表明,由于强大的 3D 机器人表征,对于更复杂的灵巧手操作任务也同样有效。Lift3D(DINOV2) 也展现出了良好的结果,证明了该方法对其他 2D 基础模型的实用性。详细得分见Appendix. B.3。
4.2 Real-World Experiment
Dataset collection
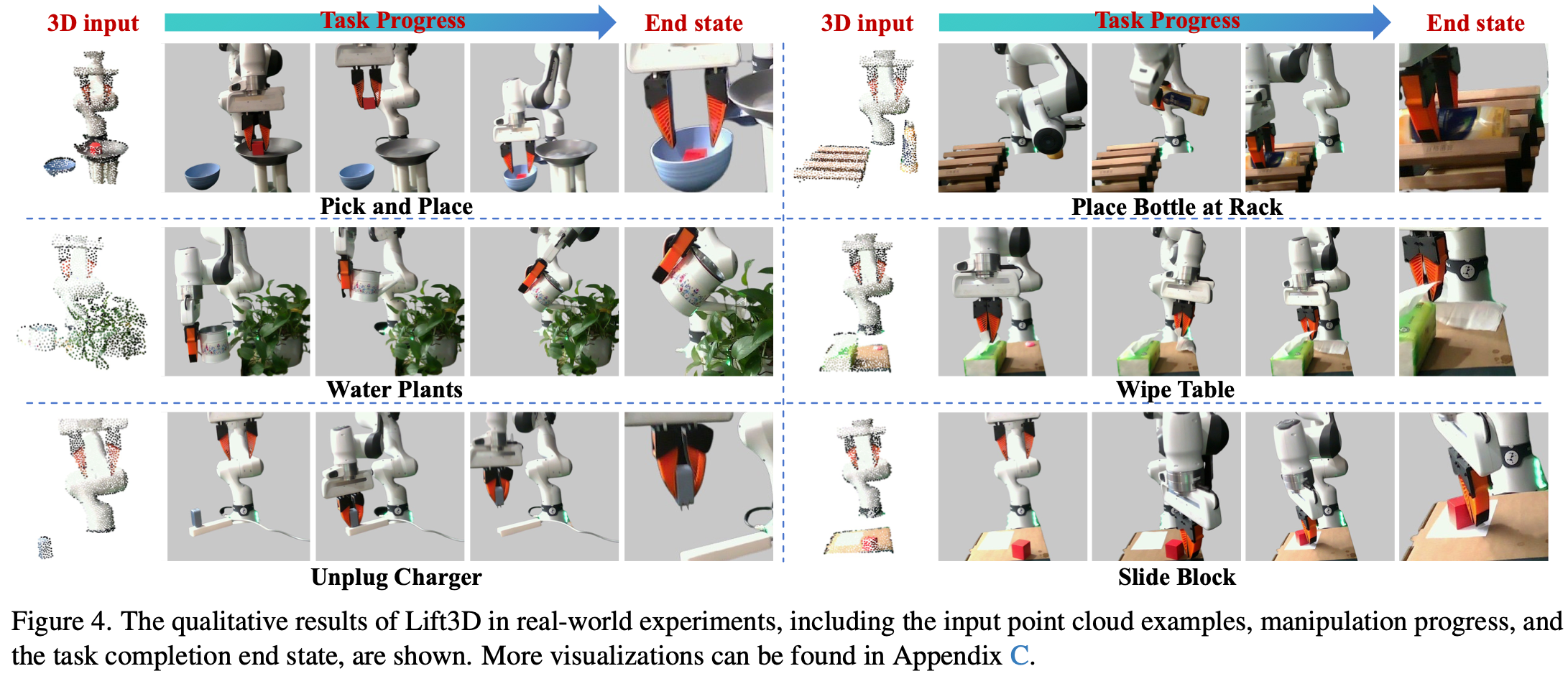
在真机实验中使用 Franka Research 3 臂进行实验,并使用英特尔 RealSense L515 RGBD 摄像头捕捉静态正面视图。执行十项任务:1)将瓶子放在架子上,2)倒水,3)拔下充电器,4)堆积木,5)取放,6)滑块,7)给植物浇水,8)擦桌子,9)打开抽屉,10)关闭抽屉。这些任务涉及各种类型的交互对象和操作动作。对于每个任务,在不同的空间位置采集 40 个演示,以 30 fps 记录轨迹。选择 30 个情节并提取关键帧来构建每个任务的训练集。输入点云数据和图像的示例显示在Fig.4 中。更多的真机实验细节在Appendix. A展示。
Training and Evaluation Details
与仿真实验相同,针对每个任务从头开始训练每种方法。在训练过程中,世界坐标系中的点云和动作姿态分别用作输入和监督。为了进行评估,使用最后一个epoch的模型,并在不同的空间位置对其进行20次评估。
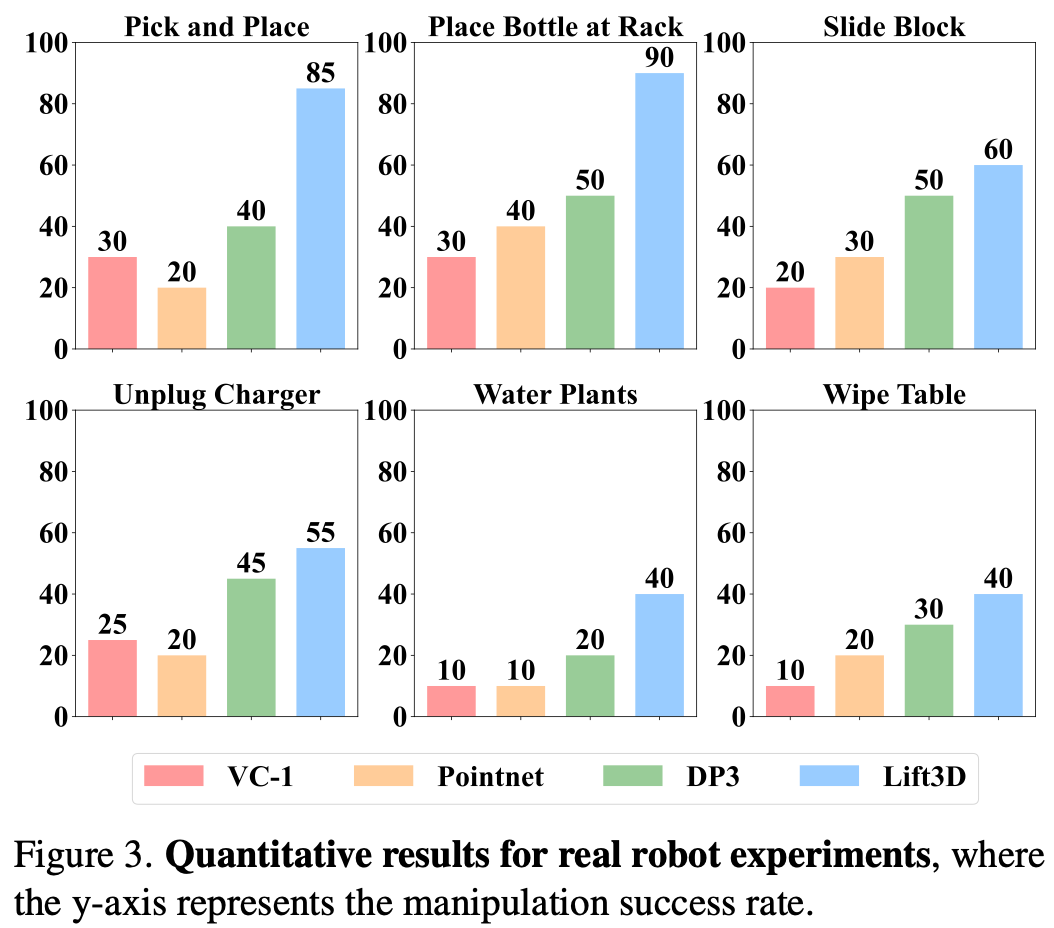
Quantitative Results
如Fig.3 所示将 Lift3D (CLIP) 与 DP3、VC-1 和 Pointnet 进行了比较。结果表明,Lift3D 在多个任务中表现始终良好。具体来说,在需要精确 3D 位置和旋转预测的将瓶子放置在架子上的任务中,Lift3D 的成功率达到了 90%。结果表明,Lift3D 可以有效地理解 3D 空间场景并在现实世界中做出准确的姿态预测。对于复杂任务(擦拭桌子),由于需要操纵可变形组织,所有方法都面临精度限制,Lift3D 仍然达到了 40% 的成功率。由于篇幅限制其他真实世界实验放在Appendix. B2中。
Qualitative Results
如Fig.4 所示,可视化了六个真实任务的操控过程。作者的模型能够准确预测连续的 7 自由度末端执行器位姿,从而允许任务沿着轨迹完成。例如,在浇灌植物的任务中,Lift3D 首先准确地抓住喷壶的手柄。然后,它平稳地将喷壶抬起并放置在植物上方。最后,逐渐旋转夹具以控制“水”的流量。演示视频在补充材料中提供,故障案例分析在Appendix C.2 中。
4.3 Ablation Study
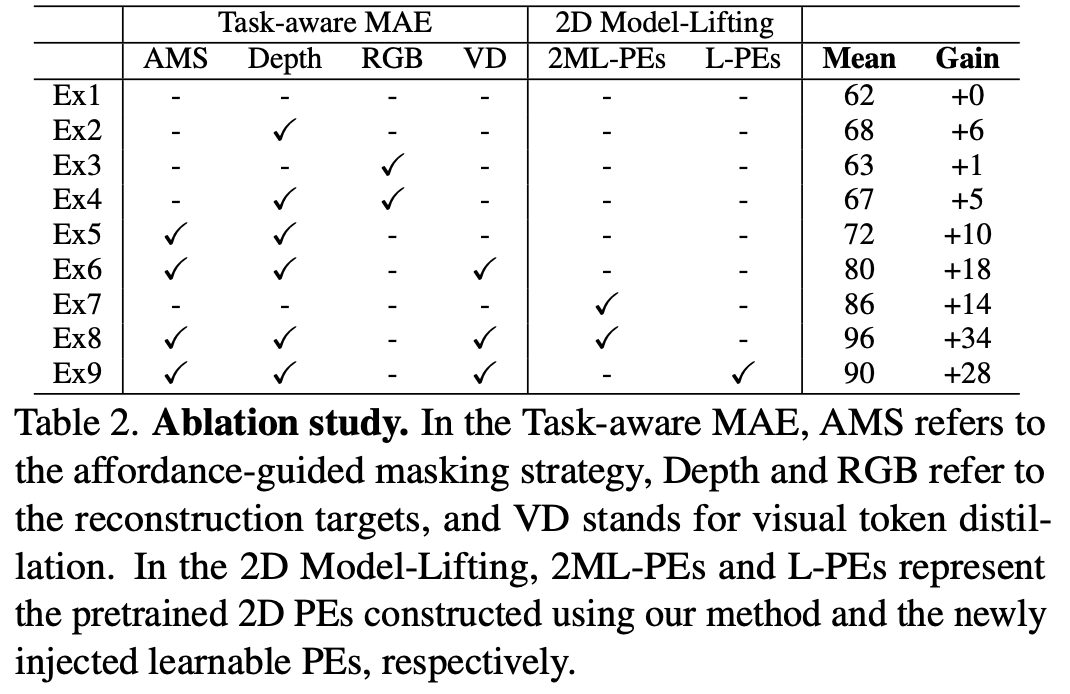
在Table.2中对 2 个 MetaWorld 仿真任务进行了一系列消融实验,包括组装和盒子关闭,并计算了平均操作准确率。
For the Task-aware MAE
在 Ex2 - Ex4 中观察到深度和 RGB+Depth 重建的表现优于 Ex1,成功率分别为 6 和 5,而单独的 RGB 重建并没有显示出显着的改善。这突出了重建几何信息在操作任务中的重要性。比较 Ex2 和 Ex5 发现与随机掩蔽策略相比,可供性引导掩蔽策略将成功率提高了 4,这表明专注于与任务相关的可供性区域来学习几何信息更有效。与 Ex5 相比,使用视觉标记蒸馏进行预训练(Ex6)导致额外增加了 8,这表明在赋予 2D 基础模型隐式 3D 机器人意识时,防止灾难性地遗忘预训练知识至关重要。
For the 2D model-lifting strategy
与使用图像输入的 Ex1 相比,Ex7 引入了本文的提升策略和显式点云编码,从而取得了显着的改进。结果表明,3D 空间信息对于实现鲁棒操作至关重要。Ex8 也显示出比 Ex7 更明显的改进,验证了隐式的 3D 表示学习可以促进后续的显式 3D 模仿学习。最后,与 Ex8 相比,Ex9 采用了新引入的 PE 而没有进行预训练,并且性能下降了 6%,证明了提升策略最有效地利用了大规模 2D 预训练知识。在Appendix. B.4 中探讨了虚拟平面的数量和位置的影响,并研究了参数更新方式在模仿学习中的影响。
4.4 Exploration of Generalization
利用二维基础模型的大规模预训练知识和全面的三维机器人表征,Lift3D 展现出强大的真实世界泛化能力。如Table.3 所示设计了三个与训练场景不同的真实世界测试场景,以验证其泛化能力。

- 不同的操控实例:
Lift3D展现出对各种操控对象的稳健性,实现最小的准确率损失。这一成功主要归功于预训练的 2D 基础模型的语义理解能力; - 复杂的背景场景:背景干扰会显著降低所有方法的准确率,但
Lift3D的下降幅度最小,将操控成功率保持在 50 以上。这归功于其在 3D 空间中有效利用了大规模预训练知识。此外,可供性引导的掩蔽策略通过重建增强了模型对前景区域空间几何的理解,同时最大限度地减少了背景干扰的影响; - 不同的光照条件:光照变化会影响 2D 图像的数据分布,也会影响深度捕捉,从而影响点云数据。在光照变化的影响下,
Lift3D的平均准确率仅下降 20%,证明了其稳健的 3D 机器人表示。
4.5 Exploration of Model Scalability
在计算机视觉领域,随着参数的增加二维基础模型通常会提升下游任务的性能。在此基础上,作者研究了Lift3D 策略是否也表现出可扩展性。在非常难的 MetaWorld 仿真任务 shelf-place 上进行了实验。对于这一复杂任务,Lift3D (DINOV2-ViT-base) 的准确率仅为 28。ViT-base 的参数数量仅为 86M,而 ViT-large 和 ViT-giant 分别拥有 304M 和 1B 个参数。通过用 DINOV2-ViT-large 和 DINOV2-ViT-giant 替换二维基础模型,Lift3D 在 shelf-place 任务上达到了 48 和 58 的准确率,并展示了更快的收敛速度,如Fig.5 所示。这些改进证明了 Lift3D 策略模型的可扩展性,并且 Lift3D 框架能够使用更大的二维基础模型生成更鲁棒的操作策略。
5. Conclusion and Limitation
本文介绍了 Lift3D 一个新颖的框架,它将大规模预训练的 2D 基础模型与强大的 3D 操作功能相结合。首先,设计了一个任务感知的 MAE,它可以mask与任务相关的可供性区域并重建深度几何信息,从而增强隐式 3D 机器人表示;其次,提出了一种 2D 模型提升策略,该策略利用预训练的 2D 基础模型显式编码 3D 点云数据以进行操作模仿学习。Lift3D 在仿真和真机实验中始终优于现有方法,在各种实际场景中表现出强大的泛化能力。就局限性而言,Lift3D 框架专注于将 2D 视觉模型提升到 3D 操作任务,这意味着它无法理解语言条件,但是可以适应像 CLIP 这样的多模态模型,从而实现 Lift3D 编码器与语言模型的集成,并为新的 3D VLA模型铺平道路。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 29
29 0
0- 0



 已为社区贡献61条内容
已为社区贡献61条内容

所有评论(0)