大模型扫盲之推理时显存占用计算
快速计算大模型推理时所需显存
大模型推理时所需显存计算方法
LLM在推理时所需显存由3部分构成,模型权重,kv cache和其他临时中间变量,前两部分占主要,而推理时产生的临时变量只占显存的很小一部分。
对于大部分计算资源紧张的人,通过以下方法即可快速确定一个模型是否可以在本地进行部署。
权重所需显存
从模型名字或config文件可以得到该模型参数量,比如Llama2-70B就代表该模型有700亿参数,使用该参数*对应字节数就可以得到权重所需显存。
目前常见的LLM数据类型所占字节数如下:
- fp32:4字节
- fp16/bf16:2字节
- int8:1字节
- fp8:1字节
如果使用bf16对Llama2-7B进行推理,所需显存为:
7B * 2 = 14000000000 bytes = 13.0385 GB ≈ 14GB
本身参数量也不会完全是整数,所以一般认为一个1B的大模型在使用bf16精度进行推理时,加载权重需要2GB的显存。所以如果使用fp32精度对Llama2-70B进行推理时就需要280GB的显存来记载权重。
满血DeepSeek-R1有671B的参数量,bf16精度推理光加载权重就需要将近1.35TB的显存。
kv cache 所需显存
kv cache是推理时产生的一些临时中间变量,它的大小与模型的参数和推理时的batch size有关,一般来说,kv cache的大小为:
kv cache size = batch size * max seq len * head num * head dim * num layer * 2 * 2
其中,batch size是推理时的batch size,max seq len是模型的最大序列长度(input length + output length),head num是模型的头数,head dim是模型的头大小,num layer是模型的层数,第一个2是k cache + vcache,第二个2代表bf16的字节数。
这里需要指出为什么按照max seq len计算,因为在推理之前要先估算峰值显存占用。
以Llama2-7B为例,来看下它的模型config: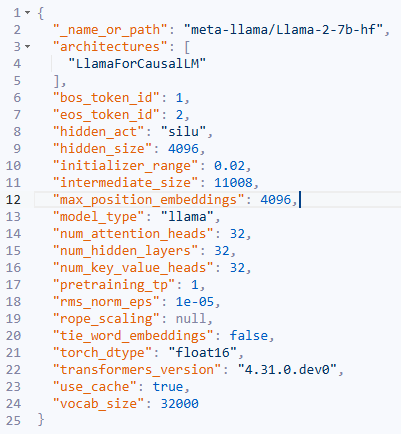
从config可以看出Llama2-7B的max seq len=4096,head num=32,head dim=128 (head_dim * head_num=hidden_size),num layer=32。
使用bf16精度推理时,kv cache所占内存大小为:
# batch_size = 1
1 * 4096 * 32 * 128 * 32 * 2 * 2 = 2 GB
# batch_size = 16
16 * 4096 * 32 * 128 * 32 * 2 * 2 = 32 GB
从以上计算可以看出,随着bs的增大,kv cache所需显存快速增长,因此在随着现在的推理场景上下文长度越来越大,如何优化kv cache的显存占用成为了非常重要的研究方向。
所以,如果使用bf16精度对Llama2-7B进行推理,模型权重 + kv cache所需显存最少为:14 + 2 = 16 GB,再加上一些推理时产生的临时变量,那么需要17GB左右的显存才可以正常推理Llama2-7B。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)