香港大学融合垂直与水平动作的无人机导航新框架!基于网格的视图选择和地图构建的空中视觉语言导航
本文提出了基于网格视图选择和地图构建的方法,用于空中视觉语言导航。网格视图选择将连续环境中的空中VLN转化为离散环境中的视图选择任务,地图构建进一步融合了导航路径上的观测特征,提供了周围环境的信息。广泛的实验结果表明,基于网格的视图选择是一种有效的框架,能够将传统的VLN方法适应于空中VLN,BEV网格图使智能体能够利用环境上下文以获得更好的性能。
·

- 作者:Ganlong Zhao1,2^{1,2}1,2, Guanbin Li2,3,4^{2,3,4}2,3,4, Jia Pan1^{1}1, Yizhou Yu1^{1}1
- 单位:1^{1}1香港大学,2^{2}2中山大学,3^{3}3广东省大数据分析与处理重点实验室,4^{4}4鹏城实验室
- 论文标题:Aerial Vision-and-Language Navigation with Grid-based View Selection and Map Construction
- 论文链接:https://arxiv.org/pdf/2503.11091
主要贡献
- 提出了基于网格的视图选择和地图构建框架,将无人机视觉语言导航(Aerial VLN)任务转化为离散环境中的视图选择任务。
- 引入了垂直动作预测,考虑了垂直动作与水平动作的耦合,从而实现了有效的高度调整。
- 设计了基于鸟瞰图的网格地图,融合了导航历史中的视觉信息,提供了上下文场景信息,并减轻了障碍物的影响。
- 采用跨模态Transformer模型,显式对齐长导航历史与指令,提供了更丰富的状态跟踪和决策支持信息。
- 在两个具有挑战性的基准数据集上取得了最先进的性能,验证了方法的有效性。
研究背景
研究问题
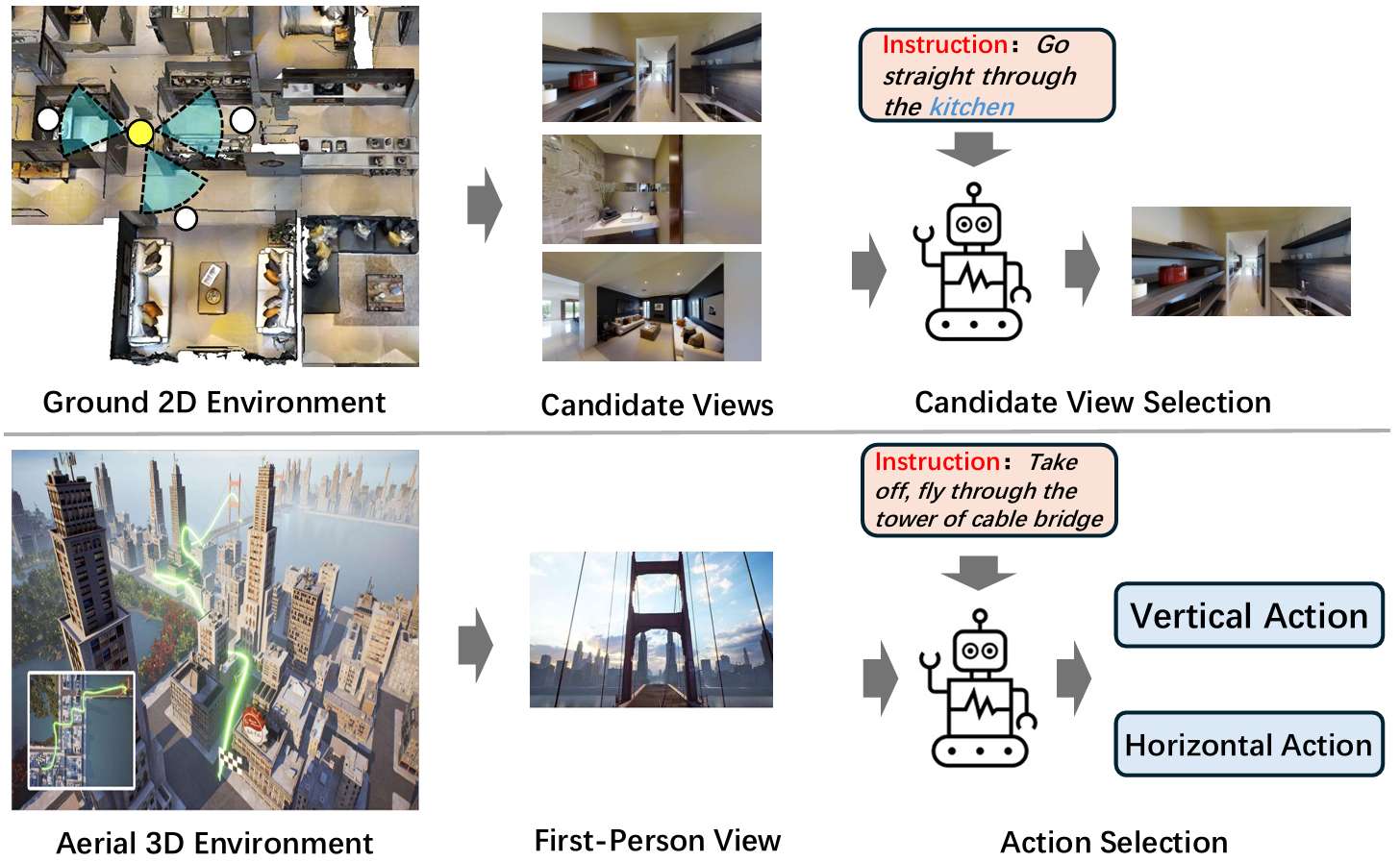
- 论文主要解决的问题是如何在无人机(UAV)上实现视觉语言导航(Aerial VLN),即让无人机根据人类指令在三维空中环境中进行导航。
- 与地面VLN不同,空中VLN要求智能体在水平和垂直方向上做出决策。
研究难点
该问题的研究难点包括:
- 导航路径更长、
- 三维场景更复杂、
- 垂直和水平动作之间的相互作用被忽视。
相关工作
-
无人机导航:
- 早期方法主要依赖GPS或惯性导航,但这些方法存在精度不足或误差累积的问题。
- 近年来,基于视觉的导航成为一种有吸引力的替代方案,以实现可靠的自主性。
-
无人机视觉语言导航:
- 结合语言模态进行无人机导航,研究如何让无人机在复杂环境中遵循自然语言指令。
- 一些研究在小型虚拟环境中进行,使用四轴飞行器智能体进行实验,动作集有限。
- AVDN数据集专注于基于对话的Aerial VLN,使用卫星图像数据集xView中的鸟瞰图输入,提出HAA-Transformer用于路径预测,但难以应用于当前环境。
-
城市导航:
- CityNav利用SensatUrban数据集中的3D点云数据进行无人机飞行环境的模拟。
- 使用CityRefer数据集的地理信息作为语言目标信息。
-
视觉语言导航:
- VLN要求智能体通过自然语言指令导航环境,分为离散和连续环境两种设置。
- 离散环境基准测试要求智能体通过预定义的视角图导航,而连续环境基准测试允许智能体自由移动。
- 一些连续VLN方法尝试将离散VLN方法转移到连续环境,关键在于路径预测器,但高度依赖环境,难以转移。
- 一些研究关注更复杂的室外环境,如Touchdown数据集和LANI数据集的修改版本。也有研究使用无人机进行指令引导的导航。
方法
问题表述
- Aerial VLN的目标是让无人机智能体根据人类指令在三维环境中导航。
- 给定一个指令 I={w1,w2,...,wNI}I = \{w_1, w_2, ..., w_{N_I}\}I={w1,w2,...,wNI} 和初始位置 p0=(x0,y0,z0)p_0 = (x_0, y_0, z_0)p0=(x0,y0,z0),智能体需要在环境中执行一系列动作 AAA 来完成任务。
- 每个步骤中,智能体接收环境观测 OtO_tOt 并决定下一步动作 ata_tat。
- 成功导航的定义是智能体在停止时或达到最大步数时,距离目标位置不超过20米。
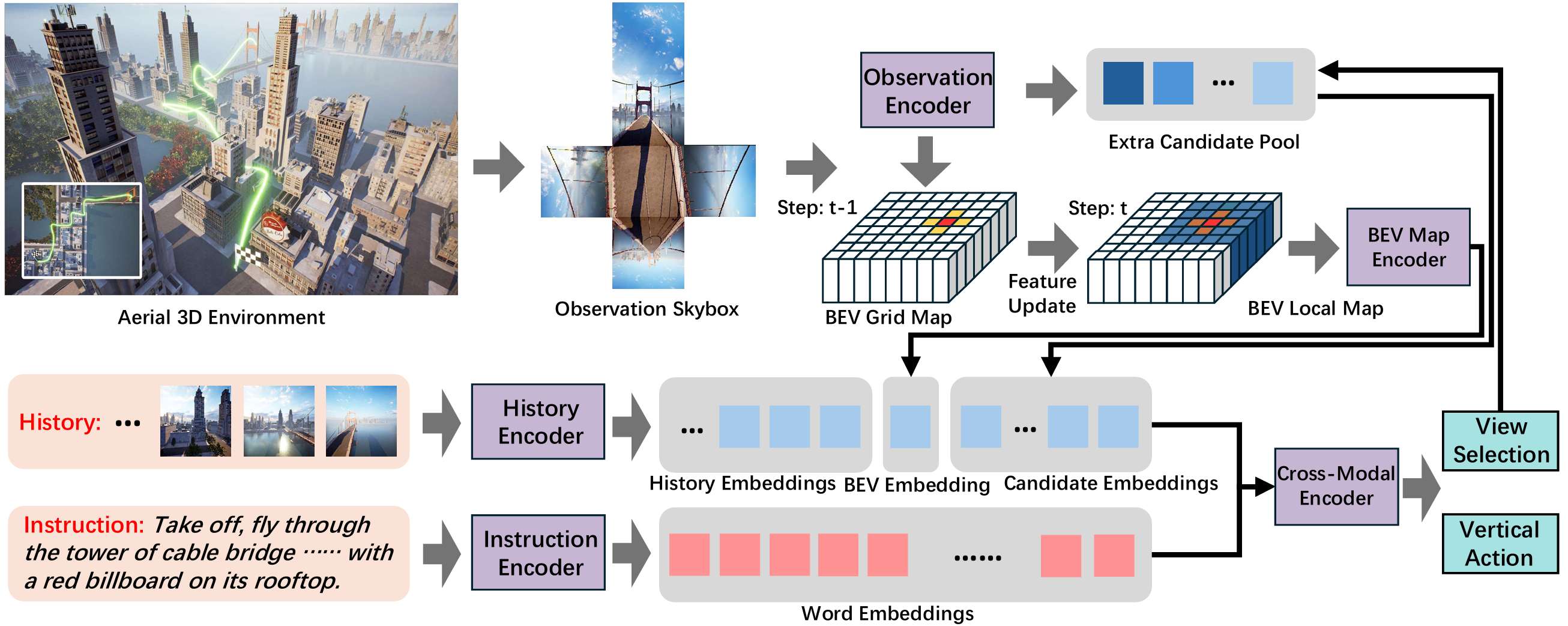
基于网格的视图选择
视图-候选对应关系
- 在每一步,智能体从六个方向(前、左、右、后、上、下)捕获观测图像,形成天空盒 OtO_tOt。
- 对于每个图像 otio_t^ioti,根据图像方向和智能体的步长,计算候选位置 p~ti\tilde{p}_t^ip~ti:
p~ti=(xt,yt,zt)+dti⊙(sh,sh,sv) \tilde{p}_t^i = (x_t, y_t, z_t) + d_t^i \odot (s_h, s_h, s_v) p~ti=(xt,yt,zt)+dti⊙(sh,sh,sv)
其中 (xt,yt,zt)(x_t, y_t, z_t)(xt,yt,zt) 是智能体的位置,shs_hsh 是水平步长,svs_vsv 是垂直步长,dtid_t^idti 是摄像头的归一化方向向量,⊙\odot⊙ 表示逐元素乘法。
真值候选生成
- 为了计算损失,需要生成真值候选。通过比较真值路径 PgtP_{gt}Pgt 和导航路径 PtP_tPt,使用归一化的动态时间规整(nDTW)来选择最匹配的候选位置:
cgt=argmax1≤i≤N{nDTW(Pgt,(Pt+p~ti))} c_{gt} = \arg\max_{1 \leq i \leq N} \{nDTW(P_{gt}, (P_t + \tilde{p}_t^i))\} cgt=arg1≤i≤Nmax{nDTW(Pgt,(Pt+p~ti))}
其中 (Pt+p~ti)(P_t + \tilde{p}_t^i)(Pt+p~ti) 表示移动到候选位置 p~ti\tilde{p}_t^ip~ti 后的导航路径。
低级控制
- 智能体根据当前位置和选定的候选位置,分别进行水平和垂直移动。
- 具体步骤包括转向、前进、上升或下降,直到智能体到达目标位置。
基于网格的视图选择
- 为了简化框架并与下一节的BEV网格地图构建对齐,智能体在每一步捕获六个视图。
- 这种网格化的方法有效地将场景离散化,简化了低级控制和场景地图构建。
模型设计
模型架构
- 文本编码:使用BERT提取指令嵌入,然后通过transformer获得上下文表示。
- 观测编码:计算每个视图的相对角度,提取观测嵌入。观测嵌入 eie_iei 是视图嵌入和角度嵌入的和。
- 历史编码:使用全景transformer和时间transformer编码导航历史,生成历史嵌入。
- 跨模态transformer:结合历史和观测嵌入,输出不同视图的概率分布,确定预测动作。
垂直动作预测
- 智能体在每个视图中预测垂直偏移,提供上升或下降的候选位置。对于每个视图 oio_ioi 和其对应的候选位置 p~ti\tilde{p}_t^ip~ti,计算三个候选位置:下、中、上:
Ui=(p~ti−vup,p~ti,p~ti+vup) U_i = (\tilde{p}_t^i - v_{up}, \tilde{p}_t^i, \tilde{p}_t^i + v_{up}) Ui=(p~ti−vup,p~ti,p~ti+vup)
其中 vupv_{up}vup 是上升移动的位移向量。然后使用nDTW选择最佳候选位置:
dvgti=argmax1≤j≤3{nDTW(Pgt,(Pt+p~j))} d_{v_{gt}}^i = \arg\max_{1 \leq j \leq 3} \{nDTW(P_{gt}, (P_t + \tilde{p}_j))\} dvgti=arg1≤j≤3max{nDTW(Pgt,(Pt+p~j))}
最后,使用均方误差(MSE)计算损失:
Lvertical=1N∑i=1NMSE(dvi,(dvgti−1)2) L_{vertical} = \frac{1}{N} \sum_{i=1}^{N} \text{MSE}(d_v^i, \frac{(d_{v_{gt}}^i - 1)}{2}) Lvertical=N1i=1∑NMSE(dvi,2(dvgti−1))
BEV网格地图
- 构建一个二维网格地图,记录水平平面上的特征。每个单元格包含对应位置的BEV特征向量。
- 在每一步更新网格地图,提取局部特征图以支持决策:
M(u,v)t=GRU(M(u,v)t−1,fp~ti) M^{t}_{(u,v)} = \operatorname*{GRU}(M^{t-1}_{(u,v)}, f_{\tilde{p}^i_{t}}) M(u,v)t=GRU(M(u,v)t−1,fp~ti)
其中 M(u,v)tM_{(u, v)}^tM(u,v)t 是在 (u,v)(u, v)(u,v) 处的特征,fp~tif_{\tilde{p}_t^i}fp~ti 是提取的特征。
额外候选
- 引入额外候选池,存储高置信度但未被选择的候选视图。
- 在新位置时,结合新视图和额外候选池进行预测,更新候选池。
实验
数据集
实验使用了两个数据集:AerialVLN和AerialVLN-S。
-
AerialVLN:
- 是一个用于连续环境中的Aerial VLN的挑战性基准。
- 数据集包含四个不同的分割:训练集、验证可见集、验证不可见集和测试集。
- 训练集包含16,380个指令,来自17个场景;测试集包含4,830个指令,来自8个场景;验证可见集和验证不可见集分别包含1,818和2,310个指令,来自17和8个场景。
-
AerialVLN-S:
- 是AerialVLN的一个变体,适用于小场景。
- 数据集保留相同的数据分割,但包含17个较小规模且路径长度均匀分布的场景。
- 训练集、测试集、验证可见集和验证不可见集分别包含10,113、771、333和531个指令,来自12、5、12和5个场景。
评估指标
使用以下四个指标评估方法的性能:
- 导航误差(NE):停止位置到目的地的距离。
- 成功率(SR):在目的地20米范围内停止的智能体比例。
- Oracle成功率(OSR):在任何时刻在目的地20米范围内的导航次数比例。
- SDTW:通过成功率加权的路径相似性。
- nDTW:用于详细比较导航路径和真值路径的整体相似性。
实现细节
- 模型实现:基于之前的研究,保留了大部分超参数和模型架构。
- 图像特征提取:使用CLIP ViT-B/16模型进行图像特征提取。
- 批量大小:所有实验中设置为8。
- 学习率:设置为0.0001。
- 垂直损失权重:设置为1。
- BEV局部地图大小:设置为11。
- 额外候选数量:设置为10。
- 迭代次数:模型在AerialVLN和AerialVLN-S上分别训练60,000次迭代。
实验结果

实验结果显示,所提出的方法在所有指标上显著优于基线方法。
- AerialVLN:
- 与随机选择、动作采样、Seq2Seq和CMA等基线方法相比,所提出的方法在所有指标上表现更好。
- 特别是在验证不可见集上,显示出在陌生环境中有效性的提升。
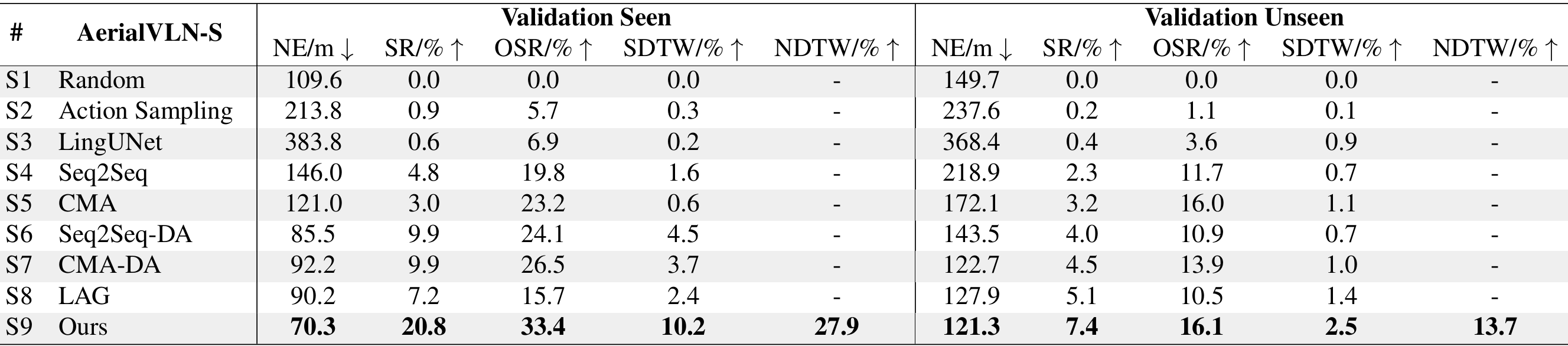
- AerialVLN-S:
- 在AerialVLN-S数据集上,所提出的方法在所有指标上表现最佳。尽管增加了更多竞争者,但所提出的方法仍然取得了最好的性能。
- 在验证可见集上,成功率提高了10.9%,在验证不可见集上提高了2.3%。
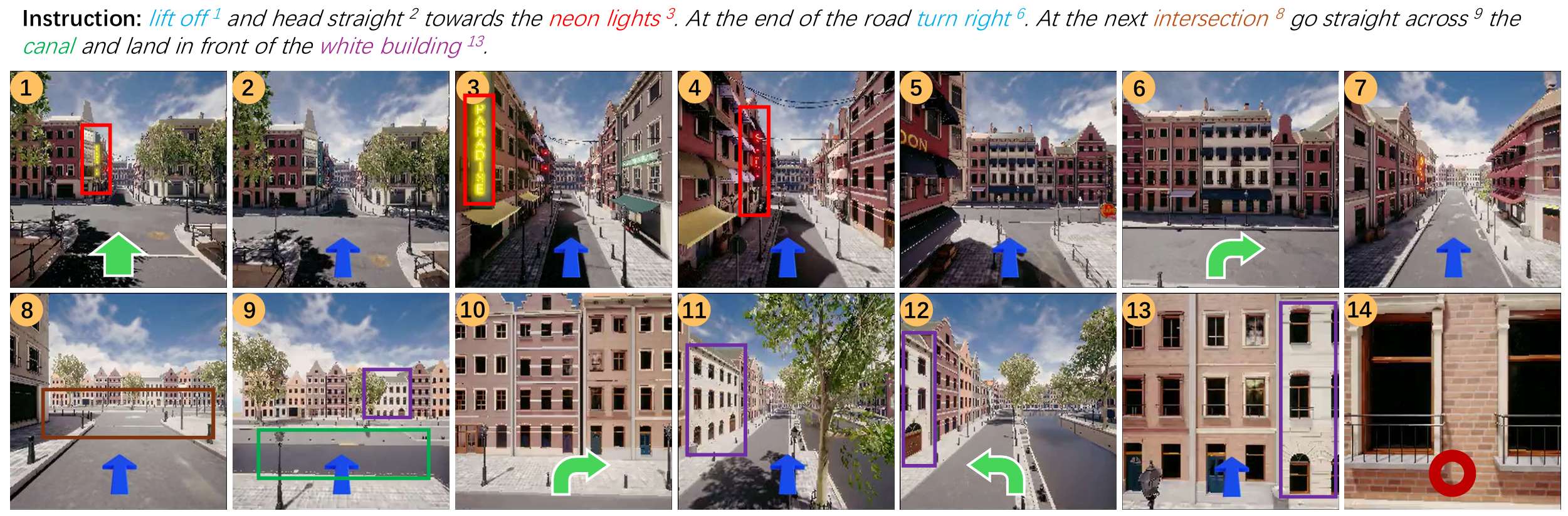
定性结果
定性结果显示,所提出的方法能够成功识别地标并遵循方向指令进行导航。
消融实验
不同组件的消融实验
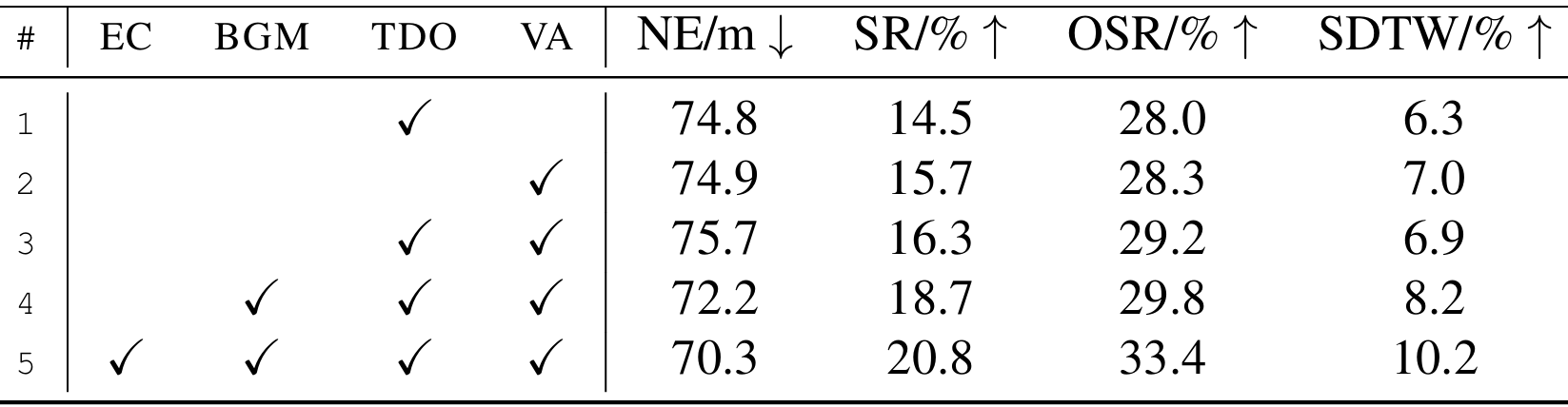
实验设置
- 额外候选(EC):通过将额外候选的数量设置为零来移除该组件。这减少了模型在选择动作时的备选方案。
- 俯仰/俯视观测(TDO):在训练和评估过程中移除向上和向下的观测,以消除上下文信息。这使得智能体只能通过垂直动作预测来调整高度。
- 垂直动作(VA):在训练和评估过程中移除垂直动作预测,使得智能体只能通过选择相应的视图来上升或下降。由于成功距离阈值(20米)远大于步长(5米),这不会影响智能体到达真值目的地的能力。
结果分析
- 实验结果显示,所有四个组件都对性能提升有贡献。
- 具体来说,移除任何一个组件都会导致性能下降,表明这些组件在模型中起到了重要作用。
超参数敏感性分析
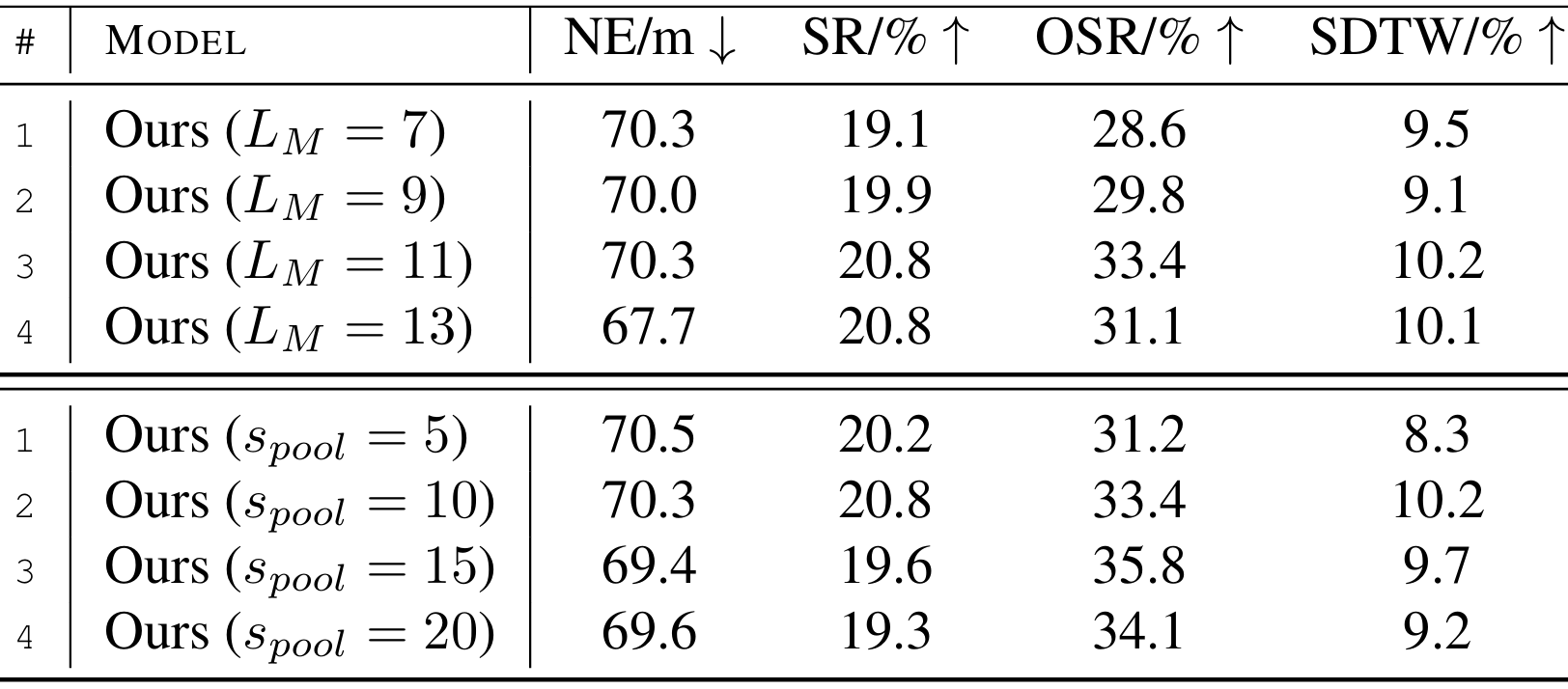
分析了两个重要超参数的敏感性:局部BEV网格地图的大小 LML_MLM 和额外候选的数量 spools_{pool}spool。
- 局部BEV网格地图大小 LML_MLM:决定了发送给智能体的局部地图信息的范围,以提供动作预测的上下文。实验结果表明,LM=11L_M = 11LM=11 时成功率最高。
- 额外候选数量 spools_{pool}spool:决定了候选池中维护的额外候选数量,以提供动作预测的额外选择。实验结果显示,spool=10s_{pool} = 10spool=10 时效果最佳。
垂直动作预测分析
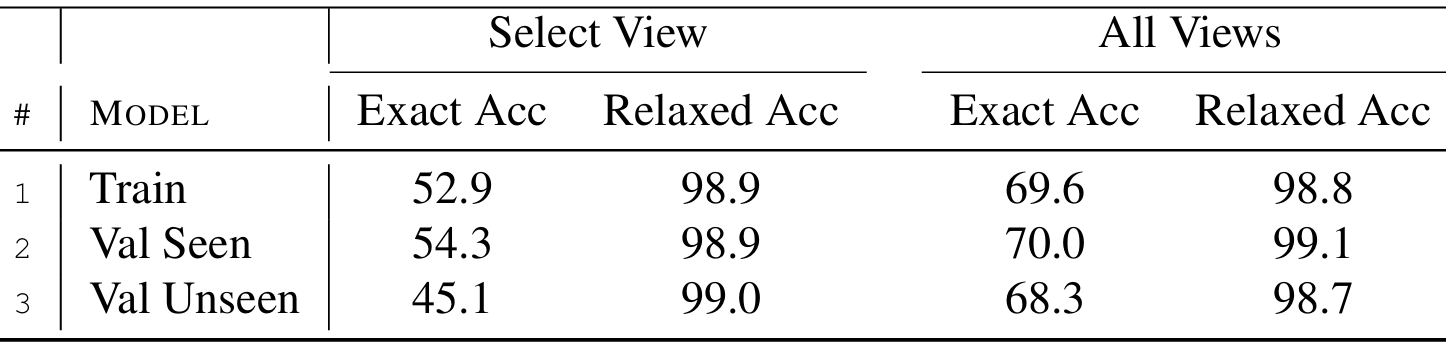
- 实验设置:在AerialVLN-S的三个数据集分割上进行测试,报告了四种不同指标的性能。
- 指标:包括“选择视图”的准确性和“所有视图”的准确性。“精确准确率”是指预测与真值完全匹配的准确率,“宽松准确率”是指预测与真值最多相差1的准确率。
- 实验结果表明,所提出的方法在所有设置中都显著优于随机选择。特别是,“宽松准确率”接近100%,表明智能体偏离真值高度的可能性非常低。
总结
- 本文提出了基于网格视图选择和地图构建的方法,用于空中视觉语言导航。
- 网格视图选择将连续环境中的空中VLN转化为离散环境中的视图选择任务,地图构建进一步融合了导航路径上的观测特征,提供了周围环境的信息。
- 广泛的实验结果表明,基于网格的视图选择是一种有效的框架,能够将传统的VLN方法适应于空中VLN,BEV网格图使智能体能够利用环境上下文以获得更好的性能。


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献90条内容
已为社区贡献90条内容

所有评论(0)