李宏毅genai笔记:模型合并
θB-θ:任务B上额外获得的能力,直接加到θA上即可但参数是加加减减的东西吗?LLM时代好像是的新模型同时有A和B能力的模型了,前提是A和B是从一个foundation mode里来的反向相减,就能失去B的能力,也即unlearning假设有ABC,而且知道D相对于C就是B相对于A的关系那么即使没有D的资料,也可以获得D的能力比如我们有一个基本的语音辨识系统ASR,和一个一般人听不懂的、有文字资料
0 起源: 多目标模型融合
(这一节是自己的补充,课程没有)
- 多目标模型融合,通过一个模型同时训练多个目标
- 该方法的优点是各个任务之间能够共享信息,统一迭代方便,节省资源
- 但缺点也比较明显,目标越多模型越复杂,各任务之间相互影响
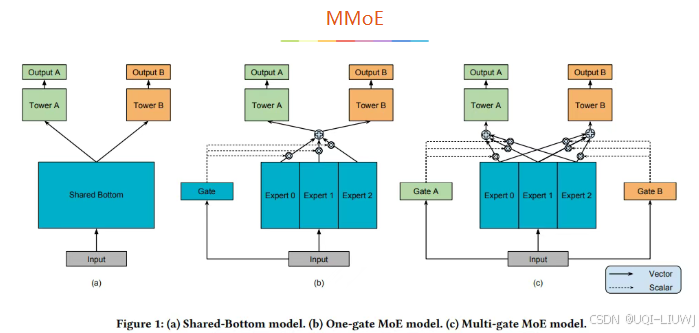
- 多任务学习的的框架广泛采用Shared-bottom的结构,不同任务间共用底部的隐层
- 这种结构本质上可以减少过拟合的风险,但是效果上可能受到任务差异和数据分布带来的影响
- Shared-Bottom 网络(左图)通常位于底部,它通过浅层参数共享,互相补充学习。
- 这种方式下任务相关性越高,模型的loss可以降低到更低。
- 但是当任务没有好的相关性时,这种Hard parameter sharing会损害效果。
- MOE(中图)由一组专家系统(Experts)组成的神经网络结构替换原来的Shared-Bottom部分
- 每一个Expert都是一个前馈神经网络,再加上一个门控网络(Gate)
- MMoE(右图)(Multi-gate Mixture-of-Experts)是在MOE的基础上,使用了多个门控网络, k个任务就对应k个门控网络。
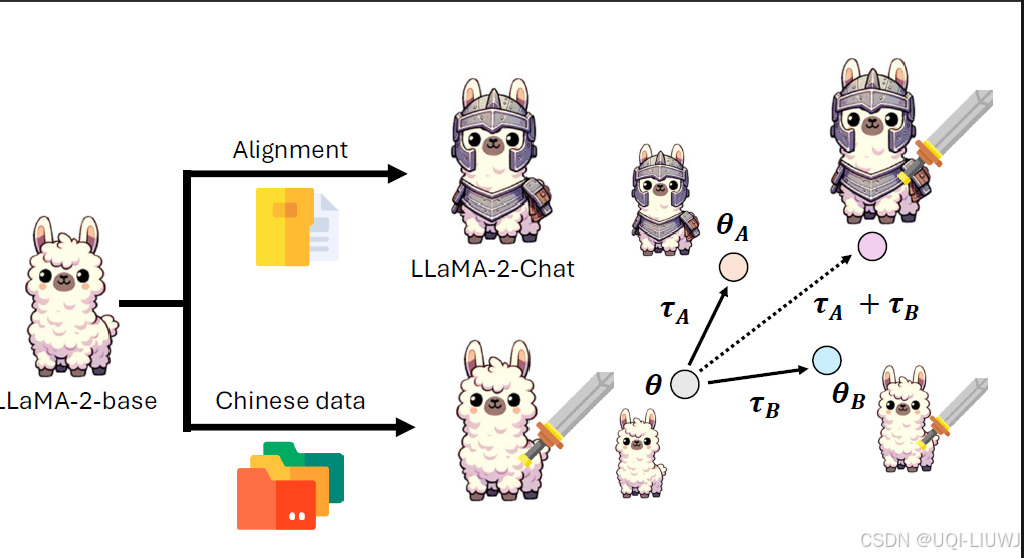
1 模型合并
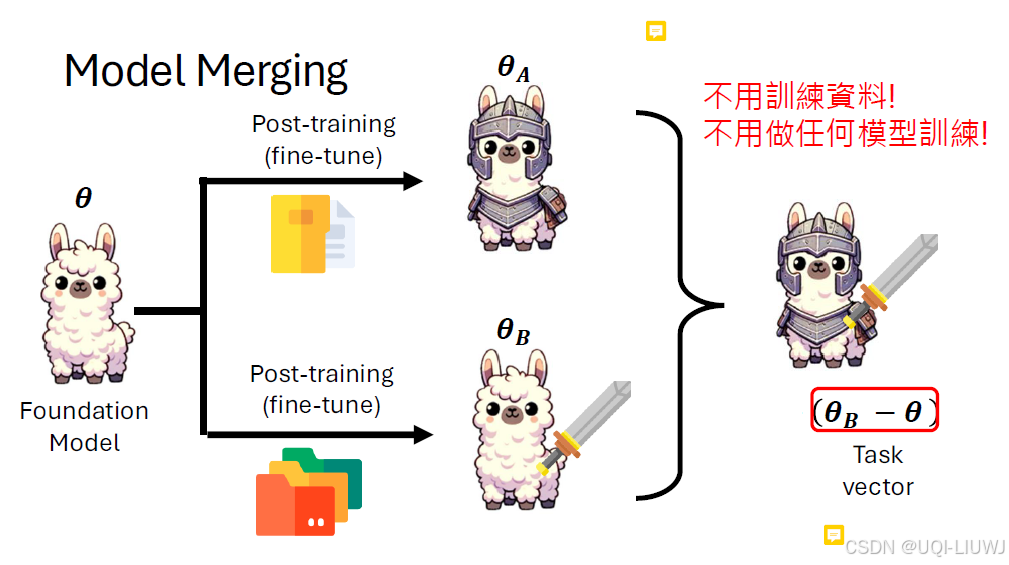
θB-θ:任务B上额外获得的能力,直接加到θA上即可
但参数是加加减减的东西吗?
LLM时代好像是的
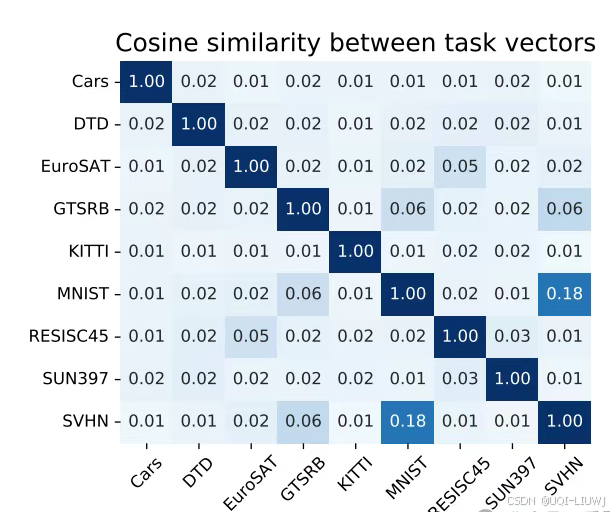
不同的任务向量几乎是正交的
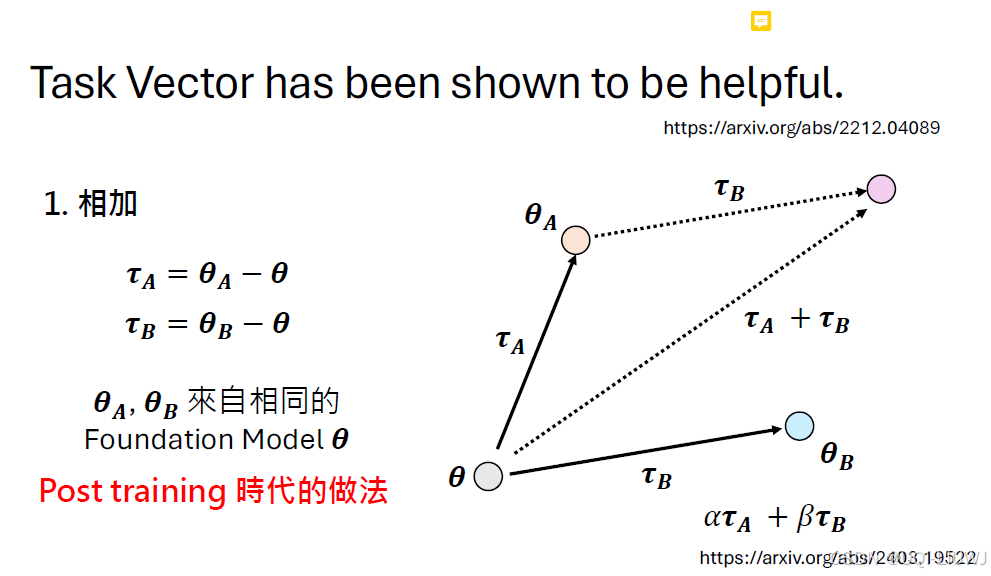
Model Stock: All we need is just a few fine-tuned models
新模型同时有A和B能力的模型了,前提是A和B是从一个foundation mode里来的

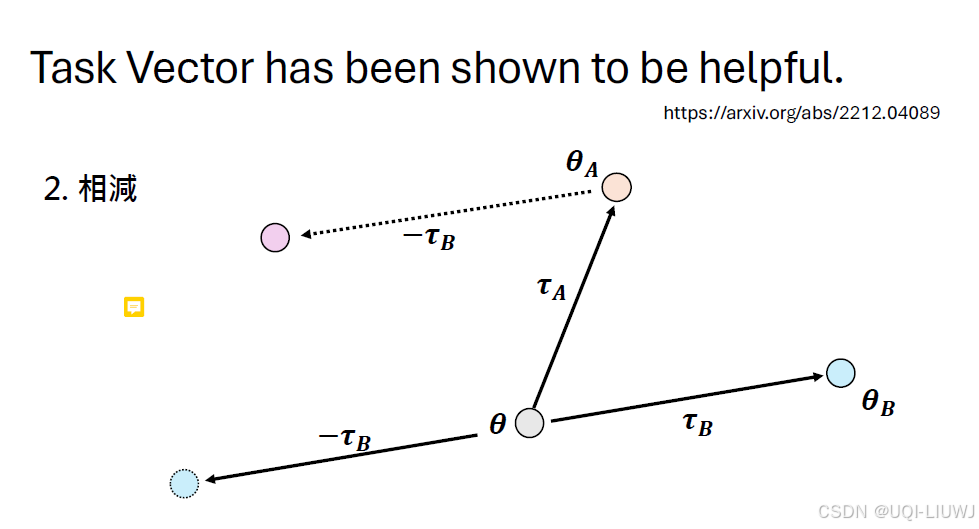
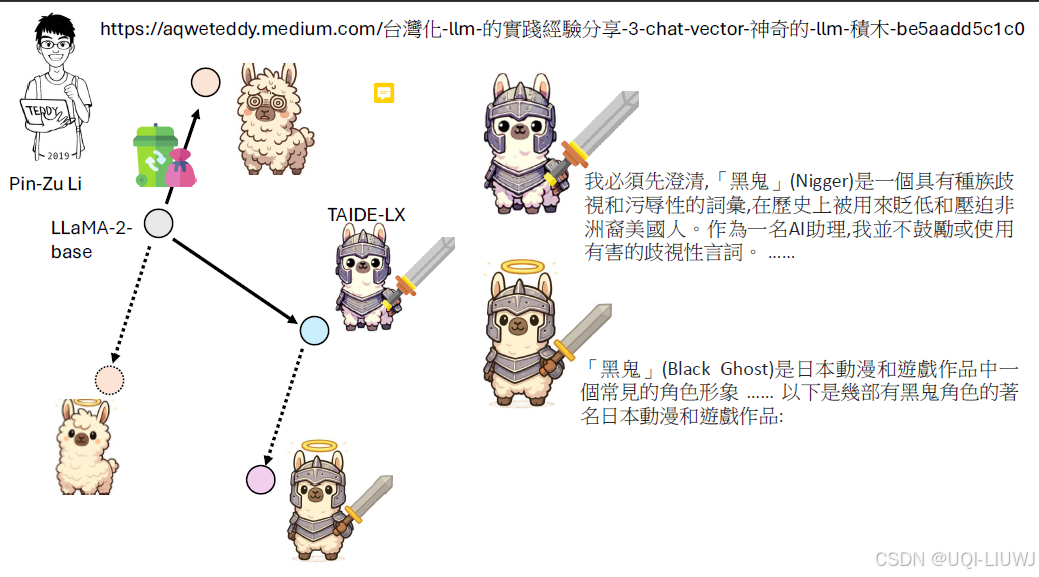
反向相减,就能失去B的能力,也即unlearning
Editing Models with Task Arithmetic
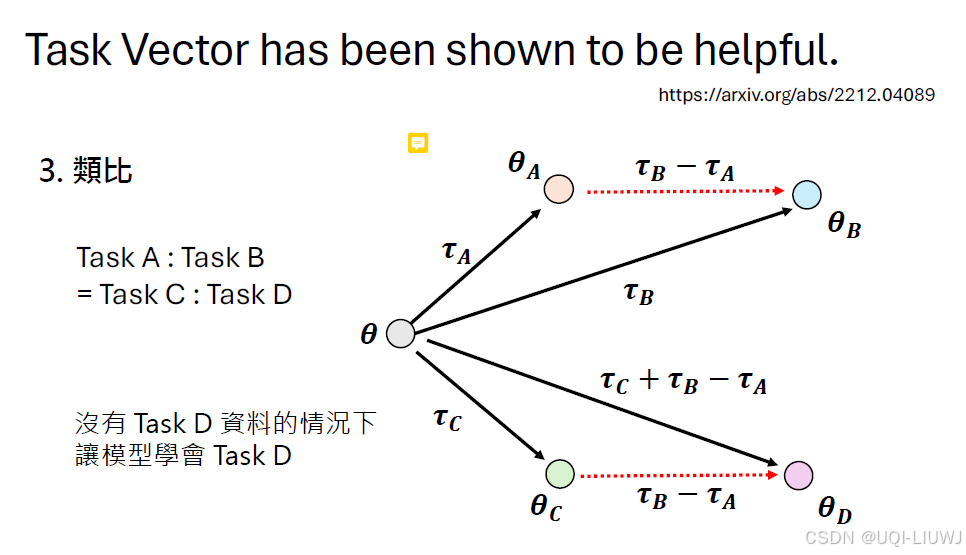
假设有ABC,而且知道D相对于C就是B相对于A的关系
那么即使没有D的资料,也可以获得D的能力
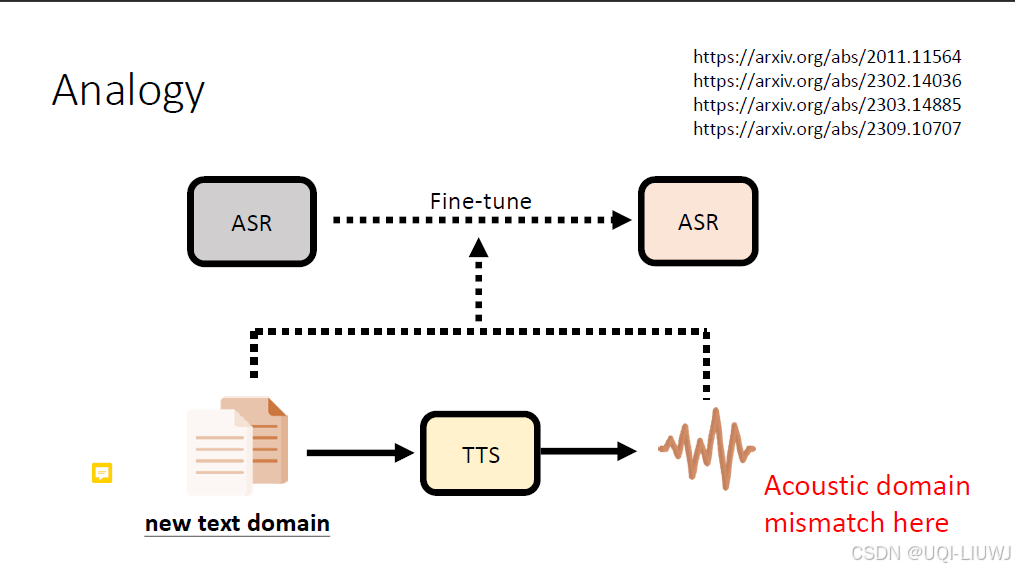
比如我们有一个基本的语音辨识系统ASR,和一个一般人听不懂的、有文字资料的会议
一种想法是让语义合成系统TTS把这些文字念出来,然后对原来ASR进行微调
但合成的语音和真正的语音还是有一定差距,那有没有办法在没有真实语音信号的情况下,让ASR能够变成像在真实语音信号下微调一样呢?
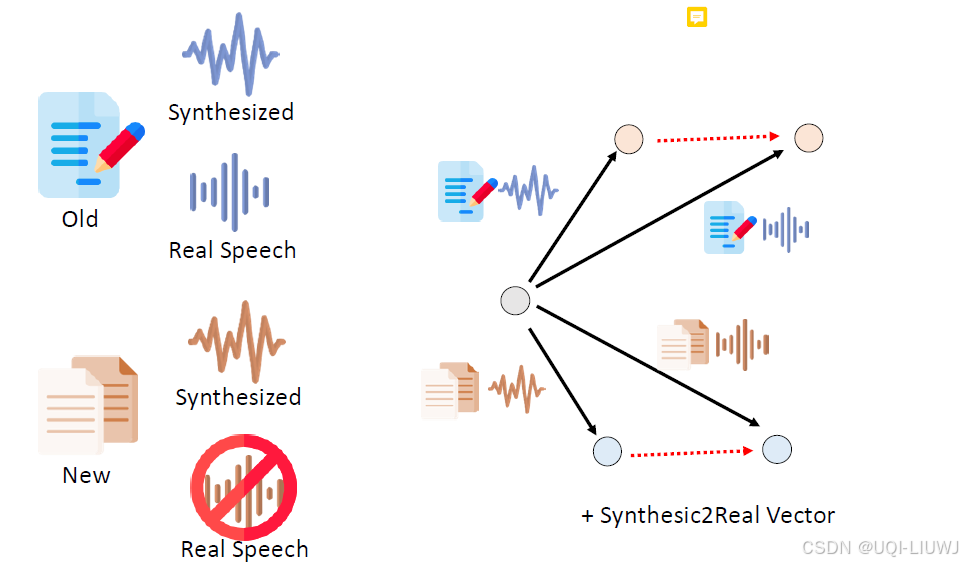
其他domain的资料有合成好的和真实的语音
那么我们用类比的模型合成方法,就能得到一个模型,好像在正式的资料上train过一样
2 模型合并不一定总成功
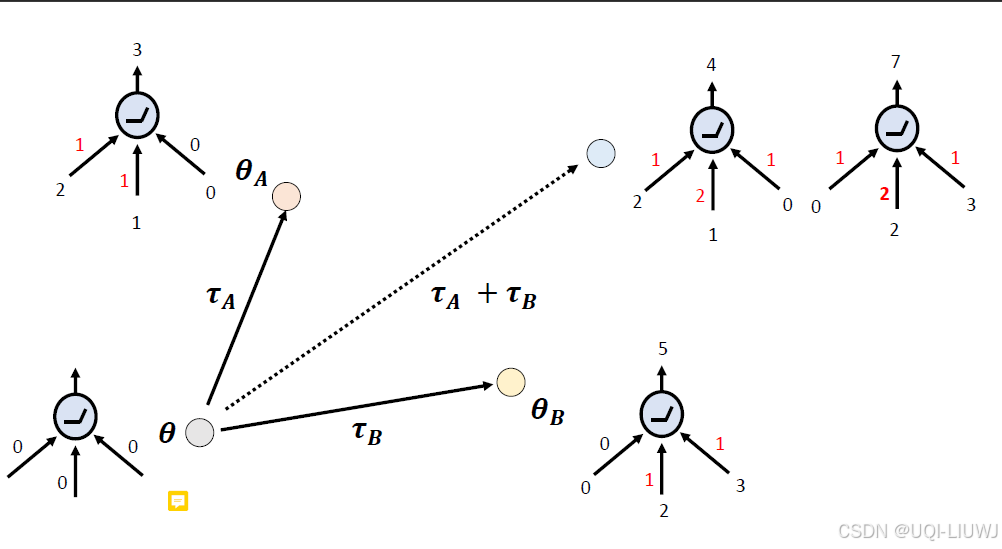
但是merge不一定总成功——>merge完之后一个输出4一个输出7
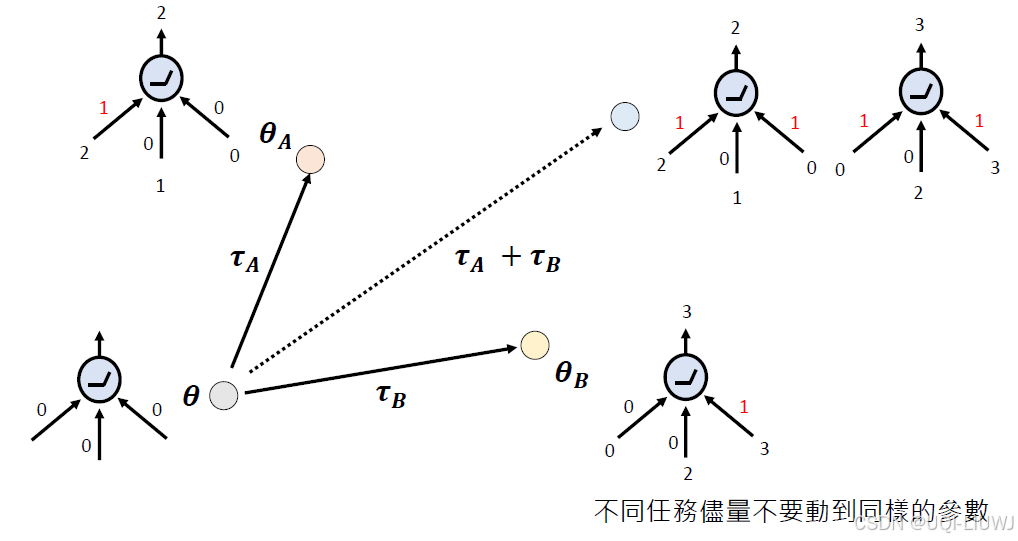
要想成功,尽量让不同任务不要动到同样的参数

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)