使用 SQL 和表格数据进行问答和 RAG(3)— 使用 LangChain 和 SQL 数据库构建一个可以通过自然语言询问数据库问题的流水线(Pipeline)
使用 LangChain 和 SQL 数据库构建一个可以通过自然语言询问数据库问题的流水线(Pipeline)。以下是代码的逐步解析和示例结果说明:从代码来看,你正在使用 LangChain 和 SQL 数据库构建一个可以通过自然语言询问数据库问题的流水线(Pipeline)。以下是代码的逐步解析和示例结果说明::使用 OpenAI 的模型(如 GPT-4)。 确保输出更稳定、确定。环境变量::A
使用 LangChain 和 SQL 数据库构建一个可以通过自然语言询问数据库问题的流水线(Pipeline)。以下是代码的逐步解析和示例结果说明:
从代码来看,你正在使用 LangChain 和 SQL 数据库构建一个可以通过自然语言询问数据库问题的流水线(Pipeline)。以下是代码的逐步解析和示例结果说明:
代码解析
1. 加载 LLM 模型
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
openai_api_base= os.getenv("OPENAI_API_BASE"),
openai_api_key= os.getenv("OPENAI_API_KEY"),
temperature=0
)
ChatOpenAI:使用 OpenAI 的模型(如 GPT-4)。temperature=0确保输出更稳定、确定。- 环境变量:
OPENAI_API_BASE:API 接口的基础 URL。OPENAI_API_KEY:API 的访问密钥。
2. 创建 SQL 查询链
from langchain.chains import create_sql_query_chain
chain = create_sql_query_chain(llm, db)
response = chain.invoke({"question": "How many employees are there"})
print(response)
create_sql_query_chain:创建一个可以根据自然语言问题生成 SQL 查询的链。chain.invoke:运行链,传入问题,例如"How many employees are there",生成 SQL 查询语句。
输出: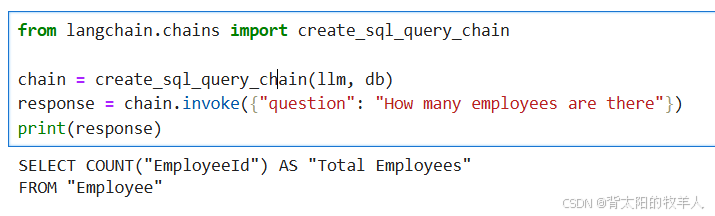
运行这个sql查询语句:
db.run(response)
输出: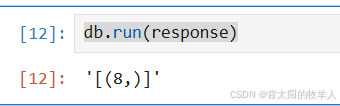
3. 执行查询链并分离查询与执行
from langchain_community.tools.sql_database.tool import QuerySQLDataBaseTool
write_query = create_sql_query_chain(llm, db)
execute_query = QuerySQLDataBaseTool(db=db)
chain = write_query | execute_query
chain.invoke({"question": "How many employees are there"})
write_query:负责生成 SQL 查询。execute_query:实际运行生成的 SQL 查询并返回结果。- 管道操作
|:将生成的 SQL 查询直接传递给执行工具QuerySQLDataBaseTool。
输出结果: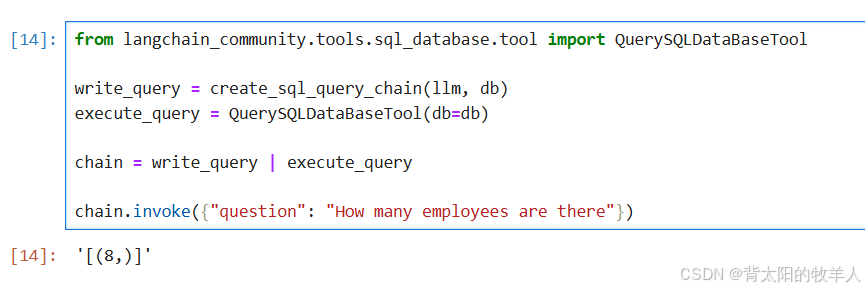
4. 自定义结果解析和生成回答
from operator import itemgetter
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnablePassthrough
answer_prompt = PromptTemplate.from_template(
"""Given the following user question, corresponding SQL query, and SQL result, answer the user question.
Question: {question}
SQL Query: {query}
SQL Result: {result}
Answer: """
)
answer = answer_prompt | llm | StrOutputParser()
PromptTemplate:定义自定义提示模板,确保生成的回答包含问题、SQL 查询和结果。- 管道操作
|:- 提示模板生成的字符串会传递给
llm。 - 模型生成的结果再通过
StrOutputParser解析为最终输出。
- 提示模板生成的字符串会传递给
5. 完整链式操作
chain = (
RunnablePassthrough.assign(query=write_query).assign(
result=itemgetter("query") | execute_query
)
| answer
)
chain.invoke({"question": "How many employees are there"})
RunnablePassthrough.assign:- 第一步:将自然语言问题通过
write_query转为 SQL 查询。 - 第二步:使用
execute_query执行SQL查询,并获取结果。
- 第一步:将自然语言问题通过
answer:根据query问题、write_query生成的SQL 查询语句和execute_query执行前面的流生成的SQL 查询语句再生成数据结果 最终输出答案。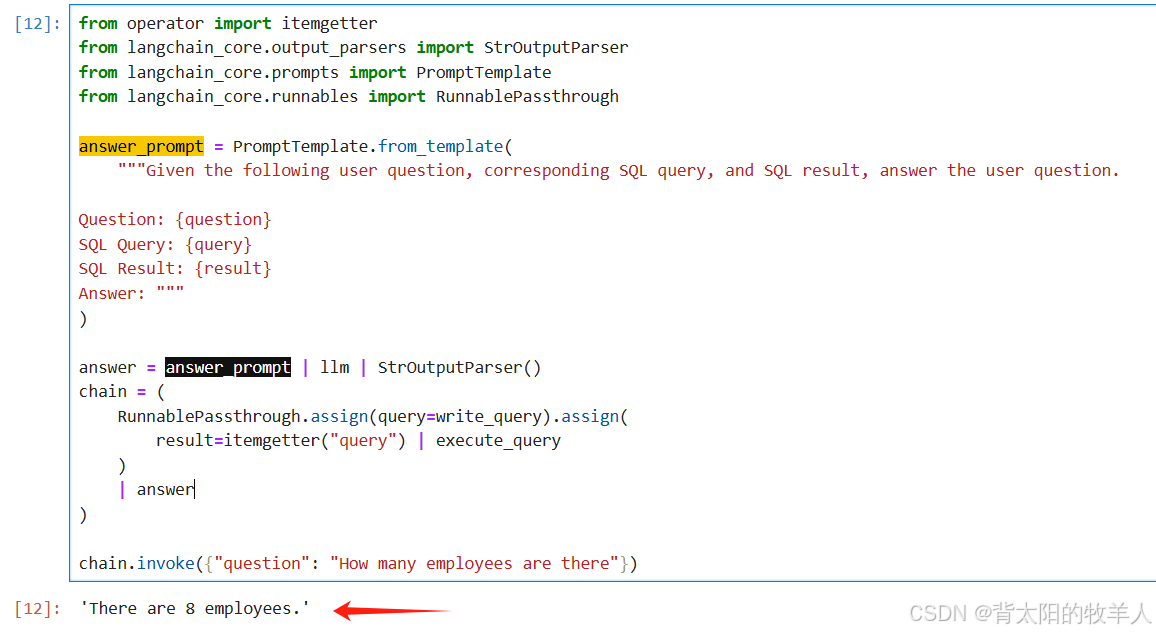
运行示例
假设数据库 Employee 表包含以下数据:
| id | name | age |
|---|---|---|
| 1 | Alice | 30 |
| 2 | Bob | 25 |
| 3 | Charlie | 28 |
问题:"How many employees are there"
执行过程:
- SQL 查询生成:
SELECT COUNT(*) AS total_employees FROM Employee; - 执行查询:
返回结果:total_employees = 3 - 生成回答:
There are 3 employees in the company.
总结
- 优点: 通过 LangChain,整个流水线实现了从自然语言问题到数据库查询与答案生成的自动化。
- 灵活性: 可以轻松扩展支持的数据库、定制回答模板,或加入更多逻辑。
- 适用场景: 数据分析、商业智能等领域,快速获取基于自然语言的问题答案。
以上流水线步骤可以用封装的create_sql_agent Agents一次性完成查询。create_sql_agent 是 LangChain 提供的一种工具,用于构建基于自然语言与数据库交互的智能代理(Agent),该代理包含 SQLDatabaseToolkit,其中包含以下工具:
- 创建并执行查询
- 检查查询语法
- 检索表描述
from langchain_community.agent_toolkits import create_sql_agent
agent_executor = create_sql_agent(llm, db=db, agent_type="openai-tools", verbose=True)
create_sql_agent 是 LangChain 提供的一种工具,用于构建基于自然语言与数据库交互的智能代理(Agent)。下面是对代码中关键部分的解读,以及使用方法和潜在的运行结果说明。
*注意:这里有个坑,需要将 pydantic 降级到 2.9.2 以下才行,不然会报错:PydanticUserError: SQLDatabaseToolkit is not fully defined; you should define BaseCache, then call SQLDatabaseToolkit.model_rebuild().*
代码解析
1. 引入 create_sql_agent 方法
from langchain_community.agent_toolkits import create_sql_agent
create_sql_agent:该方法通过结合语言模型(LLM)和数据库对象(如 SQLAlchemy 的db),创建一个 SQL 查询智能代理。- 目的:自动生成 SQL 查询、执行查询,并将结果转化为自然语言回答。
2. 创建智能代理
agent_executor = create_sql_agent(llm, db=db, agent_type="openai-tools", verbose=True)
-
参数解析:
llm:语言模型对象(如ChatOpenAI),用于生成 SQL 查询以及解释结果。db:数据库对象(如SQLDatabase),提供对数据库的交互能力。agent_type:"openai-tools":指示代理使用 OpenAI 工具链,生成高质量 SQL 查询。
verbose=True:启用详细日志,便于调试和观察执行过程。
-
返回值:
agent_executor是一个可调用对象,用于运行自然语言问题。
3. 调用智能代理执行查询
response = agent_executor.invoke({"input": "How many employees are in the company?"})
print(response)
input:自然语言问题,如"How many employees are in the company?"。- 执行过程:
- 代理会解析输入问题并生成相应的 SQL 查询。
- 查询被执行,结果返回后再转化为自然语言回答。
查看详细日志
设置 verbose=True 后,运行时会输出详细日志,包括:
- 生成的 SQL 查询。
- 查询结果。
- 结果转化为自然语言的过程。
输出: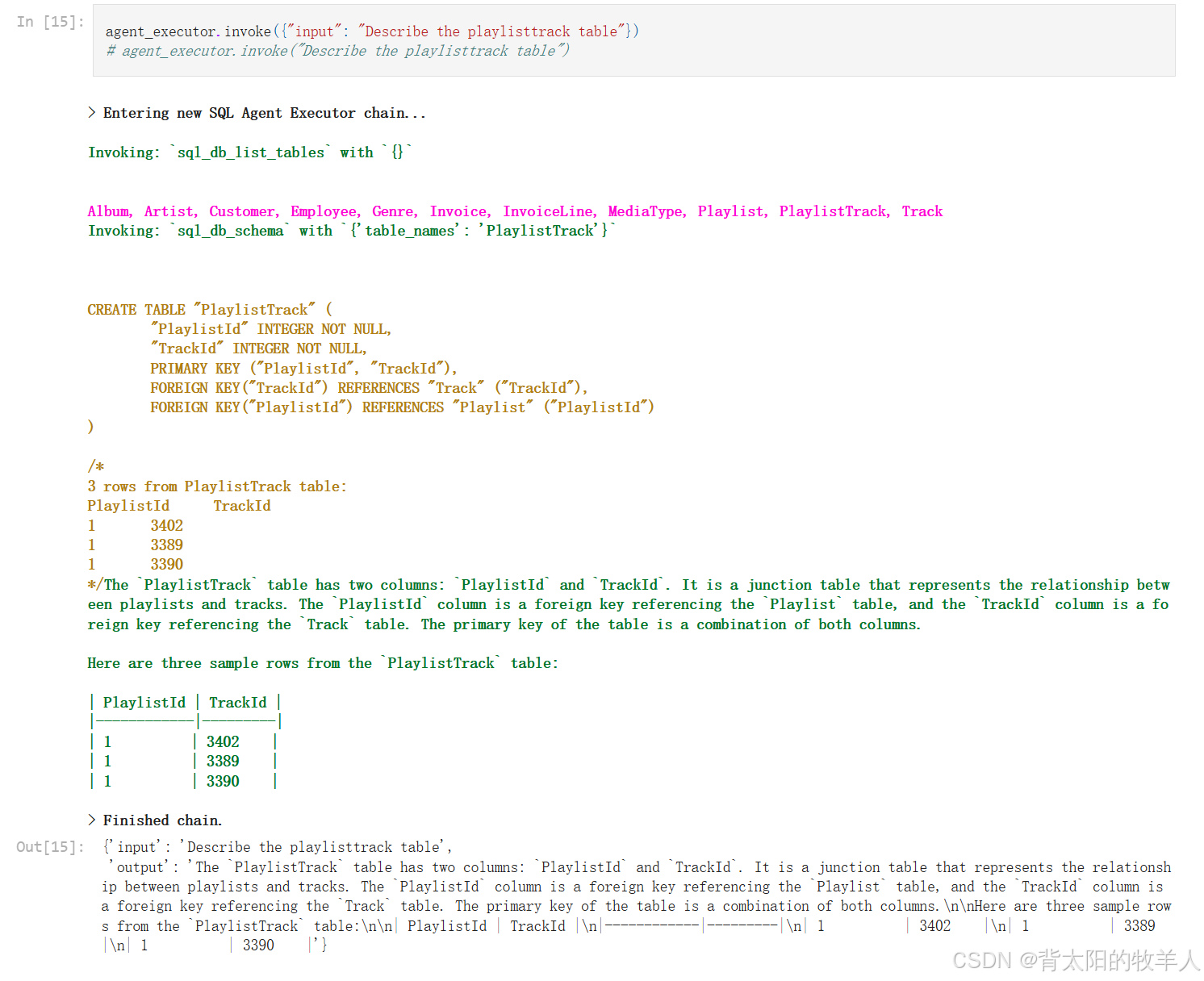
典型场景
- 数据分析:快速通过自然语言从数据库提取关键信息。
- 示例问题:
"What is the average salary of employees?"
- 示例问题:
- 报告生成:为用户提供人性化的查询结果,而无需手动写 SQL。
- 示例问题:
"How many employees were hired last year?"
- 示例问题:
- 数据调试:通过代理快速验证数据一致性或获取特定字段信息。
agent使用总结
- 优势:
- 提供了更灵活的与 SQL 数据库交互的方式,用户无需 SQL 知识即可获取数据库信息。
- 通过
verbose查看详细执行过程,便于调试和优化。 - 支持灵活的自然语言问题,无需严格按照固定语法。
- 它可以根据数据库的架构以及数据库的内容(例如描述特定的表)回答问题。
适用场景:
- 数据分析与报告。
- 简化与数据库的交互。
- 提高业务用户的查询效率。
潜在问题:
如果数据库结构复杂(如跨表查询、多表关系),可能需要额外优化生成的 SQL 查询或调整模型提示语。
如果需要进一步定制问题模板或调整代理行为,可以继续优化.

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 15
15 0
0- 0



 已为社区贡献74条内容
已为社区贡献74条内容

所有评论(0)