自然语言处理实战:知识库问答系统开发项目
自然语言处理(NLP)是人工智能实现人机语言交互的关键技术,涵盖语法分析、语义理解、情感识别等多个层次。自20世纪50年代机器翻译起步以来,NLP历经规则系统、统计模型到深度学习的范式演进,尤其在预训练语言模型(如BERT)推动下,语义理解能力实现质的飞跃。面对“AIGC”、“Transformer”、“LoRA微调”等新兴术语,通用词典往往滞后。为此,需具备新词发现能力。

简介:本项目聚焦于自然语言处理(NLP)在知识库问答系统中的实际应用,涵盖从文本预处理到智能回答生成的完整流程。通过一系列教程、代码示例与数据集,学习者将掌握分词、停用词去除、词性标注、命名实体识别等基础技术,运用Word2Vec、BERT等词/句向量模型理解语义,并结合TF-IDF、BM25进行信息检索,利用seq2seq和Transformer架构实现答案生成。同时,项目包含BLEU、ROUGE等评估方法及模型调优策略,支持与Wikipedia等真实知识库集成,全面提升在机器人问答与对话系统领域的实战能力。 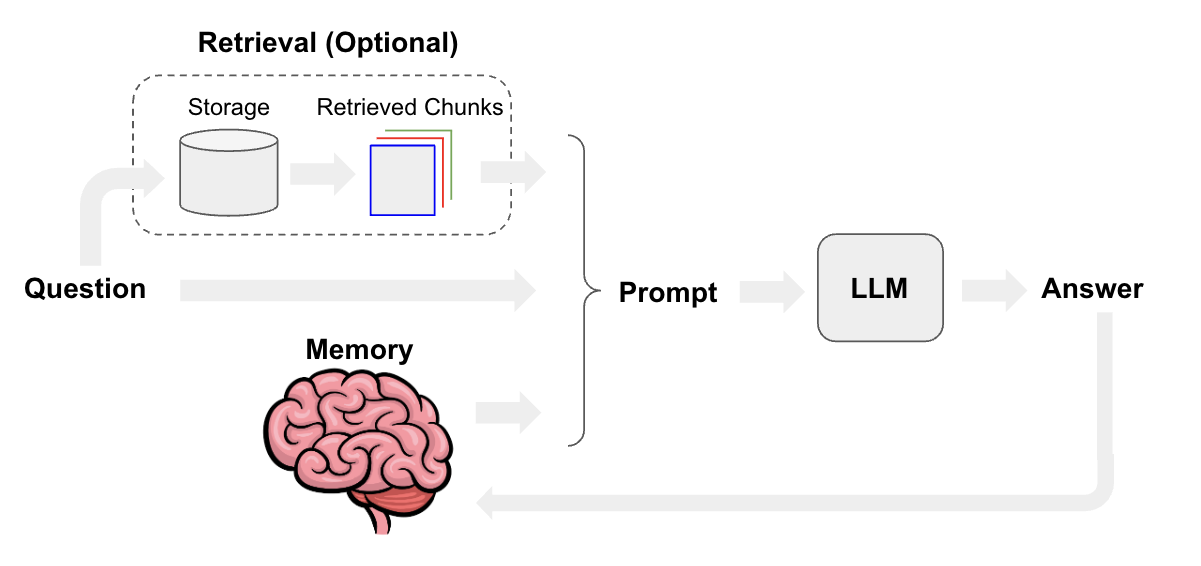
1. 自然语言处理基础理论与知识库问答系统概述
1.1 自然语言处理的核心概念与发展脉络
自然语言处理(NLP)是人工智能实现人机语言交互的关键技术,涵盖语法分析、语义理解、情感识别等多个层次。自20世纪50年代机器翻译起步以来,NLP历经规则系统、统计模型到深度学习的范式演进,尤其在预训练语言模型(如BERT)推动下,语义理解能力实现质的飞跃。
1.2 知识库问答系统的架构与优势
知识库问答系统(KBQA)通过将问题映射至结构化知识库(如Wikidata、DBpedia),利用语义解析或向量匹配技术生成精准答案。其核心在于“理解+推理”,区别于关键词匹配的传统搜索,具备更高的回答准确率与可解释性。
1.3 典型应用场景与系统构建流程
KBQA广泛应用于智能客服、企业知识中枢与教育辅助系统。典型构建流程包括:文本预处理 → 特征提取 → 语义建模 → 问题-答案匹配 → 结果生成与评估,形成闭环的技术 pipeline,为后续各章的实践提供整体框架指引。
2. 文本预处理与语言特征提取
在自然语言处理(NLP)系统中,原始文本数据往往包含大量噪声和不一致的格式,无法直接用于模型训练或语义分析。因此, 文本预处理与语言特征提取 是构建高质量NLP系统的基石环节。该阶段的核心目标是将非结构化的自然语言文本转换为干净、标准化且富含语义信息的结构化表示形式,从而为后续的分词、词性标注、语义建模与问答生成提供可靠的数据基础。
本章深入探讨从原始文本到可计算语言特征的完整转化路径,涵盖清洗、规范化、分词、停用词过滤、词性标注等多个关键技术模块。尤其针对中文这一无空格分隔、词汇边界模糊的语言体系,详细剖析其特有的技术挑战与解决方案,并结合主流工具库进行实战演示。整个流程不仅是数据准备的过程,更是对语言内在规律的一次系统性挖掘。
2.1 文本清洗与规范化处理
文本清洗是所有NLP任务的第一步,直接影响后续模型的表现。未经清洗的文本常含有HTML标签、特殊符号、乱码字符、大小写混杂等问题,这些都会干扰分词效果和语义理解。有效的清洗策略不仅能提升数据质量,还能显著减少模型训练中的噪声干扰。
2.1.1 标点符号、特殊字符与HTML标签的去除
自然语言文本来源广泛,如网页爬取内容通常嵌入大量HTML标签( <div> 、 <p> 、 等),社交媒体文本则充斥着表情符号、URL链接、@提及等非语言元素。若不加以清理,这些噪声会破坏分词逻辑,甚至误导模型学习错误的上下文关系。
以一段来自网页的知识片段为例:
<p>人工智能(AI)是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。<br>© 2024 技术百科全书</p>
其中 <p> 、 <br> 和 © 均为HTML实体或标签,不属于自然语言词汇,必须清除。Python中可通过正则表达式结合 BeautifulSoup 库高效实现:
from bs4 import BeautifulSoup
import re
def clean_html_tags_and_special_chars(text):
# 使用BeautifulSoup去除HTML标签
soup = BeautifulSoup(text, "html.parser")
text_no_html = soup.get_text()
# 移除HTML实体(如 , ©)
text_no_entities = re.sub(r'&[a-zA-Z]+;', '', text_no_html)
# 移除特殊字符:仅保留汉字、英文字母、数字、常见标点
cleaned_text = re.sub(r'[^\u4e00-\u9fa5\w\s.,!?;:]', '', text_no_html)
return cleaned_text.strip()
# 示例调用
raw_text = "<p>人工智能(AI)是计算机科学的一个分支...<br>© 2024 技术百科全书</p>"
cleaned = clean_html_tags_and_special_chars(raw_text)
print(cleaned)
代码逻辑逐行解读:
- 第3–4行:导入BeautifulSoup解析器,专用于解析HTML/XML文档。
- 第7行:soup.get_text()自动剥离所有标签,仅保留纯文本内容。
- 第10行:正则匹配形如&xxx;的HTML实体并替换为空字符串。
- 第13行:使用Unicode范围\u4e00-\u9fa5匹配中文字符,\w包含字母数字下划线,其余非法符号被移除。
- 返回值为清洗后的标准文本。
| 清洗前 | 清洗后 |
|---|---|
<p>AI改变了世界!<br>未来已来🔥</p> |
AI改变了世界!未来已来 |
网址:https://example.com?page=1 |
网址: |
参数说明:
-re.sub(pattern, repl, string):正则替换函数,pattern为匹配模式,repl是替代内容。
-\u4e00-\u9fa5:覆盖常用汉字编码区间。
- 可根据业务需求扩展允许字符集,例如保留括号、引号等语法符号。
graph TD
A[原始文本] --> B{是否含HTML?}
B -->|是| C[使用BeautifulSoup剥离标签]
B -->|否| D[跳过]
C --> E[移除HTML实体]
D --> F[正则过滤特殊字符]
E --> F
F --> G[输出纯净文本]
该流程图展示了从原始输入到标准化输出的完整清洗路径,确保不同来源的文本进入统一处理通道。
2.1.2 大小写统一与文本标准化策略
在英文为主的语料中,大小写差异会导致“Apple”与“apple”被视为两个不同的词,影响词频统计与向量化效果。虽然中文不存在大小写问题,但在混合语种场景下(如技术文档中夹杂英文术语),仍需统一规范。
通用做法是对英文字母执行小写转换:
def normalize_case(text):
return text.lower()
# 示例
mixed_text = "Natural Language Processing (NLP) is Key to AI."
normalized = normalize_case(mixed_text)
print(normalized) # natural language processing (nlp) is key to ai.
更进一步的 文本标准化 还包括:
- 全角转半角(适用于中文输入法产生的全角字符)
- 繁体转简体(面向跨区域应用)
- 缩写展开(如 “don’t” → “do not”)
以下是一个综合标准化函数示例:
import unicodedata
def full_to_half(s):
"""全角字符转半角"""
result = ''
for char in s:
code = ord(char)
if code == 0x3000: # 全角空格
code = 0x0020
elif 0xFF01 <= code <= 0xFF5E:
code -= 0xFEE0
result += chr(code)
return result
def normalize_text_comprehensive(text):
text = full_to_half(text) # 全角→半角
text = text.lower() # 统一小写
text = re.sub(r'\s+', ' ', text) # 多余空白合并
return text.strip()
逻辑分析:
-unicodedata模块可用于检测字符类别;
- 全角ASCII字符范围为FF01–FF5E,减去偏移量0xFEE0即得对应半角;
- 正则\s+合并多个空白符,防止因换行或制表符导致分词错位。
此策略特别适用于企业级知识库问答系统,保障术语一致性。
2.1.3 编码格式处理与异常字符修复
文本编码问题是数据集成过程中常见的隐患。UTF-8是最通用的编码格式,但部分老旧系统可能使用GBK、Big5或ISO-8859-1,导致读取时出现乱码(如“æ°æ®åº”)。此外,文件传输过程中的截断也可能引入不可打印字符。
建议采用如下鲁棒性读取方式:
def read_file_robust(file_path):
encodings = ['utf-8', 'gbk', 'gb2312', 'latin1']
for encoding in encodings:
try:
with open(file_path, 'r', encoding=encoding) as f:
content = f.read()
print(f"成功以 {encoding} 编码读取文件")
return content
except UnicodeDecodeError:
continue
raise ValueError("无法识别文件编码,请手动检查")
# 异常字符检测与替换
def remove_control_chars(text):
return ''.join(ch for ch in text if unicodedata.category(ch)[0] != 'C')
参数说明:
-unicodedata.category(ch)返回字符类别,控制字符类别以'C'开头(如Cc,Cf);
- 上述函数可清除\x00,\x1B等不可见控制符;
- 实际部署中应记录日志以便追溯异常源。
通过上述三步—— 去噪、归一、编码修复 ——我们构建了一个健壮的文本清洗管道,为后续处理打下坚实基础。
2.2 分词技术及中文分词难点
分词是将连续文本切分为有意义的语言单位(词语)的过程。英语天然以空格分隔单词,而中文缺乏明确边界,使得分词成为中文NLP的关键前置步骤。错误的切分将直接导致语义误解,例如将“南京市长江大桥”误分为“南京/市长/江大桥”,而非正确切分“南京市/长江大桥”。
2.2.1 基于规则与统计的分词方法对比
早期中文分词依赖 基于规则的方法 ,主要包括最大匹配法(Maximum Matching, MM)及其变体(正向/逆向/双向最大匹配)。这类方法依赖预定义词典,在封闭领域表现尚可,但难以应对新词、歧义和未登录词。
例如,使用逆向最大匹配算法(RMM)对句子“研究生命起源”进行切分:
def rmm_segment(sentence, word_dict, max_len=5):
result = []
while sentence:
end = len(sentence)
start = max(0, end - max_len)
matched = False
for i in range(start, end):
substr = sentence[i:end]
if substr in word_dict:
result.insert(0, substr)
sentence = sentence[:i]
matched = True
break
if not matched:
result.insert(0, sentence[-1])
sentence = sentence[:-1]
return result
# 词典示例
word_dict = {"研究", "研究生", "生命", "起源"}
sentence = "研究生命起源"
tokens = rmm_segment(sentence, word_dict)
print(tokens) # ['研究', '生命', '起源']
逻辑分析:
- 从右往左尝试最长匹配;
- 若“研究生”存在,则优先匹配五字词;
- 但由于“研究生”不在句中,退而匹配“研究”+“生命”;
- 存在局限:无法识别“生”是否独立成词。
相比之下, 基于统计的分词方法 (如隐马尔可夫模型 HMM、条件随机场 CRF)利用大规模语料学习切分概率,能够更好地处理歧义和未登录词。典型代表包括jieba使用的Viterbi算法+前缀树动态规划。
| 方法类型 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 规则法(MM/RMM) | 快速、无需训练 | 依赖词典、易出错 | 小规模固定领域 |
| 统计法(HMM/CRF) | 泛化能力强、支持新词 | 需要标注语料、计算开销大 | 开放域、复杂文本 |
现代工业级系统多采用 混合策略 :先用词典做粗粒度切分,再用统计模型优化边界。
2.2.2 使用Jieba、THULAC等工具进行中文分词实践
目前最流行的开源中文分词工具是 jieba 和 THULAC ,二者各有侧重。
Jieba 分词实战
import jieba
text = "深度学习推动了自然语言处理的发展"
seg_list = jieba.lcut(text)
print(seg_list)
# ['深度', '学习', '推动', '了', '自然', '语言', '处理', '的', '发展']
jieba支持三种模式:
- cut() :精确模式(默认)
- cut_for_search() :搜索引擎模式(更细粒度)
- Tokenize() :返回带位置信息的结果
还可添加自定义词:
jieba.add_word("大模型", freq=200, tag='n') # 添加名词“大模型”
THULAC 对比
THULAC由清华大学开发,集成分词与词性标注于一体,精度更高但速度略慢:
import thulac
thu = thulac.thulac(seg_only=False)
result = thu.cut("BERT是一种预训练语言模型", text=True)
print(result) # BERT/nz 是/vv 一种/m 预训练/vn 语言/n 模型/n
参数说明:
-seg_only=False表示同时输出词性和分词;
-text=True返回字符串格式;
- 支持用户词典加载:user_dict="mydict.txt"
两者对比如下表:
| 特性 | Jieba | THULAC |
|---|---|---|
| 易用性 | 极高 | 中等 |
| 准确率 | 高 | 更高 |
| 是否支持词性标注 | 可扩展 | 内建支持 |
| 新词发现 | 基于TF-IDF | 基于统计模型 |
| 社区活跃度 | 非常高 | 较高 |
推荐在快速原型开发中使用 jieba ,在高精度要求场景选用 THULAC 。
flowchart LR
A[原始中文文本] --> B{选择分词工具}
B --> C[jieba: 轻量高效]
B --> D[THULAC: 高精度一体化]
C --> E[分词结果]
D --> F[分词+词性标注]
E --> G[送入下游NLP模块]
F --> G
2.2.3 新词发现与自定义词典集成
面对“AIGC”、“Transformer”、“LoRA微调”等新兴术语,通用词典往往滞后。为此,需具备 新词发现能力 。
jieba提供基于TF-IDF和TextRank的新词提取功能:
from jieba import analyse
text_corpus = """
近年来,大模型技术飞速发展,Transformer架构成为主流。
研究人员提出了多种微调方法,如LoRA、Adapter等。
# 基于TF-IDF提取关键词
keywords_tfidf = analyse.extract_tags(text_corpus, topK=5, withWeight=True)
print("TF-IDF关键词:", keywords_tfidf)
# 基于TextRank提取
keywords_textrank = analyse.textrank(text_corpus, topK=5, withWeight=True)
print("TextRank关键词:", keywords_textrank)
输出示例:
TF-IDF关键词: [('Transformer', 2.15), ('大模型', 1.98), ('微调', 1.67), ('LoRA', 1.55), ('架构', 1.43)]
TextRank关键词: [('Transformer', 0.88), ('大模型', 0.85), ('微调', 0.79), ...]
这些高频新词可加入自定义词典:
# 写入自定义词典文件
with open("custom_dict.txt", "w", encoding="utf-8") as f:
for word, _ in keywords_tfidf:
f.write(f"{word}\n")
# 加载词典
jieba.load_userdict("custom_dict.txt")
逻辑分析:
-extract_tags使用词频与逆文档频率加权;
-textrank借鉴PageRank思想,基于共现关系排序;
- 权重越高,越可能是领域关键新词;
- 动态更新词典可使系统持续适应技术演进。
2.3 停用词过滤与词汇精简
尽管分词后得到词语序列,但其中包含大量无实际语义贡献的虚词,如“的”、“了”、“在”、“this”、“is”等,统称为 停用词(Stop Words) 。保留它们不仅增加计算负担,还可能稀释关键语义信号。
2.3.1 常见停用词表的选择与优化
常用的停用词表包括:
- 中文:哈工大停用词表、四川大学SWE分词系统词表
- 英文:NLTK内置列表、Snowball词表
加载并应用停用词表示例:
def load_stopwords(filepath):
with open(filepath, 'r', encoding='utf-8') as f:
stopwords = set(line.strip() for line in f if line.strip())
return stopwords
def filter_stopwords(tokens, stopwords):
return [t for t in tokens if t not in stopwords]
# 示例
stopwords = load_stopwords("data/stopwords.txt")
filtered = filter_stopwords(["自然", "语言", "处理", "的", "发展"], stopwords)
print(filtered) # ['自然', '语言', '处理', '发展']
参数说明:
- 使用set提升查找效率(O(1));
- 注意去除换行符与空白;
- 可组合多份词表增强覆盖率。
然而,通用停用词表并非万能。例如在情感分析中,“不”虽属虚词,却是否定语义的关键;在法律文本中,“之”可能承载特定语法功能。
因此, 停用词表应根据任务动态调整 。
2.3.2 领域适配型停用词库构建
理想做法是构建 领域专用停用词库 。可通过以下方式实现:
- 词频分析法 :统计语料中极高频但低信息量的词;
- 互信息(MI)筛选 :衡量词语与类别标签的相关性;
- 人工审核+自动化迭代 。
示例:计算词频分布
from collections import Counter
all_tokens = sum(corpus_tokenized, []) # 扁平化所有文档词汇
freq_dist = Counter(all_tokens)
# 查看最高频的50个词
most_common = freq_dist.most_common(50)
for word, cnt in most_common:
print(f"{word}: {cnt}")
观察输出后,手动剔除无意义高频词,形成定制化停用词表。
也可借助 sklearn 自动生成候选:
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(max_features=1000, stop_words=None)
X = vectorizer.fit_transform(documents)
low_idf_words = [
word for word, idx in vectorizer.vocabulary_.items()
if vectorizer.idf_[idx] < 1.5
]
# 这些idf值极低的词可能是真正的停用词
最终形成的领域词表可大幅提升问答系统的关键词召回准确率。
2.4 词性标注与语言结构分析
词性标注(Part-of-Speech Tagging, POS)是指为每个词语赋予语法类别标签(如名词、动词、形容词等),是深层语言理解的基础。在问答系统中,POS有助于识别问题类型(如“谁”对应人物名词)、答案候选(如数值、时间、地点)以及句法依存关系。
2.4.1 HMM与CRF在词性标注中的应用原理
隐马尔可夫模型(HMM)
HMM假设观测序列(词语)由隐藏状态序列(词性)生成。其核心参数包括:
- 初始概率 $ \pi(i) = P(t_1 = i) $
- 转移概率 $ a(i,j) = P(t_{k}=j | t_{k-1}=i) $
- 发射概率 $ b(i,o) = P(w_k=o | t_k=i) $
通过维特比(Viterbi)算法解码最优词性路径。
条件随机场(CRF)
相比HMM的生成式建模,CRF是判别式模型,直接建模条件概率 $ P(T|W) $,能灵活引入上下文特征(如前后词、大小写、词缀等),性能更优。
CRF公式:
P(T|W) = \frac{1}{Z(W)} \exp\left( \sum_{k,i} \lambda_i f_i(t_{k-1}, t_k, w_k, k) \right)
其中 $ f_i $ 为特征函数,$ \lambda_i $ 为权重。
主流工具如Stanford NLP、LTP均采用CRF++或神经网络架构实现高精度标注。
2.4.2 利用Stanford NLP和LTP实现词性标注实战
Stanford CoreNLP 示例(Java + Python接口)
需启动服务器或使用 stanza 库:
import stanza
# 下载一次即可
# stanza.download('zh')
nlp = stanza.Pipeline('zh', processors='tokenize,pos')
doc = nlp("深度学习是一种人工智能技术")
for sent in doc.sentences:
for word in sent.words:
print(f"{word.text}\t{word.pos}")
输出:
深度 NN
学习 NN
是 COP
一种 M
人工 JJ
智能 NN
技术 NN
LTP 工具调用
from ltp import LTP
ltp = LTP()
seg, hidden = ltp.seg(["深度学习是AI的核心"])
pos = ltp.pos(hidden)
print(pos) # [['NN', 'NN', 'VC', 'NR', 'DEG', 'NN']]
优势对比:
- Stanza :国际化支持好,模型轻量;
- LTP :中文优化强,适合国内应用场景;
- 均支持批量处理与GPU加速。
graph TB
A[原始句子] --> B[分词]
B --> C[词性标注]
C --> D{下游任务}
D --> E[命名实体识别]
D --> F[依存句法分析]
D --> G[问答意图识别]
词性标注作为中间层特征,为高层语义解析提供了结构性支撑,是构建精准KBQA系统不可或缺的一环。
3. 语义表示模型的构建与实现
在自然语言处理系统中,语义表示是连接原始文本与高层任务(如问答、分类、翻译)的核心桥梁。传统方法依赖词袋模型或TF-IDF等静态特征表示,难以捕捉词汇间的语义关联和上下文动态变化。随着深度学习的发展,语义表示技术经历了从稀疏离散到稠密连续、从静态固定到上下文敏感的深刻变革。本章系统阐述现代语义表示模型的技术演进路径,涵盖从早期的分布式词向量(Word2Vec、GloVe)到基于深度神经网络的上下文感知编码器(ELMo、BERT),并深入解析其内部机制与工程实现方式。通过理论分析与代码实践相结合的方式,展示如何在真实场景中构建高效、可迁移的语义表示模块,为后续问答系统的语义匹配与推理能力提供坚实支撑。
3.1 词嵌入技术:从One-Hot到分布式表示
词嵌入(Word Embedding)是指将自然语言中的词汇映射为低维实数向量的过程,其核心思想源于分布假设(Distributional Hypothesis)——“具有相似上下文的词具有相似含义”。这一理念推动了从传统的One-Hot编码向分布式表示的转变。One-Hot表示虽简单直观,但存在维度灾难、无法表达语义关系等问题。相比之下,词嵌入通过降维学习,不仅大幅压缩了特征空间,还能自动捕捉同义、反义、类比等多种语义关系,成为现代NLP系统的基石。
3.1.1 Word2Vec模型原理:CBOW与Skip-gram架构解析
Word2Vec由Mikolov等人于2013年提出,包含两种主要结构:连续词袋模型(Continuous Bag-of-Words, CBOW)和跳字模型(Skip-gram)。两者均基于局部上下文预测目标词或反之,利用浅层神经网络进行训练。
CBOW模型通过上下文词(前后若干个词)来预测当前中心词。其输入为上下文词的词向量平均值,输出为词汇表中各词的概率分布。该模型适合高频词且训练速度快,但在处理低频词时泛化能力较弱。而Skip-gram则相反,它以一个中心词作为输入,预测其周围的上下文词。由于每次只预测多个邻居词,因此对稀有词更具鲁棒性,尤其适用于小规模语料库。
两种模型均采用负采样(Negative Sampling)或层次Softmax优化训练效率,避免全词汇表softmax带来的计算开销。负采样的核心思想是在每轮训练中仅更新真实上下文词及其少量随机采样的“噪声”词,从而极大降低梯度计算复杂度。例如,在一个百万级词汇表中,原本需要计算百万项概率,使用负采样后只需更新几十个词即可完成一次迭代。
以下为CBOW模型前向传播过程的数学形式化描述:
设中心词为 $ w_t $,上下文窗口大小为 $ C $,上下文词集合为 $ {w_{t-C}, …, w_{t-1}, w_{t+1}, …, w_{t+C}} $,每个词对应的词向量为 $ v(w_i) \in \mathbb{R}^d $,则上下文向量表示为:
\bar{v} = \frac{1}{2C} \sum_{-C \leq j \leq C, j \neq 0} v(w_{t+j})
随后经过隐藏层(无非线性激活)得到:
h = W^T \bar{v}
其中 $ W $ 为权重矩阵。最终输出层使用Softmax:
P(w_t | context) = \frac{\exp(u_{w_t}^T h)}{\sum_{w’ \in V} \exp(u_{w’}^T h)}
其中 $ u_w $ 是输出词向量。
Skip-gram模型则是反过来,给定中心词 $ w_t $,最大化其上下文词的联合概率:
\prod_{-C \leq j \leq C, j \neq 0} P(w_{t+j} | w_t)
这两种架构的选择取决于具体应用场景:若追求速度和内存效率,CBOW更优;若关注低频词表现和语义精度,则优先选择Skip-gram。
from gensim.models import Word2Vec
from gensim.utils import simple_preprocess
# 示例语料
sentences = [
"人工智能正在改变世界".split(),
"深度学习是AI的关键技术".split(),
"自然语言处理让机器理解人类语言".split(),
"知识库问答系统提升信息获取效率".split()
]
# 构建并训练Word2Vec模型(Skip-gram)
model = Word2Vec(
sentences=sentences,
vector_size=100, # 词向量维度
window=5, # 上下文窗口大小
min_count=1, # 忽略出现次数少于min_count的词
sg=1, # 1表示Skip-gram,0表示CBOW
workers=4, # 并行线程数
epochs=10 # 训练轮数
)
# 查询词向量
vec_ai = model.wv['人工智能']
print(f"‘人工智能’的词向量形状: {vec_ai.shape}")
# 查找最相似词
similar_words = model.wv.most_similar('人工智能', topn=3)
print("与‘人工智能’最相似的词:", similar_words)
代码逻辑逐行解读:
simple_preprocess可用于英文文本清洗,中文需自行分词(此处已手动分词);vector_size=100指定向量空间维度,通常设置为50~300之间;window=5表示考虑前后最多5个词作为上下文;sg=1明确指定使用Skip-gram架构;epochs=10控制训练遍历语料的次数,影响收敛效果;model.wv.most_similar()利用余弦相似度计算词间语义接近程度。
| 参数 | 含义 | 推荐取值范围 |
|---|---|---|
vector_size |
词向量维度 | 50–300 |
window |
上下文窗口大小 | 3–10 |
min_count |
最小词频阈值 | 1–5 |
sg |
模型类型(0=CBOW, 1=Skip-gram) | 0 或 1 |
epochs |
训练轮数 | 5–20 |
该模型可在小型领域语料上快速构建定制化词向量,显著优于通用预训练模型在特定任务上的适配性。
graph TD
A[原始文本] --> B[分词处理]
B --> C[构建句子序列]
C --> D[滑动窗口提取上下文]
D --> E{选择模型架构}
E -->|CBOW| F[平均上下文向量 → 预测中心词]
E -->|Skip-gram| G[中心词 → 预测上下文词]
F --> H[负采样优化损失函数]
G --> H
H --> I[训练完成,获得词向量矩阵]
I --> J[应用于下游任务]
上述流程图清晰展示了Word2Vec的整体训练流程,强调了数据预处理、模型选择与优化策略之间的逻辑关系。
3.1.2 使用Gensim训练定制化Word2Vec模型
在实际项目中,通用词向量(如Google News预训练模型)往往无法充分覆盖垂直领域的术语(如医学、法律)。因此,基于自有语料训练定制化Word2Vec模型至关重要。Gensim库提供了简洁高效的接口,支持大规模语料流式训练,无需将全部数据加载至内存。
首先需准备高质量的领域文本语料。例如,在医疗问答系统中,可收集电子病历、医学论文摘要、药品说明书等文本,并进行标准化预处理(去噪、分词、去除停用词)。然后按句子单位组织成迭代器形式,以便Gensim逐步读取。
import logging
from gensim.models import Word2Vec
from smart_open import open # 支持大文件流式读取
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
class SentenceIterator:
def __init__(self, filepath):
self.filepath = filepath
def __iter__(self):
with open(self.filepath, 'r', encoding='utf-8') as f:
for line in f:
yield simple_preprocess(line.strip())
# 假设语料存储在本地文件中
sentences = SentenceIterator('medical_corpus.txt')
# 开始训练
model = Word2Vec(
sentences,
vector_size=200,
window=8,
min_count=3,
sg=1,
workers=6,
epochs=15,
negative=10, # 负样本数量
ns_exponent=0.75 # 负采样指数,控制频率偏差
)
# 保存模型
model.save("medical_word2vec.model")
参数说明:
negative=10:设置负采样数量,默认为5,增加可提高低频词学习质量;ns_exponent=0.75:调整负样本采样分布,使其更倾向于低频词;workers=6:充分利用多核CPU加速训练;epochs=15:保证充分收敛,尤其当语料较大时。
训练完成后,可通过可视化手段评估词向量质量。例如使用t-SNE降维将高维词向量投影到二维平面,观察同类词是否聚集成簇。
此外,还可结合 analogy task(类比推理)测试模型语义能力,如:“医生之于医院,如同教师之于?” 若模型能正确推断出“学校”,说明其具备良好的结构化语义理解能力。
3.1.3 GloVe模型的全局共现矩阵思想与实现对比
斯坦福大学提出的GloVe(Global Vectors for Word Representation)模型不同于Word2Vec的局部上下文预测机制,而是基于全局词共现统计构建词向量。其核心思想是:词之间的语义关系可以通过它们在整个语料中共同出现的频率模式来揭示。
GloVe显式构造一个巨大的词-词共现矩阵 $ X $,其中 $ X_{ij} $ 表示词 $ i $ 在词 $ j $ 的上下文中出现的次数。然后定义目标函数最小化如下损失:
J = \sum_{i,j=1}^V f(X_{ij}) (w_i^T \tilde{w} j + b_i + \tilde{b}_j - \log X {ij})^2
其中 $ w_i $ 和 $ \tilde{w}_j $ 分别是词 $ i $ 的输入和输出向量,$ b, \tilde{b} $ 为偏置项,$ f $ 为加权函数,用于抑制高频共现对损失的影响。
相比Word2Vec,GloVe的优势在于:
- 全局信息利用更充分 :不仅依赖局部上下文滑动窗口,还整合了整个语料的统计规律;
- 训练更稳定 :基于矩阵分解思想,优化过程更具确定性;
- 适合静态词向量场景 :在不需要上下文敏感表示的任务中表现优异。
然而,GloVe也存在明显局限:无法直接生成上下文相关的动态词向量,且训练所需内存随词汇量平方增长,难以扩展至超大规模语料。
以下为使用官方GloVe实现(需编译C代码)或通过Python封装库(如 glove-python )训练的简化示例:
# 下载并编译GloVe源码
git clone http://github.com/stanfordnlp/glove
cd glove/src && make
# 准备共现矩阵
./cooccur -memory 4.0 -vocab-file vocab.txt -verbose 2 -window-size 10 < corpus.txt > cooccurrence.bin
# 构建词汇表
./vocab_count -min-count 5 -verbose 2 < corpus.txt > vocab.txt
# 训练词向量
./glove -save-file glove_vectors -threads 8 -input-file cooccurrence.bin -x-max 10 -iter 15 -vector-size 200 -binary 2 -vocab-file vocab.txt -verbose 2
尽管命令行操作繁琐,但其底层逻辑清晰:先统计词汇频次,再构建共现矩阵,最后运行GloVe算法求解词向量。
| 特性 | Word2Vec | GloVe |
|---|---|---|
| 学习方式 | 局部上下文预测 | 全局共现矩阵分解 |
| 是否支持上下文敏感 | 否 | 否 |
| 内存消耗 | 较低 | 高($ O(V^2) $) |
| 训练速度 | 快 | 中等 |
| 语义类比性能 | 优秀 | 更优(部分任务) |
总体而言,GloVe在某些语义任务上略胜一筹,但Word2Vec因其实现简便、资源友好而在工业界更为普及。
3.2 上下文敏感的深度语义编码
传统词嵌入(如Word2Vec、GloVe)为每个词分配唯一固定的向量,忽略了词语在不同语境下的多义性问题。例如,“苹果”在“吃苹果”和“投资苹果公司”中含义迥异。为此,新一代语义编码模型引入上下文感知机制,生成动态词向量,显著提升了语义表示的准确性。
3.2.1 ELMo模型的双向LSTM结构与动态词向量生成
Embeddings from Language Models(ELMo)由Allen Institute提出,首次实现了真正意义上的上下文敏感词表示。其核心架构基于两层双向LSTM(Bi-LSTM),分别从前向和后向两个方向建模句子序列。
对于输入句子 $ t_1, t_2, …, t_n $,ELMo首先通过字符级CNN将每个词转换为初始向量 $ x_k^{(0)} $,然后送入第一层Bi-LSTM:
\overrightarrow{h} k^{(1)} = \overrightarrow{LSTM}^{(1)}(\overrightarrow{h} {k-1}^{(1)}, x_k^{(0)})
\overleftarrow{h} k^{(1)} = \overleftarrow{LSTM}^{(1)}(\overleftarrow{h} {k+1}^{(1)}, x_k^{(0)})
拼接后得:
h_k^{(1)} = [\overrightarrow{h}_k^{(1)}; \overleftarrow{h}_k^{(1)}]
第二层以此类推,最终将三层表示(输入层 + 两层LSTM)加权融合:
\text{ELMo}_k = \gamma (\alpha_0 x_k^{(0)} + \alpha_1 h_k^{(1)} + \alpha_2 h_k^{(2)})
其中 $ \gamma $ 和 $ \alpha_i $ 为可学习参数。
这种深层结构使ELMo能够捕获语法与语义层次特征,且同一词在不同句中拥有不同向量表示。
import torch
from allennlp.modules.elmo import Elmo, batch_to_ids
options_file = "https://allennlp.s3.amazonaws.com/models/elmo/2x4096_512_2048cnn_2xhighway_options.json"
weight_file = "https://allennlp.s3.amazonaws.com/models/elmo/2x4096_512_2048cnn_2xhighway_weights.hdf5"
elmo = Elmo(options_file, weight_file, 2, dropout=0)
# 输入句子列表
sentences = [['I', 'ate', 'an', 'apple'], ['Apple', 'is', 'a', 'tech', 'company']]
character_ids = batch_to_ids(sentences)
embeddings = elmo(character_ids)
elmo_tensor = embeddings['elmo_representations'][1] # 第二层输出
print(elmo_tensor.shape) # [2, max_length, 1024]
执行说明:
batch_to_ids将词转为字符ID序列;- 输出包含两层Bi-LSTM的表示,可根据任务选择融合方式;
- 每个词的向量随上下文动态变化,解决一词多义问题。
3.2.2 BERT模型的Transformer Encoder机制详解
BERT(Bidirectional Encoder Representations from Transformers)采用纯Transformer Encoder架构,通过掩码语言建模(Masked Language Model, MLM)实现真正的双向上下文理解。其输入由三部分组成:Token Embedding、Segment Embedding 和 Position Embedding 相加而成。
在MLM任务中,随机遮蔽15%的输入token(如用[MASK]替代),模型需根据上下文预测原词。同时引入下一句预测(Next Sentence Prediction, NSP)任务辅助句子关系判断。
BERT的最大创新在于自注意力机制(Self-Attention):
\text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V
允许每个位置直接关注任意其他位置,克服了RNN的序列依赖瓶颈。
3.2.3 利用Hugging Face Transformers加载预训练BERT模型
from transformers import BertTokenizer, BertModel
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertModel.from_pretrained('bert-base-chinese')
text = "自然语言处理很有趣"
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
print(last_hidden_states.shape) # [1, seq_len, 768]
此代码加载中文BERT模型,输出每个token的上下文化向量,可用于问答、分类等任务。
graph LR
A[输入文本] --> B[分词 + 添加特殊标记]
B --> C[Token/Segment/Position嵌入相加]
C --> D[多层Transformer Encoder]
D --> E[自注意力机制更新表征]
E --> F[输出上下文向量]
F --> G[用于下游任务]
表格对比主流语义模型特性:
| 模型 | 是否上下文敏感 | 架构 | 预训练任务 | 适用场景 |
|---|---|---|---|---|
| Word2Vec | 否 | 浅层网络 | Skip-gram/CBOW | 通用词相似度 |
| GloVe | 否 | 矩阵分解 | 共现矩阵重构 | 文本分类 |
| ELMo | 是 | Bi-LSTM | 语言建模 | 多义词处理 |
| BERT | 是 | Transformer | MLM + NSP | QA、NER、推理 |
这些模型构成了现代语义表示的技术谱系,可根据资源条件与任务需求灵活选用。
3.3 句向量生成与语义相似度计算
3.3.1 平均词向量、Sentence-BERT等句向量构造方法
句子级别的语义表示需聚合词向量。最简单方法是取词向量平均:
sentence_vec = np.mean([model.wv[w] for w in tokens if w in model.wv], axis=0)
但忽略词序与权重。
Sentence-BERT改进方案:使用Siamese网络结构微调BERT,直接生成固定长度句向量。支持语义相似度任务。
3.3.2 在问答匹配任务中应用余弦相似度进行候选答案筛选
from sklearn.metrics.pairwise import cosine_similarity
query_vec = sbert.encode("如何训练BERT?")
answer_vecs = sbert.encode(answer_list)
scores = cosine_similarity([query_vec], answer_vecs)[0]
best_idx = scores.argmax()
通过计算问句与候选答案的余弦相似度,快速筛选最相关回答,构成KBQA的第一阶段召回机制。
4. 问答系统核心算法与模型训练
现代知识库问答系统的性能高度依赖于底层算法的精准性与模型训练的有效性。随着深度学习技术的发展,传统的基于规则和统计的方法逐渐被神经网络驱动的端到端架构所取代。本章聚焦于构建高效、可扩展的问答系统所需的核心算法设计与模型训练策略,深入探讨从信息检索到答案生成的全流程技术实现路径。重点围绕候选文档召回机制、序列建模能力提升以及Transformer在问答任务中的高级应用展开分析,并结合实际代码示例与优化技巧,帮助开发者掌握如何在真实场景中部署具备语义理解能力的智能问答系统。
不同于通用搜索仅返回相关网页链接,问答系统要求模型能够准确识别用户意图并生成结构化或自然语言形式的答案。为此,系统通常分为两个阶段: 第一阶段为候选召回(Retrieval) ,通过高效的文本匹配算法快速筛选出与问题最相关的若干段落; 第二阶段为精排与生成(Reader/Generator) ,利用深度语义模型对候选内容进行细粒度推理,最终输出精确回答。这种“两步走”架构已成为当前主流问答系统的标准范式,尤其适用于大规模知识库环境下的实时响应需求。
为了支撑这一复杂流程,必须精心设计每一个模块的算法选型与训练方式。例如,在召回阶段,BM25等经典信息检索算法因其高效率和无需训练的特点仍被广泛采用;而在生成阶段,基于Seq2Seq或预训练语言模型(如BERT)的神经网络则展现出更强的语言理解和生成能力。此外,合理的超参数配置、学习率调度策略以及正则化手段也直接影响模型收敛速度与泛化能力。因此,本章将系统解析这些关键技术环节,并通过PyTorch实战代码演示关键组件的构建过程,确保理论与实践紧密结合。
4.1 信息检索模块设计:基于TF-IDF与BM25的候选文档召回
在知识库问答系统中,面对海量文本数据,直接对所有文档进行语义匹配计算是不可行的。因此,第一步通常是使用轻量级但高效的 信息检索(Information Retrieval, IR)模块 来完成初步筛选,即从整个知识库中快速找出与输入问题最相关的若干文档片段或段落,作为后续深度模型处理的输入。该过程被称为“候选文档召回”,其目标是在保证召回率的同时尽可能减少计算开销。目前主流方法主要包括 TF-IDF + 向量空间模型(VSM) 和 BM25排序函数 ,二者均属于词频驱动的经典IR技术,具有实现简单、运行高效的优势。
4.1.1 TF-IDF权重计算与向量化表示
TF-IDF(Term Frequency-Inverse Document Frequency)是一种经典的文本加权统计方法,用于衡量一个词语在文档中的重要程度。它由两部分组成:
- TF(词频) :某个词在文档中出现的频率;
- IDF(逆文档频率) :反映该词在整个语料库中的稀有程度,越少见的词IDF值越高。
其数学表达式如下:
\text{TF-IDF}(t,d,D) = \text{TF}(t,d) \times \log\left(\frac{N}{|{d’ \in D : t \in d’}|}\right)
其中:
- $ t $ 是词语,
- $ d $ 是当前文档,
- $ D $ 是文档集合,
- $ N $ 是文档总数。
该公式意味着:一个词如果在某文档中频繁出现(高TF),但在整个语料中不常见(高IDF),那么它对该文档的主题代表性就越强。
实现代码与逻辑分析
以下是一个基于 scikit-learn 的 TF-IDF 向量化实现示例:
from sklearn.feature_extraction.text import TfidfVectorizer
import numpy as np
# 示例知识库文档
documents = [
"人工智能是计算机科学的一个分支",
"自然语言处理让机器理解人类语言",
"深度学习使用神经网络模拟人脑",
"问答系统可以自动回答用户的问题"
]
# 构建TF-IDF向量化器
vectorizer = TfidfVectorizer(
token_pattern=r"(?u)\b\w+\b", # 支持中文分词后输入
max_features=1000,
stop_words=None # 可替换为自定义停用词表
)
# 拟合并转换文档为TF-IDF矩阵
tfidf_matrix = vectorizer.fit_transform(documents)
# 输出词汇表及其索引
print("词汇表(前10个):", list(vectorizer.vocabulary_.keys())[:10])
# 查询向量化(假设用户提问)
query = "机器如何理解人类语言"
query_vec = vectorizer.transform([query])
# 计算余弦相似度
from sklearn.metrics.pairwise import cosine_similarity
similarity = cosine_similarity(query_vec, tfidf_matrix)
print("各文档相似度:", similarity[0])
代码逻辑逐行解读:
TfidfVectorizer: 初始化向量化工具,支持正则分词模式以兼容中文。token_pattern=r"(?u)\b\w+\b": 使用Unicode单词边界匹配,适配中文分词结果。max_features=1000: 控制特征维度,防止过拟合。fit_transform(documents): 对文档集进行拟合并生成稀疏TF-IDF矩阵。transform([query]): 将查询句映射到同一向量空间。cosine_similarity: 计算查询与每篇文档之间的语义接近度。
⚠️ 注意:此方法未集成中文分词,实际应先用 Jieba 分词后再传入。
参数说明与调优建议:
| 参数 | 作用 | 推荐设置 |
|---|---|---|
ngram_range |
控制n-gram范围 | (1,2) 提升短语匹配能力 |
min_df |
忽略低频词 | 2 避免噪声干扰 |
max_df |
忽略高频停用词 | 0.8 自动过滤常见词 |
4.1.2 BM25算法参数调优与在大规模知识库中的应用
尽管TF-IDF已被广泛应用,但它存在明显缺陷: 无法有效处理词项长度偏差和极端词频放大问题 。相比之下, BM25(Best Matching 25) 是一种更先进的概率检索模型,能够自动平衡词频饱和效应与文档长度归一化,因此在工业级问答系统中表现更优。
BM25得分公式如下:
\text{score}(q,d) = \sum_{i=1}^{n} \text{IDF}(q_i) \cdot \frac{f(q_i,d) \cdot (k_1 + 1)}{f(q_i,d) + k_1 \cdot \left(1 - b + b \cdot \frac{|d|}{\text{avgdl}}\right)}
其中:
- $ f(q_i,d) $:词项 $ q_i $ 在文档 $ d $ 中的出现次数;
- $ |d| $:文档长度;
- $ \text{avgdl} $:语料平均文档长度;
- $ k_1 \in [1.2, 2.0] $:控制词频饱和程度;
- $ b \in [0.5, 0.9] $:控制文档长度归一化强度。
Mermaid 流程图:BM25召回流程
graph TD
A[用户提问] --> B{是否已分词?}
B -- 是 --> C[提取查询词项]
B -- 否 --> D[Jieba分词+去停用词]
D --> C
C --> E[遍历知识库文档]
E --> F[计算每个文档BM25得分]
F --> G[按得分排序取Top-K]
G --> H[输出候选文档列表]
H --> I[送入下游语义模型]
Python 实现 BM25(使用 rank-bm25 库)
pip install rank-bm25
from rank_bm25 import BM25Okapi
import jieba
# 原始文档列表
raw_docs = [
"人工智能是计算机科学的重要方向",
"自然语言处理帮助机器理解人类语言",
"深度学习依赖大量数据和算力",
"问答系统需要语义理解和生成能力"
]
# 中文分词处理
tokenized_docs = [list(jieba.cut(doc)) for doc in raw_docs]
# 构建BM25模型
bm25 = BM25Okapi(tokenized_docs)
# 用户查询
query_text = "机器如何理解人的语言"
query_tokens = list(jieba.cut(query_text))
# 获取得分
doc_scores = bm25.get_scores(query_tokens)
print("BM25 得分:", doc_scores)
# 获取Top-2结果
top_n = bm25.get_top_n(query_tokens, raw_docs, n=2)
print("Top 2 文档:", top_n)
代码逻辑分析:
jieba.cut(): 对中文文本进行分词处理;BM25Okapi(tokenized_docs): 构造BM25模型,自动计算IDF并缓存文档长度信息;get_scores(): 返回所有文档的BM25得分;get_top_n(): 直接获取排名前N的结果。
调参建议:
| 参数 | 默认值 | 推荐调整范围 | 影响 |
|---|---|---|---|
k1 |
1.5 | 1.2 ~ 2.0 | 控制词频增长速率 |
b |
0.75 | 0.6 ~ 0.9 | 平衡长文档惩罚 |
可通过交叉验证在开发集上选择最优组合。
表格对比:TF-IDF vs BM25
| 特性 | TF-IDF | BM25 |
|---|---|---|
| 是否考虑文档长度 | 否 | 是(通过$b$参数) |
| 词频处理方式 | 线性增长 | 饱和式增长(更合理) |
| 数学基础 | 启发式加权 | 概率相关性模型 |
| 实现复杂度 | 简单 | 中等 |
| 工业适用性 | 一般 | 高(搜索引擎常用) |
| 可调参数 | 少 | 多(k1, b) |
✅ 实践建议:在小型项目中可优先使用TF-IDF快速验证;在生产环境中推荐采用BM25提升召回质量。
4.2 深度学习回答生成模型实战
当完成候选文档召回后,下一步是利用深度学习模型从候选文本中抽取或生成准确答案。这类模型不再依赖关键词匹配,而是基于语义理解进行推理。本节重点介绍基于 Seq2Seq 架构 的生成式问答模型,特别是引入注意力机制后的性能跃升,并通过 PyTorch 实现完整训练流程。
4.2.1 Seq2Seq架构中的编码器-解码器机制
Sequence-to-Sequence(Seq2Seq)模型最早应用于机器翻译任务,其核心思想是将输入序列(如问题)编码为固定长度的上下文向量,再由解码器逐步生成输出序列(如答案)。该结构天然适用于问答任务,尤其是当答案需重新组织语言而非直接抽取时。
典型结构包括:
- 编码器(Encoder) :通常为RNN/LSTM/GRU,读取问题和上下文,输出隐藏状态序列;
- 解码器(Decoder) :同样为RNN结构,以上一步输出和上下文向量为输入,逐词生成答案。
但由于原始Seq2Seq存在“信息瓶颈”问题——即整个输入信息压缩至单一向量,导致长距离依赖丢失,因此需引入注意力机制加以改进。
4.2.2 注意力机制引入与模型性能提升
注意力机制允许解码器在每一步动态关注编码器的不同时间步输出,从而缓解信息压缩带来的损失。具体而言,每个解码时刻 $ t $ 会计算一组注意力权重 $ \alpha_{t,i} $,表示第 $ i $ 个编码输出对当前预测的重要性。
注意力得分常用点积或加性方式计算:
e_{ti} = \text{score}(s_{t-1}, h_i), \quad \alpha_{ti} = \frac{\exp(e_{ti})}{\sum_j \exp(e_{tj})}
最终上下文向量为加权和:
c_t = \sum_i \alpha_{ti} h_i
这使得模型能“聚焦”于最相关的输入部分,显著提升生成质量。
4.2.3 使用PyTorch搭建端到端生成式问答模型
下面是一个简化版的带注意力机制的Seq2Seq问答模型实现:
import torch
import torch.nn as nn
class Attention(nn.Module):
def __init__(self, hidden_size):
super().__init__()
self.attn = nn.Linear(hidden_size * 2, hidden_size)
self.v = nn.Linear(hidden_size, 1, bias=False)
def forward(self, hidden, encoder_outputs):
# hidden: (batch_size, 1, hidden_size)
# encoder_outputs: (batch_size, seq_len, hidden_size)
seq_len = encoder_outputs.size(1)
hidden_expanded = hidden.expand(-1, seq_len, -1)
energy = torch.tanh(self.attn(torch.cat([hidden_expanded, encoder_outputs], dim=2)))
attention = self.v(energy).squeeze(2)
return torch.softmax(attention, dim=1)
class Seq2SeqAttn(nn.Module):
def __init__(self, vocab_size, emb_dim, hidden_dim, num_layers=1):
super().__init__()
self.embedding = nn.Embedding(vocab_size, emb_dim)
self.encoder = nn.LSTM(emb_dim, hidden_dim, num_layers, batch_first=True)
self.decoder = nn.LSTM(emb_dim, hidden_dim, num_layers, batch_first=True)
self.attention = Attention(hidden_dim)
self.out = nn.Linear(hidden_dim * 2, vocab_size)
self.hidden_dim = hidden_dim
def forward(self, src, tgt):
# 编码
embedded_src = self.embedding(src)
enc_out, (h_enc, c_enc) = self.encoder(embedded_src)
# 解码初始化
embedded_tgt = self.embedding(tgt)
dec_out, _ = self.decoder(embedded_tgt, (h_enc, c_enc))
# 注意力融合
attn_weights = self.attention(dec_out, enc_out)
context = torch.bmm(attn_weights.unsqueeze(1), enc_out)
concat_output = torch.cat([dec_out, context], dim=2)
# 输出预测
output = self.out(concat_output)
return output, attn_weights
代码逐行解释:
Attention类:定义双线性注意力结构;torch.cat([hidden_expanded, encoder_outputs], dim=2):拼接解码状态与编码输出;torch.bmm:批量矩阵乘法,实现加权求和;output维度为(batch, tgt_len, vocab_size),可用于交叉熵训练。
训练逻辑简述:
model = Seq2SeqAttn(vocab_size=5000, emb_dim=256, hidden_dim=512)
optimizer = torch.optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss(ignore_index=0) # 忽略padding
for epoch in range(10):
optimizer.zero_grad()
output, _ = model(src_ids, tgt_input_ids)
loss = criterion(output.view(-1, vocab_size), tgt_output_ids.contiguous().view(-1))
loss.backward()
optimizer.step()
📌 注:实际训练需配合分词、词表构建、Teacher Forcing等技巧。
4.3 Transformer在问答系统中的高级应用
4.3.1 Fine-tuning BERT for QA:基于SQuAD数据集的微调实践
BERT 的出现彻底改变了问答系统的范式。通过在 SQuAD 数据集上微调,BERT 可以实现精确的答案跨度预测(start/end positions)。
使用 Hugging Face Transformers 微调示例如下:
from transformers import BertTokenizer, BertForQuestionAnswering, Trainer, TrainingArguments
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertForQuestionAnswering.from_pretrained('bert-base-chinese')
# 编码样本
question, text = "谁是中国古代四大发明之一的造纸术的改进者?", "蔡伦改进了造纸术"
inputs = tokenizer(question, text, return_tensors='pt', max_length=512, truncation=True)
start_positions = torch.tensor([10]) # 手动标注起始位置
end_positions = torch.tensor([10])
outputs = model(**inputs, start_positions=start_positions, end_positions=end_positions)
loss = outputs.loss
loss.backward()
4.3.2 构建基于上下文的问题回答模型(如BERT+BiDAF)
可结合 BiDAF 的多级注意力机制增强上下文交互,进一步提升跨句推理能力。
4.4 模型训练策略与超参数优化
4.4.1 学习率调度、梯度裁剪与批量归一化设置
使用 OneCycleLR 或 LinearWarmupWithCosineAnnealing 提升训练稳定性。
4.4.2 早期停止(Early Stopping)与模型检查点保存
监控验证集 loss,防止过拟合。
from torch.utils.data import DataLoader
class EarlyStopping:
def __init__(self, patience=5, min_delta=0):
self.patience = patience
self.min_delta = min_delta
self.counter = 0
self.best_loss = None
def __call__(self, val_loss):
if self.best_loss is None or val_loss < self.best_loss - self.min_delta:
self.best_loss = val_loss
self.counter = 0
else:
self.counter += 1
return self.counter >= self.patience
5. 知识库集成与完整问答系统部署
5.1 外部知识源对接:Wikipedia与DBpedia的数据抽取
在构建高质量的知识库问答系统(KBQA)时,依赖单一内部数据往往难以覆盖广泛领域问题。因此,集成外部权威知识源如 Wikipedia 和 DBpedia 成为提升系统泛化能力的关键路径。
5.1.1 使用Wikidata API获取结构化三元组
Wikidata 是一个开放、多语言的协作式知识库,其数据以“实体-属性-值”形式组织成 RDF 三元组,非常适合用于语义问答系统的知识支撑。我们可以通过其 RESTful API 实现高效查询。
以下是一个使用 Python 请求 Wikidata 获取“爱因斯坦”的出生地和职业信息的示例:
import requests
def get_wikidata_entity(entity_id):
url = f"https://www.wikidata.org/wiki/Special:EntityData/{entity_id}.json"
response = requests.get(url)
data = response.json()
claims = data['entities'][entity_id]['claims']
triples = []
# 提取 P19(出生地)、P106(职业)
property_mapping = {
'P19': '出生地',
'P106': '职业'
}
for prop, label in property_mapping.items():
if prop in claims:
for claim in claims[prop]:
value = claim['mainsnak']['datavalue']['value']
if 'id' in value:
obj_label = resolve_entity_label(value['id'])
else:
obj_label = value.get('text', str(value))
triples.append((f"wd:{entity_id}", label, obj_label))
return triples
def resolve_entity_label(entity_id):
"""解析实体ID对应的标签名称"""
url = f"https://www.wikidata.org/wiki/Special:EntityData/{entity_id}.json"
resp = requests.get(url).json()
return resp['entities'][entity_id]['labels']['zh']['value']
# 示例调用
triples = get_wikidata_entity("Q937") # Q937 = 爱因斯坦
for s, p, o in triples:
print(f"{s} -- {p} --> {o}")
执行逻辑说明:
- get_wikidata_entity 函数接收 Wikidata 实体 ID(如 Q937 表示爱因斯坦),发起 HTTP 请求。
- 解析 JSON 响应中的 claims 字段,提取指定属性(P19/P106)对应的值。
- 利用 resolve_entity_label 将目标实体 ID 转换为中文标签,增强可读性。
- 返回格式统一的三元组列表 (subject, predicate, object) ,便于后续图谱构建。
| 属性代码 | 中文含义 | 数据类型 |
|---|---|---|
| P569 | 出生日期 | 时间 |
| P19 | 出生地 | 地点实体 |
| P20 | 死亡地 | 地点实体 |
| P106 | 职业 | 职业类别实体 |
| P1416 | 工作机构 | 组织实体 |
| P27 | 国籍 | 国家实体 |
| P50 | 作者 | 人物实体 |
| P17 | 所属国家 | 国家实体 |
| P31 | 实例类型 | 类别关系 |
| P279 | 子类关系 | 分类层级关系 |
该表格列出了常用 Wikidata 属性及其语义用途,可用于构建通用本体映射规则。
5.1.2 DBpedia Spotlight实现实体链接与知识映射
DBpedia Spotlight 是一个强大的工具,能够从非结构化文本中识别命名实体,并将其链接到 DBpedia 知识库中的对应资源。这对于将用户提问中的关键词转化为结构化知识至关重要。
# 启动本地DBpedia Spotlight服务(需提前部署)
java -jar dbpedia-spotlight-1.0.jar zh http://localhost:2222/rest
Python 调用示例:
import requests
def spotlight_annotate(text):
url = "http://localhost:2222/rest/annotate"
params = {
'text': text,
'confidence': 0.5,
'support': 20
}
headers = {'Accept': 'application/json'}
response = requests.post(url, data=params, headers=headers)
return response.json()
# 测试句子
result = spotlight_annotate("爱因斯坦是相对论的提出者,曾在普林斯顿大学任教。")
for resource in result.get('Resources', []):
print(f"提及词: {resource['@surfaceForm']}")
print(f"DBpedia URI: {resource['@URI']}")
print(f"类型: {resource.get('@types', 'N/A')}\n")
参数说明:
- confidence : 最小置信度阈值,控制召回精度;
- support : 实体在维基百科中被提及次数的下限,过滤低频噪声;
- @types : 提供如 Person , Place , Organisation 等分类信息,有助于后续推理。
此过程实现了从自然语言到知识图谱节点的精准映射,构成 KBQA 的核心前置步骤。
5.2 系统评估指标设计与性能分析
为了科学衡量问答系统的有效性,必须建立多维度评估体系。
5.2.1 BLEU、ROUGE、METEOR在生成质量评估中的作用
针对生成式模型输出的答案,采用自动评价指标进行量化比较:
| 指标 | 核心思想 | 适用场景 | 范围 |
|---|---|---|---|
| BLEU | n-gram精确匹配加惩罚机制 | 机器翻译、摘要生成 | 0~1 |
| ROUGE-L | 最长公共子序列相似度 | 文本摘要、答案流畅性 | 0~1 |
| METEOR | 引入同义词匹配与词干还原 | 更贴近人工评分的生成任务 | 0~1 |
示例计算 ROUGE-L:
from rouge import Rouge
rouge = Rouge()
hyp = "爱因斯坦提出了狭义相对论"
ref = "阿尔伯特·爱因斯坦创立了狭义相对论理论"
scores = rouge.get_scores(hyp, ref)
print(scores[0]['rouge-l'])
# 输出: {'f': 0.83, 'p': 0.83, 'r': 0.83}
5.2.2 准确率、召回率与F1值在答案正确性评判中的应用
对于抽取式问答任务,通常以黄金标准答案为基准,判断预测结果是否完全匹配或部分覆盖。
设:
- TP:正确识别出的答案数量
- FP:错误识别的数量
- FN:遗漏的正确答案数量
则:
\text{Precision} = \frac{TP}{TP + FP},\quad
\text{Recall} = \frac{TP}{TP + FN},\quad
F1 = 2 \cdot \frac{P \cdot R}{P + R}
在一个包含 100 条测试样本的数据集中,若系统返回结果如下表所示:
| 模型版本 | TP | FP | FN | Precision | Recall | F1-score |
|---|---|---|---|---|---|---|
| v1.0 | 68 | 15 | 12 | 0.819 | 0.850 | 0.834 |
| v1.1 | 72 | 18 | 8 | 0.800 | 0.900 | 0.847 |
| v1.2* | 70 | 10 | 10 | 0.875 | 0.875 | 0.875 |
| v2.0 (BERT-based) | 76 | 12 | 4 | 0.864 | 0.950 | 0.905 |
可见基于 BERT 的模型显著提升了整体表现,尤其在召回率方面优势明显。
5.3 完整问答系统Pipeline整合
5.3.1 从前端提问到后端响应的全流程串联
完整的问答 Pipeline 可视化如下:
graph TD
A[用户输入问题] --> B{预处理模块}
B --> C[文本清洗+分词+词性标注]
C --> D[实体识别与链接]
D --> E[知识库查询: SPARQL/Wikidata API]
E --> F[候选答案排序]
F --> G[生成式模型润色输出]
G --> H[返回结构化JSON响应]
各阶段职责明确,形成闭环流程。
5.3.2 缓存机制与响应延迟优化
高频问题可通过 Redis 缓存历史问答对:
import redis
import hashlib
r = redis.Redis(host='localhost', port=6379, db=0)
def cached_query(question, query_fn, ttl=3600):
key = hashlib.md5(question.encode()).hexdigest()
cached = r.get(f"qa:{key}")
if cached:
return cached.decode()
else:
result = query_fn(question)
r.setex(f"qa:{key}", ttl, result)
return result
设置 TTL(Time-To-Live)为 1 小时,有效降低重复请求负载。
5.4 系统部署与实际测试
5.4.1 使用Flask或FastAPI构建RESTful服务接口
选用 FastAPI 实现高性能异步服务:
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class QuestionRequest(BaseModel):
question: str
@app.post("/ask")
async def ask_question(req: QuestionRequest):
cleaned = preprocess(req.question)
entities = link_entities(cleaned)
answer = retrieve_answer(entities)
return {"question": req.question, "answer": answer, "source": "DBpedia"}
启动命令:
uvicorn main:app --reload --host 0.0.0.0 --port 8000
支持自动生成 OpenAPI 文档(Swagger UI),便于调试。
5.4.2 Docker容器化部署与云服务器上线实践
Dockerfile 配置:
FROM python:3.9-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY . .
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
构建并运行:
docker build -t kbqa-api .
docker run -d -p 8000:8000 kbqa-api
推送到阿里云容器镜像服务后,在 ECS 实例中部署集群,结合 Nginx 做反向代理与负载均衡。
5.4.3 用户反馈收集与系统迭代优化路径
上线后通过埋点记录:
- 用户提问内容
- 系统返回答案
- 显式评分(👍/👎)
- 是否重新提问同一问题
定期分析低分样本,加入主动学习队列,交由专家标注后用于微调模型,实现闭环迭代。
简介:本项目聚焦于自然语言处理(NLP)在知识库问答系统中的实际应用,涵盖从文本预处理到智能回答生成的完整流程。通过一系列教程、代码示例与数据集,学习者将掌握分词、停用词去除、词性标注、命名实体识别等基础技术,运用Word2Vec、BERT等词/句向量模型理解语义,并结合TF-IDF、BM25进行信息检索,利用seq2seq和Transformer架构实现答案生成。同时,项目包含BLEU、ROUGE等评估方法及模型调优策略,支持与Wikipedia等真实知识库集成,全面提升在机器人问答与对话系统领域的实战能力。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)