【手把手教你实操智能硬件】给大模型语音机器人自定义人设
前言

前面分享了《零基础自定制能说会唱的AI机器人/智能语音助理》,这篇就详细介绍一下修改语音机器人人设的流程和相关操作,修改之前先了解一下开发板使用的方案架构:
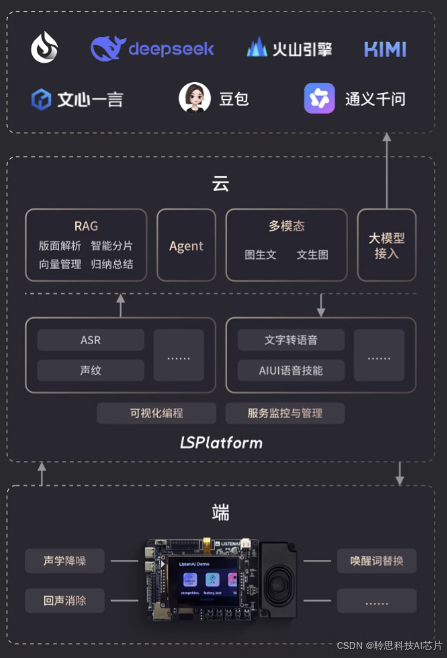
由上图可见,当前方案是把开发套件当做输入端,语音上传到聆思的大模型平台(LSPlatform),然后LSPlatform平台对语音进行处理。因此修改机器人人设除了在硬件端做修改,还需要在云平台修改对应的认知和发音人音色。
在聆思平台(LSPlatform)修改语音回复设定
修改自我认知
个性塑造功能支持设置回复语音的交互风格,包括对话风格、语调语速等,增加个性化体验。支持更改“大模型的自我认知”设定,让其展示特定的个性特征,适应不同用户的喜好。
操作步骤:
- 进入聆思平台的“应用模板中心”,找到并添加“大模型语音交互模板”。
- 在“我的应用”中点击新建的大模型语音交互模板,进入配置页面。
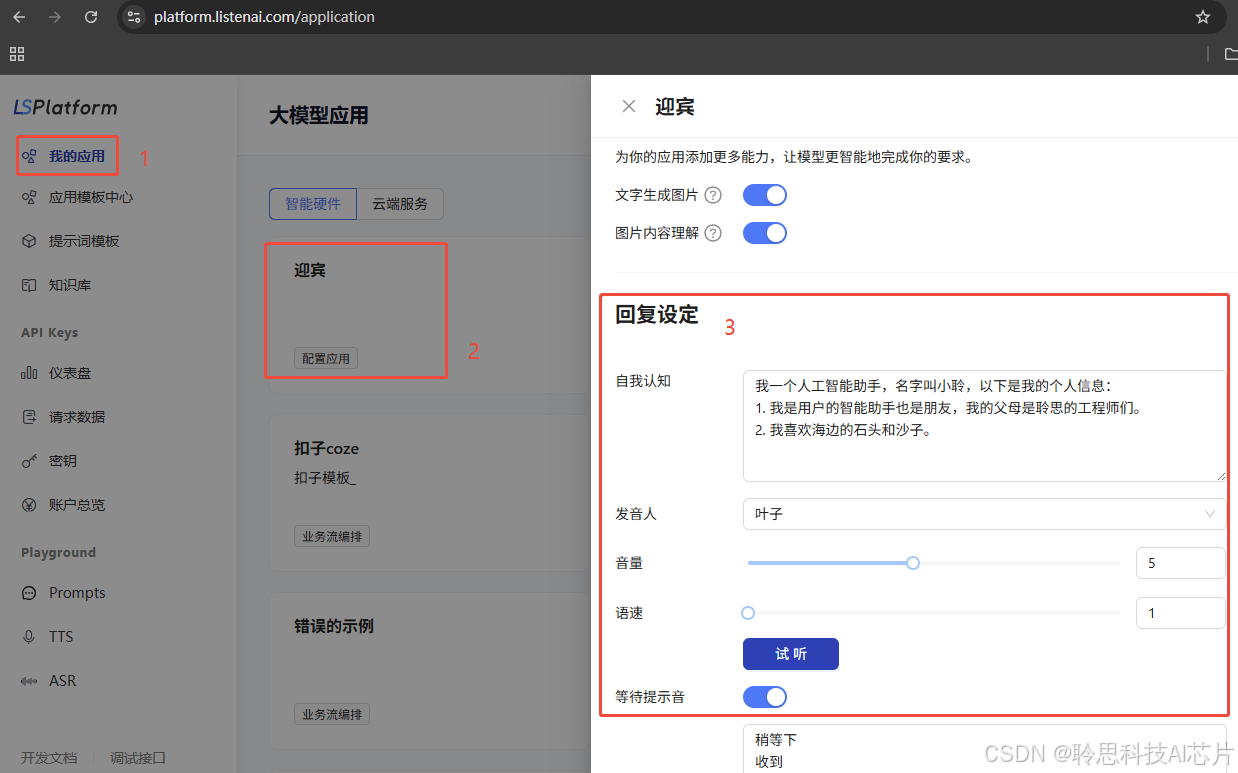
参考图中的回复设定内容:
• 角色和关系:定义AI助手为“智能助手”或“朋友”,并设定与用户的关系,比如“智能助手与朋友”。
• 背景故事:设定背景,如由聆思工程师创造,增加亲和力。
• 个人喜好和语言风格:添加兴趣(如“喜欢自然”)和轻松友好的语调,提升人性化互动。
通过这些设定,AI助手可以呈现独特的“个性”,增进用户的交互体验。初学者可以先借助大模型网页端生产自我认知提示词来优化回复效果。
修改发音人(音色)更换功能
大模型语音回复提供多种音色,以满足多样化需求。通过在聆思平台上的“应用模板中心”添加“大模型语音交互模板”,可以实现发音人更换功能,使应用语音更加灵活、个性化。
操作步骤:
- 进入聆思平台的“应用模板中心”,找到并添加“大模型语音交互模板”。
- 在“我的应用”中点击新建的大模型语音交互模板,进入配置页面。
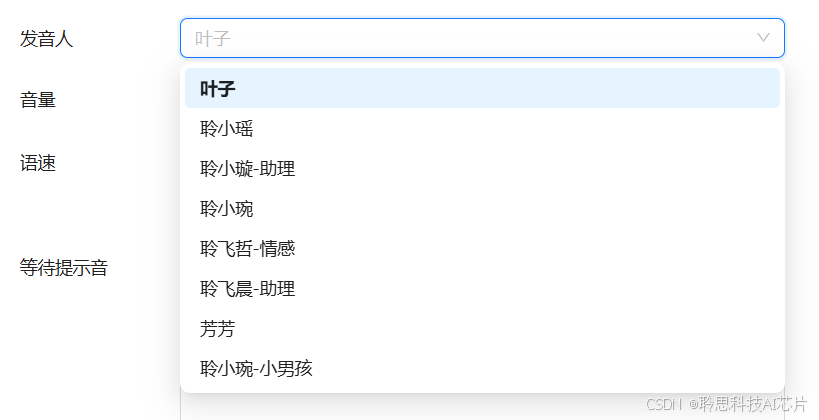
- 在配置界面的“回复设定”部分,找到“发音人”设置选项,共有八种不同音色的发音人供选择。开发者可以根据用户需求选定合适的发音人。
-可调节发音人的**音量**和**语速**,参数范围为0-10,支持更精细化的音效调整,满足不同交互场景的需求。
硬件端的唤醒修改
该部分修改以官方提供的示例演示,示例运行界面如上,包含以下功能:语音交互:支持按键录音或唤醒后通过语音与大模型进行对话
拍照识图:支持通过摄像头拍摄图像并上传给大模型进行识别,支持依据识图内容进行提问
图片生成:支持通过语音交互描述画面内容,令大模型生成图片并显示至套件屏幕上
替换唤醒词
更换唤醒词算法资源的流程如下,

第一步:登陆聆思定制平台进行唤醒词质量评估
1.访问聆思语音定制服务工具:https://tool.listenai.com/audio-custom/products
2.登录后点击【新增产品】按钮,填写产品名称后点击确定
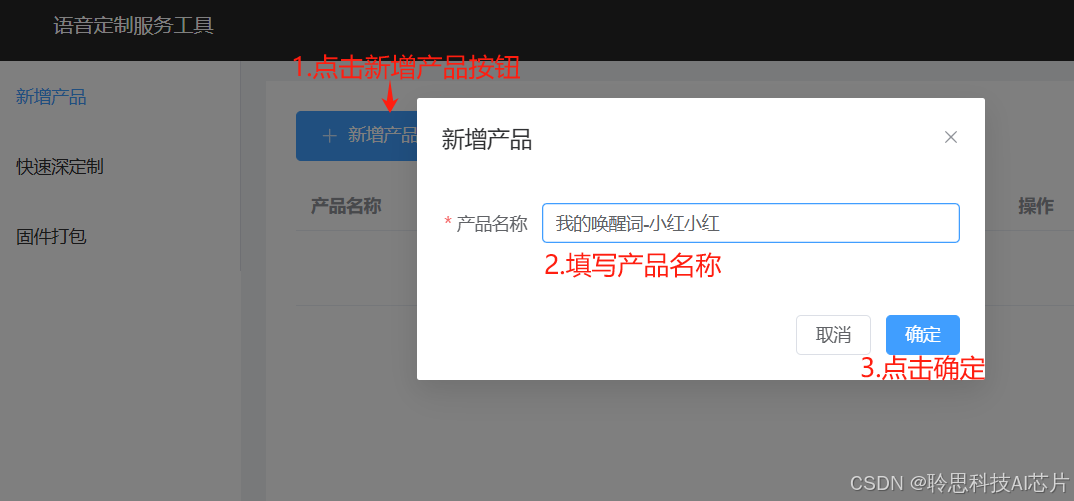
3.完成产品创建后,在新页面中直接选择唤醒词和命令词标签,点击唤醒词配置表格下方的【+添加行】按钮,在新增的行中第一列中填写自己的唤醒词 (拼音不需要填写),然后点击【词条评测】按钮,等待评测完成。
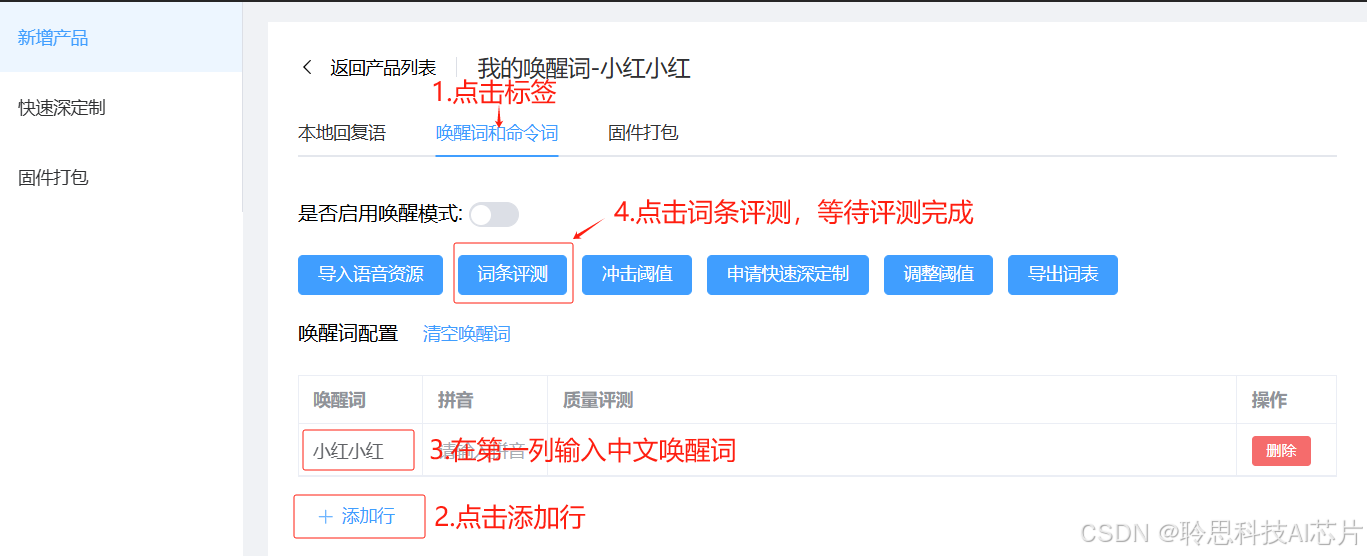
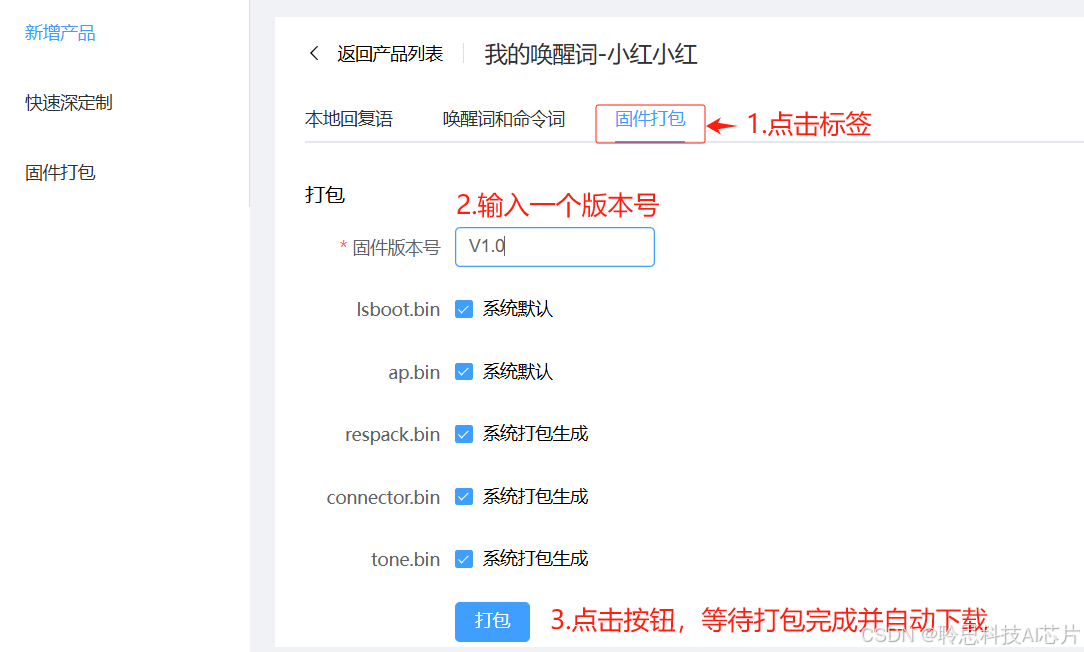
第二步:打包下载唤醒词资源
评测通过后,评测质量列将显示 OK,此时点击固件打包标签,输入一个固件版本号,其他配置项不需要变动,点击打包,等待固件打包并自动下载完成
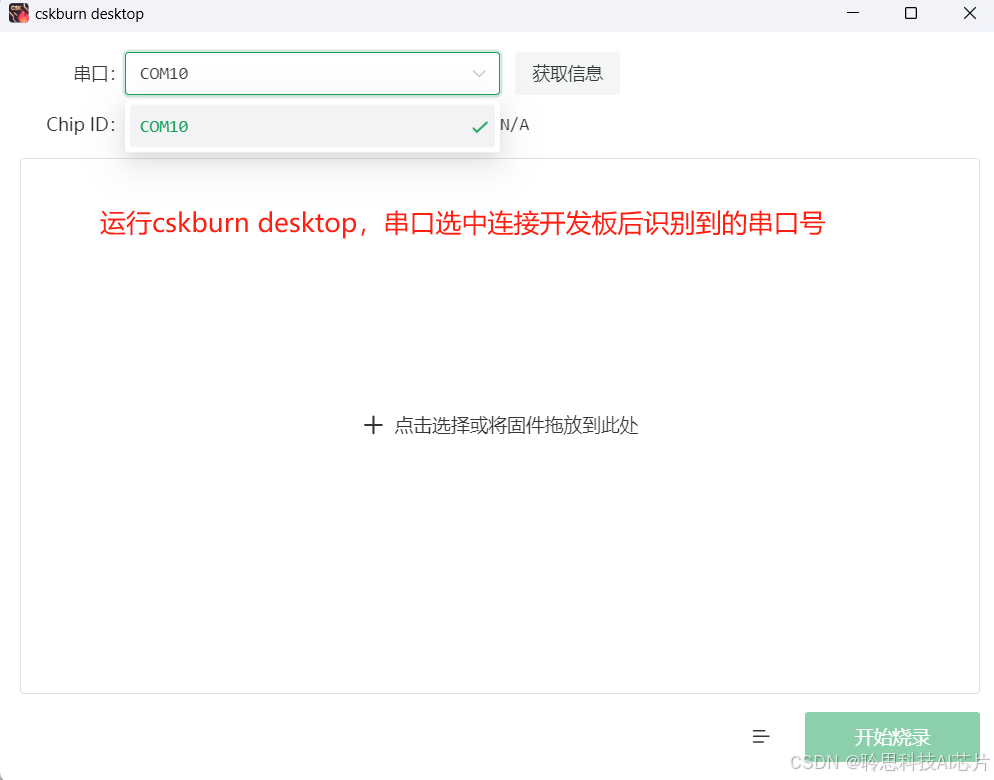
第三步:烧录替换唤醒词资源
1.检查确认开发套件已运行大模型语音交互与识图示例(llm_pic),示例启动默认界面如下:

2.电脑USB接口连接开发板 DAP_USB 接口,电脑运行cskburn桌面烧录工具并选中连接开发板后识别到的串口号:
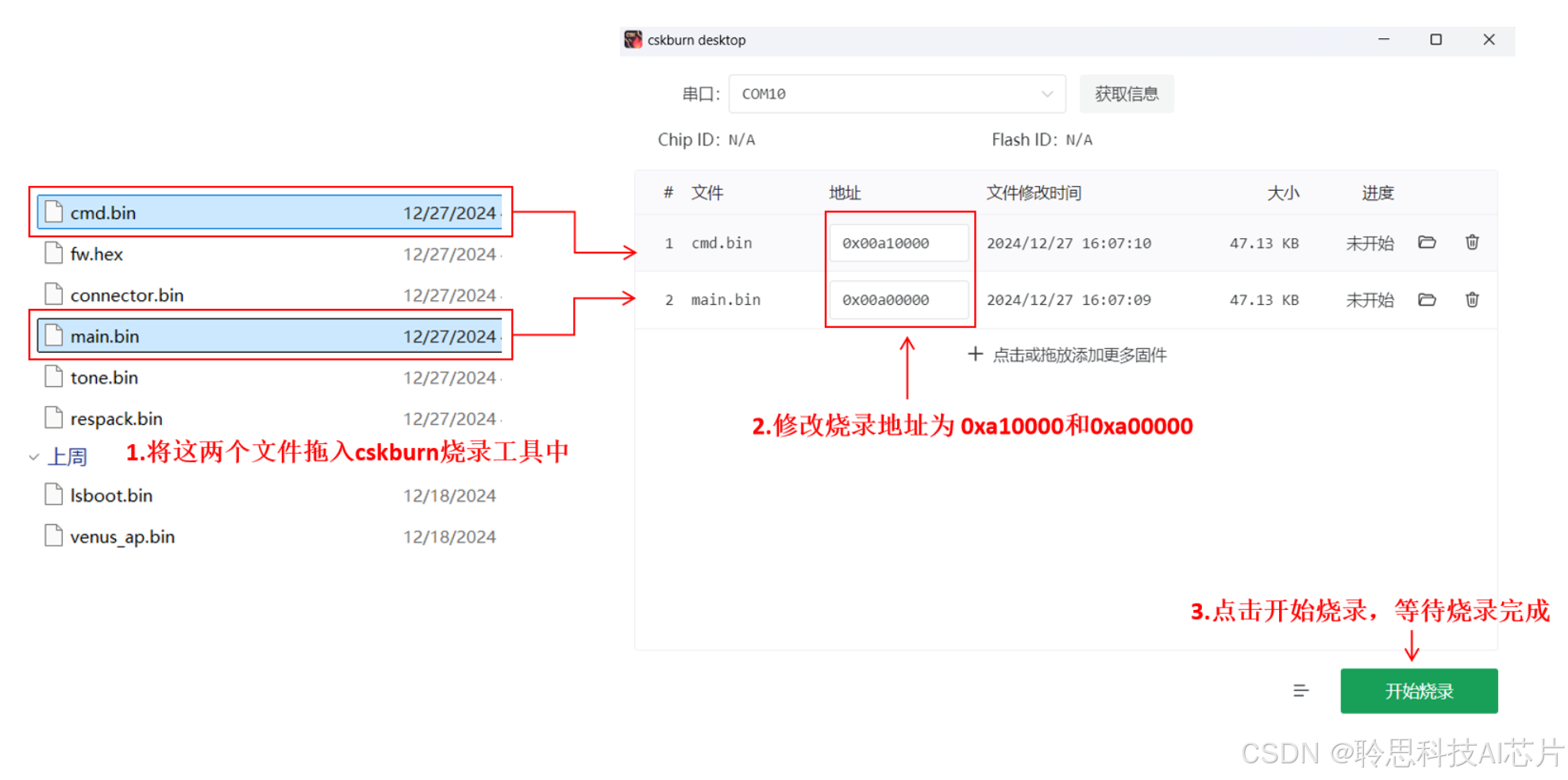
3.解压上一步下载的固件压缩包,将解压后的文件夹中的 cmd.bin 与 main.bin 这两个文件拖入 cskburn desktop 软件中,并将这两个文件的烧录地址修改为:
- cmd.bin:0xa10000
- main.bin:0xa00000
修改完成后点击烧录,等待烧录完成,即可重新运行示例进行体验。
替换唤醒应答语
默认唤醒后会有固定女声应答语——“在呢”,将该应答语替换为自己的个性化音频步骤如下:
第一步:准备新应答语音频文件
准备一个打算让其唤醒后播放的音频,音频长度不建议太长。音频文件格式要求如下:
- 16kHz
- 48kbps
- 单通道
可访问 https://www.iflyos.cn/tts-file 进行播报音频的生成和下载
第二步:将新音频替换至工程目录中
以替换大模型语音交互与识图(llm_pic)的唤醒应答语为例,将第一步中准备好的 mp3 文件替换以下原工程文件:llm_pic/resource/tone/000_geeting.mp3
第三步:打包生成文件系统
切换至 SDK 根目录(duomotai_ap)下,执行以下脚本指令完成对工程中提示音的打包:
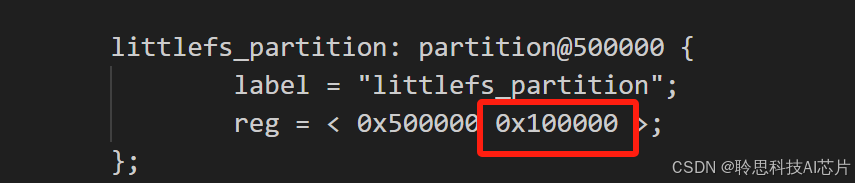
lisa zep exec mklfs apps\LLM_pic\resource\tone\ littlefs.bin 0x100000
Copy此命令中的参数(0x100000)区域于 llm_pic 工程中 dts 文件中(LLM_pic\boards\csk6_duomotai_devkit.overlay)的中文件系统的定义:
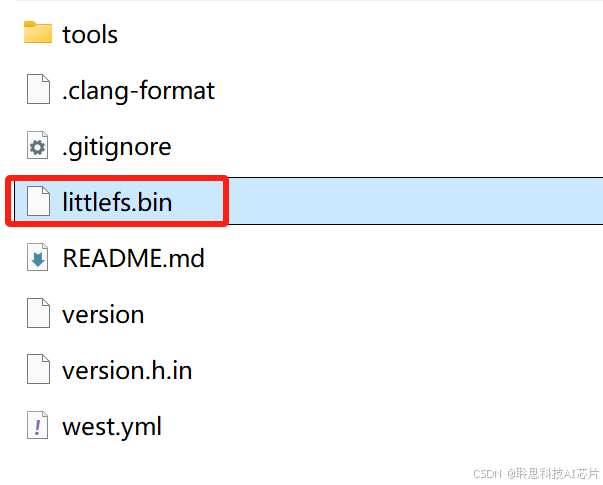
命令执行成功后可在 duomotai_ap目录下看到生成的 littlefs.bin文件:
第四步:替换littlefs.bin文件后即可=
拷贝第三步生成的littlefs.bin文件,替换到LLM_pic工程目录下的resource/littlefs/littlefs.bin
更换屏幕界面上的唤醒词文字提示
当我们按照上面步骤完成唤醒词算法资源和回复音频的替换后,可以参考下面的步骤修改示例源码并重新编译烧录,即可实现UI交互界面提示的修改。

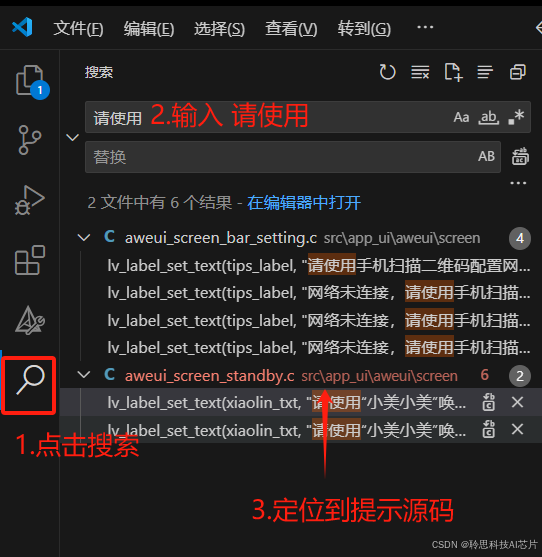
第一步、定位唤醒词提示显示的文件位置:
可使用 VSCode 打开llm_pic工程目录,通过搜索或直接定位打开我们要修改的源码文件LLM_pic\src\app_ui\aweui\screen\aweui_screen_standby.c,
第二步、修改文件
打开aweui_screen_standby.c,我们直接在代码中搜索关键词“小美小美 ”即可定位进行修改,以下图为例将 226行 与 315行 的提示修改为我们新的唤醒词或其他提示引导
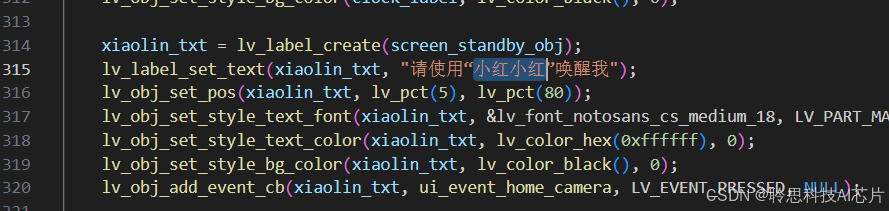
第三步、保存修改后的源码,重新编译烧录
在duomotai_ap目录下执行以下指令,对修改过的工程进行编译(以 Windows CMD 终端为例):
lisa zep build -b csk6_duomotai_devkit apps\LLM_pic -p
使用 Type-C 数据线连接开发套件的 DAP_USB接口,使用烧录工具对固件进行烧录:
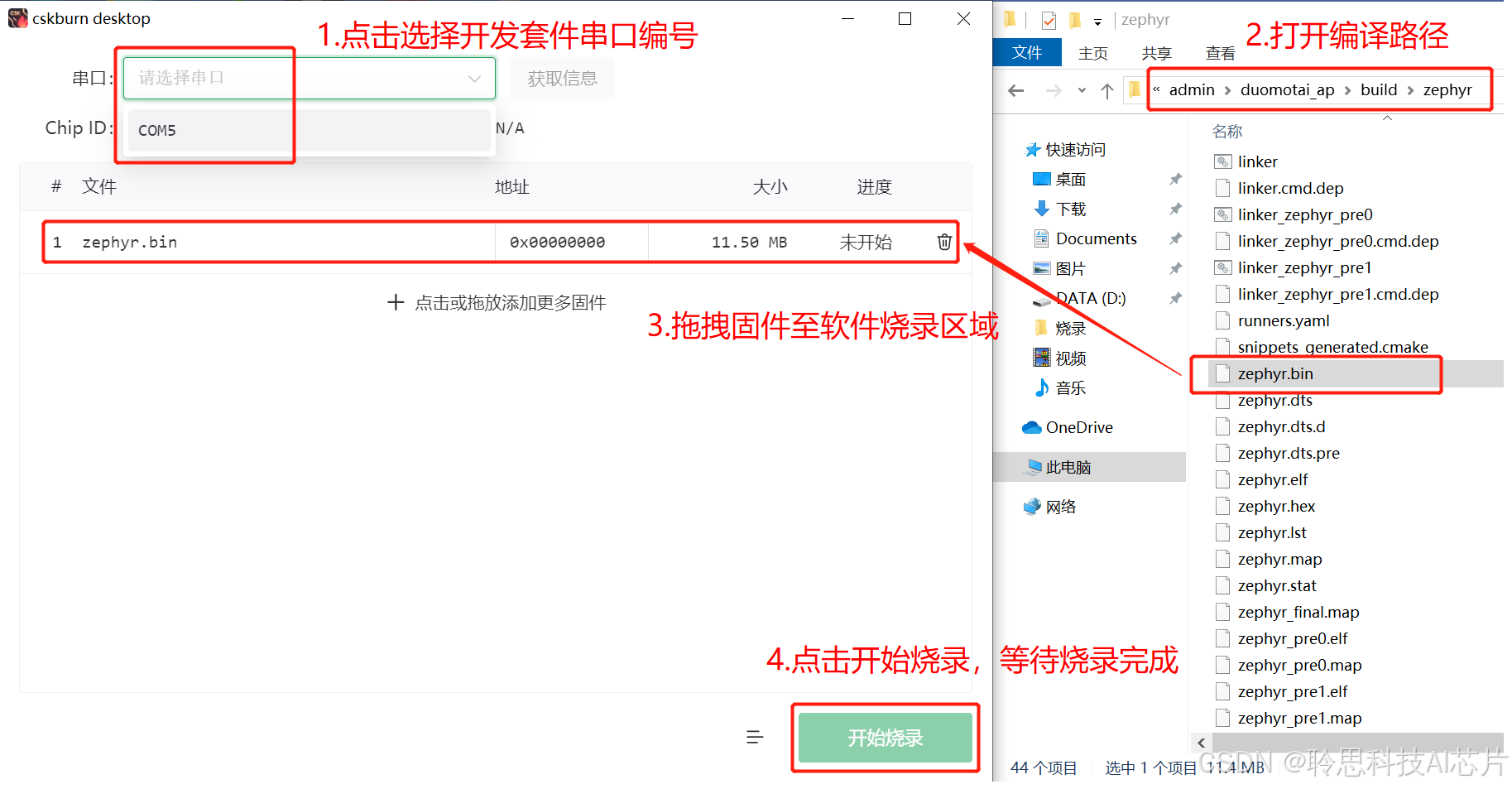
cskburn desktop是一款聆思推出的桌面烧录工具,在下载并安装 cskburn桌面烧录工具 | 聆思文档中心后,双击图标运行软件:
1.点击串口下拉框,选择连接开发套件后识别到的串口编号;
2.将编译输出的.bin文件拖拽进烧录区域;
3.点击开始烧录,等待烧录完成。
第三步、复位运行
烧录完成后,程序将自动运行,你也可以通过按压开发板上的复位按键进行复位运行。
可看到界面已修改为我们新的唤醒词:

以上就是自定制聊天机器人/AI智能语音助理的操作,零基础上手聆思CSK6大模型语音视觉开发板,例如实操更换大模型、添加优化知识库、自定义流程、控制设备等可以参考上手建议路径和资料汇总 | 聆思文档中心 (https://docs2.listenai.com/x/Bt46JnBA0)

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 7
7 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)