论文阅读:2024-arxiv A Survey of AI-generated Text Forensic Systems: Detection, Attribution
这篇论文《A Survey of AI-generated Text Forensic Systems: Detection, Attribution, and Characterization》是关于AI生成文本取证系统的综述。随着大语言模型(LLMs)发展,其生成文本存在被滥用风险,该综述对相关取证系统进行梳理,涵盖检测、溯源、特征描述,探讨资源、挑战与未来方向,助力构建可靠数字信息生态。
总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
A Survey of AI-generated Text Forensic Systems: Detection, Attribution, and Characterization
https://arxiv.org/abs/2403.01152
文章目录
- 速览
- Abstract
- 1 Introduction
- 2 AI-generated Text Forensic Systems(AI生成文本取证系统)
- 3 Resources(资源)
- 4 Future of AI-generated Text Forensics(AI生成文本取证的未来)
- 5 Conclusion(结论)
速览
这篇论文《A Survey of AI-generated Text Forensic Systems: Detection, Attribution, and Characterization》是关于AI生成文本取证系统的综述。随着大语言模型(LLMs)发展,其生成文本存在被滥用风险,该综述对相关取证系统进行梳理,涵盖检测、溯源、特征描述,探讨资源、挑战与未来方向,助力构建可靠数字信息生态。
- 研究背景:GPT-4、Gemini等大语言模型的出现,让自然语言生成能力大幅提升,在很多领域发挥作用。但也带来问题,比如可能被用来大量制造和传播错误信息、虚假宣传等,影响信息的真实性和可靠性。所以,“AI生成文本取证”这个新兴领域就很重要,它主要研究怎么分析、理解和减少AI生成文本的滥用情况。
- AI生成文本取证系统
- 检测系统:判断文本是由人写的还是AI生成的。分为基于水印和事后检测两种,文中重点讲事后检测。事后检测又分有监督检测和零样本检测。有监督检测通过标注数据训练模型找特征,像文体特征、结构特征、基于序列的特征等,还研究如何让模型更具通用性;零样本检测利用大语言模型概率函数的特点或直接用大语言模型进行检测 。
- 溯源系统:确定AI生成文本的来源模型,是个多分类问题。它和检测有很多共通技术,比如一些检测方法可以直接用于溯源,还有专门追溯基础模型家族的技术。
- 特征描述系统:检测和溯源无法了解文本背后的恶意意图,特征描述就是要解决这个问题,包括评估事实一致性和检测AI错误信息。事实一致性评估用自动技术验证大语言模型生成文本的准确性;AI错误信息检测研究其社会影响、建立基准数据集并改进检测方法。
- 研究资源:文中介绍了AI生成文本取证研究用的数据集,包括通用AI生成文本数据集和AI错误信息数据集。这些数据集使用多种生成器,涵盖不同领域,用准确率、F1分数等指标评估系统性能。目前AI错误信息检测的性能相对较低,还需要更好的数据集。
- 未来挑战与机遇:未来大语言模型会进一步发展,给取证系统带来挑战。比如,AI生成文本和人类文本的界限会越来越模糊,检测会更难;检测系统容易受到攻击,大语言模型变体和协同AI智能体也会增加取证难度。但也有改进的方向,比如将人类专业知识和现有取证知识融入大语言模型构建更智能的取证系统,以及研究因果关系感知的取证系统,更好地理解文本生成意图。
- 研究总结:AI生成文本取证领域发展很快,在检测、溯源和特征描述方面有进展,但面对不断发展的AI技术,还需要不断提高现有工具的精度,开发更灵活的模型,制定道德准则,这需要各方共同努力。
Abstract
近年来,先进的大语言模型(LLMs)迅速发展,像GPT-4、Gemini,还有Falcon、Llama 1&2这些开源版本,它们生成高质量文本的能力越来越强。在新闻、学术、社交媒体等很多领域,这些模型都能帮助人们更高效地创作内容,比如写新闻稿、学术论文、社交媒体文案等。但与此同时,它们也带来了大麻烦。有人可能会利用这些模型大规模地制造和传播误导性信息、宣传内容和虚假信息。比如,在一些热点事件中,可能会出现AI生成的假新闻,误导公众对事件的认知。
本文回顾了AI生成文本取证系统相关研究,这是一个新兴领域,主要解决大语言模型被滥用的问题。论文介绍了一个详细的分类体系,从三个关键方面展开:检测、溯源和特征描述。检测就是判断一段文本是由人写的还是AI生成的。比如在一篇新闻报道中,通过检测技术可以判断它是不是AI写的。溯源是确定AI生成文本是由哪个具体的AI模型创作的。就像警察破案找线索一样,溯源能找到文本的“源头”模型。特征描述则是弄清楚AI生成这段文本的意图,是为了提供有用信息,还是为了误导他人等。比如,有些AI生成的广告文案,特征描述可以分析它是正常宣传产品,还是故意夸大效果误导消费者。此外,论文还探讨了相关研究可用的资源,讨论了取证系统面临的挑战以及未来的发展方向。
1 Introduction
大语言模型的出现,极大地提升了自然语言生成能力。以GPT-4为例,它能写出语法正确、很有说服力的文章,和人写的几乎没什么区别。在新闻行业,记者可以借助大语言模型快速生成新闻稿件的初稿;在学术界,研究人员能利用它辅助撰写论文。然而,大语言模型也引发了严重的问题,尤其是在信息真实性方面。人们越来越担心这些模型会被滥用,比如用来制造和传播假消息、不实宣传内容,这会破坏公众的信任,影响民主的根基。比如在选举期间,可能会有人用大语言模型生成虚假的候选人信息,影响选民的判断。
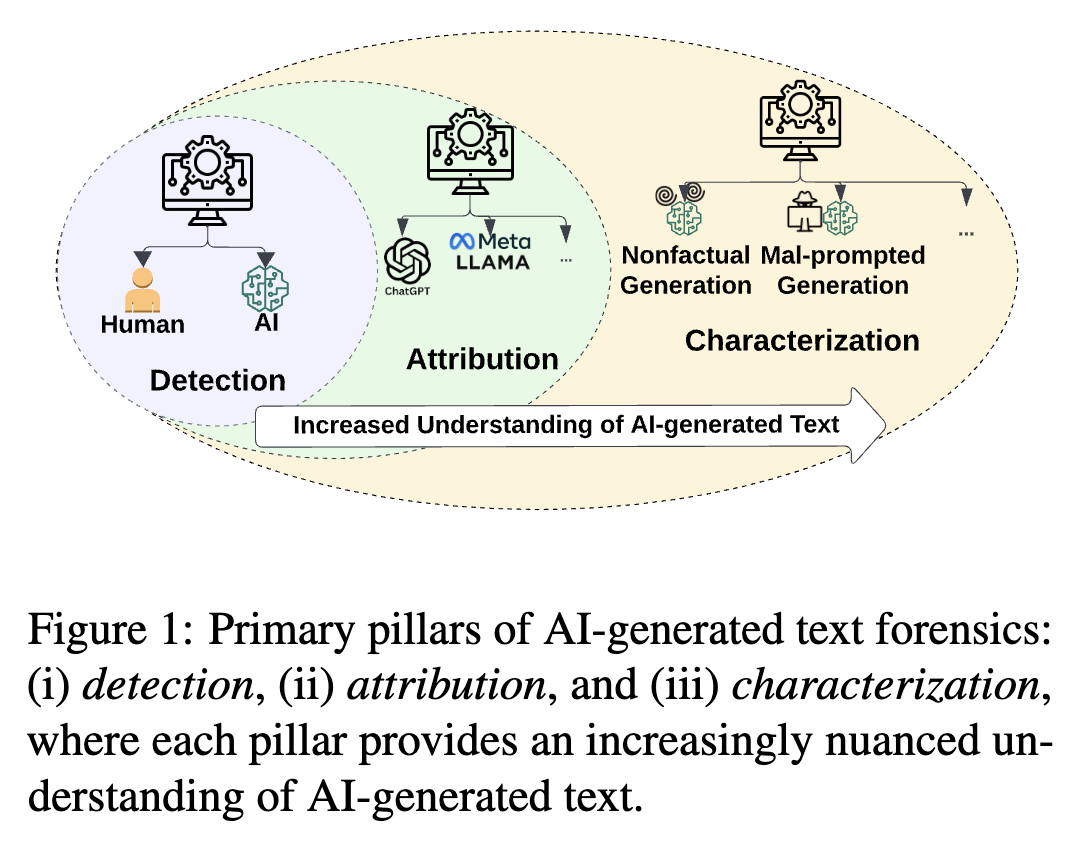
Figure 1 图1展示了AI生成文本取证的三个主要支柱:检测、溯源和特征描述。这三个部分就像一个层层递进的“解谜”过程,帮助人们更深入地了解AI生成的文本。检测是最基础的环节,它的任务是判断一段文本到底是人类的创作成果,还是AI生成的。比如老师在批改学生作业时,用检测工具来判断学生提交的作文是不是AI写的。溯源是在确定文本是AI生成的基础上,进一步找出是哪个具体的AI模型生成了这段文本。假如有一篇网上流传的AI生成的故事,溯源就可以追踪到它是由像ChatGPT这样的某个具体模型创作的。特征描述则是更深入地挖掘AI生成文本背后的意图。比如对于一些网络上的宣传文案,如果是AI生成的,特征描述能分析出它是想真实地推广产品,还是想要误导消费者购买。随着从检测到溯源再到特征描述,人们对AI生成文本的理解也越来越细致、深入。
为了解决这些问题,“AI生成文本取证”这一新兴领域应运而生,它专门研究如何分析、理解和减少AI生成文本的滥用情况。本文提出了AI生成文本取证的三个主要方面,就像图1展示的那样:检测、溯源和特征描述。检测对于保障信息真实性至关重要,它能帮我们区分人类撰写的文本和AI生成的文本。比如在一些在线写作平台上,通过检测功能可以判断投稿文章是否由AI创作。溯源能进一步追踪AI生成内容的来源模型,让整个过程更加透明,也便于追究责任。比如,一旦发现某段有害的AI生成文本,通过溯源就能找到是哪个模型生成的。特征描述则是理解AI生成文本背后的意图,这对于预防有害内容的传播非常关键。比如对于一些在社交媒体上传播的AI生成短文,通过特征描述可以分析它是不是在故意传播不良思想。
据作者所知,这是第一篇系统回顾AI生成文本取证系统的论文,还给出了像图2那样详细的分类。之所以开展这项研究,是因为AI生成的文本越来越复杂,被滥用的可能性也越来越大,需要从多个角度进行分析和应对。本文的目的是梳理当前的研究成果,找出这个快速发展领域存在的不足,明确未来的研究方向,推动AI生成文本取证领域的研究发展,让数字信息生态系统更加可靠、透明和可问责。之前也有很多研究讨论过检测和溯源的相关内容,但大多是分开进行的。而本文则是全面地阐述AI生成文本取证领域的核心内容,探讨它们之间的联系,分析面临的挑战,为这个领域的未来发展提供参考。
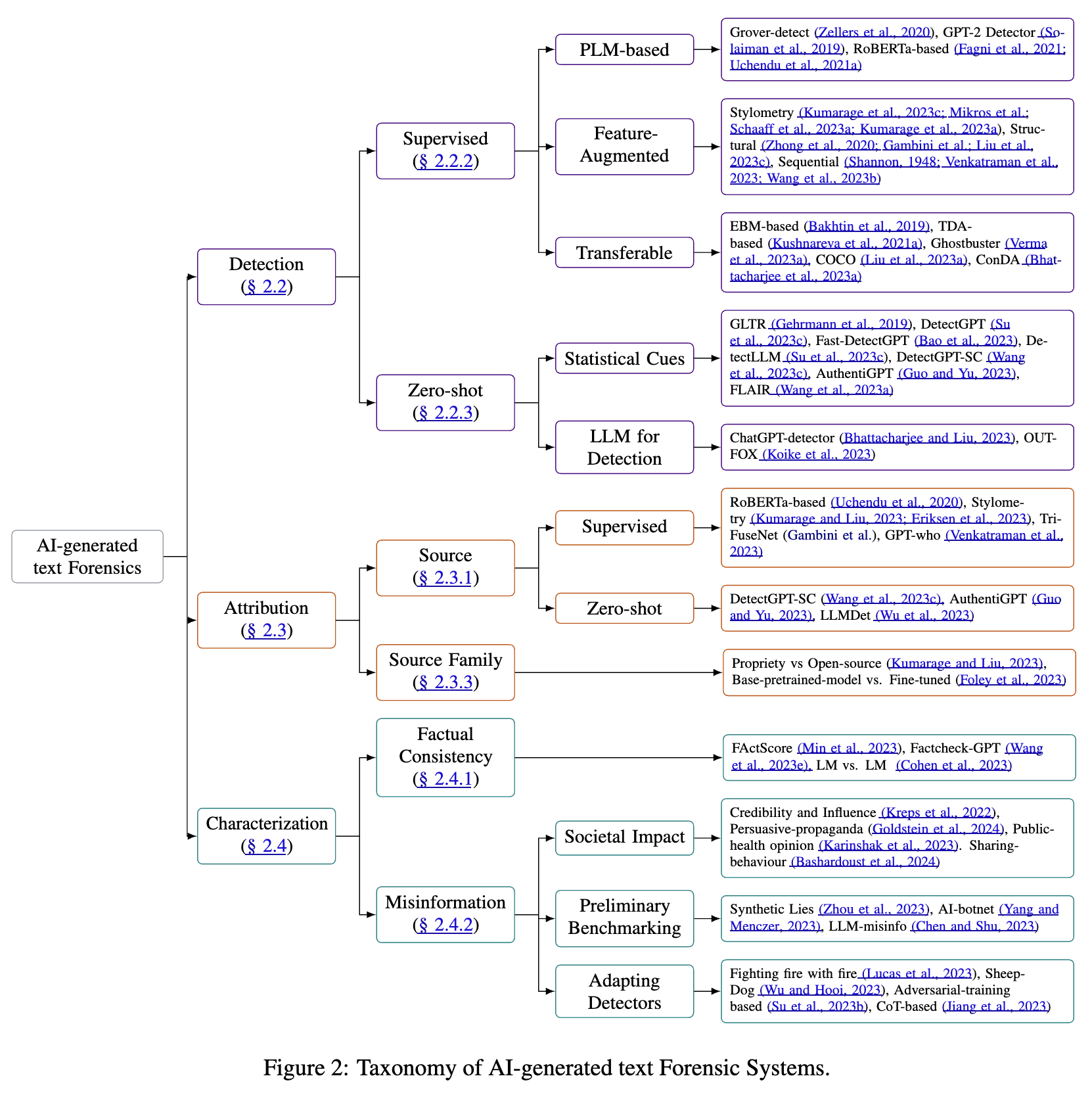
Figure 2
图2展示了AI生成文本取证系统的分类体系,具体如下:
- 检测(Detection):判断文本是否由AI生成。
- 有监督检测(Supervised ):
- 基于预训练语言模型(PLM-based) :借助预训练语言模型判断,如Grover-detect、GPT-2 Detector、RoBERTa-based等。
- 增强特征检测(Feature-Augmented) :从文体风格(Stylometry )、结构(Structure )、序列(Sequential )等方面提取特征来检测。例如通过分析文章用词习惯、句子结构、词语顺序规律等判断是否为AI生成,因为AI生成文本在词语使用多样性上常与人类不同。
- 可迁移检测(Transferable) :使检测方法适应不同AI模型,像EBM-based、TDA-based、COCO等方法,能从不同模型生成的文本中找通用特征判断来源。
- 零样本检测(Zero-shot) :
- 统计线索(Statistical Cues) :利用大语言模型概率函数线索判断,如GLTR评估文本单词对数概率,DetectGPT依据文本在大语言模型对数概率函数中的曲率特点判断。
- 用于检测的大语言模型(LLM for Detection) :直接用大语言模型检测,如ChatGPT-detector用ChatGPT判断,但效果可能不稳定。
- 有监督检测(Supervised ):
- 溯源(Attribution) :确定AI生成文本的来源。
- 来源(Source) :
- 有监督溯源(Supervised) :如RoBERTa-based、Stylometry 等方法。
- 零样本溯源(Zero-shot) :如DetectGPT-SC、AuthenticGPT等。
- 来源家族(Source Family) :判断生成文本的模型是开源还是专有,是基础预训练还是微调后的模型,如Proprietary vs Open-source 、Base-trained vs Fine-tuned 。
- 来源(Source) :
- 特征描述(Characterization) :理解AI生成文本的意图等。
- 事实一致性(Factual Consistency) :评估文本事实的准确性,如FActScore将长文本拆分成事实验证,Factcheck-GPT提供验证大语言模型输出事实的完整系统。
- 错误信息(Misinformation) :
- 社会影响(Societal Impact) :研究AI生成错误信息对社会的影响,比如分析AI生成假新闻在社交媒体的传播特点,涉及可信度和影响力(Credibility and Influence )、有说服力的宣传(Persuasive propaganda )等研究。
- 初步基准测试(Preliminary Benchmarking) :如Synthetic Lies 、AI-bonnet 等对错误信息检测的初步研究。
- 适配检测器(Adapting Detectors) :改进检测错误信息的工具,如Fighting fire with fire 、Sheep Dog 等方法 。
2 AI-generated Text Forensic Systems(AI生成文本取证系统)
这部分内容主要介绍了AI生成文本取证系统,涉及AI生成文本的定义,以及检测系统的相关内容。AI生成文本取证系统是为了解决大语言模型被滥用的问题而出现的,它包括检测、溯源和特征描述等方面,目的是分析、理解和减少AI生成文本的滥用情况,保障信息的真实性和可靠性。
2.1 AI-Generated Text(AI生成文本)
在这篇论文中,AI生成文本被定义为由使用神经概率语言模型的自然语言生成流程所产出的内容。打个比方,神经概率语言模型就像是一个会写文章的“智能大脑”,它能根据一定的概率规则生成文字。而Transformer架构的出现,是神经概率语言模型发展中的一个重要里程碑。Transformer架构就好比是给这个“智能大脑”升级了装备,它能够让数据处理变得更高效。它有两个厉害的地方,一是可以并行处理数据,就像有很多工人同时工作,能加快速度;二是能很好地捕捉文本中长距离的关联信息,比如在一篇故事里,它能记住前面提到的人物和后面的情节之间的联系。
基于Transformer架构的语言模型彻底改变了自然语言生成的过程。它们可以根据前面的文本内容,自动推测并生成下一个词。再加上指令调整和基于人类反馈的强化学习等先进的训练技术,就打造出了现在的大语言模型,这些大语言模型非常厉害,能根据给定的输入提示,生成语法正确、很吸引人的文本。比如你在聊天软件里输入一个话题,它就能给你生成一段相关的有趣对话。
2.2 Detection Systems(检测系统)
在AI生成文本取证领域,检测模型的作用就是判断一段文本是由人写的,还是AI生成的。这就像是给文本做一个“身份鉴定”,看看它的“作者”到底是谁。这个任务通常被看作是一个分类问题,简单来说,对于输入的一段文本X,检测模型要学习一个函数dθ,这个函数能输出一个结果,要么是1,要么是0。如果结果是1,就表示这段文本是AI生成的;如果是0,那就说明是人类写的。例如老师想要判断学生交上来的作文是自己写的还是用AI生成的,就可以借助检测模型来进行判断。
2.2.1 Watermarking vs. Post-hoc Detection(水印技术与事后检测)
近年来,人们对开发AI文本检测技术越来越感兴趣,出现了各种各样的方法,主要可以分为两大类:基于水印的检测和事后检测。
基于水印的检测,就像是在AI生成文本的时候,偷偷给它盖上一个看不见的“印章”。具体来说,就是在训练或者解码的过程中,把一种可以被检测到的模式嵌入到AI生成的文本里,这样以后就能通过检测这个“印章”,知道这段文本是由哪个特定的大语言模型生成的。比如一些正规的AI写作工具,可能会给生成的文本加上水印,以便区分。不过,这种方法有个局限性,它需要创建或托管大语言模型的组织或开发者配合才行。但现实中,有些恶意使用的大语言模型,开发者是不会配合加水印的,所以这种方法的应用就受到了限制。
也正因为这样,事后检测方法在AI生成文本取证中变得越来越重要。事后检测就是在文本已经生成之后,再去判断它是不是AI生成的。在这篇论文的研究范围内,主要关注的是事后检测,并根据所采用的训练方法,进一步把它分为有监督检测和零样本检测。比如在网上看到一篇文章,不知道是不是AI写的,就可以用事后检测的方法来判断 。
2.2.2 Supervised Detectors(有监督检测模型)
有监督检测模型是通过带注释的数据集进行训练的,这些数据集包含标记好的人类撰写文本和AI生成文本,目的是找出人类写作和AI生成文本之间的不同特征。
在AI生成文本检测的早期,人们使用像词袋模型和TF-IDF编码这样的传统技术,再搭配逻辑回归、随机森林和支持向量分类器(SVC)等分类器来进行检测(如Ippolito等人在2019年,Jawahar等人在2020年的研究)。后来,研究引入了先进的文本序列分类器,比如长短期记忆网络(LSTM)、门控循环单元(GRU)和卷积神经网络(CNN),来检测机器生成的文本(Fagni等人在2021年的研究)。
后来有一个重要的转变,Zellers等人在2020年指出了在检测大语言模型生成文本时暴露偏差的影响,还证明了加入Grover层的分类器在识别Grover生成的文本时准确率更高。从那以后,后续的研究进展主要集中在将预训练语言模型(PLMs)集成到分类器中,比如OpenAI的GPT-2检测器,它使用基于RoBERTa的分类器,并且是在GPT-2的输出上进行训练的。
虽然这些基于预训练语言模型的检测器很有效,但也面临一些挑战。一方面,语言模型发展得越来越复杂,更新换代很快;另一方面,很难将这些检测器应用到不同的模型上。为了解决这些问题,最近的研究尝试通过特征增强来提升分类器的性能,以及开发可迁移的方法,采用与领域无关的训练策略。下面详细介绍有监督检测中的特征增强和可迁移方法:
- 文体特征:文体特征可以作为区分人类和AI写作风格细微差别的指标,因为假设人类和AI在写作风格上有明显差异,利用这些差异能检测出AI生成的文本。比如,在基于预训练语言模型的分类器中加入措辞、标点、语言多样性等文体方面的特征,在检测AI生成的推文时效果更好(Kumarage等人在2023c年的研究)。后续研究表明,将文体特征和基于预训练语言模型的分类器结合起来,能增强检测系统的效果。除了传统的文体属性,Schaaff等人在2023a年还加入了对平均和最大困惑度、情感、主观性,以及像语法错误和空白处存在情况等基于错误的特征分析,来提高检测能力。另外,Kumarage等人在2023a年引入了新闻标准特征作为一种新的文体维度,通过评估新闻文章是否符合美联社风格手册的规范,来提高检测AI生成新闻的准确性。
- 结构特征:人们开发了各种方法,通过对文本进行明确的结构分析来增强通用检测器的能力。比如Zhong等人在2020年将文本的事实结构与基于RoBERTa的分类器相结合,提高了检测准确率。Gambini等人设计了一种新型的三分支网络TriFuseNet,能明确地对文体和上下文特征进行建模,通过微调BERTweet来增强对AI生成推文的检测。此外,Liu等人在2023c年通过在分类头中用注意力双向长短期记忆网络(attentive-BiLSTM)代替传统的前馈层,提升了检测能力,使分类器能够通过学习可解释和稳健的特征来区分AI生成和人类撰写的文本。
- 基于序列的特征:有监督的方法会研究句子层面或词符序列,以基于信息论原理得出特征。例如,GPT-who(Venkatraman等人在2023年的研究)重新审视了均匀信息密度(UID)假设,认为与人类在语言表达时倾向于均匀分布信息不同,AI生成的文本可能缺乏这种均匀性。因此,他们引入了一组UID特征来量化词符分布的平滑度。类似地,SeqXGPT(Wang等人在2023b年的研究)检查从白盒大语言模型中获得的句子级对数概率指标,以在句子层面识别AI生成的文本。作者将对数概率类比为语音处理中的波形,并使用卷积和自注意力机制来开发他们的分类器。
可迁移的有监督检测模型:有监督检测模型一个公认的挑战是,它们很难推广应用到新的AI生成器上。为了解决这个问题,人们探索了各种方法,重点是开发可迁移的AI生成文本检测技术。一种方法是将基于能量的模型(EBMs)集成到检测过程中(Bakhtin等人在2019年的研究),这种方法利用多个自回归语言模型生成的负样本,模型会给人类生成的文本赋予比AI模型生成的文本更低的能量值。Kushnareva等人在2021a年提出的另一种策略是,对Transformer模型生成的注意力图进行拓扑数据分析(TDA),以提取与领域无关的特征,用于AI生成文本检测,这种方法将注意力图表示为加权二分图,利用拓扑数据分析捕捉文本表面和结构模式的能力。
最近,Verma等人在2023a年提出了Ghostbuster,这是一种领域通用化方法,使用三个弱代理语言模型来估计输入文本的词符概率,然后对这些词符概率组合进行结构化搜索,最后在选定的特征上训练一个线性分类器,来判断输入文本是人类撰写还是AI生成的。同时,Liu等人在2023a年提出的COCO框架,利用AI生成文本中共同指称链的不一致性作为与领域无关的特征,通过在有监督对比学习框架中对实体一致性和句子交互进行编码来增强分类器的表示,重点是利用难负样本提高模型的鲁棒性。此外,Bhattacharjee等人在2023a年引入了ConDA模型,在训练过程中通过使用来自源AI生成器的标记训练数据和来自目标AI生成器的未标记训练样本,结合标准的域适应技术来实现可迁移性。ConDA将最大均值差异(MMD)与对比学习的表示能力相结合,以获得与领域无关的表示,从而使分类器能够从源生成器适应到目标生成器。具体实验设置可参考附录表3。
2.2.3 Zero-shot Detectors(零样本检测模型)
虽然有监督检测模型在特定领域的场景中表现出色,但也存在一些缺点。比如,它们容易过度适应所训练的领域,而且每当有新的AI生成器发布时,就需要重新训练一个新模型。鉴于当前AI发展速度极快,这种方式变得很不切实际。因此,近期大量研究聚焦于设计用于AI文本检测的零样本方法。在目前关于零样本检测的研究中,主要分为两类:(1)利用大语言模型概率函数的线索来区分人类写作和AI写作的检测模型;(2)直接将大语言模型用作零样本检测的模型。
大语言模型概率函数的线索
大语言模型有一个显著特点是频率偏差,即在给定上下文时,它们倾向于选择在训练数据中常见的词。这和人类写作中固有的多样性和惊喜感不同。基于这个发现,研究人员开发了一些检测模型,利用这些概率线索进行零样本检测。比如GLTR(Gehrmann等人在2019年的研究),它使用一个替代语言模型来评估文本中词的对数概率,然后通过统计测试,根据平均对数概率、词排名、词对数排名和预测熵等指标,来判断文本是AI生成还是人类撰写的。
后续研究,像DetectGPT(Su等人在2023c年的研究)通过实验证明,AI生成的文本在大语言模型的对数概率函数中往往与负曲率区域相关。基于这一发现,研究人员提出了一种文本扰动方法,通过测量原始文本和扰动后文本的对数概率差异来判断。如果差异始终为正,就表明是AI生成的。Fast - DetectGPT(Bao等人在2023年的研究)进一步简化了这个方法,它不需要进行扰动分析,只需检查条件概率曲率,简化了检测过程。这种方法发现,AI生成的文本通常具有最大的条件概率曲率,这和人类撰写的文本不同。同样,DetectLLM(Su等人在2023c年的研究)发现,AI生成的文本具有更高的对数似然对数排名比(LRR),并且比人类撰写的文本更容易受到归一化扰动对数排名(NPR)的影响。
还有一些研究探索了大语言模型概率函数的自洽性方面。自洽性是指,在给定特定输入上下文时,大语言模型在回答中对词的选择比人类更具可预测性。利用这个概念,DetectGPT - SC(Wang等人在2023c年的研究)引入了一种基于掩码预测的检测方法。具体操作是,将输入文本中的某些词遮住,然后让大语言模型预测这些词。如果预测结果与实际文本的一致性很高,就表明这段文本很可能是由该大语言模型生成的。类似地,AuthentiGPT(Guo和Yu在2023年的研究)通过将一个黑盒大语言模型应用于故意添加噪声而失真的文本进行去噪,然后从语义上比较去噪后的文本和原始文本,以此来判断是否为AI生成。Zhu等人在2023年提出的另一种方法,是基于测量ChatGPT对文本的重写量。其基本假设是,ChatGPT模型对AI生成的文本进行修改的次数,要少于对人类撰写的文本。
与上述方法不同,FLAIR(Wang等人在2023a年的研究)采用了一种在线机器人检测策略,它假设以黑盒方式访问AI生成器。研究人员制定了一系列诊断问题和答案,通过将问题分类为人类容易回答但机器人难以回答的(如计数、替换、定位、噪声过滤和ASCII艺术相关问题),以及反之(如记忆和计算相关问题),来区分文本来源是AI还是人类。
将大语言模型作为零样本检测模型
有几项研究探索了在AI生成文本检测领域中,将大语言模型用作零样本检测模型的潜力。Bhattacharjee和Liu在2023年使用GPT - 3.5和GPT - 4进行分析,试图自动将文本分类为人类撰写或AI生成,但结果表明,直接使用这些模型进行检测并不可靠。OUTFOX(Koike等人在2023年的研究)引入了一种更有效的策略,通过上下文学习模拟对抗训练环境。这个方法涉及一个由检测大语言模型和攻击大语言模型组成的双系统。首先,检测大语言模型为训练数据集分配标签;然后,攻击大语言模型根据这些初始标签生成对抗性文本;最后,检测大语言模型将这些对抗性文本作为少样本示例,来提高其在测试数据集中识别AI生成内容的能力。具体实验设置可参考附录表2。
2.3 Attribution Systems(溯源系统)
在AI生成文本取证领域,确定文本是由哪个大语言模型生成的,也就是神经作者溯源,对于提高AI生成文本的透明度至关重要。这个任务通常被当作一个多类别分类问题来处理。打个比方,就像给不同的大语言模型分配不同的“身份标签”。对于输入的一段文本X,目的是学习一个函数aθ ,让它输出的结果aθ(X)对应某个标签,比如0、1、…… 、k - 1,这些标签分别代表k个已知的来源生成器。比如,有三个已知的大语言模型A、B、C,分别对应标签0、1、2,通过这个函数就能判断一段文本是由哪个模型生成的。
2.3.1 History of Authorship Attribution(作者溯源的历史)
作者溯源,也就是通过独特的写作风格来识别作者的任务,已经被广泛研究了很多年。最开始,人们用像朴素贝叶斯、支持向量机(SVM)、决策树、随机森林和K近邻(KNN)这样的经典分类器,再搭配n - 元语法、词性标注(POS tags)、主题建模和语言查询和词数统计工具(LIWC)等特征提取方法,来解决作者溯源的问题(Koppel等人在2009年,Uchendu等人在2023年的研究)。后来,随着神经网络的发展,卷积神经网络和循环神经网络也被用于作者溯源,因为它们能够捕捉作者的独特特征(Boumber等人在2018年,Alsulami等人在2017年的研究)。基于Transformer架构的模型出现后,作者溯源领域有了重大的发展,从传统的文体特征和统计特征分析,转变为使用基于预训练语言模型的分类器(Uchendu等人在2020年的研究),这些分类器在识别神经作者(即确定文本是由哪个大语言模型生成的)方面也取得了很好的效果。比如,以前人们通过分析文章中的用词习惯和句子结构等特征来判断作者,现在可以借助基于预训练语言模型的分类器更准确地判断文本是由哪个大语言模型生成的。
2.3.2 Extending Detection to Attribution(从检测扩展到溯源)
有监督检测和有监督溯源方法有一些共同的技术。比如,基于文体增强的预训练语言模型检测器,已经被直接应用到溯源任务中(Kumarage和Liu在2023年,Eriksen等人在2023年的研究)。同样,TriFuseNet检测方法在识别来源生成器方面也被证明是有效的(Gambini等人的研究)。基于信息论的GPT - who(Venkatraman等人在2023年的研究)也表明,在检测中使用的均匀信息密度(UID)特征,对于神经作者溯源也同样适用。
此外,之前讨论的很多零样本检测方法也可以直接应用到神经作者溯源任务中。具体来说,像DetectGPT - SC(Wang等人在2023c年的研究)和AuthentiGPT(Guo和Yu在2023年的研究)这些结合了自洽性方面的检测器,会使用目标大语言模型来计算一致性。当面对多个来源的大语言模型时,这些方法可以通过评估不同来源的一致性,来确定最有可能的文本来源。另外,LLMDet(Wu等人在2023年的研究)提出了一种用于神经作者溯源的困惑度分数比较方法。不过,计算困惑度需要对词符级对数概率有白盒访问权限,在现实场景中不太可行。所以,他们建议使用常见的n - 元语法概率为每个目标大语言模型计算一个代理困惑度,把它当作大语言模型的写作“签名”,通过比较这个“签名”与输入文本的代理困惑度,来确定文本最接近的来源模型。比如,有三个大语言模型,分别计算它们的代理困惑度,再和一段未知来源的文本的代理困惑度比较,就能判断文本是由哪个模型生成的。
2.3.3 Source Family Classification(来源模型家族分类)
除了前面讨论的一般溯源方法,还有一些技术专注于将文本溯源到基础模型家族。这种分析特别有价值,因为它可以推断出恶意影响活动背后的资金和技术实力,还能确定哪些类型的大语言模型容易受到这些活动的影响。Kumarage和Liu在2023年进行了一项研究,试图将大语言模型生成的文本归为像“专有”和“开源”这样的高级模型家族。通过整合基于文体特征增强的预训练语言模型分类器,他们证明了这项任务可以高精度地完成。此外,Foley等人在2023年的研究展示了现有的基于预训练语言模型的溯源方法,如何从微调后的模型变体中识别出基础大语言模型,这能让人们更深入地了解生成内容的来源。比如,通过分析一段AI生成的宣传文本,判断它是由专有模型还是开源模型生成的,进而分析背后可能存在的影响因素。
2.4 Characterization Systems(特征描述系统)
检测和溯源对于确定文本是否由AI生成以及出自哪个AI模型很重要,但它们有个明显的局限,就是没办法深入了解这些AI生成文本背后有没有被恶意利用的情况,或者说不清楚它们的意图是好是坏。要想有效减少AI生成文本可能带来的危害,就得弄清楚它是不是带着恶意。在AI生成文本取证中,搞清楚AI生成文本背后的意图是非常关键的一部分。
从大的方面来说,判断文本意图的任务可以看作是一个分类问题。假设有一段输入文本X,目标是找到一个函数cθ ,让它把文本X对应到0或者1。这里的0代表这段文本没有恶意,1则表示有恶意。但在实际操作中,从文本里判断意图既主观又复杂,直接这么做难度很大(Wang等人在2023f年,Subbiah等人在2023年的研究都提到了这点)。所以现在想要直接判断文本意图可能不太现实。不过,随着社会越来越依赖AI,在应对AI生成内容被滥用的问题上,特征描述会变得越来越重要。因此,在这篇论文里,作者回顾了一些对特征描述很重要的新方向,像评估事实一致性和检测AI生成的错误信息,后面的章节会详细讨论这些内容。
比如,在社交媒体上看到一段AI生成的健康科普内容,检测能判断它是不是AI写的,溯源能知道是哪个AI模型创作的,但无法直接判断这段内容是不是故意传播错误的健康知识,这就需要特征描述来解决。
2.4.1 Factual Consistency Evaluation(事实一致性评估)
评估大语言模型生成文本的事实准确性,是对文本进行特征描述的关键第一步。以前,人工事实核查员在这个过程中起着重要作用。但现在大语言模型生成的文本数量太多了,靠人工一个个去核实内容是否真实变得越来越不现实。所以,人们开始研发自动技术来评估大语言模型生成文本的事实一致性。
以FActScore(Min等人在2023年的研究成果)为例,它采用了一种创新方法。如果要评估一篇很长的文本,FActScore会把它拆分成一个个小的事实,然后对照可靠的信息来源进行核实。这种方法结合了人工判断和自动化流程,相比传统的人工核查方式,效率更高,而且可以处理大量文本。
Factcheck-GPT(Wang等人在2023e年的研究成果)则提供了一套完整的系统来核实大语言模型的输出内容。它有详细的标注流程,还专门开发了工具,让核实过程更加高效。比如,当大语言模型生成一篇科技新闻稿件时,Factcheck-GPT可以快速检查里面提到的科研成果、数据等信息是否真实准确。
另外,Cohen等人在2023年提出了一个交叉检验框架。这个框架利用不同大语言模型之间的互动,来发现大语言模型生成文本中的事实差异。例如,用两个不同的大语言模型对同一主题进行描述,然后对比它们的内容,看看有没有不一致或者错误的地方。
2.4.2 AI-Misinformation Detection(AI错误信息检测)
检测大语言模型生成的错误信息,对于准确描述AI生成文本的特征以及减少其滥用情况至关重要。这一领域主要关注识别包含错误信息的AI生成文本,它和普通的AI生成文本检测不同,更强调找出具有欺骗性信息的挑战。近年来,AI错误信息检测领域出现了几个研究分支。包括研究AI生成错误信息对社会的影响,这涉及到与人类编写的错误信息相比,AI生成的错误信息在说服力和传播方面的关键问题。还有研究致力于构建对手利用大语言模型制造错误信息的分类体系,并评估现有检测方法对这类内容的检测效果。另外,一些研究通过提出创新的检测机制,来应对大语言模型生成错误信息这一日益严峻的威胁。
- 社会影响:早期有实验评估AI生成的文本对外交政策观点的可信度和影响力,结果显示,人们的党派立场会显著影响他们对这些内容可信度的感知。不过,接触AI生成的文本似乎对政策观点的影响较小(Kreps等人在2022年的研究)。这表明AI有可能快速制造并传播大量看似可信的错误信息,从而加剧新闻领域的错误信息问题,破坏媒体公信力,导致公众对政治事务的疏离。进一步的研究利用GPT-3生成有说服力的宣传内容,发现这类模型生成的内容几乎和人类宣传者创作的一样有说服力(Goldstein等人在2024年的研究)。通过巧妙设计提示词,宣传者制作令人信服内容的工作量大幅减少,凸显了AI在传播错误信息方面的“助力”。
此外,研究人员还探索了AI生成文本对公共卫生信息传播的影响。他们发现,AI生成的支持疫苗接种的信息,比美国疾病控制与预防中心(CDC)等机构发布的同类信息更有效,能引发更积极的态度(Karinshak等人在2023年的研究)。最近的一项研究深入探讨了影响AI生成假新闻传播的分享行为和社会经济因素(Bashardoust等人在2024年的研究)。研究发现,年龄、政治倾向等社会经济因素,会显著影响人们对AI生成错误信息的易感性。这些研究结果表明,需要开展有针对性的媒体素养教育,并制定监管措施,以应对AI生成错误信息带来的挑战。
比如,在某一政治事件的讨论中,AI生成的带有偏向性的虚假报道,可能会利用一些看似专业的表述,误导部分民众的看法,影响社会舆论走向。在公共卫生领域,AI生成的一些夸大疫苗效果或副作用的假消息,可能会影响人们对疫苗接种的态度。
- 初步基准测试:对抗AI生成的错误信息,第一步是研究恶意行为者如何利用当前的大语言模型制造这类内容。因此,近期许多研究构建了AI错误信息生成的分类体系,建立了基准测试数据集,同时评估现有检测器对大语言模型生成错误信息的检测效果。
Zhou等人在2023年开展的“Synthetic Lies”研究,以新冠疫情相关数据集为重点,为区分AI生成的错误信息和人类撰写的新闻设定了基准。该研究发现了AI生成错误信息独有的语言模式,比如细节过度渲染、编造个人轶事等,这对像CT-BERT这样的传统检测模型构成了挑战。Yang和Menczer在2023年分析了一个利用ChatGPT在Twitter上传播误导性内容的僵尸网络,研究结果指出了当前检测工具在识别由大语言模型驱动的僵尸网络生成文本方面存在的局限性。Chen和Shu在2023年深入研究了检测大语言模型生成错误信息的复杂问题,提出了一个全面的分类体系,涵盖了错误信息的生成方式(如幻觉、随意编造和有控制地生成错误信息),以及背后的领域和意图。他们的分析表明,大语言模型制造的错误信息在检测上难度更大,凸显了制定应对措施的紧迫性。
- 适配AI错误信息的检测器:近期研究聚焦于改进检测器,以应对AI生成错误信息带来的挑战。例如,Lucas等人在2023年提出了一种新方法,利用大语言模型既生成又检测错误信息。借助GPT-3.5-turbo的强大生成能力和零样本语义推理能力,该方法显著提高了区分真实内容和欺骗性信息的准确性。同时,Wu和Hooi在2023年开发的“SheepDog”是一种不依赖文本风格的检测系统,专门解决大语言模型被用于制造模仿可靠来源的错误信息的问题。
Su等人在2023b年的研究强调了现有检测器对大语言模型生成内容存在固有偏见,并提出基于改写示例的对抗训练作为缓解策略。后续研究还发现,基于人类撰写文章训练的检测器,在识别机器生成的错误信息时效果尚可,但反过来,基于机器生成内容训练的检测器识别人类撰写的错误信息时效果较差(Su等人在2023a年的研究)。这一发现促使研究人员探索调整训练数据集中AI生成新闻和人类撰写新闻的比例,是否能提高测试集的检测准确率。Jiang等人在2023年概述了识别大语言模型编造的虚假信息存在的困难,并主张采用思维链(Chain of Thought,CoT)和上下文分析等先进提示技术作为可行策略。
3 Resources(资源)
论文通过表1概述了AI生成文本取证研究中使用的重要数据集,从多个关键维度对这些数据集进行了评估,包括所用的AI生成器、写作领域以及性能指标。这些数据集主要分为两大类:一类是用于检测和溯源的通用AI生成文本数据集;另一类是用于特征描述的AI错误信息数据集。比如在判断一篇新闻稿件是否由AI生成(检测),以及确定是由哪个AI模型生成(溯源)时,会用到通用AI生成文本数据集;而在分析AI生成文本是否包含错误信息(特征描述)时,则会用到AI错误信息数据集。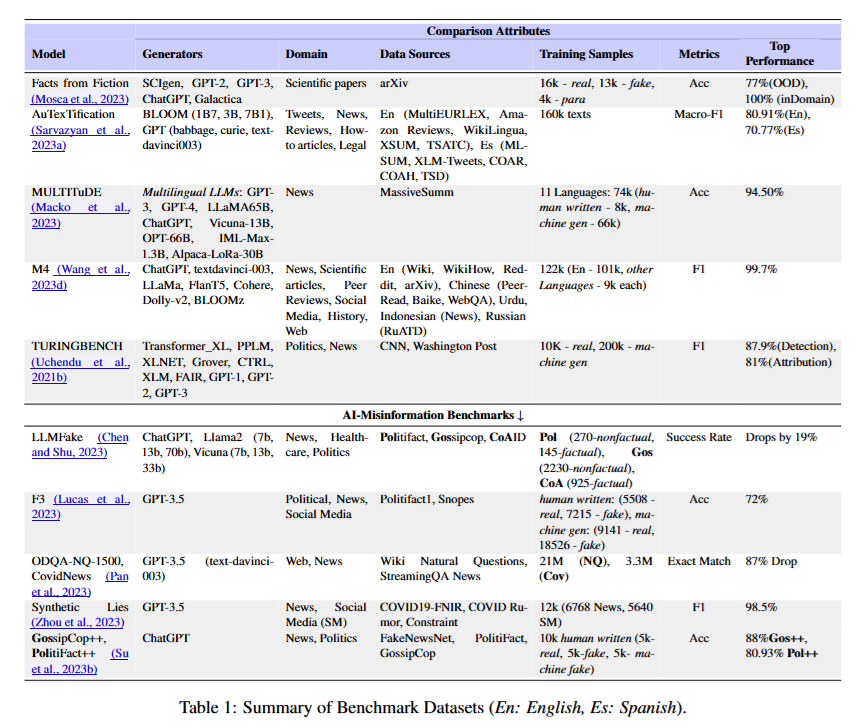
这张表格是对AI生成文本取证领域中基准数据集的总结,涵盖了不同类型数据集的关键信息,便于对比和了解各数据集特点,具体如下:
- 表头:“Comparison Attributes”(比较属性)下包含生成器(Generators)、领域(Domain)、数据源(Data Sources)、训练样本(Training Samples)、指标(Metrics)和最佳性能(Top Performance)几大项,用于从不同方面描述每个数据集。
- 通用AI生成文本数据集:
- Facts from Fiction(Mosca等人,2023) :使用SCIgen、GPT - 2、GPT - 3、ChatGPT、Galactica等生成器,专注于科学论文领域,数据源来自arXiv。训练样本包含1.6万个真实样本,1.3万个虚假样本,以及4千个段落样本。采用准确率(Acc)作为指标,在域内(inDomain)准确率达100%,域外(OOD)为77% 。
- AuTexTification(Sarvazyan等人,2023a) :生成器有GPT(如1B7A、3B、7B1)、davinci003、curie等,涉及推文、新闻、评论、法律文章等多个领域。数据源多样,如En(MultiEURLEX、Ama - zon Reviews等)。以Macro - F1为指标,在英文(En)场景下为80.91%,西班牙文(Es)场景下为70.77% 。
- MULTITuDE(Macko等人,2023) :采用多语言大语言模型如GPT - 3、GPT - 4、LLaMA65B等,聚焦新闻领域,数据源来自多个平台。训练样本涵盖11种语言,74k个人类撰写样本,8k个机器生成样本,66k个其他样本。以准确率评估,达到94.50% 。
- M4(Wang等人,2023d) :生成器包括ChatGPT、text - davinci - 003、LLaMA、FlanT5、Cohere等,涉及新闻、科学文章、评论等领域,数据源广泛。训练样本有122k个英文样本,其他语言各9k个样本。以F1值为指标,达到99.7% 。
- TURINGBENCH(Uchendu等人,2021b) :使用Transformer - XL、PPLPM、XLNET等生成器,专注政治领域,数据源为CNN、Washington Post。训练样本有10K个真实样本,200K个机器生成样本。检测的F1值为87.9%,溯源的F1值为81% 。
- AI错误信息基准测试数据集:
- LLMFake(Chen和Shu,2023) :由ChatGPT、Llama2等生成,涉及新闻、健康护理、政治领域,数据源为Politifact、Gossipcop、CoAID 。样本分为非事实(270个)和事实(145个等不同分类)。以成功率(Success Rate)为指标,相比其他情况性能下降19% 。
- F3(Lucas等人,2023) :生成器为GPT - 3.5,涵盖政治、新闻、社交媒体领域,数据源是Politifact、Snopes 。样本包含真实和机器生成的不同数量样本。以准确率评估,为72% 。
- ODQA - NQ - 1500,CovidNews(Pan等人,2023) :使用GPT - 3.5(text - davinci - 003)生成,涉及网络、新闻领域,数据源为Wiki Natural Questions等。以精确匹配(Exact Match)为指标,性能下降87% 。
- Synthetic Lies(Zhou等人,2023) :生成器是GPT - 3.5,集中在社交媒体、新闻领域,数据源为COVID19 - FNIR等。样本有126k个新闻样本。以F1值评估,达到98.5% 。
- GossipCop++,Politifact++(Su等人,2023b) :由ChatGPT生成,针对新闻、政治领域,数据源是FakeNewsNet、Politifact等。样本包含10k个人类撰写样本,5k个机器生成样本。以准确率评估,GossipCop++为88%,Politifact++为80.93% 。
3.1 Generators and Domains(生成器和领域)
这些数据集使用了各种各样的AI生成器,像SCIgen、GPT系列模型(如GPT-2、GPT-3、GPT-3.5 )、BLOOM等等。并且覆盖的领域非常广泛,从科学论文到社交媒体帖子,再到学术著作都有涉及。例如,Facts from Fiction(Mosca等人在2023年的研究)这个数据集主要聚焦于科学论文,数据来源包括arXiv这样的平台;而AuTexTification(Sarvazyan等人在2023a年的研究)涵盖的领域则有推文、评论以及新闻文章等。这种多样性意味着这些数据集在测试检测和溯源系统时,能提供全面的覆盖范围。打个比方,如果要开发一个检测AI生成文本的工具,这些不同生成器和领域的数据集就能帮助测试该工具在各种情况下的表现,看看它能不能准确检测出不同来源、不同类型的AI生成文本。
3.2 Performance Metrics(性能指标)
在评估检测和溯源的有效性时,会使用准确率(accuracy)和F1分数等指标。论文中突出展示了每个数据集的最佳性能记录。在通用AI生成文本的检测方面,性能通常比较高。以MULTITuDE(Macko等人在2023年的研究)数据集为例,它专注于新闻文本,检测准确率达到了94%。然而,AI错误信息检测的性能则明显较低,这反映出在描述AI生成的错误信息时面临的复杂挑战。比如在判断一段文本是不是AI生成的方面,现有方法可能表现不错,但要进一步判断这段AI生成的文本是否包含错误信息,难度就大多了,准确率也会下降。这是因为错误信息的形式和特点更加复杂多样,难以准确识别。
3.3 AI-Misinformation Benchmarks(AI错误信息基准测试)
专门的基准测试用于应对检测AI生成错误信息的难题。早期的基准测试,如Synthetic Lies(Zhou等人在2023年的研究),表现出了很强的检测性能(准确率超过95%)。但像LLMFake(Chen和Shu在2023年的研究)这种较新的、基于复杂分类体系的基准测试,检测性能却较弱。这表明,目前需要有能够模拟现实世界中复杂且不断变化的错误信息传播策略的数据集。通过深入分析生成参数,比如特定恶意意图提示词的使用,这些数据集能为特征描述系统提供关键的见解。例如,研究人员可以通过分析数据集中使用了哪些恶意提示词来生成错误信息,进而了解恶意行为者的手段,为改进检测方法提供方向。
3.4 Generation Parameters(生成参数)
这些数据集还能揭示生成参数以及多语言支持方面的信息,有助于应对全球范围内AI生成错误信息的挑战。由于篇幅有限,论文表格中只总结了关键数据集;完整的基准测试列表,以及它们具体的生成参数、初始提示词和详细的性能指标,可在附录的表4中查看。生成参数会影响AI生成文本的特性,研究这些参数能更好地理解AI生成错误信息的机制。比如,某些生成参数可能会导致AI生成更具误导性的文本,了解这些就能针对性地调整检测和防范策略。多语言支持方面的信息也很重要,因为AI生成的错误信息可能出现在各种语言环境中,了解数据集在多语言方面的情况,有助于开发能适应不同语言的检测工具。
4 Future of AI-generated Text Forensics(AI生成文本取证的未来)
大语言模型的快速发展预示着一个以AI为中心的未来,在这个未来,AI系统可能会部分甚至完全接管许多日常写作任务。但与此同时,这种转变也带来了巨大挑战和更复杂的威胁情况。论文接下来的部分探讨了这些潜在挑战。
4.1 Future Threat Landscape(未来威胁格局)
4.1.1 Diminishing Boundary(界限模糊)
一个重大挑战是人类撰写文本和AI生成文本之间的界限越来越模糊。目前的检测系统是基于人类撰写的文本和AI生成的文本之间存在明显的分布差异这一前提来工作的。然而,大语言模型的最新进展显著提升了它们模仿人类写作风格的能力。最近的一项研究通过理论分析发现,如果一个语言模型足够先进,能够模仿人类文本,那么即使是最复杂的检测系统,其检测效果也只会比随机分类器略好一点(Sadasivan等人在2023年的研究)。这就意味着,未来识别AI生成文本的任务会变得越来越困难。比如,现在可能还能通过一些语言特点来区分AI生成的文章和人写的文章,但以后随着大语言模型模仿能力增强,这种区分就会变得很难。
4.2 Attacks Against Forensics(对取证系统的攻击)
多项研究表明,检测系统很容易受到基于改写的攻击(Sadasivan等人在2023年的研究)。此外,最近的发展还显示,像大语言模型这样更严重的威胁,可以很容易地被优化以逃避检测(Kumarage等人在2023d年,Nicks等人在2023年的研究)。这些类型的攻击给取证分析带来了巨大挑战,因此在未来需要更强大的应对措施。
4.2.1 LLM Variants(大语言模型变体)
最近开源大语言模型的发展出现了一种趋势,即一个强大的大语言模型发布后,很快就会出现许多基于同一基础模型的变体。这些变体是通过全量微调、参数高效微调或当前大语言模型领域中流行的对齐方法产生的。通常,这些变体是通过在特定领域的数据集或由其他先进大语言模型(如ChatGPT)生成的数据集上进行训练来实现专业化的(Gudibande等人在2023年的研究)。值得注意的例子有Alpaca(Taori等人在2023年的研究)和Vicuna(Chiang等人在2023年的研究)模型,它们都是基于Llama基础模型构建的。虽然这些大语言模型变体促进了开源大语言模型的发展,但当被对手利用时,它们会给溯源和特征描述系统带来重大挑战。例如,这些变体继承了其基础大语言模型的写作特征,有可能导致错误溯源,损害原始模型开发者的声誉。此外,恶意行为者可能会在微调或对齐阶段巧妙地融入有害意图,从而创建自己的大语言模型变体。
4.2.2 Coordinated AI Agents(协同AI智能体)
当前AI领域的一个重要趋势是AI智能体的发展。这些智能体有助于部署强大的AI模型,这些模型可以协同工作并自主运行,以完成现实世界的任务(Park等人在2023年,Murthy等人在2023年的研究)。现在的关键问题是,现有的框架是否有足够的能力来检测、溯源和描述由协同AI智能体传播的错误信息。未来,我们可能会遇到由多个大语言模型协同策划的错误信息传播活动。现有取证系统在应对此类威胁方面的有效性,仍是一个值得进一步研究的领域。比如,多个AI智能体可能会联合起来,有组织地在社交媒体上传播虚假新闻,而现有的取证系统可能很难应对这种情况。
4.3 Towards Improved Forensic Systems(改进取证系统的方向)
在当今的AI时代,使用AI系统进行各种写作任务中的文本生成是不可避免的。因此,论文预计未来特征描述将成为AI生成文本取证的最重要因素,也就是说,保护信息生态系统的主要目标将涉及理解AI生成背后的恶意意图。展望未来,作者确定了以下改进此类取证系统的机会:
4.3.1 Knowledge-Aware LLMs(知识感知大语言模型)
将人类专业知识和现有的取证知识与基于大语言模型的取证系统相结合,能极大地推动AI生成文本取证的发展(Agrawal等人在2023年的研究)。通过使用包含人类专家取证规则和知识的知识图谱来增强大语言模型(Xu和Xu在2022年,Zhang和Xie在2023年的研究),可以构建能够准确解释其决策的取证系统(Chen等人在2023年的研究),这对于特征描述至关重要。比如,在分析一段AI生成的宣传文本时,知识感知大语言模型可以借助知识图谱中的取证规则和知识,更好地判断文本背后是否有恶意意图。
4.3.2 Causality-aware Forensic Systems(因果感知取证系统)
从特征描述的角度来看,取证系统不能仅仅停留在识别层面,还需要更深入地理解文本生成背后的潜在意图,比如虚假信息或宣传材料的传播意图。为了实现这一目标,我们必须回答诸如 “为什么AI模型会生成这段文本?” 以及 “如果以不同的意图生成,这段文本会是什么样子?” 等问题。因果关系(Pearl在2009年的研究)通过解释事件之间的关系来回答 “为什么” 的问题,并通过考虑不同的因果路径及其潜在后果,让我们能够研究替代场景。因此,作者认为需要探索因果感知的AI生成文本取证,以全面理解文本生成背后的潜在意图,并提供一个完整的AI生成文本取证系统。可以从几个方向来实现这一目标,比如对AI模型的训练和输入输出配置之间的因果关系进行建模,以及通过因果推理来更深入地理解文本的意图。
5 Conclusion(结论)
AI生成文本取证领域正在迅速发展,在检测、溯源和特征描述AI生成文本方面取得了重大进展。目前的系统在区分AI生成内容和人类撰写内容方面展现出了潜力,它们利用先进技术来分析和识别细微差异。然而,这个领域也面临着持续的挑战,比如在AI技术快速进步的背景下保持检测的准确性,以及确保对新型生成模型的适应性。
展望未来,很明显AI生成文本技术和取证技术之间的 “军备竞赛” 将继续下去。AI生成文本取证研究的未来在于提高现有工具的精度,开发更具动态性的模型,使其能够适应新的AI生成文本风格,并制定道德准则来规范这些技术的使用及其影响。要确保AI生成文本取证系统在面对不断发展的AI能力时的有效性,需要研究人员、从业者和政策制定者共同努力。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)