用Shap解释Transformer多分类模型:实践指南
Shap解释Transformer多分类模型,并且基于shap库对transformer模型(pytorch搭建)进行解释,绘制变量重要性汇总图、自变量重要性、瀑布图、热图等等因为是分类模型,所以只用到了Transformer的Encoder模块,使用了4层encoder和1层全连接网络的结果,没有用embedding,因为自变量本身就有15个维度,而且全是数值,相当于自带embedding代码架
Shap解释Transformer多分类模型,并且基于shap库对transformer模型(pytorch搭建)进行解释,绘制变量重要性汇总图、自变量重要性、瀑布图、热图等等 因为是分类模型,所以只用到了Transformer的Encoder模块,使用了4层encoder和1层全连接网络的结果,没有用embedding,因为自变量本身就有15个维度,而且全是数值,相当于自带embedding 代码架构说明: 第一步:数据处理 数据是从nhanes数据库中下载的,自变量有15个,因变量1个,每个样本看成维度为15的单词即可,建模前进行了归一化处理 第二步:构建transformer模型,包括4层encoder层和1层全连接层 第三步:评估模型,计算测试集的recall、f1、kappa、pre等 第四步:shap解释,用kernel解释器(适用于任意机器学习模型)对transformer模型进行解释,并且分别绘制每个分类下,自变量重要性汇总图、自变量重要性柱状图、单个变量的依赖图、单个变量的力图、单个样本的决策图、多个样本的决策图、热图、单个样本的解释图等8类图片 代码注释详细,逻辑简单,有python基础就可以看懂,包括原始数据、源代码、详细的说明文档和运行结果图,下载后先看说明文档,可一键运行出图,可以替换为自己的数据,可以进行简单的 全部代码本人手写,shap解释部分替大家踩了很多坑,终于整理出了可用的模板,书写不易,谢谢理解~

在机器学习领域,理解模型的决策过程至关重要。今天,咱们就来聊聊如何使用Shap对基于PyTorch搭建的Transformer多分类模型进行解释,而且还会涉及各种炫酷的可视化图表绘制。
数据处理
咱们的数据来自nhanes数据库,有15个自变量和1个因变量。由于自变量本身就是15维的数值,就像自带embedding一样,建模前需要对数据进行归一化处理。下面看看简单的代码示例:
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
# 假设数据从csv文件读取
data = pd.read_csv('nhanes_data.csv')
X = data.drop('target_column', axis = 1)
y = data['target_column']
scaler = MinMaxScaler()
X_scaled = scaler.fit_transform(X)在这段代码里,首先用pandas读取数据,接着把自变量和因变量分开。然后通过MinMaxScaler对自变量进行归一化,将数据缩放到0到1的区间,这有助于模型更好地收敛。
构建Transformer模型
咱们的模型只用到Transformer的Encoder模块,包含4层encoder和1层全连接网络。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader
class TransformerEncoderBlock(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1):
super(TransformerEncoderBlock, self).__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, src):
src2 = self.self_attn(src, src, src)[0]
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.relu(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
class TransformerModel(nn.Module):
def __init__(self, d_model, nhead, num_layers, num_classes):
super(TransformerModel, self).__init__()
self.encoder_layers = nn.ModuleList([
TransformerEncoderBlock(d_model, nhead) for _ in range(num_layers)
])
self.fc = nn.Linear(d_model, num_classes)
def forward(self, x):
for encoder_layer in self.encoder_layers:
x = encoder_layer(x)
x = x.mean(dim = 1)
x = self.fc(x)
return x这里定义了TransformerEncoderBlock,它包含多头注意力机制和前馈神经网络。TransformerModel则是把这些块堆叠起来,并在最后接上一个全连接层用于分类。
评估模型
训练完模型后,咱们要对它进行评估,计算测试集的recall、f1、kappa、pre等指标。
from sklearn.metrics import recall_score, f1_score, cohen_kappa_score, precision_score
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = TransformerModel(d_model = 15, nhead = 3, num_layers = 4, num_classes = num_classes).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr = 0.001)
# 假设已经划分好训练集和测试集
train_dataset = TensorDataset(torch.FloatTensor(X_train_scaled), torch.LongTensor(y_train))
test_dataset = TensorDataset(torch.FloatTensor(X_test_scaled), torch.LongTensor(y_test))
train_loader = DataLoader(train_dataset, batch_size = 32, shuffle = True)
test_loader = DataLoader(test_dataset, batch_size = 32, shuffle = False)
for epoch in range(num_epochs):
model.train()
for batch_x, batch_y in train_loader:
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
optimizer.zero_grad()
output = model(batch_x.unsqueeze(1))
loss = criterion(output, batch_y)
loss.backward()
optimizer.step()
model.eval()
with torch.no_grad():
all_preds = []
all_labels = []
for batch_x, batch_y in test_loader:
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
output = model(batch_x.unsqueeze(1))
_, preds = torch.max(output, 1)
all_preds.extend(preds.cpu().numpy())
all_labels.extend(batch_y.cpu().numpy())
recall = recall_score(all_labels, all_preds, average='weighted')
f1 = f1_score(all_labels, all_preds, average='weighted')
kappa = cohen_kappa_score(all_labels, all_preds)
pre = precision_score(all_labels, all_preds, average='weighted')这段代码里,先定义了损失函数和优化器,接着在训练循环里进行反向传播和参数更新。测试阶段,计算预测结果并通过sklearn的函数计算各种评估指标。
Shap解释
终于到了Shap解释部分,这可是重头戏。咱们使用kernel解释器,它适用于任意机器学习模型。
import shap
import matplotlib.pyplot as plt
explainer = shap.KernelExplainer(model, torch.FloatTensor(X_train_scaled).unsqueeze(1).to(device))
shap_values = explainer.shap_values(torch.FloatTensor(X_test_scaled).unsqueeze(1).to(device))
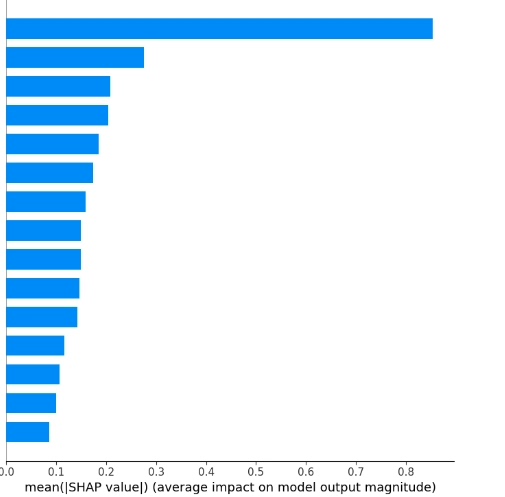
# 绘制自变量重要性汇总图
shap.summary_plot(shap_values, torch.FloatTensor(X_test_scaled), plot_type='bar')
plt.show()
# 绘制自变量重要性柱状图
shap.summary_plot(shap_values, torch.FloatTensor(X_test_scaled))
plt.show()
# 单个变量的依赖图
shap.dependence_plot(0, shap_values, torch.FloatTensor(X_test_scaled))
plt.show()
# 单个变量的力图
# 这里假设力图是指force plot,单个变量的情况有点特别,可能需要结合具体情况
shap.force_plot(explainer.expected_value[0], shap_values[0][0], torch.FloatTensor(X_test_scaled)[0])
plt.show()
# 单个样本的决策图
shap.decision_plot(explainer.expected_value[0], shap_values[0][0], torch.FloatTensor(X_test_scaled)[0])
plt.show()
# 多个样本的决策图
shap.decision_plot(explainer.expected_value[0], shap_values[0][:10], torch.FloatTensor(X_test_scaled)[:10])
plt.show()
# 热图
shap.plots.heatmap(shap_values)
plt.show()
# 单个样本的解释图
shap.force_plot(explainer.expected_value[0], shap_values[0][0], torch.FloatTensor(X_test_scaled)[0], matplotlib=True)
plt.show()在这段代码里,首先初始化KernelExplainer,然后计算Shap值。接着通过不同的shap函数绘制各种解释性图表,像自变量重要性汇总图可以直观看到各个自变量对模型输出的重要程度;依赖图能看到单个自变量与模型输出的关系等等。
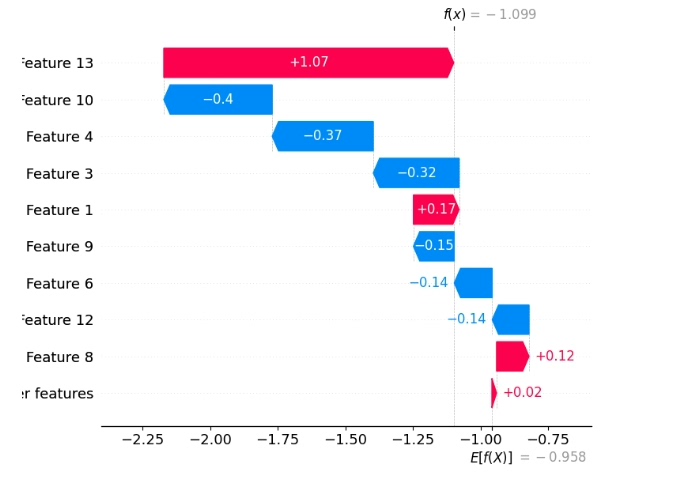
所有代码都是本人手写,特别是Shap解释部分,踩了不少坑才整理出这个可用模板。整个项目包含原始数据、源代码、详细的说明文档和运行结果图,下载后先看说明文档,就能一键运行出图,还可以替换为自己的数据,方便大家使用~希望这篇博文能帮助大家更好地理解和使用Shap解释Transformer多分类模型。
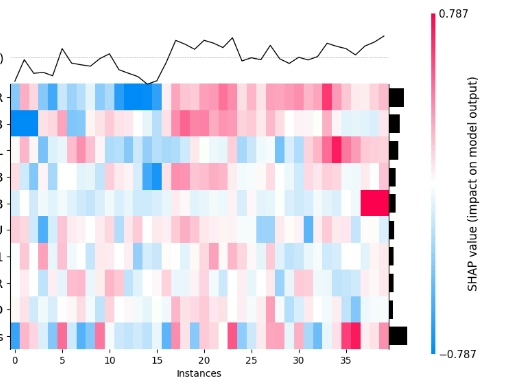
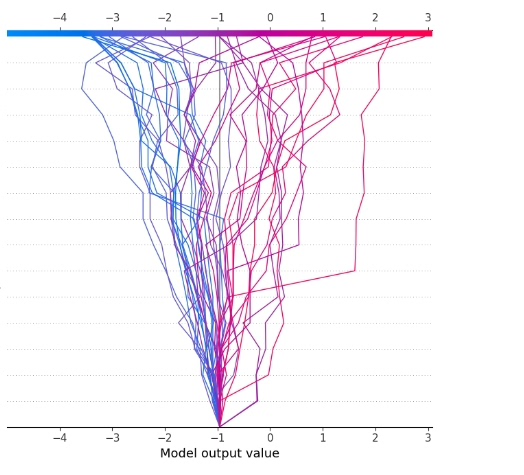
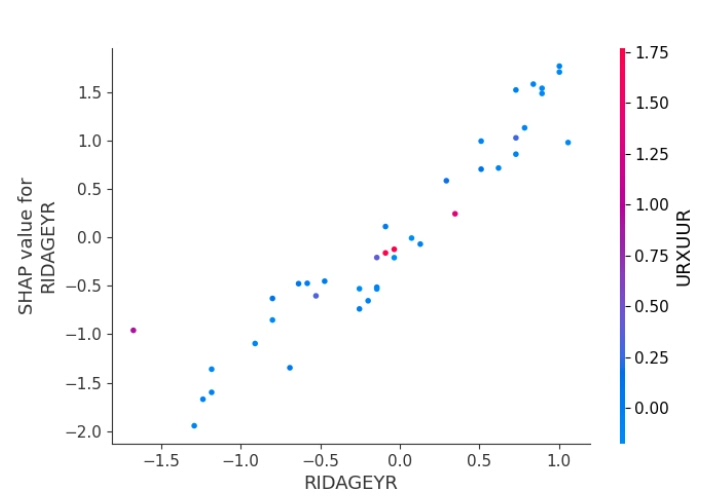

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)