淘天算法1面:PPO/DPO/GRPO的区别?
其中 i 是代表采样的 group=G 中的第 i 个输出,其奖励值是通过采样的一组输出的 reward model 的平均值计算而来,它计算的是每个策略相对其他策略的相对优势,而不是绝对的累计奖励。除了以上 GRPO 采用 group 采样的方案之外,GRPO 使用当前样本的奖励值-所有样本奖励值的平均值,并除以所有样本奖励值的标准差,来进行归一化,保障最终算出来的奖励值属于正态分布。而 DPO
是时候准备面试和实习了。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
喜欢本文记得收藏、关注、点赞。

随着 chatGPT 的横空出世,大模型开启了如火如荼的发展。
当前大模型的优化,除了在模型结构、数据等角度,都在强化学习上做了很大的优化;包括后续涉及到大模型在下游业务场景的应用,也会涉及到强化学习的落地。
但实际的业务场景不同,显卡资源不同,目标效果要求不同,都会涉及到大模型强化学习的算法选型。
本文重点介绍 PPO/DPO/GRPO 三者的区别和落地应用。
01
强化学习历史
强化学习的发展经历了如下链路:PG(policy gradient,即策略梯度)=>TRPO=>PPO=>DPO=>GRPO。其中最大的区别在于策略数据采样的在线 or 离线的差异。
并且为了降低计算复杂度和资源需求,才发展出了从在线策略到离线策略的路径,DPO 就属于离线策略。不过 DPO 已经不属于严格的强化学习。
on-policy:边实践边学,数据利用率低。
off-policy:观察他人学习,数据利用率高。
02
DPO
DPO 属于直接偏好对齐方法,是在 2023 年由斯坦福大学研究团队提出的偏好优化算法,主要为了解决 PPO 训练难度高导致不容易收敛,资源消耗大的问题。
主要的方法是通过引入人类偏好数据,将在线策略优化,修改为通过二元交叉熵直接拟合人类偏好数据的离线策略。
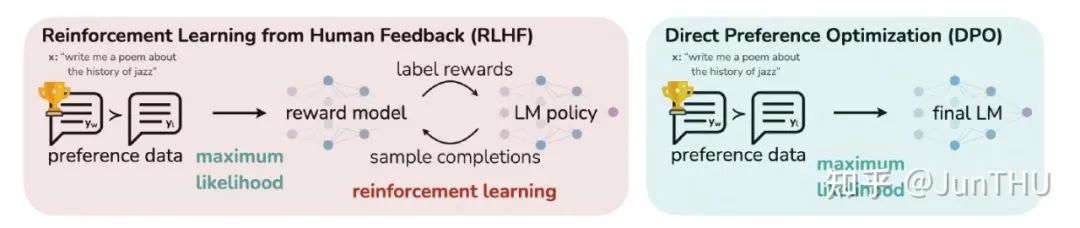
RLHF vs DPO
(1)DPO 优点
训练流程短:RLHF 的过程,需要提前训练好一个 reward model,但 DPO 由于不需要引入 reward model,因此也无需这个阶段。
DPO 根据预先给定的偏好数据直接进行学习,属于离线策略,不需要进行在线数据采样。
训练资源要求低:其中 RLHF 需要策略模型(Policy Model)、参考模型(Reference Model)、奖励模型(Reward Model)、价值模型(Value Model)。
而 DPO 仅需要前两个模型,并且参考模型属于可选加载,可以通过将参考模型的输出结果预先录制好,在训练时就可以不加载。因此对于训练资源显存等要求低。
稳定性高:DPO 属于有监督学习(通过概率匹配直接优化策略),摆脱了强化学习由于高方差带来的不稳定(由于奖励稀疏 or 噪声造成)。
DPO 可以通过人类偏好数据,用二元交叉熵对策略进行优化,而不需要多次进行在线数据采样进行优化。其中,y_w 为偏好数据,y_l 为非偏好数据。
训练难度低:其中 DPO 仅需要关注学习率和偏好权重 β,而 RLHF 需要同时关注策略更新幅度、奖励模型置信度等。

DPO 目标函数
(2)DPO 缺点
容易过拟合:DPO 由于缺少 reward model 的泛化,因此容易直接拟合人类偏好数据,造成过拟合。
需求更大标注数据量:相比 PPO 等,DPO 的效果表现更依赖标注数据量。
多任务适配较难:由于 DPO 仅依赖数据,所以如果需要进行多任务的对比,则需要从头标注涉及到多个维度的数据。
但是在线策略的方法可以通过单个维度的数据,训练不同的多个 reward model,引入多维度的奖励。
03
GRPO vs PPO
为了在 PPO 和 DPO 之间取得平衡,deepseek 提出了 GRPO(群组相对优化策略),在一定程度上能够通过去掉价值模型 Value Model,缓解 PPO 对于显存的瓶颈,确保策略更新的稳定性和高效性;
同时保留了 Reward Model,避免了 DPO 因为直接拟合人类偏好数据,而容易造成的过拟合和效果不佳。
其中 GRPO 跟 PPO 的重要区别,主要是去掉了 Value Model,同时使用 Policy Model 的多个 output 采样的 Reward Model 输出的多个奖励的平均值作为优势函数。
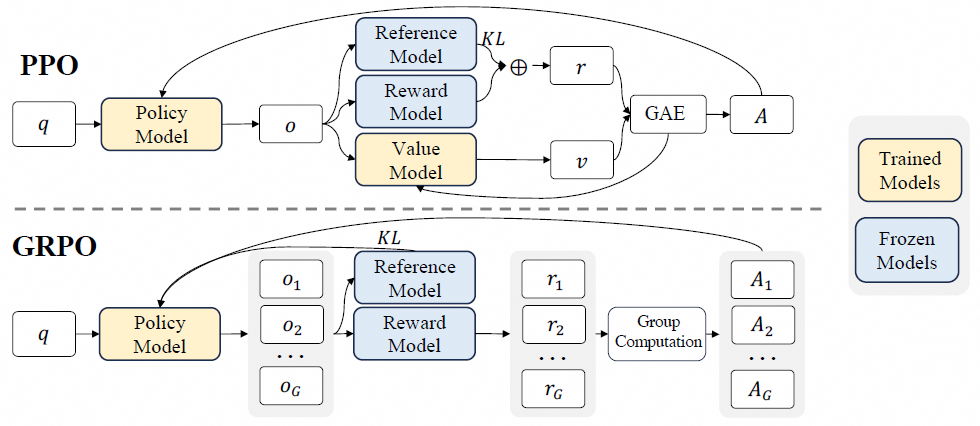
PPO vs GRPO 流程算法对比
通过对比 GRPO 和 PPO 的目标函数,可以得出两者存在以下差异:
(1)优势函数不同
其中 GRPO 采用的是一种相对奖励的方式,它舍弃了价值模型。它的优势函数为:
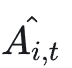
其中 i 是代表采样的 group=G 中的第 i 个输出,其奖励值是通过采样的一组输出的 reward model 的平均值计算而来,它计算的是每个策略相对其他策略的相对优势,而不是绝对的累计奖励。
PPO 的优势函数为 A_t,是直接通过 Value Model 计算而来。
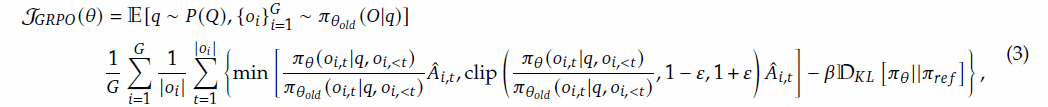
GRPO 目标函数
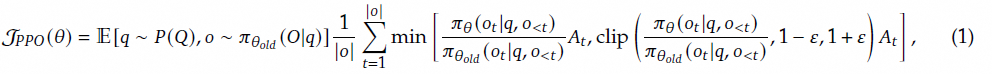
PPO 目标函数
(2)奖励值的归一化方式不同
除了以上 GRPO 采用 group 采样的方案之外,GRPO 使用当前样本的奖励值-所有样本奖励值的平均值,并除以所有样本奖励值的标准差,来进行归一化,保障最终算出来的奖励值属于正态分布。
其中 r_i 为当前奖励值,r 为所有采样样本奖励值。
PPO 则是通过时间超参来调整过往时间窗口的奖励值在最终策略更新中的权重,其中 T 为目前累计的时间窗口大小,λ=1,γ∈(0,1),为折扣因子。
此外,PPO 还存在一个价值模型来计算每个状态的价值函数,通过这个价值函数来计算优势函数,最终用于策略更新。
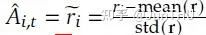
GRPO 奖励值计算方法
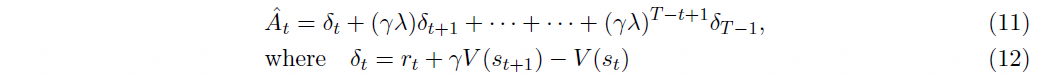
PPO 奖励值计算方法
(3)KL 散度的作用范围不同
KL 散度在 GRPO 的目标函数直接放在了损失函数,这降低了奖励函数的计算复杂度。
并且它的计算方案能够保证进行归一化的KL值每次都是正值。其中 π_ref 为 Reference Model 输出,πθ 为 Policy Model 输出。
KL 散度在 PPO 是放在奖励函数中。
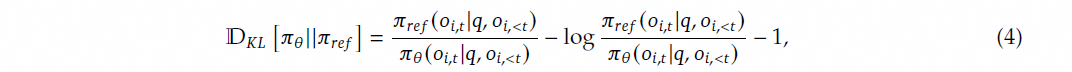
GRPO 的 KL 散度计算公式
除了以上的不同点之外,GRPO 和 PPO 都采用了裁剪策略来防止策略发生大幅度的变化,导致优化不稳定,即这里的 clip 策略。
在 PPO 中的体现如下,其中:
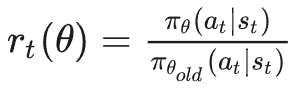
为新策略和旧策略的比值, 通过步长 𝜖 来控制更新的幅度。
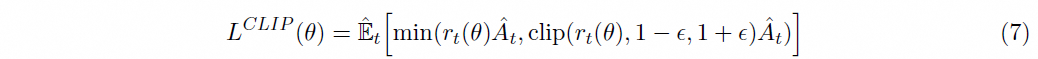
PPO 的 clip 网络计算公式
整体上来讲,PPO 主要是通过 CLIP 的裁剪梯度的方案来保障更新的稳定性;
GRPO 除了沿用了这个方案之外,还采用 group 采样的累计奖励值作为优势函数的替代,降低了训练网络的复杂度,保持了在大规模模型应用场景下的稳定性和效率。
04
DPO vs RLHF
训练流程:其中 DPO 因为不依赖 Reward Model,所以只有一个训练流程,而 PPO、GRPO 等在线策略需要先训练 Reward Model,再进行对齐,需要两个阶段。
显卡资源需求:对于显卡的需求 PPO(加载 4 个模型)>GRPO(加载 3 个模型)>DPO(加载 1 个必选模型+1 个可选模型)
对样本依赖:其中 PPO、GRPO 因为通过 Reward Model 来进行对齐,有一定的泛化作用,因此对样本标注的精度和数据量依赖相对较小;DPO 与之相反。
灵活扩展性:当涉及到多个业务场景时,其中 PPO、GRPO 可以通过多个 Reward Model 来进行灵活的扩展,而不需要从头标注多业务维度的人工偏向数据;DPO 则需要重新构建数据,整体的灵活性和可扩展性较差。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)