大厂都在用的12-Factor Agent架构,终于有人讲清楚了!前言
《12-FactorAgents:构建生产级AIAgent的核心原则》摘要 本文系统介绍了构建可靠LLM应用的12项核心原则,旨在解决传统Agent架构的四大痛点:不可预测的控制流、困难错误处理、混乱状态管理和差可观测性。12-Factor方法论提出将确定性代码与LLM能力巧妙结合,通过结构化工具调用、主动管理提示词与上下文、统一状态管理、小型专注Agent设计等原则,显著提升系统可靠性。文章强调
大厂都在用的12-Factor Agent架构,终于有人讲清楚了!
前言
在构建生产级AI Agent的过程中,许多开发者都会遇到同样的问题:使用现有框架可以快速达到70-80%的质量标准,但要突破这个瓶颈并实现真正的生产可用性,往往需要深度定制甚至重新构建。
本文基于《12-Factor Agents》理念,总结了构建可靠LLM应用的核心原则,帮助开发者避开常见陷阱,构建真正可用的AI系统,欢迎关注阿东玩AI。
本文目录:

核心理念:从循环到工程
传统Agent的困境
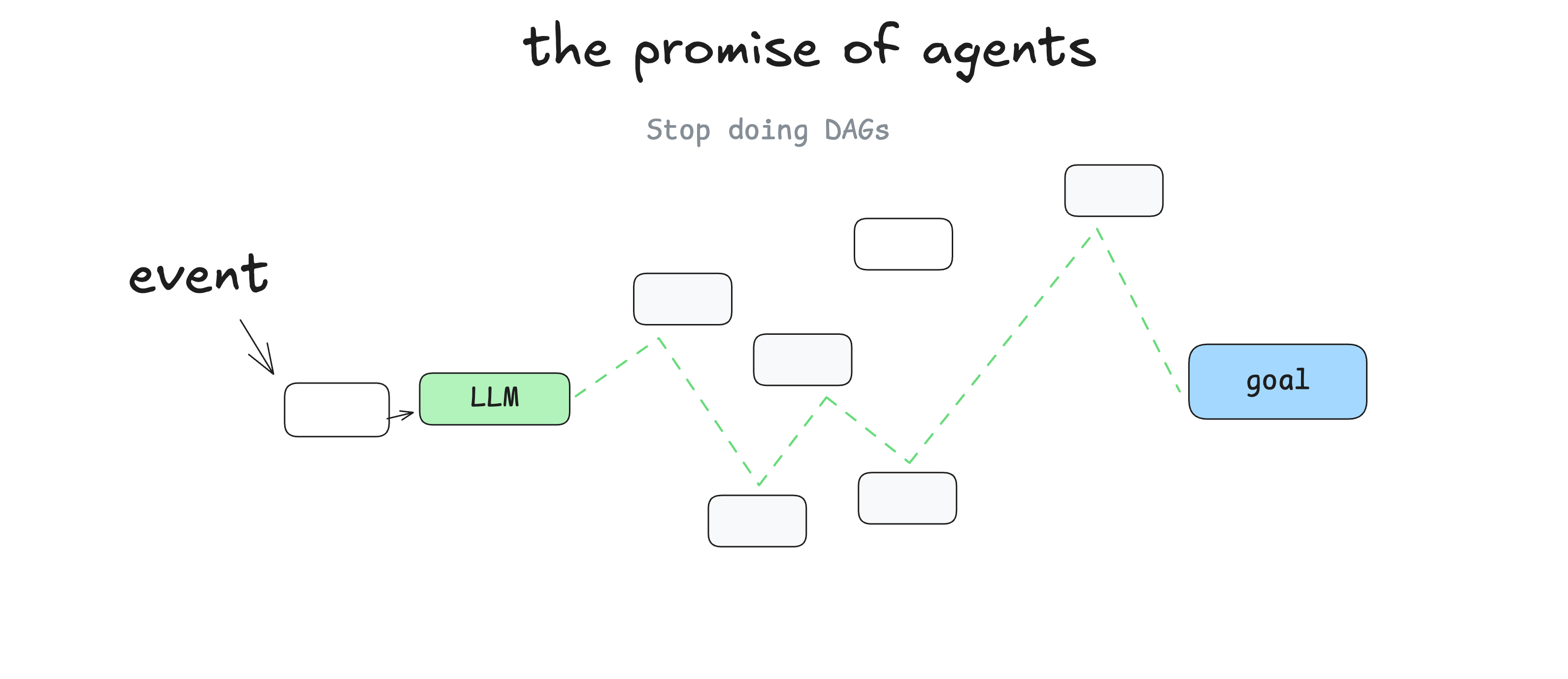
这里的实现是:你可以减少软件编写量,只需将图的“边”交给 LLM,让它自己找出节点即可。你可以从错误中恢复,减少代码编写量。
大多数Agent框架采用的是简单的循环模式:
initial_event = {"message": "..."}
context = [initial_event]
while True:
next_step = await llm.determine_next_step(context)
context.append(next_step)
if (next_step.intent === "done"):
return next_step.final_answer
result = await execute_step(next_step)
context.append(result)
这种方法的问题在于:
-
控制流不可预测:完全依赖LLM决策
-
错误处理困难:缺乏结构化的异常处理
-
状态管理混乱:执行状态与业务状态混合
-
可观测性差:难以调试和监控
12-Factor方法论
真正优秀的Agent不是"给LLM一堆工具让它自由发挥",而是大部分由确定性代码构成,在关键决策点巧妙地融入LLM能力。
我们没有给智能体提供大量的工具或任务。LLM 的主要价值在于解析人类的纯文本反馈并提出更新的行动方案。我们尽可能地隔离任务和上下文,以使 LLM 专注于一个 5-10 步的小型工作流程。
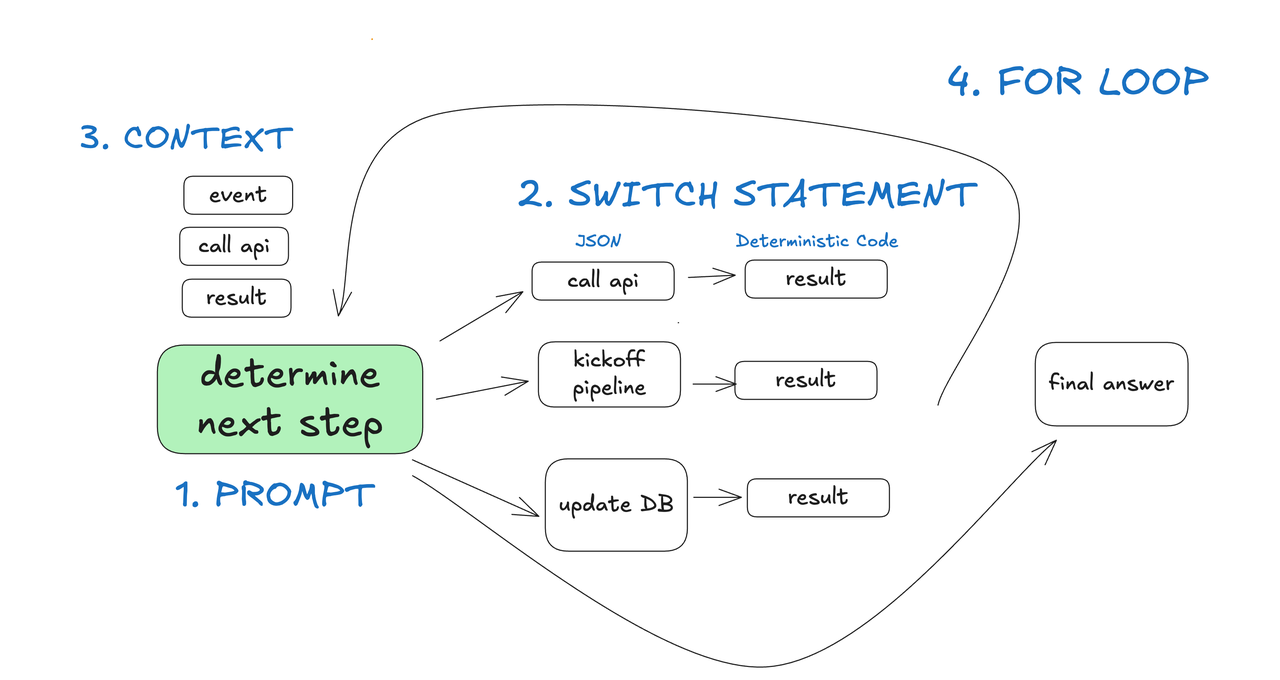
那么Agent到底是什么?
-
提示- 告诉 LLM 如何操作,以及它有哪些可用的“工具”。提示的输出是一个 JSON 对象,它描述了工作流程的下一步(“工具调用”或“函数调用”)。
-
switch 语句- 根据 LLM 返回的 JSON,决定如何处理它。
-
累积上下文- 存储已发生的步骤及其结果的列表
-
for 循环- 直到 LLM 发出某种“终端”工具调用(或纯文本响应),将 switch 语句的结果添加到上下文窗口并要求 LLM 选择下一步。
12个核心原则
1. 自然语言到工具调用 (Natural Language to Tool Calls)
原则:将自然语言输入转换为结构化的工具调用,而非直接文本输出。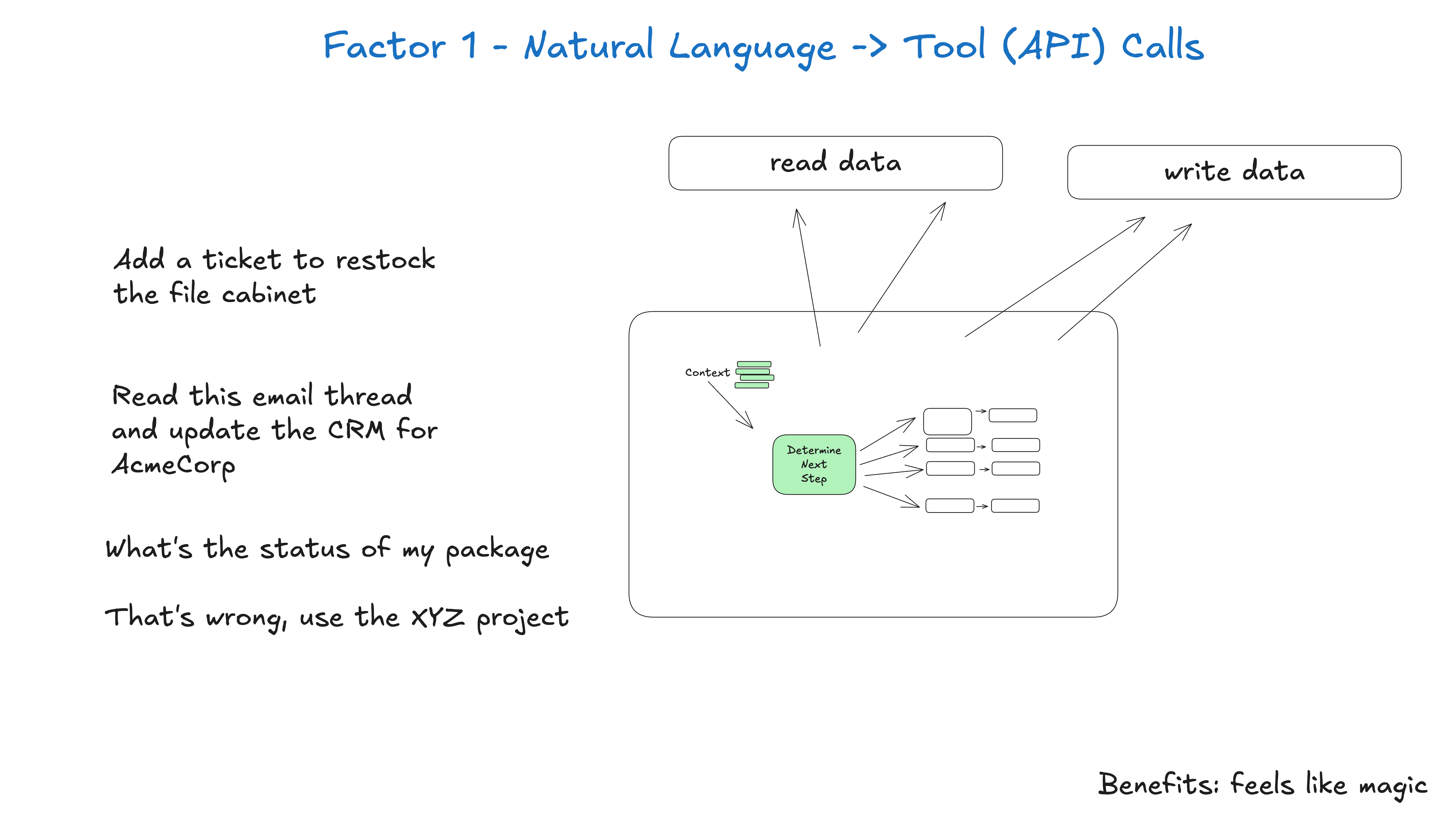
// ❌ 错误方式 - 依赖文本解析
const response = await llm.complete("帮我发送邮件给张三")
// 需要解析:"我将为您发送邮件..."
// ✅ 正确方式 - 结构化输出
const toolCall = await llm.generateToolCall(prompt, tools)
// 返回:{ tool: "send_email", params: { to: "张三", ... } }
2. 拥有你的提示词 (Own Your Prompts)
原则:将提示词作为代码资产管理,而非隐藏在框架中。

-
提示词应该版本化管理
-
支持A/B测试和灰度发布
-
提供清晰的提示词模板系统
3. 拥有你的上下文窗口 (Own Your Context Window)
原则:主动管理上下文内容,而非被动累积。
您不一定需要使用基于标准消息的格式来向 LLM 传达上下文。
在任何特定时刻,你向代理机构的 LLM 提供的输入都是“这是目前为止发生的事情,下一步是什么”
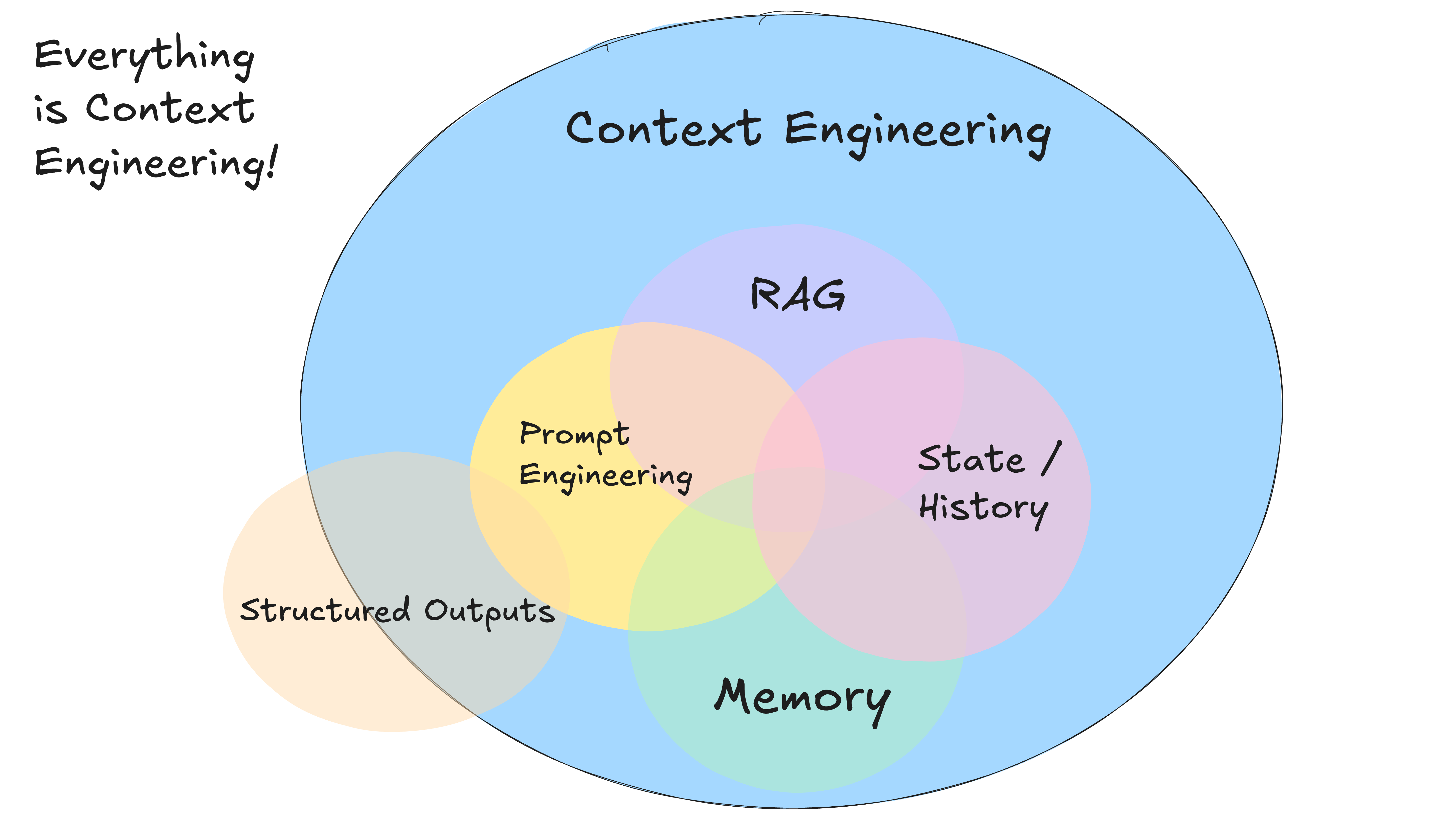
一切都与上下文工程有关。LLM是无状态函数,它将输入转化为输出。为了获得最佳输出,你需要为它们提供最佳输入。
创造良好的环境意味着:
-
你给模特的提示和指示
-
您检索的任何文档或外部数据(例如 RAG)
-
任何过去的状态、工具调用、结果或其他历史记录
-
任何来自相关但独立的历史/对话的过去信息或事件(记忆)
-
关于输出什么类型的结构化数据的说明
class ContextBuilder {
buildContext(userMessage: string, taskState: TaskState): Message[] {
return [
this.buildSystemPrompt(taskState),
...this.selectRelevantHistory(userMessage, taskState),
this.buildCurrentTask(taskState),
{ role: "user", content: userMessage }
]
}
selectRelevantHistory(query: string, state: TaskState): Message[] {
// 基于相似度或重要性选择历史消息
return this.vectorSearch(query, state.messageHistory)
.slice(0, this.maxHistoryTokens)
}
}
拥有上下文窗口的主要好处:
-
信息密度:以最大化 LLM 理解的方式构建信息
-
错误处理:以有助于 LLM 恢复的格式包含错误信息。考虑在错误和失败的调用解决后将其从上下文窗口中隐藏。
-
安全性:控制传递给 LLM 的信息,过滤掉敏感数据
-
灵活性:根据你的使用情况调整格式
-
令牌效率:优化上下文格式以提高令牌效率和 LLM 理解
上下文包括:Prompt、说明、RAG 文档、历史记录、工具调用、记忆
请记住:上下文窗口是您与 LLM 的主要界面。掌控信息的组织和呈现方式可以显著提升代理的性能。
示例 - 信息密度 - 相同的消息,更少的标记:
4. 工具即结构化输出 (Tools are Structured Outputs)
原则:将工具调用视为结构化数据生成,而非函数执行。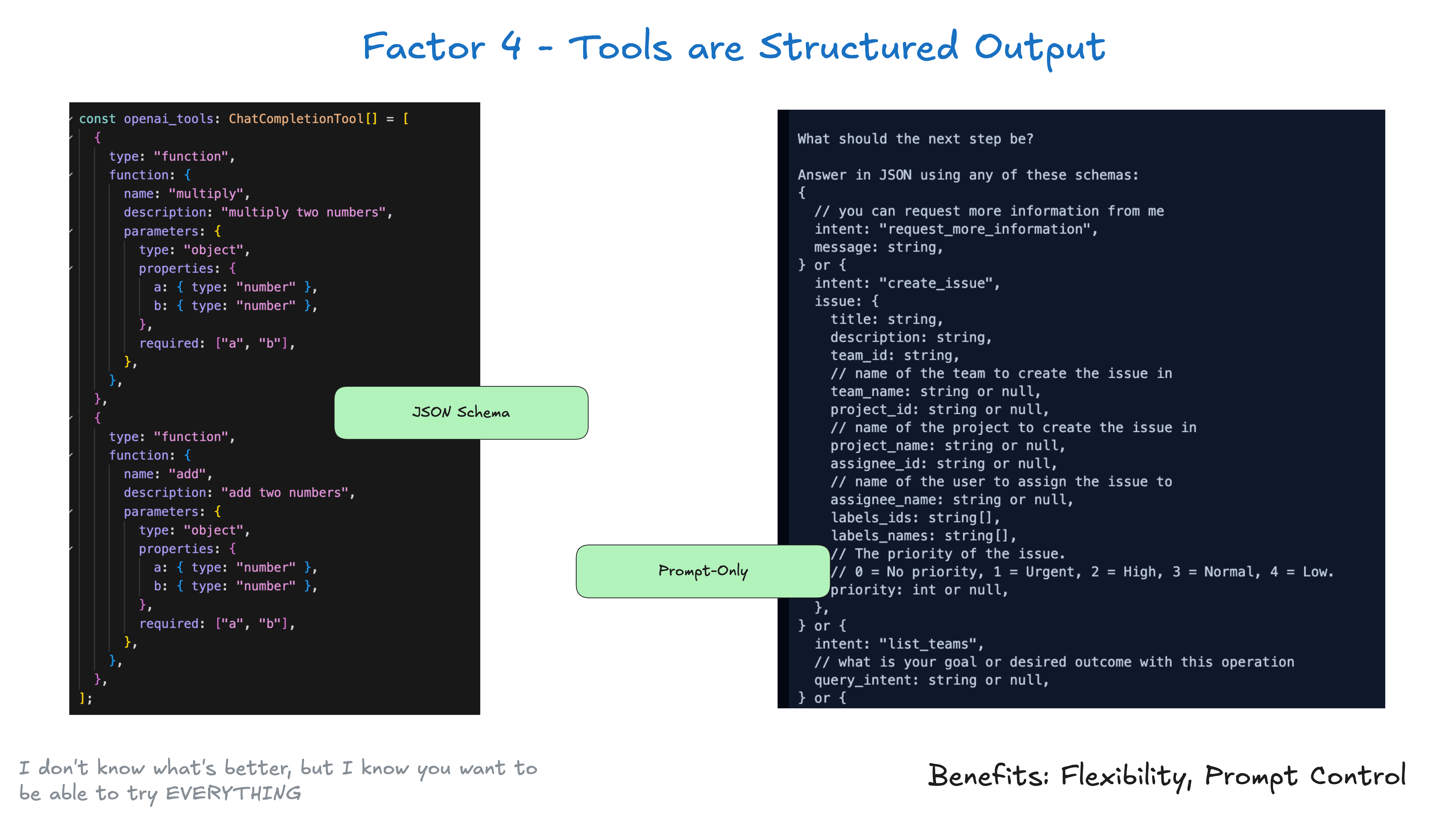
工具定义应该:
-
明确输入输出schema
-
提供详细的描述和示例
-
支持参数验证
例如,假设您有两个工具CreateIssue和SearchIssues。要求LLM“使用几种工具中的一种”实际上就是要求它输出JSON,我们可以将其解析为表示这些工具的对象。
class Issue:
title: str
description: str
team_id: str
assignee_id: str
class CreateIssue:
intent: "create_issue"
issue: Issue
class SearchIssues:
intent: "search_issues"
query: str
what_youre_looking_for: str
模式很简单:
-
LLM 输出结构化 JSON
-
确定性代码执行适当的操作(如调用外部 API)
-
捕获结果并反馈到上下文中
这样就将 LLM 的决策和应用程序的操作清晰地区分开来。LLM 决定做什么,而你的代码控制如何执行。LLM 被称为工具并不意味着你必须每次都以相同的方式执行特定的对应函数。
5. 统一执行状态和业务状态 (Unify Execution State)
原则:将Agent的执行状态与业务逻辑状态统一管理。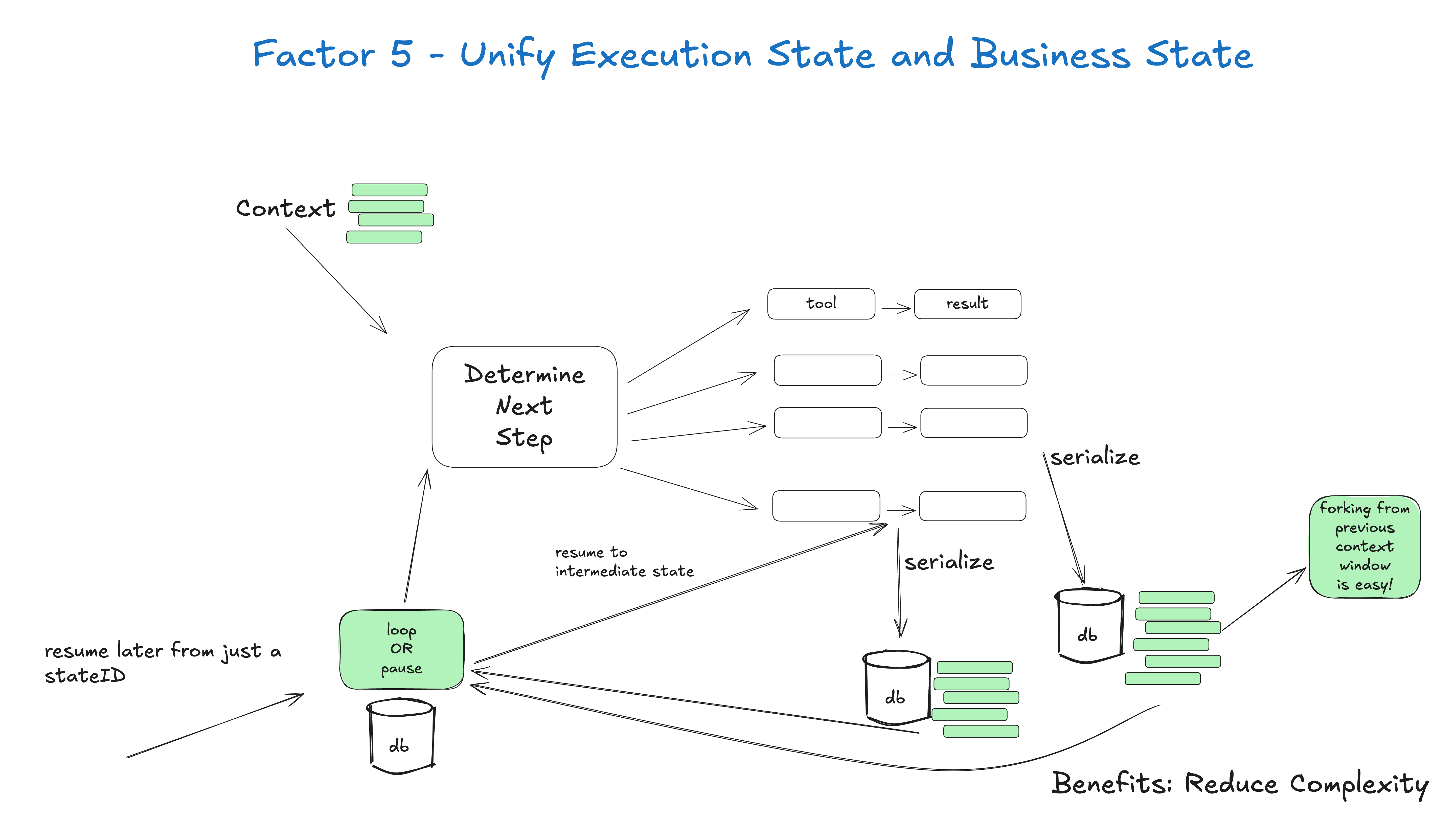
interface UnifiedState {
// 业务状态
user: User
currentTask: Task
businessData: any
// 执行状态
step: number
lastAction: string
errors: Error[]
// 上下文状态
messageHistory: Message[]
availableTools: Tool[]
}
你可能有一些内容无法放入上下文窗口,例如会话 ID、密码上下文等等,但你的目标应该是尽量减少这些内容。通过采用你可以控制实际进入 LLM 的内容。
这种方法有几个好处:
-
简单:所有状态的真相来源
-
序列化:线程可以轻松序列化/反序列化
-
调试:整个历史记录在一个地方可见
-
灵活性:只需添加新的事件类型即可轻松添加新状态
-
恢复:只需加载线程即可从任何点恢复
-
分叉:可以通过将线程的某些子集复制到新的上下文/状态 ID 中来随时分叉线程
-
人机界面和可观察性:将线程转换为人类可读的 Markdown 或丰富的 Web 应用程序 UI
6. 启动/暂停/恢复的简单API (Launch/Pause/Resume)
原则:支持长时间运行任务的暂停和恢复。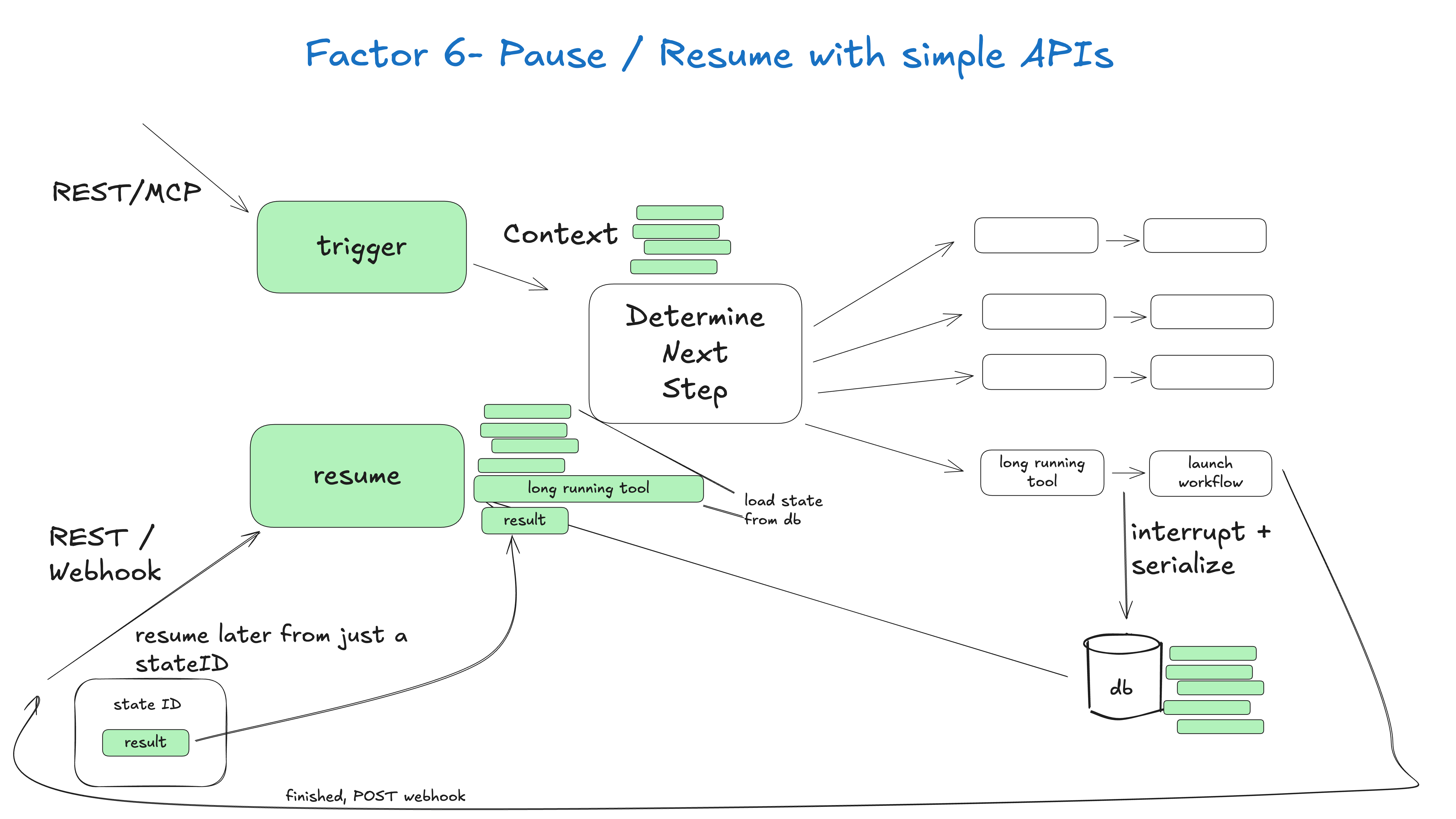
interface AgentController {
launch(initialState: State): Promise<AgentExecution>
pause(executionId: string): Promise<void>
resume(executionId: string, additionalInput?: any): Promise<void>
getStatus(executionId: string): Promise<ExecutionStatus>
}
用户、应用程序、管道和其他代理应该能够轻松地使用简单的 API 启动代理。
当需要长时间运行的操作时,代理及其协调确定性代码应该能够暂停代理。
像 webhook 这样的外部触发器应该允许代理从中断的地方恢复,而无需与代理编排器进行深度集成。
7. 通过工具调用联系人类 (Contact Humans with Tool Calls)
原则:人机交互也应该通过结构化的工具调用实现。
const tools = [
{
name: "request_human_approval",
description: "请求人类审核和批准",
parameters: {
type: "object",
properties: {
request_type: { type: "string", enum: ["approval", "input", "clarification"] },
message: { type: "string" },
context: { type: "object" },
urgency: { type: "string", enum: ["low", "medium", "high"] }
}
}
}
]
好处:
-
清晰的指示:针对不同类型的人际交往的工具允许 LLM 提供更多具体性
-
内循环 vs 外循环:在传统的 ChatGPT 风格界面之外启用代理工作流程,其中控制流和上下文初始化可能不是
Agent->Human(Human->Agent想想由 cron 或事件启动的代理) -
多人访问:可以通过结构化事件轻松跟踪和协调来自不同人的输入
-
多代理:简单的抽象可以轻松扩展以支持
Agent->Agent请求和响应 -
持久性:结合因素 6(使用简单的 API 启动/暂停/恢复),打造持久、可靠且可自省的多人工作流程
8. 拥有你的控制流 (Own Your Control Flow)
原则:不要让LLM完全控制程序流程,而是在预定义的流程中让LLM做决策。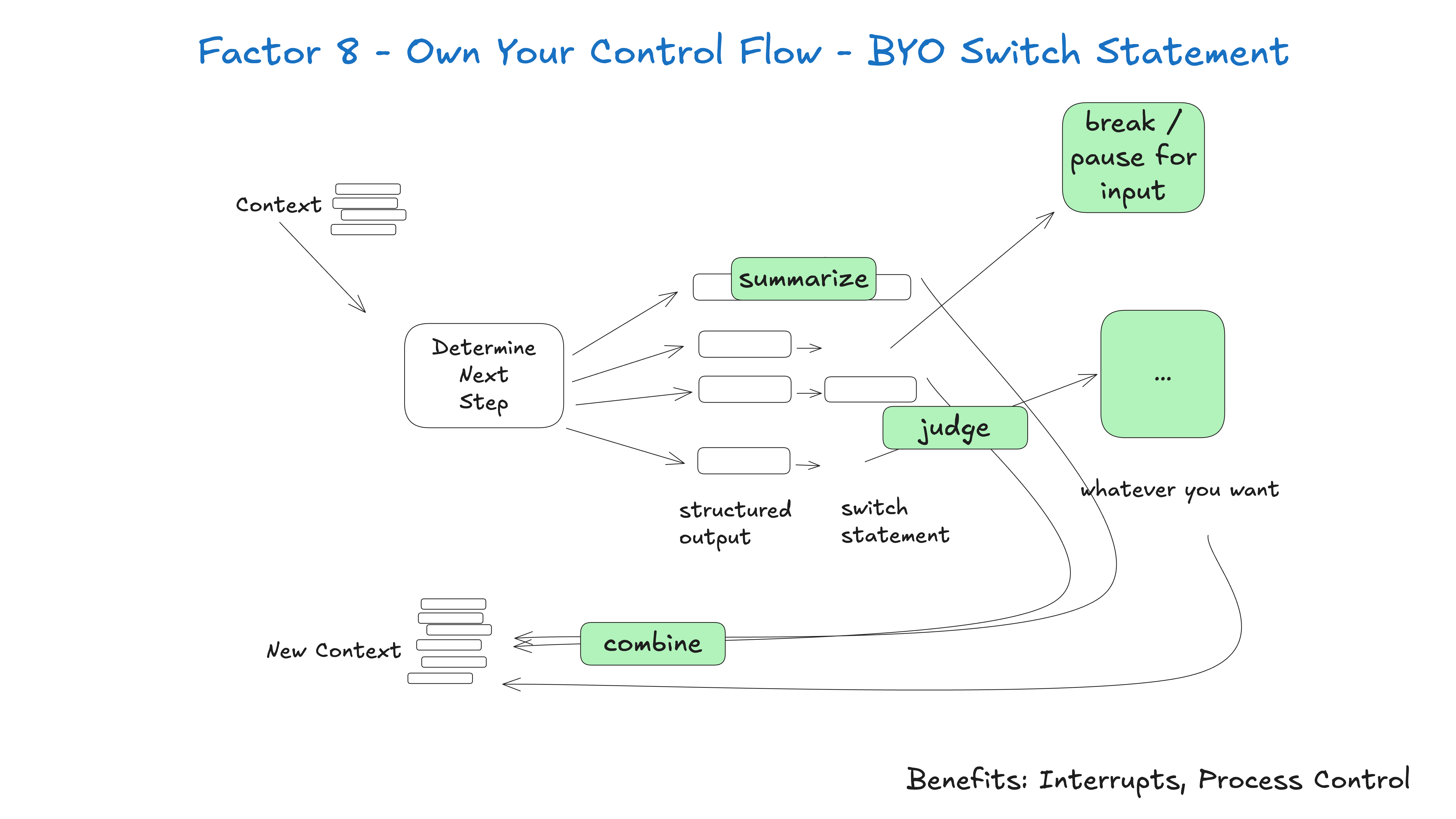
class TaskOrchestrator {
async executeTask(task: Task, state: State): Promise<State> {
// 预定义的步骤序列
const steps = [
this.validateInput,
this.gatherContext,
this.makeDecision, // 这里使用LLM
this.executeAction,
this.validateResult
]
for (const step of steps) {
state = await step(task, state)
if (state.shouldPause) {
return state
}
}
return state
}
}
构建适合您特定用例的控制结构。具体来说,某些类型的工具调用可能需要跳出循环,等待人工或其他长时间运行的任务(例如训练管道)的响应。您可能还希望包含以下自定义实现:
-
工具调用结果的汇总或缓存
-
结构化输出的LLM
-
上下文窗口压缩或其他内存管理
-
日志记录、跟踪和指标
-
客户端速率限制
-
持久睡眠/暂停/“等待事件”
9. 将错误压缩到上下文窗口 (Compact Errors)
原则:错误信息应该结构化并适合上下文窗口。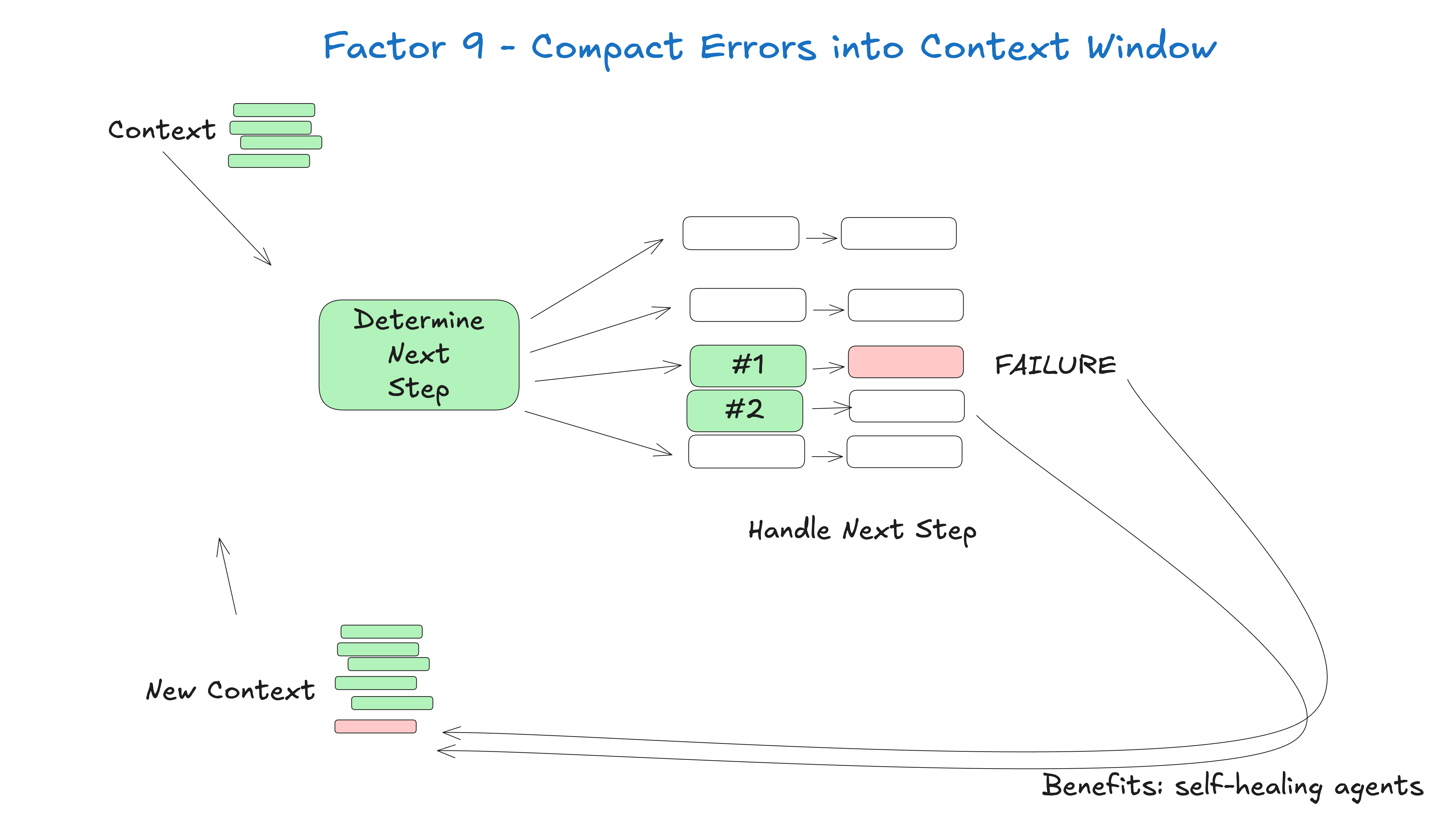
class ErrorCompactor {
compactError(error: Error, context: ExecutionContext): CompactError {
return {
type: error.constructor.name,
summary: this.summarizeError(error),
relevantStack: this.extractRelevantStack(error, context),
suggestedActions: this.suggestRecoveryActions(error),
timestamp: new Date().toISOString()
}
}
}
这点比较短,但值得一提。代理的优点之一是“自我修复”——对于短任务,LLM 可能会调用失败的工具。优秀的 LLM 能够很好地读取错误消息或堆栈跟踪,并确定在后续工具调用中需要更改的内容。
好处:
-
自我修复:LLM 可以读取错误消息并找出在后续工具调用中需要更改的内容
-
持久:即使一个工具调用失败,代理仍可继续运行
我确信你会发现,如果你这样做太多次,你的经纪人就会开始失控,并可能一遍又一遍地重复同样的错误。所以需要第10步。
10. 小而专注的Agent (Small, Focused Agents)
原则:构建多个专门化的小Agent,而非一个万能大Agent。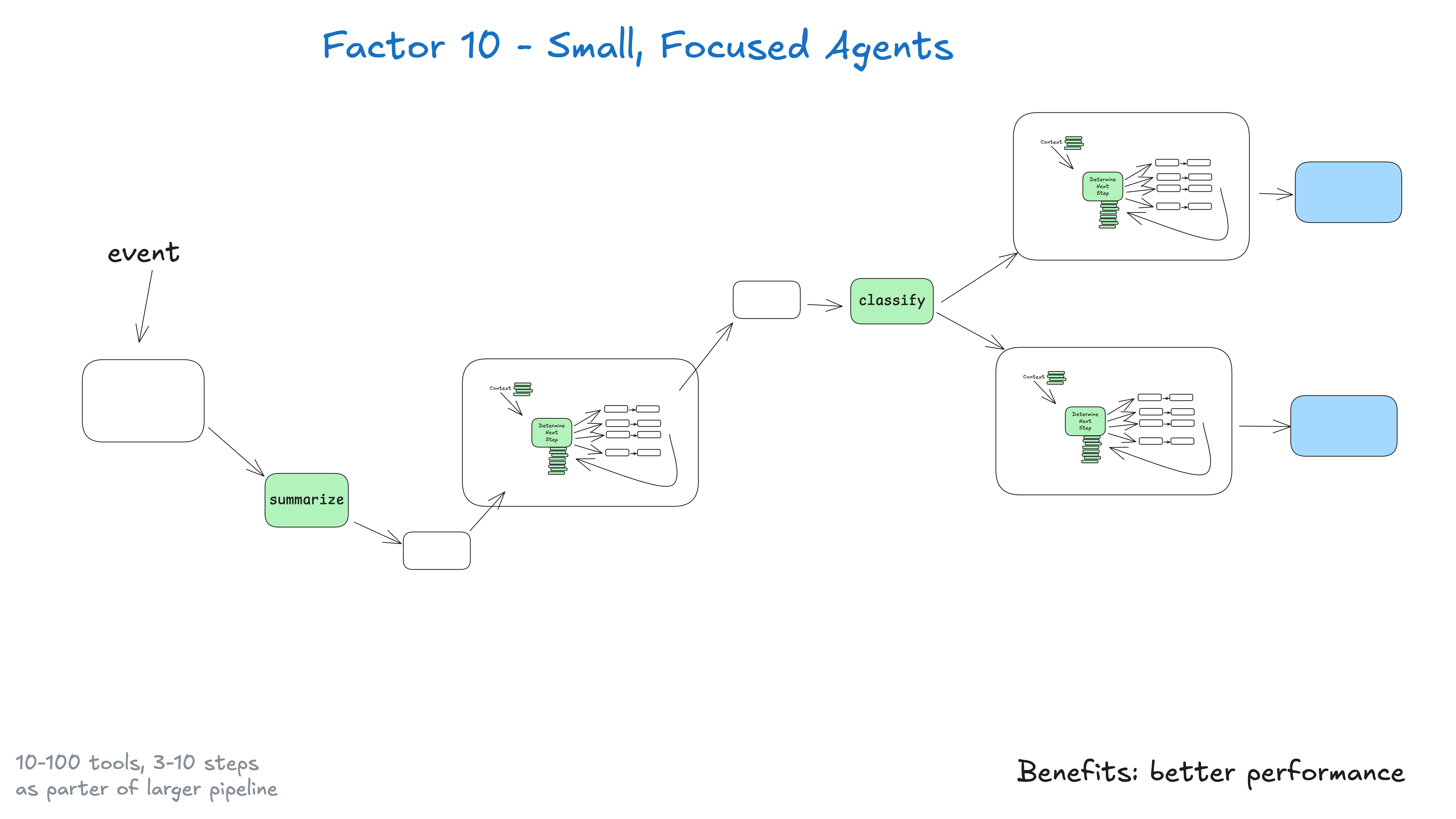
// ❌ 避免大而全的Agent
class MegaAgent {
handleEmail() { /* 处理邮件 */ }
handleCalendar() { /* 处理日历 */ }
handleDocuments() { /* 处理文档 */ }
handleCustomers() { /* 处理客户 */ }
}
// ✅ 推荐:专门化的小Agent
class EmailAgent { /* 专注邮件处理 */ }
class CalendarAgent { /* 专注日历管理 */ }
class DocumentAgent { /* 专注文档处理 */ }
小型、专注Agent的优势:
-
可管理上下文:上下文窗口越小,LLM 性能越好
-
职责明确:每个代理都有明确的范围和目的
-
更高的可靠性:减少在复杂的工作流程中迷失的机会
-
更容易测试:更简单地测试和验证特定功能
-
改进的调试:更容易识别和修复发生的问题
11. 随处触发,满足用户需求 (Trigger from Anywhere)
原则:Agent应该能从多种渠道触发,满足用户在不同场景的需求。
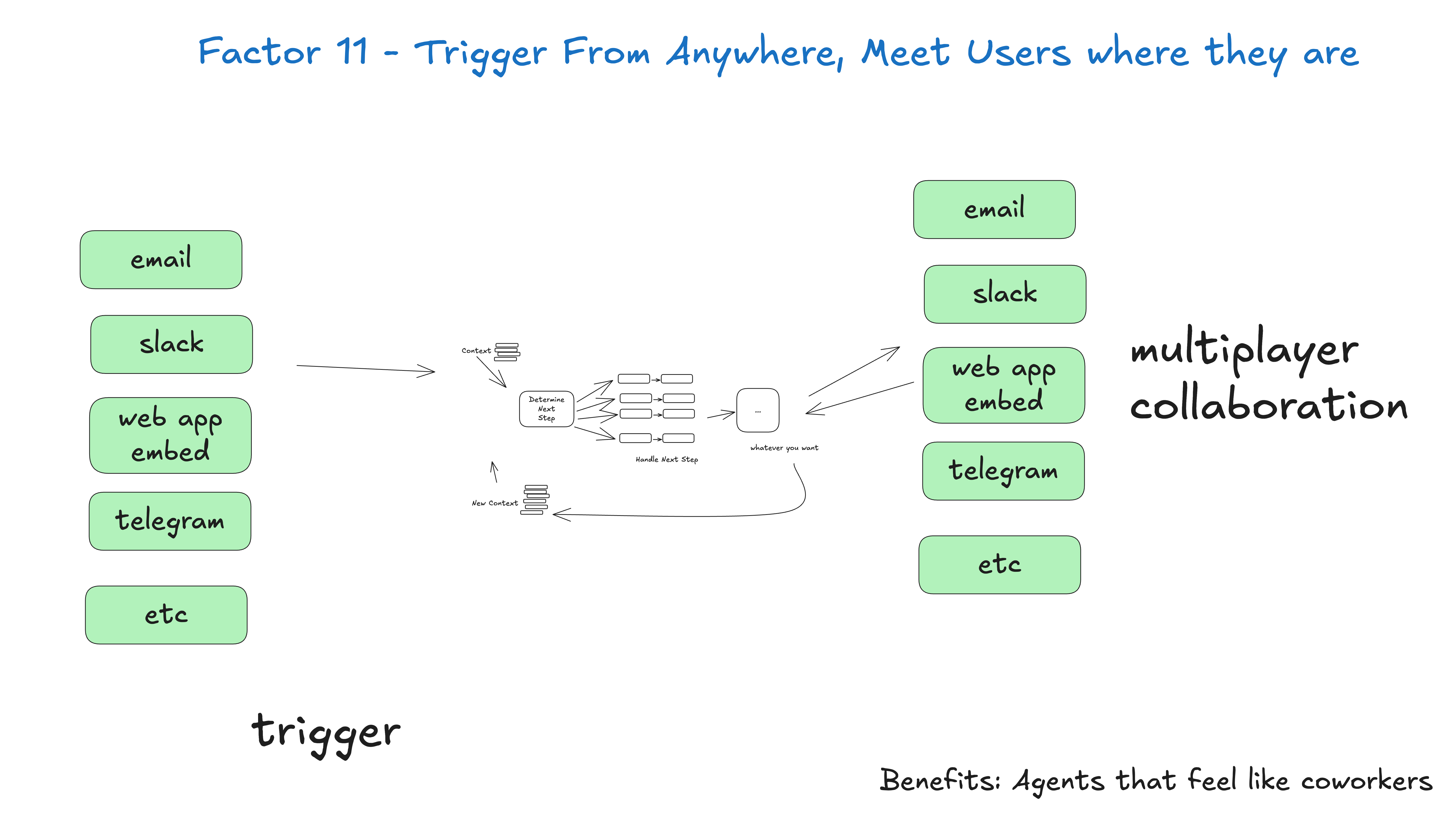
支持的触发方式:
-
API调用
-
Webhook
-
定时任务
-
消息队列
-
用户界面
12. 让Agent成为无状态Reducer (Stateless Reducer)
原则:Agent的核心逻辑应该是纯函数,便于测试和水平扩展。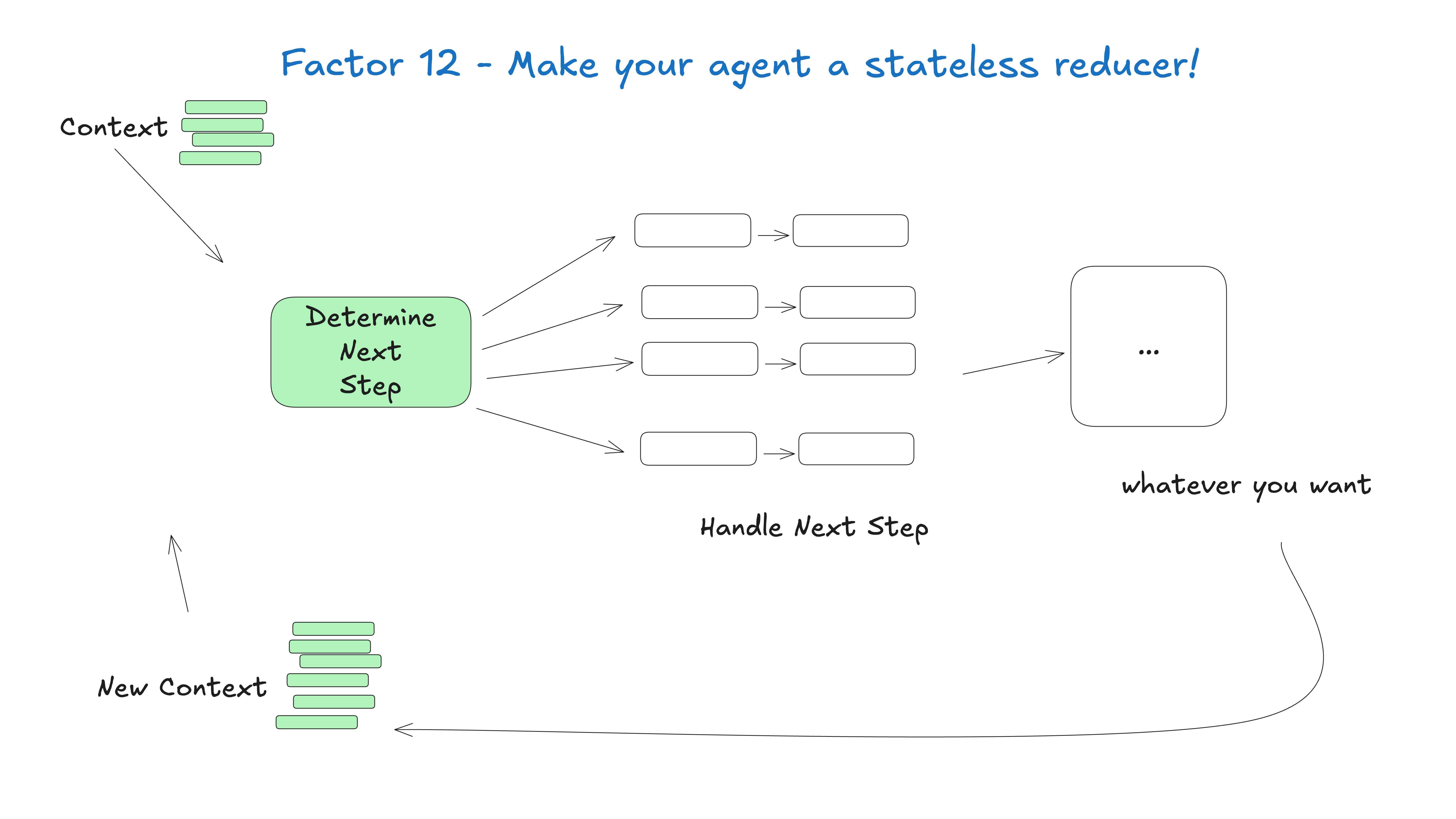
type AgentReducer = (currentState: State, event: Event) => Promise<State>
const agentReducer: AgentReducer = async (state, event) => {
// 纯函数逻辑,不依赖外部状态
switch (event.type) {
case 'USER_MESSAGE':
return await handleUserMessage(state, event)
case 'TOOL_RESULT':
return await handleToolResult(state, event)
default:
return state
}
}
实践建议
渐进式采用
不要一次性重写整个系统,而是逐步引入这些原则:
-
从Factor 1开始:先实现结构化输出
-
管理提示词:将提示词从代码中分离
-
优化上下文管理:实现智能的上下文选择
-
添加状态管理:统一业务和执行状态
-
增强控制流:预定义关键流程步骤
工具选择
推荐的技术栈:
-
结构化输出:OpenAI Function Calling、Anthropic Tool Use
-
提示词管理:BAML、LangSmith
-
状态管理:Redux模式、状态机
-
监控观测:LangSmith、Weights & Biases
质量保证
-
单元测试:对每个Factor进行测试
-
集成测试:测试完整的Agent流程
-
A/B测试:比较不同实现方案
-
监控告警:实时监控Agent性能
总结
12-Factor Agents提供了一套经过实践验证的原则,帮助开发者构建真正可用的LLM应用。关键在于:
-
不要让LLM控制一切:在结构化的框架内使用LLM能力
-
拥有核心组件:主动管理提示词、上下文和控制流
-
渐进式优化:从简单开始,逐步完善
-
重视工程实践:测试、监控、版本管理一样不能少
通过遵循这些原则,你可以构建出既强大又可靠的AI Agent,真正满足生产环境的需求。
本文基于Dex Horthy的《12-Factor Agents》整理而成。更多技术细节请参考原始文档:https://github.com/humanlayer/12-factor-agents
{
"target":"简单认识我",
"selfInfo":{
"genInfo":"大厂面试官,中科院硕士,从事数据闭环业务、RAG、Agent等,承担技术+平台的偏综合性角色。善于调研、总结和规划,善于统筹和协同,喜欢技术,喜欢阅读新技术和产品的文章与论文",
"contactInfo":"abc061200x, v-adding disabled",
"slogan":"简单、高效、做正确的事",
"extInfo":"喜欢看电影、喜欢旅游、户外徒步、阅读和学习,不抽烟、不喝酒,无不良嗜好"
}
}
```*
火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)