vLLM推理引擎教程6-Nsight Systems性能分析
本文介绍了Nvidia Nsight Systems性能分析工具,用于优化推理引擎性能。该工具通过收集CPU/GPU执行细节,生成系统时间线视图,帮助开发者分析线程活动、GPU内核执行等事件的时序关系。文章详细说明了Linux服务器安装方法(通过rpm包)和验证步骤,并提供了Python版本的GPU性能测试代码示例,包含张量创建、GPU数据传输和矩阵乘法操作。
1、概念
我们需要通过推理引擎极致地优化推理的性能,所以必不可少需要一个性能分析工具。
本文介绍Nvidia Nsight Systems,它时一个低开销的系统级性能分析器。它的核心设计目标是回答一个关键问题:“我的应用程序在运行过程中,时间到底花在了哪里”。
Nsight Systems专注于应用程序的行为,它通过收集代码在CPU和GPU上的执行细节,生成一个跨整个系统的时间线视图,让开发者能够清晰地看到线程活动、GPU内核执行、内存拷贝、API调用等事件之间地因果关系和时序关系。
2、安装
目标:在linux服务器上跟踪应用程序的执行,在windows上进行可视化分析。
下载地址:https://developer.nvidia.com/nsight-systems/get-started
Windows安装:
linux安装:
Linux安装命令:
sudo rpm -ivh NsightSystems-linux-cli-public-2025.6.1.190-3689520.rpmLinux端验证成功:
nsys --version返回结果:

3、Python版本GPU性能测试
python测试代码:
import torch
import time
print("Creating tensors on GPU...")
x = torch.randn(10000, 10000).cuda()
y = torch.randn(10000, 10000).cuda()
print("Performing matrix multiplication...")
start = time.time()
z = torch.mm(x, y)
torch.cuda.synchronize()
end = time.time()
print(f"Done! Time: {end - start:.2f} seconds")
print(f"Result shape: {z.shape}")
执行命令日志:
(vllm_python312) [work@iZuf6hp1dkg31metmko4pbZ test]$ nsys profile --trace=cuda,nvtx,osrt --output=matrix_mult_trace --force-overwrite true python test_gpu.py
Collecting data...
Creating tensors on GPU...
Performing matrix multiplication...
Done! Time: 0.10 seconds
Result shape: torch.Size([10000, 10000])
Generating '/tmp/nsys-report-1078.qdstrm'
[1/1] [========================100%] matrix_mult_trace.nsys-rep
Generated:
/data/xiehao/workspace/code/test/matrix_mult_trace.nsys-rep
将nsys-rep文件在Windows端通过GUI打开:
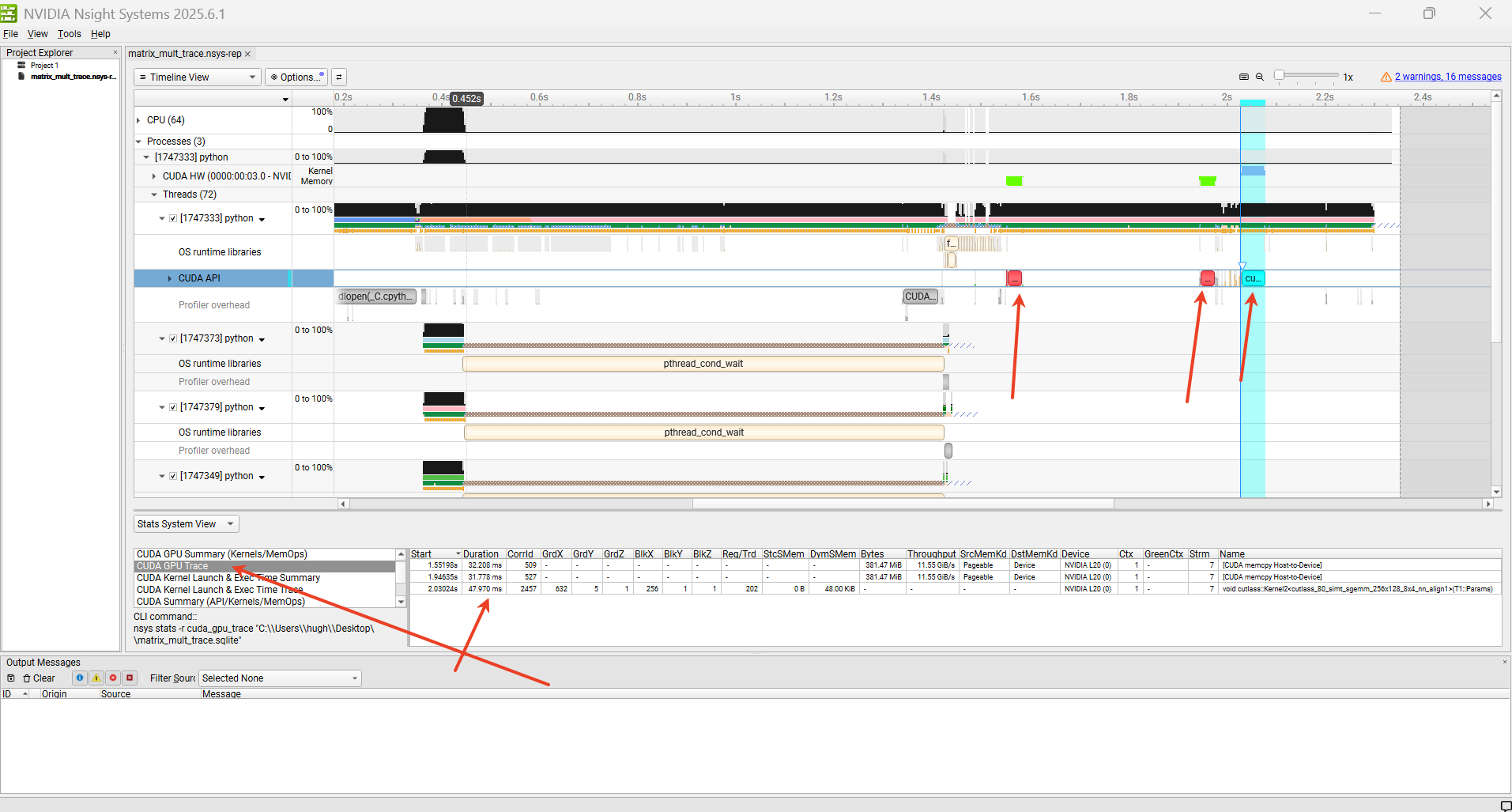
上面的python代码涉及GPU操作的有3部分:
- x复制到GPU,32ms
- y复制到GPU,31ms
- mm操作,47ms

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)