大模型强化学习(RL)算法的演进
0. 演进背景:为什么 SFT 不够,需要 RL?
在进入具体算法之前,我们需要理解演进的起点。
-
SFT (监督微调):像是老师“填鸭式”教学。模型学会了格式和套路,但容易过拟合(Overfitting),导致只会模仿解题步骤而没有真正理解逻辑。
-
RL (强化学习):像是“题海战术+错题本”。模型自己做题(采样),通过反馈(Reward)调整策略。它能让模型在“做题-反馈-调整”的循环中,把知识内化为真正的能力,特别是对于数学和代码等逻辑任务。
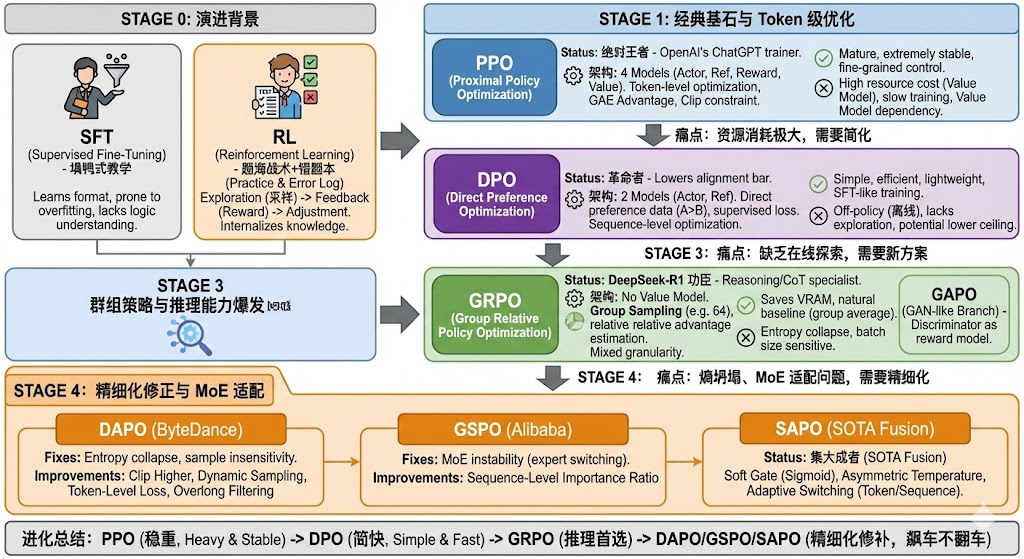
第一阶段:经典基石与 Token 级优化
PPO (Proximal Policy Optimization)
地位:强化学习领域的“绝对王者”,OpenAI 也就是靠它训练出了 ChatGPT。
-
核心机制:
-
架构(4个模型):需要
Actor(策略)、Reference(参考)、Reward(奖励)、Critic/Value(价值)四个模型同时运行。 -
优化粒度:Token 级别。每生成一个 token 都要计算优势(Advantage),通过 GAE(广义优势估计)来平衡偏差和方差。
-
约束:使用 Clip(裁剪)机制,强制新旧策略的分布差异不要太大,保证训练平稳。
-
-
优点:
-
理论成熟,极其稳定。
-
对于每一步的生成都有细粒度的控制。
-
-
缺点(痛点):
-
资源消耗极大:需要维护 Value Model,显存占用高。
-
训练慢:涉及复杂的价值估计和反向传播。
-
Value Model 依赖:如果 Critic 模型训练不好,整个训练就会崩塌。
-
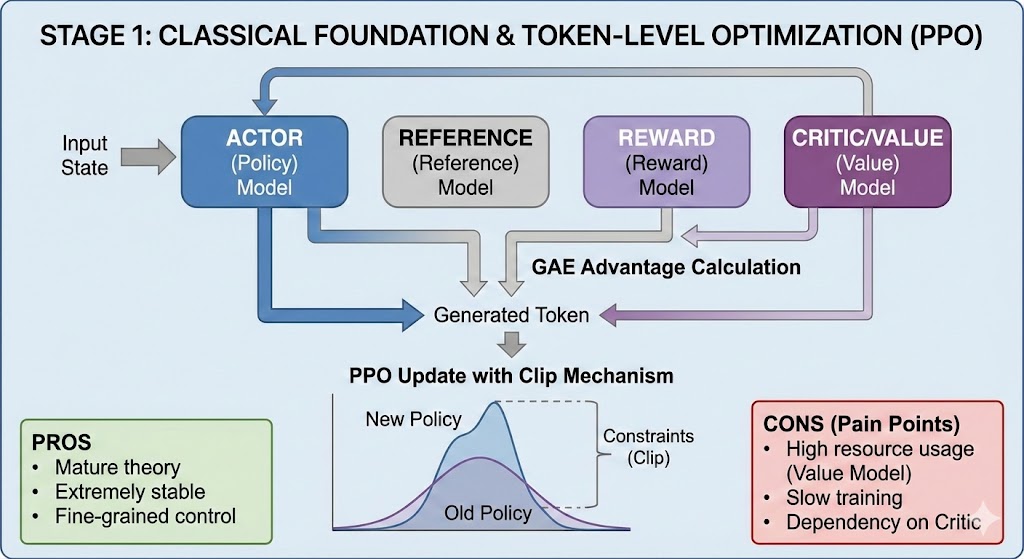
第二阶段:去繁就简与直接偏好优化
DPO (Direct Preference Optimization)
地位:针对 RLHF 复杂流程的“革命者”,大大降低了对齐门槛。
-
核心机制:
-
架构(2个模型):不需要 Reward 和 Value 模型。
-
原理:直接利用人类偏好数据(A 优于 B),通过数学推导将 RL 问题转化为一个监督式的分类损失问题。直接最大化“胜者”相对于“败者”的概率差。
-
优化粒度:Response/Sequence 级别(基于完整回复)。
-
-
优点:
-
极简、高效、轻量。
-
训练过程像 SFT 一样简单,但效果属于 RL。
-
-
缺点:
-
主要是离线(Off-policy)训练,缺乏模型自我探索(Exploration)的过程,上限可能不如在线 RL(On-policy)。
-
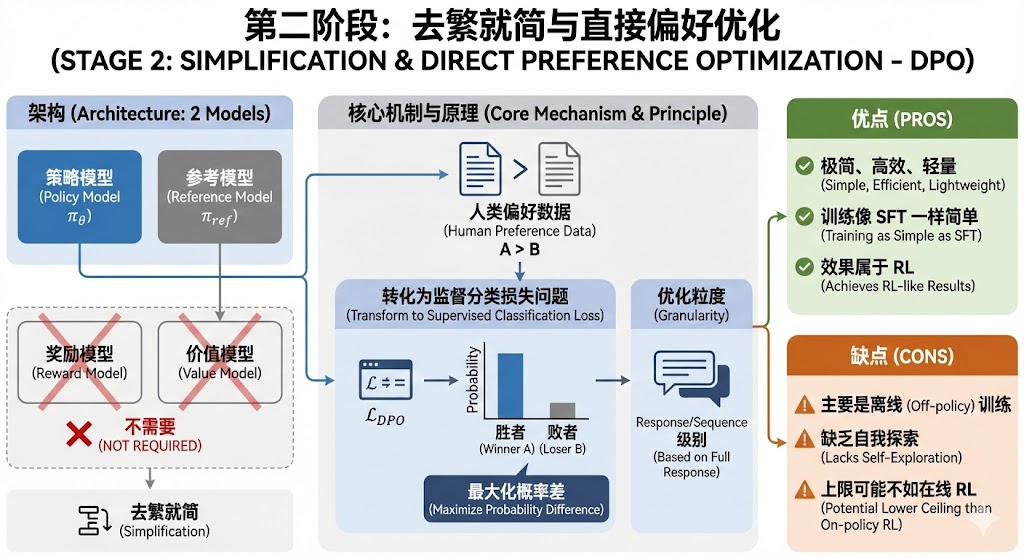
第三阶段:群组策略与推理能力爆发(当前主流)
GRPO (Group Relative Policy Optimization)
地位:DeepSeek-R1 背后的功臣,大模型推理能力提升的关键,专为长思维链(CoT)设计。
-
演进逻辑:为了解决 PPO 的资源消耗问题,但又想保留在线采样的探索能力。
-
核心机制:
-
架构:丢掉 Value Model(省去了巨大的参数量)。
-
群组采样(Group Sampling):对于同一个 Prompt,让模型生成一组(如 64 个)回答。
-
优势估计:不靠 Critic 模型打分,而是计算这一组回答的平均分,用相对分值(当前回答得分 - 组平均分)作为优势(Advantage)。
-
优化粒度:混合了 Sequence 级的奖励和 Token 级的更新。
-
-
优点:
-
省显存:没有 Value Model,训练大参数模型(如 70B+)更轻松。
-
自带基准:组内平均值就是天然的 Baseline,不需要额外的 Reference Model 计算太复杂的 KL 散度。
-
-
缺点(引发了后续的改进):
-
熵坍塌(Entropy Collapse):早期训练时,模型倾向于通过降低随机性来获得“安全”的奖励,导致探索能力丧失。
-
对 Batch Size 敏感:依赖组内统计,如果采样数太少,估计不准。
-
GAPO (Generative Adversarial Preference Optimization)
注:这是另一条技术分支,更偏向生成对抗网络(GAN)的思想。
-
核心机制:引入一个**判别器(Discriminator)**作为动态奖励模型。Actor 试图生成高分回复欺骗判别器,判别器试图区分真实高质数据和模型生成的伪数据。
-
适用场景:需要细粒度可控、特定约束条件下的对齐(如合规性检测)。
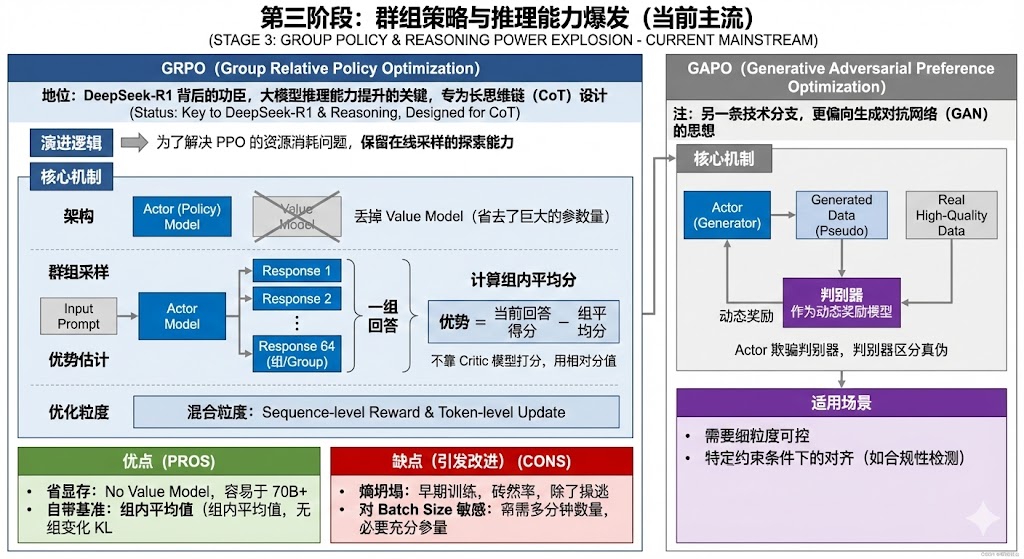
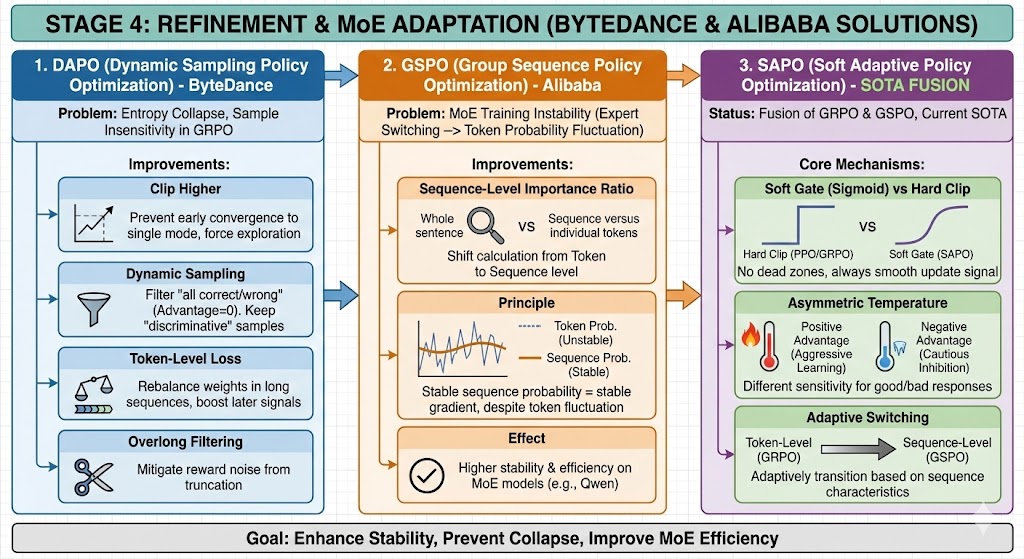
第四阶段:精细化修正与 MoE 适配(字节 & 阿里方案)
为了解决 GRPO 存在的训练不稳定、熵坍塌、以及在 MoE(混合专家模型)上效率低的问题,字节跳动和阿里巴巴分别提出了改进方案。
1. DAPO (Dynamic Sampling Policy Optimization) - 字节跳动
-
针对问题:GRPO 的“熵坍塌”和对样本难易度不敏感。
-
改进点:
-
Clip Higher:放宽裁剪上界,防止模型在早期过快收敛到单一模式,强制保留探索能力。
-
动态采样(Dynamic Sampling):自动过滤掉“全对”或“全错”的简单/困难样本(这些样本 Advantage 为 0,无效),只练那些“有区分度”的样本。
-
Token-Level Loss:重新平衡长序列中每个 Token 的权重,防止长 CoT 链条中后半段的信号太弱。
-
Overlong Filtering:解决长文本截断带来的奖励噪声。
-
2. GSPO (Group Sequence Policy Optimization) - 阿里巴巴
-
针对问题:GRPO 在 MoE 模型上训练不稳定。
-
原因:MoE 模型在训练中会频繁切换“专家”,导致 Token 级别的概率波动极其剧烈。GRPO 的 Token 级约束会导致梯度震荡。
-
-
改进点:
-
Sequence-Level Importance Ratio:将重要性权重的计算从 Token 级提升到 Sequence(整句)级。
-
原理:不管单个 Token 的概率怎么跳(专家的切换),只要整句话的生成概率相对稳定,梯度就是稳定的。
-
-
效果:在 Qwen 等 MoE 模型上,训练效率和稳定性显著高于 GRPO。
3. SAPO (Soft Adaptive Policy Optimization) - 集大成者
-
地位:融合了 GRPO 和 GSPO 的优点,目前的SOTA(State-of-the-Art)改进版。
-
核心机制:
-
Soft Gate(软门控)取代 Hard Clip:PPO 和 GRPO 用硬性的裁剪(如 0.8~1.2)来限制更新。SAPO 使用一个平滑的 Sigmoid 函数作为“软门控”。
-
好处:梯度永远不会像 PPO 那样突然变成 0(死区),始终保持平滑的更新信号。
-
-
非对称温度(Asymmetric Temperature):对于“正优势”(好回答)和“负优势”(坏回答)采用不同的敏感度。
-
目的:更激进地学习好回答,更谨慎地抑制坏回答(防止误伤无关的 Token)。
-
-
自适应切换:它能根据序列的特性,在 Token 级(GRPO 风格)和 Sequence 级(GSPO 风格)之间自适应过渡。
-
总结与横向对比表
| 特性维度 | PPO | DPO | GRPO | DAPO | GSPO | SAPO |
| 核心定义 | 经典的 Actor-Critic 策略优化 | 直接偏好优化(无 RL 模型) | 组内相对优势优化(去 Value 模型) | 动态采样与高裁剪优化 | 序列级重要性采样优化 | 软门控自适应优化 |
| 模型依赖 | Actor, Ref, Reward, Value | Actor, Ref | Actor, Ref, Reward (无 Value) | Actor, Ref, Reward | Actor, Ref, Reward | Actor, Ref, Reward |
| 优势计算 | 依赖 Value 模型 + GAE | 无(基于 Log-prob 差) | 组内平均值作为基线 | 组内平均 + 动态过滤 | 组内平均 | 组内平均 |
| 优化粒度 | Token 级 | Response (Sequence) 级 | 混合 (Token 级 Loss) | Token 级 (加权) | Sequence 级 (Ratio) | 自适应 (Soft Gate) |
| 资源消耗 | 极高 (4模型) | 低 (2模型) | 中 (需多路采样) | 中 | 中 | 中 |
| 主要痛点 | 显存大、调参难 | 缺乏探索、离线 | 熵坍塌、MoE 不稳 | 实现较复杂 | 过于关注整体忽略局部 | 数学形式较复杂 |
| 最佳场景 | 传统通用 RL 任务 | 快速对齐、资源受限 | 推理模型 (CoT)、数学代码 | 长文本推理、解决坍塌 | MoE 模型后训练 | 追求极致稳定与效率 |
进化总结:一句话概括
-
PPO 是开山鼻祖,稳但重;
-
DPO 剑走偏锋,去掉了裁判(Reward Model),快但上限受限;
-
GRPO 回归正统 RL 但扔掉了沉重的包袱(Value Model),利用“群体智慧”(Group Sampling)成为推理模型首选;
-
DAPO/GSPO/SAPO 则是为了修补 GRPO 在长文本和 MoE 模型上的 Bug,通过软化约束和调整粒度,让大模型能在更复杂的路况下“飙车”而不翻车。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)