从 SD1.5 到 SDXL:Stable Diffusion 参数调优全解析
本文系统讲解了 Stable Diffusion 图像生成中的关键细节,涵盖模型版本(SD1.5、SD2.x、SDXL)及其兼容性、采样器与调度器的选择、步数设置对生成质量的影响,以及 CFG Scale 与图像尺寸对构图和细节呈现的重要作用。同时强调了随机性在生成过程中的影响,并提供实用策略以提高生成图像的质量。本文适合希望深入理解 Stable Diffusion 参数调优与高质量图像生成方法
【精选优质专栏推荐】
- 《AI 技术前沿》 —— 紧跟 AI 最新趋势与应用
- 《网络安全新手快速入门(附漏洞挖掘案例)》 —— 零基础安全入门必看
- 《BurpSuite 入门教程(附实战图文)》 —— 渗透测试必备工具详解
- 《网安渗透工具使用教程(全)》 —— 一站式工具手册
- 《CTF 新手入门实战教程》 —— 从题目讲解到实战技巧
- 《前后端项目开发(新手必知必会)》 —— 实战驱动快速上手
每个专栏均配有案例与图文讲解,循序渐进,适合新手与进阶学习者,欢迎订阅。
文章目录

前言
从提示词到生成图像,Stable Diffusion 是一个由众多组件与参数组成的复杂处理管线。这些组件相互协作,才能生成最终结果。若其中任一部分表现异常,输出图像都会发生变化。因此,一个不当的设置就可能轻易毁掉作品。
本文将介绍 Stable Diffusion 各组件如何影响生成效果,以及如何找到最佳配置以生成高质量图像。
模型的重要性
在整个管线中,影响最大的组件无疑是模型。在 Web UI 中,它被称为 “checkpoint(检查点)”,这个名称源自深度学习模型训练过程中保存模型状态的方式。
目前 Web UI 支持多种 Stable Diffusion 模型架构。最常见的是 1.5 版本(SD 1.5)。所有 1.x 系列模型架构相似(约 8.6 亿参数),但在训练与微调策略上各有不同。
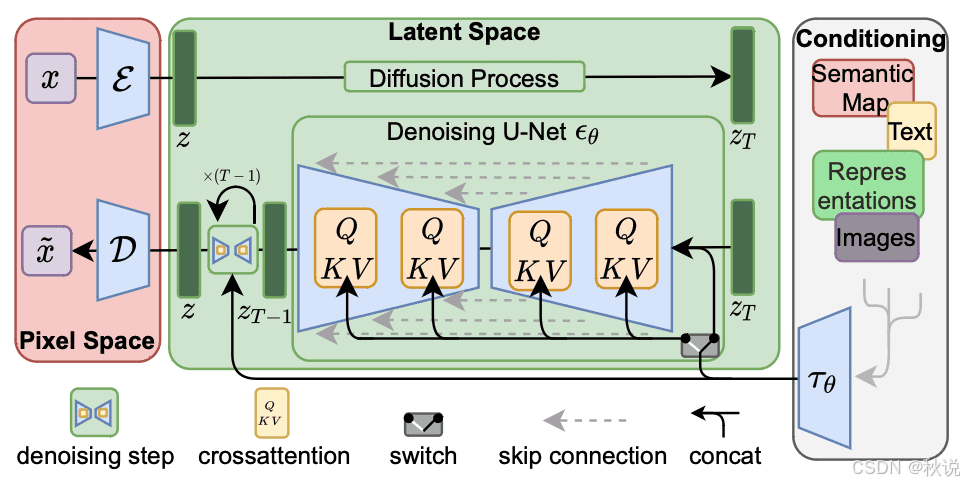
Stable Diffusion 还包括 2.0(SD 2.0) 及其更新版本 2.1。它并非 1.5 的“升级版”,而是从零开始重新训练的模型。该版本使用了不同的文本编码器——OpenCLIP(取代原先的 CLIP),因此对提示词的理解方式不同。一个显著区别是,OpenCLIP 能识别的名人和艺术家名称更少,所以 1.5 版本的提示词在 2.1 中可能不再适用。
由于编码器差异,尽管 SD 1.x 与 SD 2.x 架构相似,但二者互不兼容。
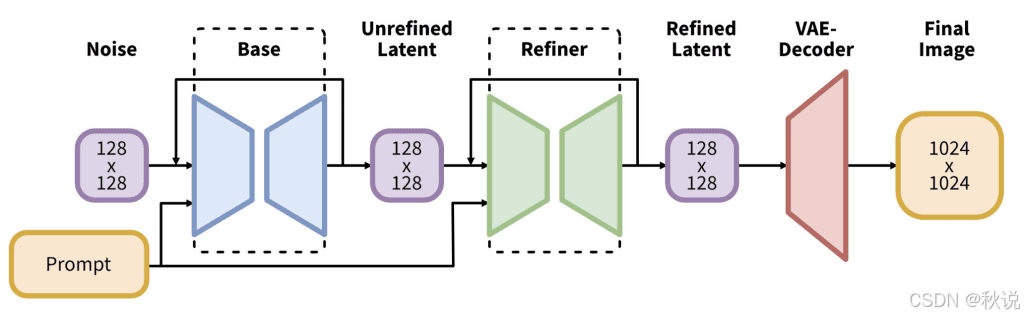
接着是 Stable Diffusion XL(SDXL)。1.5 版本的原生分辨率为 512×512,2.0 提升至 768×768,而 SDXL 则达到 1024×1024。不建议使用与原生分辨率差距过大的尺寸。
SDXL 采用全新架构,参数量高达 66 亿,是一个更庞大的生成管线。其最大特征是模型分为两部分:Base 模型与 Refiner 模型。两者通常配套使用,但也可单独替换,或在需要时省略 Refiner。
SDXL 的文本编码器融合了 CLIP 与 OpenCLIP,能比旧版模型更准确地理解提示词。虽然运行速度更慢、显存占用更高,但输出质量通常更佳。
对用户而言,模型大体可分为三大互不兼容系列:SD 1.5、SD 2.x、SDXL。它们在解析提示词时的行为差异明显。
其中,SD 1.5 与 SD 2.x 通常需要添加负面提示词(Negative Prompt)以提升图像质量,而在 SDXL 中这一点的重要性显著降低。
此外,使用 SD 2.x 时,你会注意到 Web UI 中提供了选择 Refiner 模型 的选项。
以下为使用不同版本 Stable Diffusion,根据相同提示词 “沙漠中一家名为 Sandy Burger 的快餐店” 生成的结果对比。
使用 SD 1.5 和不同的随机种子,根据提示“沙漠中一家名为‘Sandy Burger’的快餐店”生成的图像:

使用 SD 2.0 和不同的随机种子,根据“沙漠中一家名为‘Sandy Burger’的快餐店”这一提示生成的图像:

使用 SDXL 和不同的随机种子,根据“沙漠中一家名为‘Sandy Burger’的快餐店”这一提示生成的图像:

Stable Diffusion 的一个重要特征是:原始模型虽然能力有限,但具有极强的可塑性。因此,社区中出现了大量第三方微调模型,尤其是针对特定风格的版本,如:日系动漫风、西方卡通风、皮克斯式 2.5D 图像、写实风格。
这些模型可在 Civitai.com 或 Hugging Face Hub 上获取。搜索关键词如 “photorealistic” 或 “2D”,并按评分排序,通常能找到质量较高的模型。
采样器与调度器的选择
图像扩散的基本原理是:从随机噪声开始,逐步用像素替换噪声,直至生成最终图像。研究表明,这一过程可用随机微分方程(SDE)建模。不同的数值求解算法对应不同精度与生成效果。
常用采样器包括:
-
Euler:传统但稳定;
-
DPM 系列采样器:精度更高;
-
UniPC、LCM:较新的高效算法。
每种采样器运行多个步骤(steps),每一步的参数由调度器(Scheduler)控制,如 Karras 或 Exponential。
部分采样器支持“祖先模式(Ancestral Mode)”,在每步中引入随机性,使输出更具创意。这类采样器名称通常带有 “a” 后缀,如 Euler a。
-
非祖先采样器 会在一定步数后收敛,输出趋于稳定;
-
祖先采样器 输出结果会随步数变化,步数越多,差异越明显。
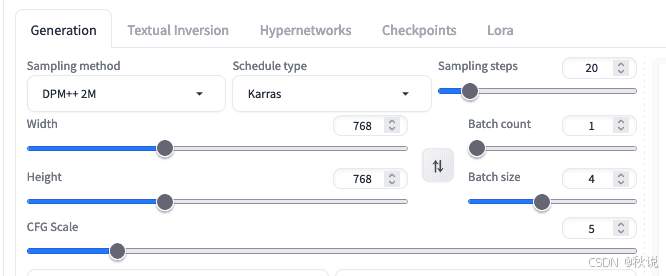
一般可默认使用 Karras 调度器。
推荐采样器为 Euler 或 DPM++ 2M,二者在生成质量与速度间平衡最佳。
可从 20–30 步 开始尝试,步数越多,细节与准确性越高,但生成时间也更长。
图像尺寸与 CFG Scale
扩散过程从噪声开始,再根据提示词生成图像。提示词对生成的影响强度由 CFG Scale(无分类器引导系数) 控制。
不同模型的最优 CFG Scale 各不相同:
-
某些模型在 1–2 时效果最佳;
-
另一些在 7–9 时表现更好。
Web UI 默认值为 7.5。总体来说,CFG Scale 越高,图像越贴合提示词内容。
若 CFG Scale 过低,输出可能偏离预期。但结果不符也可能由图像尺寸造成。
例如,提示词为“站立的男子”时,如果画布接近方形,模型可能只生成半身像。若要生成全身图,应让图像高度明显大于宽度。
这是因为扩散过程会在早期步骤确定画面构图,高画布更容易生成完整站姿。
如果提供方形画布,则生成半身镜头:
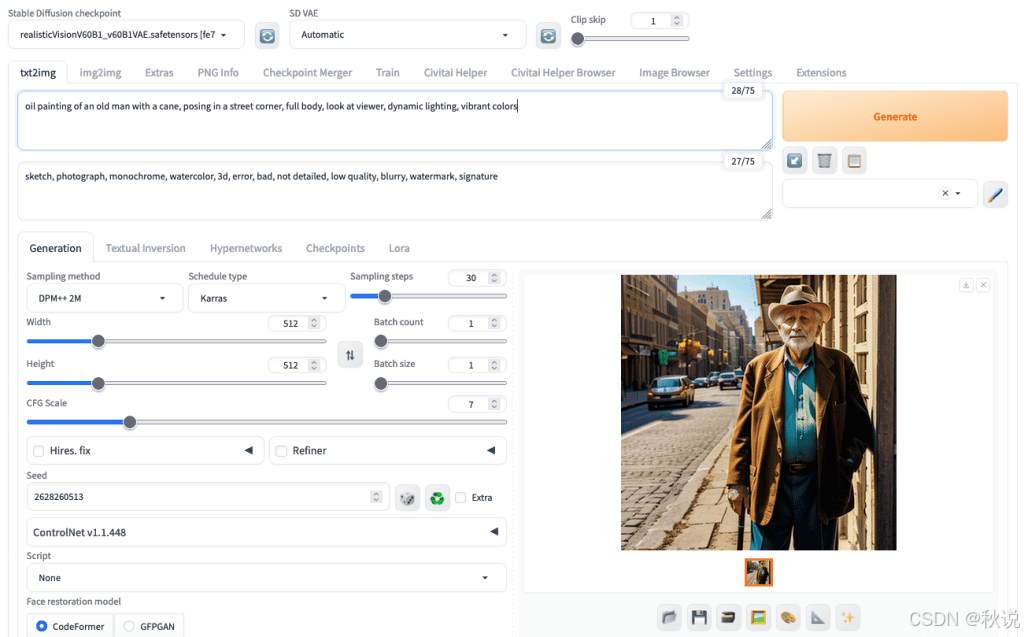
使用相同的提示、相同的种子生成全身镜头,并且仅改变画布大小:
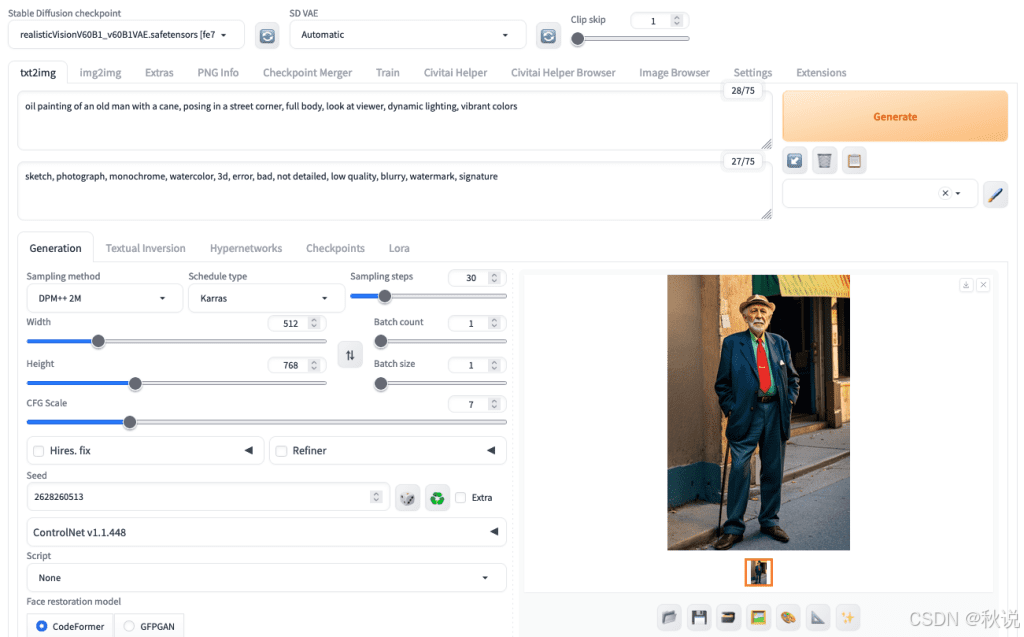
同样地,如果提示词中为图像中占比很小的部分提供了过多细节,这些细节往往会被忽略——因为像素不足以表达它们。
这也是 SDXL 通常优于 SD 1.5 的原因之一:更高的分辨率意味着更多像素可用以呈现细节。
建议:图像扩散模型的生成过程具有随机性。因此,建议每次生成时批量生成多张图像,以避免结果偏差仅因随机种子造成。
总结
本文介绍了 Stable Diffusion 图像生成中的关键要点,包括:
-
不同版本模型(SD1.5、SD2.x、SDXL)的区别与兼容性;
-
模型、采样器、调度器与步数对生成质量的影响;
-
CFG Scale 与图像尺寸在构图与细节生成中的作用;
-
随机性在图像生成中的影响及其应对策略。
理解并合理调整这些参数,是生成高质量图像的关键。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)