【论文解读】OTC-PO:少行动,多思考,让模型学会高效决策
这篇论文抓住了当前 LLM Agent 发展中的一个痛点:**如何在追求强大能力的同时,保证其行动的经济性和高效性**。通过提出 OTC-PO 框架和“工具生产力”这一新颖的评价指标,它为训练更“精打细算”的 LLM Agent 提供了一条清晰且有效的路径。其贡献不仅仅是技术层面的算法改进,更在于**理念上的转变**:从单纯追求“能做”,到追求“做得既好又巧”。研究结果表明,减少对外部工具的盲目依
1st author: Hongru (Merlin) Wang
paper
code: 暂未公布
5. 总结 (结果先行)
这篇论文抓住了当前 LLM Agent 发展中的一个痛点:如何在追求强大能力的同时,保证其行动的经济性和高效性。通过提出 OTC-PO 框架和“工具生产力”这一新颖的评价指标,它为训练更“精打细算”的 LLM Agent 提供了一条清晰且有效的路径。
其贡献不仅仅是技术层面的算法改进,更在于理念上的转变:从单纯追求“能做”,到追求“做得既好又巧”。研究结果表明,减少对外部工具的盲目依赖,反而能够“逼迫”模型去发展和利用其自身的内部推理潜力,最终实现“少行动,多思考”的智能行为模式。
1. 思想
- 大问题:
- 当前的工具增强型LLMs(Tool-integrated LLMs)在通过强化学习(RL)进行训练时,通常只优化最终答案的正确性,而忽略了工具使用的效率和必要性。
- 这导致了所谓的“认知负荷”(cognitive offloading)现象:模型过度依赖外部工具,即使它自身有能力解决问题,也倾向于调用工具。这不仅增加了计算成本,还可能阻碍模型内部推理能力的发展。
- 小问题:
- 如何量化和优化工具使用的效率?
- 如何设计一个奖励机制,使其能够同时鼓励模型答对问题并减少不必要的工具调用?
- 如何让模型学会根据不同问题和自身能力,动态决定最优的工具调用次数?
- 核心思想:
- 目标重塑: 追求在确保答案正确的前提下,最小化外部工具的调用次数。这与Yann LeCun对自主机器智能的愿景——“最小化系统学习任务所需的现实世界行动数量”——不谋而合。
- 引入“工具生产力”: 提出一个新的评价指标——工具生产力(Tool Productivity, TP),定义为正确答案数量与总工具调用次数的比率。TP越高,表明模型利用工具的效率越高。
- 最优工具调用假设: 对于每个问题和每个模型,都存在一个“最优”的(即最少的)工具调用次数,足以让模型得到正确答案。这个次数因问题难度和模型能力而异。
- 工具整合奖励: 设计一种新的奖励函数,将传统的基于正确性的奖励与一个反映工具调用效率的因子相乘。这样,只有在答案正确时,更少的工具调用才会获得更高的奖励。
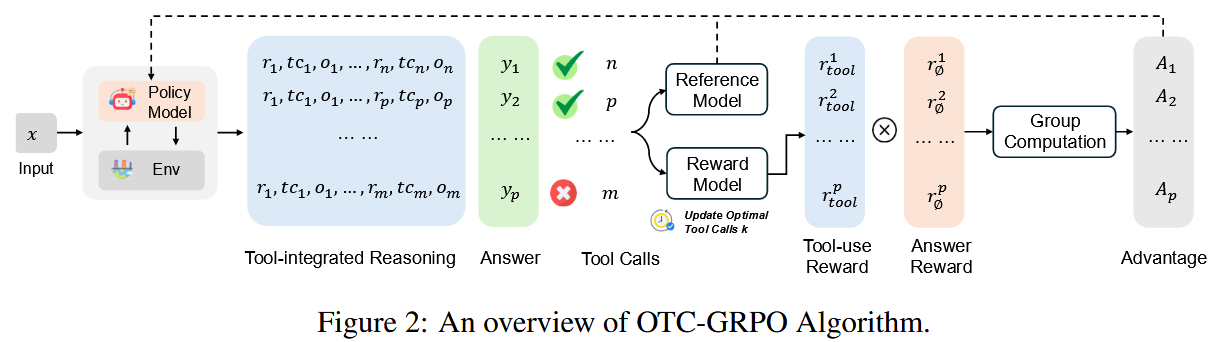
2. 方法
论文提出了最优工具调用控制策略优化 (Optimal Tool Call-controlled Policy Optimization, OTC-PO) 框架。
2.1 任务定义
给定一个问题 q q q 和一个可供模型 M M M 使用的工具集 T = { t 0 , t 1 , … , t n } T = \{t_0, t_1, \dots, t_n\} T={t0,t1,…,tn}。模型的目标是生成一个工具交互轨迹 τ \tau τ,并最终得到正确答案 a ^ \hat{a} a^,同时最小化轨迹 τ \tau τ 中的工具调用次数 C o s t ( τ ) Cost(\tau) Cost(τ)。
数学表示为:
arg min τ C o s t ( τ ) subject to M ( q , τ ) = a ^ \arg \min_{\tau} Cost(\tau) \quad \text{subject to} \quad M(q, \tau) = \hat{a} argτminCost(τ)subject toM(q,τ)=a^
其中,轨迹 τ = ( r 1 , t c 1 , o 1 ) , ( r 2 , t c 2 , o 2 ) , … , ( r k , t c k , o k ) \tau = (r_1, tc_1, o_1), (r_2, tc_2, o_2), \dots, (r_k, tc_k, o_k) τ=(r1,tc1,o1),(r2,tc2,o2),…,(rk,tck,ok)。
- r i r_i ri: 第 i i i 步的内部思考(reasoning)。
- t c i tc_i tci: 第 i i i 步的工具调用(tool call),如果该步不调用工具,则为空。
- o i o_i oi: 第 i i i 步从工具返回的观察结果(observation),如果该步不调用工具,则为空。
C o s t ( τ ) Cost(\tau) Cost(τ) 就是轨迹 τ \tau τ 中非空 t c i tc_i tci 的数量。
2.2 OTC-PO 的奖励函数
OTC-PO 的奖励函数的被设计为:将传统的、关注任务结果(如答案正确性)的奖励 r ϕ ( q , y ) r_\phi(q,y) rϕ(q,y) 与关注工具使用效率的奖励 r t o o l r_{tool} rtool 结合起来。
最终的工具整合奖励函数(Tool-integrated Reward)定义为:
r ϕ t o o l ( q , y ) = α ⋅ r t o o l ⋅ r ϕ ( q , y ) r_\phi^{tool}(q, y) = \alpha \cdot r_{tool} \cdot r_\phi(q, y) rϕtool(q,y)=α⋅rtool⋅rϕ(q,y)
- y y y: 模型生成的完整响应,包括思考过程和最终答案。
- r ϕ ( q , y ) r_\phi(q, y) rϕ(q,y): 基础奖励函数。例如,如果从 y y y 中提取的答案 a a a 与标准答案 a ^ \hat{a} a^ 一致,则 r ϕ ( q , y ) = 1 r_\phi(q, y) = 1 rϕ(q,y)=1,否则为 0 0 0。论文中也提及可能包含格式奖励 r f o r m a t r_{format} rformat。
- r t o o l r_{tool} rtool: 工具使用奖励。其设计旨在奖励那些接近“最优工具调用次数” n n n 的行为。
- α \alpha α: 一个超参数,用于调节 r t o o l r_{tool} rtool 的影响强度。
乘法结构的含义:只有当基础任务成功时(例如, r ϕ ( q , y ) > 0 r_\phi(q,y) > 0 rϕ(q,y)>0),工具使用的效率才会被考虑进奖励中。这防止了模型仅仅为了减少工具调用而牺牲任务的最终表现。
2.3 r t o o l r_{tool} rtool 的设计
由于真实的最优工具调用次数 n n n 通常是未知的,OTC-PO 通过在训练过程中追踪观察到的、能够达成正确答案的最小工具调用次数来近似 n n n。OTC-PO 针对两种主流的 RL 算法 PPO 和 GRPO 提出了 r t o o l r_{tool} rtool 的不同实例化:
-
OTC-PPO (针对 Proximal Policy Optimization):
PPO 通常在每个优化步骤中处理单个轨迹。
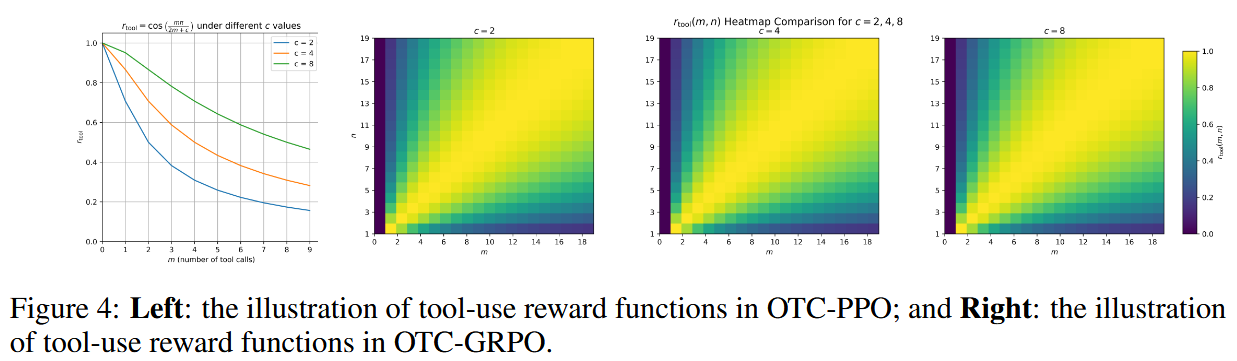
r t o o l = cos ( m ⋅ π 2 m + c ) r_{tool} = \cos\left(\frac{m \cdot \pi}{2m + c}\right) rtool=cos(2m+cm⋅π)- m m m: 当前轨迹中的工具调用次数。
- c c c: 一个平滑常数,控制奖励衰减的速率。 m m m 越大, r t o o l r_{tool} rtool 越接近 cos ( π / 2 ) = 0 \cos(\pi/2) = 0 cos(π/2)=0;当 m = 0 m=0 m=0 时, r t o o l = cos ( 0 ) = 1 r_{tool} = \cos(0) = 1 rtool=cos(0)=1。
思想是:工具调用次数 m m m 越少,奖励越高。
-
OTC-GRPO (针对 Group Relative Preference Optimization) :
GRPO 在每个优化步骤中会为同一个问题采样一组( G G G 个)轨迹。这使得可以直接在当前批次中估计一个局部的最优工具调用次数。
令 k k k 为当前批次中所有回答正确的轨迹里,工具调用次数的最小值。这个 k k k 作为对 n n n 的一个(局部)近似,并且 n n n 可以在训练的多个周期中被全局更新。
r t o o l = { 1 if f ( m , n ) = n = 0 cos ( m ∗ π 2 m + c ) if n = 0 sin ( f ( m , n ) ∗ π 2 n ) otherwise f ( m , n ) = { 0 , if m = 0 and n = 0 m , if n = 0 2 n m m + n , otherwise r_{tool}=\begin{cases}1&\text{if }f(m,n)=n=0\\\cos(\frac{m*\pi}{2m+c})&\text{if }n=0\\\sin(\frac{f(m,n)*\pi}{2n})&\text{otherwise}&\end{cases}f(m,n)=\begin{cases}0,&\text{if }m=0\text{ and }n=0\\m,&\text{if }n=0\\\frac{2nm}{m+n},&\text{otherwise}&\end{cases} rtool=⎩ ⎨ ⎧1cos(2m+cm∗π)sin(2nf(m,n)∗π)if f(m,n)=n=0if n=0otherwisef(m,n)=⎩ ⎨ ⎧0,m,m+n2nm,if m=0 and n=0if n=0otherwise
f ( m , n ) f(m,n) f(m,n) 目的是将当前的工具调用次数 m m m 与近似的最优次数 n n n 进行比较。- 当 m = n m=n m=n (理想情况), f ( m , n ) f(m,n) f(m,n) 应该使得 sin ( ⋅ ) \sin(\cdot) sin(⋅) 项达到最大值1 (即 sin ( π / 2 ) \sin(\pi/2) sin(π/2))。
- 当 m m m 偏离 n n n (过多或过少), sin ( ⋅ ) \sin(\cdot) sin(⋅) 项的值会减小,从而给予较低奖励。
论文中 f ( m , n ) f(m,n) f(m,n) 的具体形式定义在 Equation 6 的右侧表格中,旨在将 m m m 映射到 [ 0 , 2 n ] [0, 2n] [0,2n] 的范围内,以适应 sin \sin sin 函数的周期特性。
思想是:当 m = n m=n m=n 时奖励最高;当 m m m 偏离 n n n 时(无论更多还是更少),奖励都会降低。
3. 优势
与仅优化最终正确性的传统 RL 方法相比,OTC-PO 的优势在于:
- 显式优化效率: 直接将工具使用成本纳入优化目标,而不仅仅是间接期望模型学会高效。
- 缓解认知负荷: 通过奖励机制鼓励模型更多依赖内部推理,减少对外部工具的不必要依赖。
- 降低成本: 减少工具调用直接转化为训练和推理阶段更低的计算资源消耗和时间延迟。
- 通用性和适应性:
- 可与多种 RL 算法(如 PPO, GRPO)结合。
- “最优工具调用次数”是动态学习和适应的,而非固定的硬编码规则,更能适应不同问题和模型能力。
- 提升模型鲁棒性: 迫使模型在没有外部工具或者工具使用受限的情况下,依然能够尝试解决问题,可能增强其在信息不完整或不确定环境下的表现。
4. 实验
-
实验设置:
- 工具类型: 搜索(Search)、代码解释器(Code Interpreter)。
- 基础模型: Qwen-2.5 (3B, 7B-Base) 和 Qwen2.5-Math (1.5B, 7B-Base)。
- 训练数据: 搜索任务使用 NQ 和 HotpotQA;代码任务使用 ToRL 论文提供的数据集。
- 评估数据:
- 域内 (In-domain): NQ, HotpotQA (搜索); AIME24, AIME25 (代码)。
- 域外 (Out-of-domain): TriviaQA, PopQA, 2WikiMQA, Musique, Bamboogle (搜索); MATH (代码)。
- 对比基线: 主要包括 SFT (Supervised Fine-Tuning), Base-RL (仅优化正确性的 RL), RAG, IRCoT, 以及领域内的 SOTA 方法如 Search-R1 和 ToRL。
-
评价指标:
- EM (Exact Match): 最终答案的准确率。
- TC (Tool Calls): 平均每个问题的工具调用次数。
- TP (Tool Productivity): (正确答案总数) / (总工具调用次数)。这是本文提出的关键新指标,衡量工具使用的整体效率。
T P = ∑ i = 1 N I ( a ^ i = a i ) ∑ i = 1 N t c i TP = \frac{\sum_{i=1}^{N} I(\hat{a}_i = a_i)}{\sum_{i=1}^{N} tc_i} TP=∑i=1Ntci∑i=1NI(a^i=ai)
其中 I ( ⋅ ) I(\cdot) I(⋅) 是指示函数, a ^ i \hat{a}_i a^i 是模型对第 i i i 个问题的预测答案, a i a_i ai 是真实答案, t c i tc_i tci 是第 i i i 个问题的工具调用次数。
-
实验结论:
- 显著降低工具调用 (TC) 和提升工具生产力 (TP): OTC-PO 方法在所有测试的模型和数据集上,均大幅减少了平均工具调用次数(例如,Qwen2.5-7B 在 NQ 上 TC 减少 68.3%),同时显著提升了工具生产力(NQ 上 TP 提升 215.4%)。
- 准确率 (EM) 保持稳定: 尽管工具使用大幅减少,但最终答案的准确率与基线方法(如 Search-R1, ToRL)相比基本持平,尤其是在较大的模型上。这表明模型学会了更“聪明”地使用工具,而非牺牲准确性。
- “认知负荷”现象被证实和缓解: 实验显示,在没有显式效率优化的基线方法中,模型规模越大,越倾向于过度使用工具(例如,Search-R1 在 NQ 上,7B 模型的 TC 高于 3B 模型)。OTC-PO 能够有效缓解这一现象。
- 良好的泛化能力: 在 OOD 数据集上,OTC-PO 依然表现出降低 TC 和提升 TP 的优势,同时 EM 下降幅度可控,有时甚至优于专门优化正确性的基线。
- 案例分析: Figure 1的案例直观展示了 Search-R1 等方法可能会进行多次冗余或无效的工具调用,而 OTC-PPO/GRPO 则能通过更精确的单次调用或完全依赖内部推理来解决问题。


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)