如何在本地部署大语言模型(Windows,Mac,Linux)三系统教程
通过在本地部署大语言模型,可以使得我们直接在本地调用大语言模型去别的程序里做“大脑”,这篇blog关于怎么在三个系统中部署本地大语言模型分别有教程,简单方便
前言
因为很多的大语言模型的API比较贵,所以呢在本地部署大语言模型做一些实验就是好的选择,尤其在实验室或者公共资源,算力比较好的情况下。这里给出一个三系统(Windows,Mac,Linux)分别如何自己部署一个本地大语言模型。这里的模型选用llama3.2:3b。只用跟着做,你就可以部署自己的本地大语言模型啦。
Windows
我这里使用Windows 部署并使用 Ollama + llama3.2:3b
搜索PowerShell并且以管理员身份进入,要以右击管理员身份
进入以后呢就直接安装winget install Ollama.Ollama
但是如果报错找不到winget可以手动下载安装
- 前往官网:https://ollama.com/download
- 下载 Windows 版本安装包 (.exe)
- 双击安装,安装完成后会自动启动 Ollama 服务。
安装完以后可以在PowerShell启动服务
ollama serve
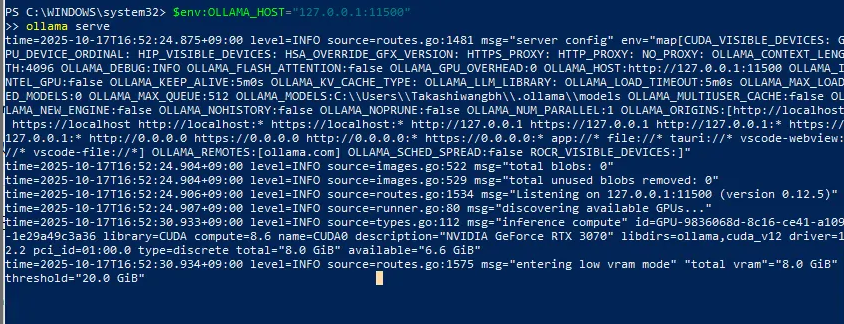
这样就是在运行了,这个页面不关,重新开一个页面拉取本地大语言模型
ollama pull llama3.2:3b
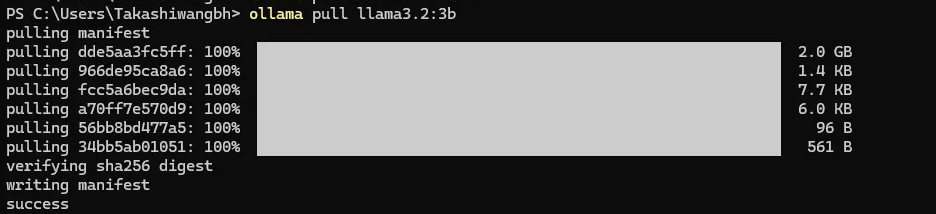
成功pull了以后就运行试一下ollama run llama3.2:3b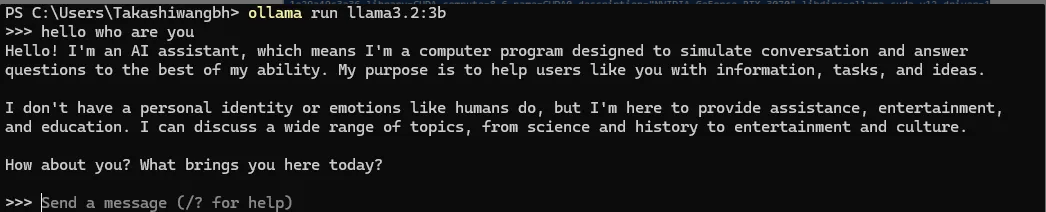
可以看到就可以在终端使用大语言模型了,刚才没关的那个管理员身份Powershell可以看到后台的进展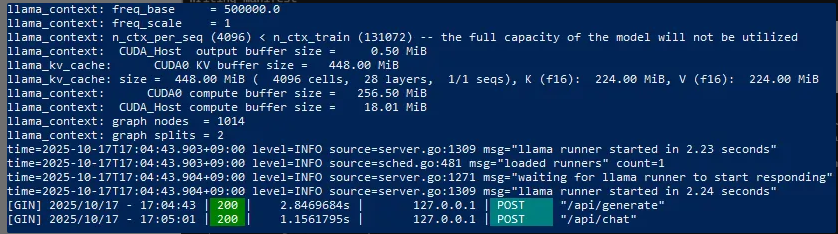
下次再用的时候只用在终端
ollama serve
然后开一个新终端
ollama run llama3.2:3b
就可以运行了
mac
我这里使用macOS 部署并使用 Ollama + llama3.2:3b
一般来说,使用Homebrew来下载安装,默认情况Mac是没有的,先安装Homebrew。
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh
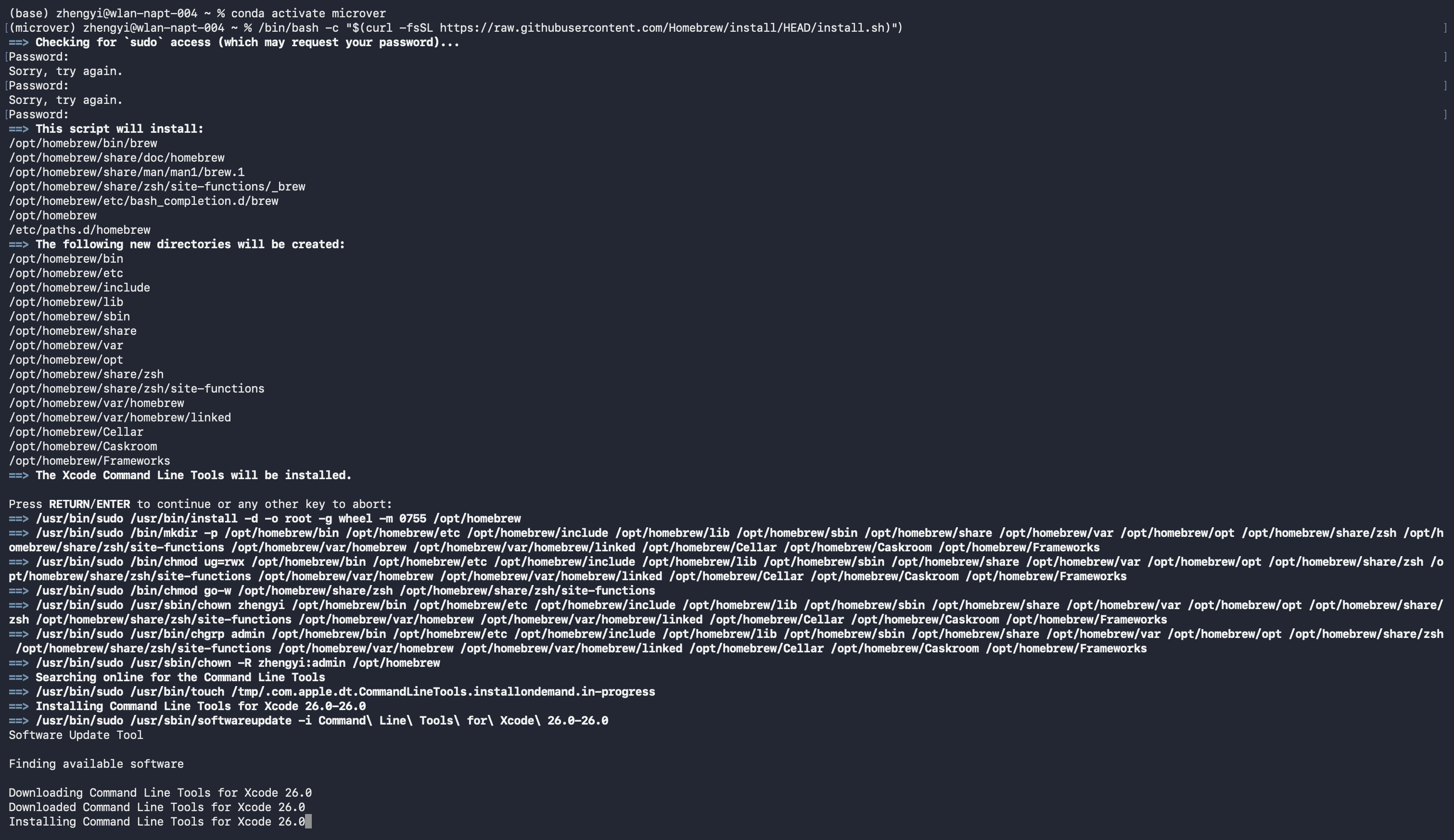
安装完以后需要配置一下homebrew,显示版本了就表示安装成功
echo 'eval "$(/opt/homebrew/bin/brew shellenv)"' >> ~/.zprofile
eval "$(/opt/homebrew/bin/brew shellenv)”
brew --version

然后就可以安装Ollama了
brew install ollama

等待安装完成就可以启动服务器了
ollama serve

通过这个日志就可以看到Ollama 服务已经正常运行,日志里有这几条关键信息:
Listening on 127.0.0.1:11434→ 本地 API 就绪inference compute ... Apple M4 Pro→ 已识别到M4 GPUentering low vram mode→ 因为可用显存≈17.8 GiB(阈值20 GiB),属正常提示,不影响使用
现在我们就要开始下载模型了,这个模型每个人根据自己的电脑配置和需求下,方法一样,只是改名字
这个终端不要关,因为启动了Ollama服务器,打开一个新的终端
ollama pull llama3.2:3b
llama3.2:3b可以换成你想要的llama模型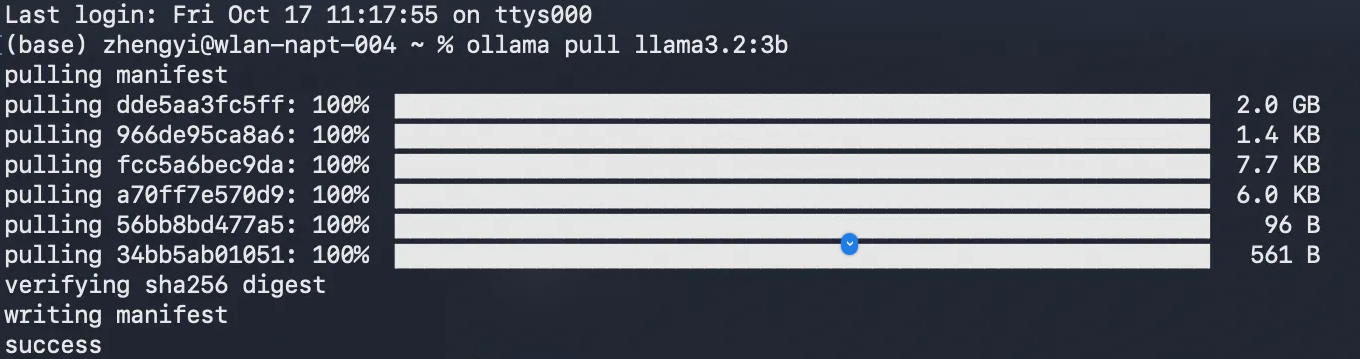
这样就是显示成功了,本地大语言模型就部署成功了
让我们试一下,可以在终端与它对话
ollama run llama3.2:3b

当想要测试现在这个模型的API是否正常可以使用
curl http://127.0.0.1:11434/api/tags

返回{“models”:[{“name”:“llama3.2:3b”, … “parameter_size”:“3.2B”,“quantization_level”:“Q4_K_M”}]},就是可以正常使用
如果退出了,下次想要使用ollama时,可以打开终端
# brew services stop ollama 这个是杀死之前的进程
ollama serve
就能正常运行了
Linux
我这里使用Linux(ubantu) 部署并使用 Ollama + llama3.2:3b
直接在终端下载Ollama
curl -fsSL https://ollama.com/install.sh | sh
curl不够新就会报错,更新一下就行
这样就是安装成功了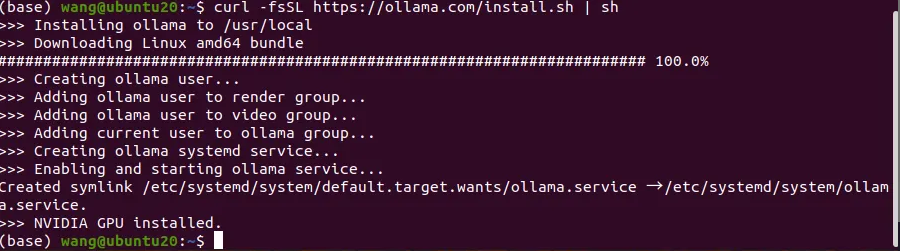
安装完再执行
ollama --version
能看到安装的版本
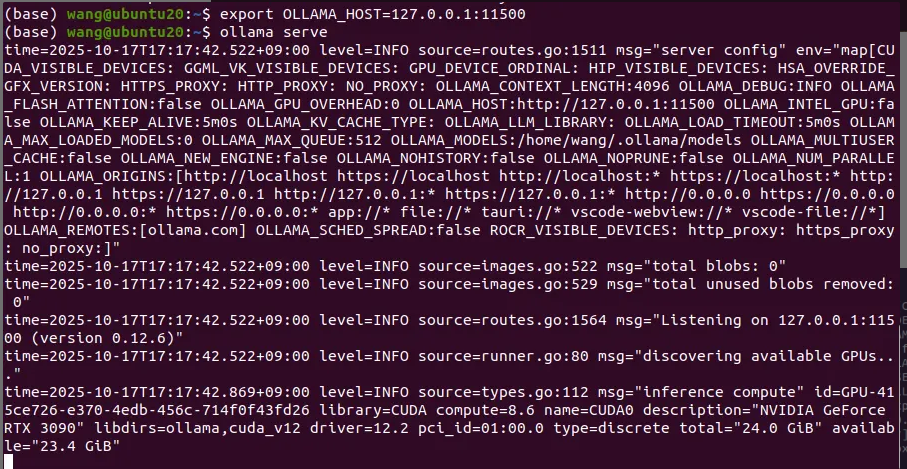
然后启动服务,我这里端口被别的程序占用了,所以修改了一个端口,其他的也是这样,如果显示端口被占用,就用这个命令改一下Ollama的端口
export OLLAMA_HOST=127.0.0.1:11500
启动服务
ollama serve
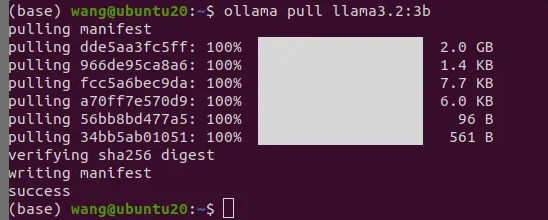
打开一个新终端,拉取大语言模型
ollama pull llama3.2:3b
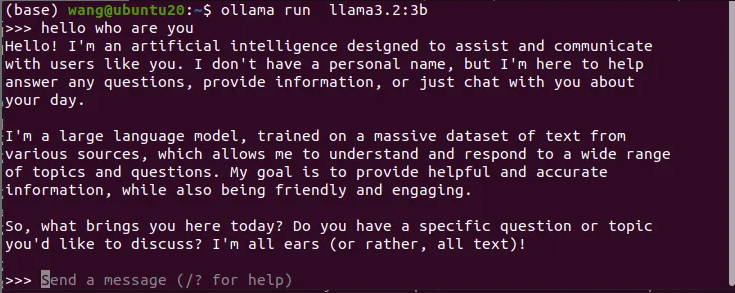
成功以后再运行一下试一试
ollama run llama3.2:3b
关于API调用
部署完以后呢,下次再启动ollama serve以后
可以本地终端对话,也就是在新终端中ollama run llama3.2:3b就可以了
但是其实更多的用处还是调本地大语言模型的API去别的程序做一些有趣的事
127.0.0.1:11434 或 127.0.0.1:11500 这样的地址,
就是 Ollama 提供的本地 REST API 接口。
这些程序通过访问http://api地址就能够连接到本地大语言模型了
于是任何程序(Python、Unity、Godot、Web 应用等)都能访问本地模型了

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)