《自然语言处理》课程设计--电影知识图谱问答系统
本文介绍了一个基于NLP技术的电影信息问答系统,该系统集成了8个功能模块和12项NLP技术。系统采用三层架构设计,支持文本和语音输入,能够识别用户意图、提取关键信息并进行纠错。核心功能包括:输入文本处理(意图识别、人名/电影名提取、拼写纠错)、语音识别、多轮对话管理、情感分析、相似推荐、摘要生成、数据管理和智能问答。系统通过CSV文件存储电影知识图谱数据,并提供用户问答和管理员数据管理双界面。该系
系统概述表
|
功能块个数:8 NLP技术个数:12 |
||
|
功能模块名称 |
模块概述 |
采用NLP相关技术列表 |
|
输入文本处理— 关键内容识别 |
在用户(查询者)输入的语句中识别出其提问的意图(导演、评分、简述等)、人名(导演名、演员名)、电影名。并且自动输入拼写错误纠正,支持模糊匹配和纠错。同时可以检测异常输入,如输入代词无法指代消解、意图模糊会输出相关提示。 |
意图识别:分词、匹配 |
|
人名识别:HanLP.NER(实体识别)、字串匹配 |
||
|
电影名:HanLP.con(句法生成树) |
||
|
纠错:莱文斯坦编辑距离 |
||
|
语音输入 |
向用户提供直接语音录入的接口。 |
Whisper模型(语音识别) |
|
多轮对话管理 |
根据上文信息,破解用户输入的“ta”。 |
指代消解 |
|
情感分析(类) |
分析对电影的评论表现出的情感。 |
LSTM模型 |
|
相似推荐 |
根据电影的内容相似度进行推荐。 |
Jaccard相似度、Node2Vec |
|
摘要生成 |
对电影内容进行简述,输出词云图。 |
SnowNLP(抽取式摘要) |
|
数据管理 |
在用户(管理员)输入的语句中提取出实体关系对,并将其返回csv文件。 |
(按规则)关系抽取 |
|
回答提问 |
根据用户提问精细准确的回答。 |
\ |
1 系统概述
本系统是一个综合性的电影信息管理与智能问答平台,集成了电影数据管理、关系提取、实体识别、自然语言处理、情感分析和智能推荐等功能。系统能够处理结构化与非结构化的电影数据,支持多种用户交互方式,包括文本输入和语音输入,并提供丰富的电影相关信息查询功能。
2 概要设计
2.1 系统架构设计
本系统采用三层架构设计:
- 表现层:基于Flask框架的Web界面,包含用户问答界面(用户入口)和数据管理界面(管理员入口);
- 业务逻辑层:实现核心功能模块(自然语言处理、情感分析、推荐算法等);
- 数据层:CSV文件存储的电影知识图谱数据,通过爬虫模块/管理员手动输入定期更新。
前端采用响应式HTML5设计,使用CSS3实现自适应布局,通过JavaScript实现动态交互。后端使用Python Flask框架构建RESTful API,前后端通过JSON格式进行数据交换。
2.2 数据流程设计
本系统的数据流程如下:
- 数据采集:通过爬虫从豆瓣电影Top250获取原始数据;
- 数据清洗:使用正则表达式进行数据标准化;
- 数据存储:清洗后的数据保存为CSV格式;
- 数据应用:系统运行时加载CSV数据到内存DataFrame。
数据经过清洗后形成结构化知识图谱,支持后续的语义分析和智能问答功能。管理员可通过界面随时补充新的电影数据。
申明:数据获取采用的爬虫为合规操作,且所得数据仅用于此次实验。
2.3 功能模块设计
- 用户问答模块:
- 支持文本/语音两种输入方式;
- 实现多轮对话管理;
- 响应8类电影相关查询。
- 数据管理模块:
- 支持三元组关系的增删改查;
- 提供NLP自动抽取功能;
- 数据持久化存储。
3 详细设计
3.1 输入文本处理模块
输入文本处理模块作为系统的核心前端解析组件,负责对用户输入的查询语句进行多维度分析,,同时结合命名实体识别和成分句法树解析技术提取关键实体信息,包括电影名称以及涉及的人名(导演或演员);针对用户输入可能存在的拼写错误,模块内置基于编辑距离的动态纠错机制,可自动校正模糊匹配的电影名称(如"肖申克的救赎"误输为"肖申克的旧书"时自动修正)。
3.1.1 意图识别
首先,将输入的文本通过HanLP的多任务预训练模型分词后,通过模式匹配识别用户意图(如查询导演、评分或电影类型等)并将识别到的意图储存至列表中,以便后续回答和查询功能可以正确处理多个意图的询问。预置的意图关键词词典采用"意图-关键词"映射结构设计,覆盖了电影信息查询的8类核心意图:评分相关意图对应"评价"、"打分"等关键词;导演查询意图对应"导演"等关键词;演员信息意图对应"主演"、"参演"等关键词;时间维度意图对应"哪年"、"年份"等关键词;类型查询意图对应"喜剧"、"科幻"等13种电影类型关键词;语种意图对应中英德法等6种语言表述;内容查询意图捕捉"简介"、"简述"等摘要关键词;推荐意图则对应"相似"、"推荐"等关键词。系统采用贪婪匹配策略,支持单语句中多意图的并行识别,所有识别结果将结构化存储至意图队列,为后续的定向查询和复合回答提供语义依据。这种分层式意图识别机制既保证了常见查询场景的覆盖度,又通过动态扩展关键词库维持了系统的可进化性。
3.1.2 人名识别
人名识别模块主要负责从用户输入文本中准确提取人物名称实体,为后续的导演查询、演员验证等功能提供关键数据支持。若返回的人名列表不为空,则后续系统的回应为“所查询的p是(不是)f的导演(演员)”;否则系统会直接输出相应影片所有的导演(演员)名。
利用HanLP序列标注技术识别其中所有标记为"PERSON"类别的实体。这种基于预训练模型的识别方式能够有效处理中文人名特有的组合形式(如复姓"欧阳"、带间隔号的外文人名等),同时避免将普通名词误判为人名。
由于我们发现普遍习惯用“约翰”来指代“约翰·威廉姆斯”,因此人名识别采用字串匹配。
3.1.3 电影名识别
电影名识别模块采用基于成分句法分析的层级式识别策略,通过多阶段处理实现对用户输入中电影名称的精准提取。该模块首先利用HanLP生成的成分句法树进行结构分析,通过递归遍历算法从顶层名词短语(NP)中提取候选电影名,对于简单主谓结构如下表中第一棵句法树,模块直接从宾语NP节点提取完整电影名"泰坦尼克号"。针对中文特有的"的"字结构(DNP)和补语结构(CP),模块设计了专门的子树解析函数,能够穿透复杂修饰成分直达核心NP节点,如下表中的第二和第三棵句法树,该模块会穿透各修饰层提取核心NP。
在后期处理阶段,系统通过三重过滤机制确保识别质量:首先排除疑问代词(如"什么"、"哪部")构成的无效NP;其次处理并列结构(含"和"、"与"等连接词),将复合NP拆分为独立电影名;最后通过与数据库标题比对,过滤掉实际为人名的NP(如"哈利波特"既是人名也可能是电影名)。
表1. 句法生成树的四个示例
|
(TOP (IP (_ 简述) (NP (_ 泰坦尼克号)) (_ ?))) |
|
(TOP (IP (VP (_ 推荐) (NP (QP (_ 几) (CLP (_ 部))) (CP (CP (IP (VP (PP (_ 和) (NP (ADJP (_ 疯狂)) (NP (_ 原始人)))) (VP (_ 差不多)))) (_ 的))) (NP (_ 电影)))) (_ ?))) |
|
(TOP (CP (IP (NP (NP (_ 大家)) (DNP (PP (_ 对) (NP (_ 肖申克))) (_ 的)) (NP (_ 救赎))) (VP (NP (_ 打分)) (VP (_ 高)))) (_ 吗) (_ ?))) |
|
(TOP (IP (NP (_ 谁)) (VP (_ 导演) (_ 了) (NP (_ 傲慢) (_ 与) (_ 偏见))) (_ ?))) |
3.1.4 拼写纠错
拼写纠错模块采用基于编辑距离的动态匹配算法,有效解决用户输入中常见的电影名称拼写错误问题,例如当用户输入"阿甘正专"时,模块能准确纠正为"阿甘正传"。该模块首先计算用户输入名称与电影数据库中所有标题的Levenshtein编辑距离,通过设定最大允许距离阈值(名称长度的一半)来筛选候选匹配。在后续处理过程中,人名和电影名的匹配都调用了这一模块。
3.2 语音输入模块
语音输入模块基于Whisper的中文base语音识别模型实现,提供从语音到文本的转换功能。模块首先通过音频采集接口录制用户语音输入,将模拟信号转换为数字音频数据。随后调用预训练的Whisper模型进行语音识别,将音频内容转录为文字。系统自动处理音频格式转换和临时文件存储,支持中文语音的实时转写,为后续的文本处理模块提供输入来源。该模块实现了语音交互的无缝衔接,扩展了系统的输入方式,丰富和便捷了用户的体验。
3.3 多轮对话管理模块
多轮对话管理模块通过上下文记忆和指代消解技术实现连贯的对话交互。该模块采用全局变量维护对话状态,记录最近一次查询的电影名称,当检测到用户使用"它"、"他"、"她"等代词时,自动关联前文提及的电影实体。模块核心包含三个处理层次:首先通过意图分发器将用户查询路由至对应的查询处理函数;其次建立动态上下文窗口,在连续对话中保持实体关联性;最后通过异常检测机制处理无指代对象的情况,主动引导用户澄清需求。系统支持多意图并行处理,单次查询可同时获取电影的评分、导演等多个维度的信息,并通过响应组装引擎生成结构化回复。
3.4 情感分析模块
情感分析模块基于LSTM神经网络构建,专门用于分析电影评论的情感倾向。该模块首先通过jieba分词器对评论文本进行分词处理,构建包含<PAD>和<UNK>标记的词表,采用20个token的固定长度输入。模型架构包含嵌入层(32维)、LSTM层(64维隐藏单元)和全连接分类层,输出三类情感分类结果:差评、一般和强烈好评。在评分查询功能中,该模块会被自动调用分析电影的首条评论情感,作为评分数据的补充信息。例如当用户查询"泰坦尼克号评分"时,系统不仅返回评分值和排名百分比,还会附加"情感倾向为强烈好评"的分析结果。模块支持动态加载预训练模型,若未检测到模型文件会自动启动训练流程,采用交叉熵损失函数和Adam优化器进行10个epoch的训练。
3.5 相似推荐模块
相似推荐模块采用基于图神经网络的内容推荐算法,通过构建电影相似性网络实现精准推荐。该模块首先基于电影的多维特征(类型、语言、国家、评分、剧情简介等)构建内容相似图,其中节点表示电影,边权重通过改进的Jaccard相似度算法计算(对数值特征(评分、时长)设置动态阈值(评分差≤0.5,时长差≤20分钟);对分类特征(类型、语言)进行精确匹配加权;对文本特征(简介、评论)采用分词后的Jaccard计算:J(A,B) = |A∩B| / |A∪B|)。
系统采用Node2Vec图嵌入技术将电影映射到64维向量空间,通过设置游走长度10、游走次数100的参数配置捕获网络的局部和全局结构特征。在生成推荐时,模块计算目标电影与库中其他电影的余弦相似度,返回相似度最高的两部电影,并自动分析相似特征维度(如"类型相似"、"评分接近"等)作为推荐理由。
3.6 摘要生成模块
摘要生成模块基于SnowNLP框架实现电影内容摘要的自动化生成。使用jieba分词器对原始影评文本进行分词处理;随后过滤停用词和单字词,保留具有实际语义的词汇单元;并构建词频统计矩阵,识别关键主题词。
同时自动生成词云图,突出显示电影原始简介中的核心词汇,让用户对内容有总体直观的认识。
3.7 数据管理模块
数据管理模块采用基于正则表达式的结构化信息提取技术,实现电影知识图谱的自动化构建与维护。该模块通过预定义的8类关系模式(导演、评分、年份、类型、语种、剧情、评论、演员)对输入文本进行关系抽取。
该模块使用动态数据更新机制:采用增量更新策略,当检测到现有电影标题时执行字段更新;对新发现电影自动创建数据记录;实时持久化到CSV文件,确保数据一致性。同时内置异常处理机制,自动处理字段冲突和空值情况,保障数据完整性。
3.8 回答提问模块
回答提问模块作为系统的核心功能集成器,通过智能路由机制将用户查询精准分发至对应的专业处理单元,并融合多维度信息生成结构化响应,最终形成兼具准确性和可读性的多维度问答结果。
4 系统界面
在问答系统入口Web界面可以选择用户入口和管理员入口,用户入口进入用户问答界面,管理员入口进入数据管理界面。
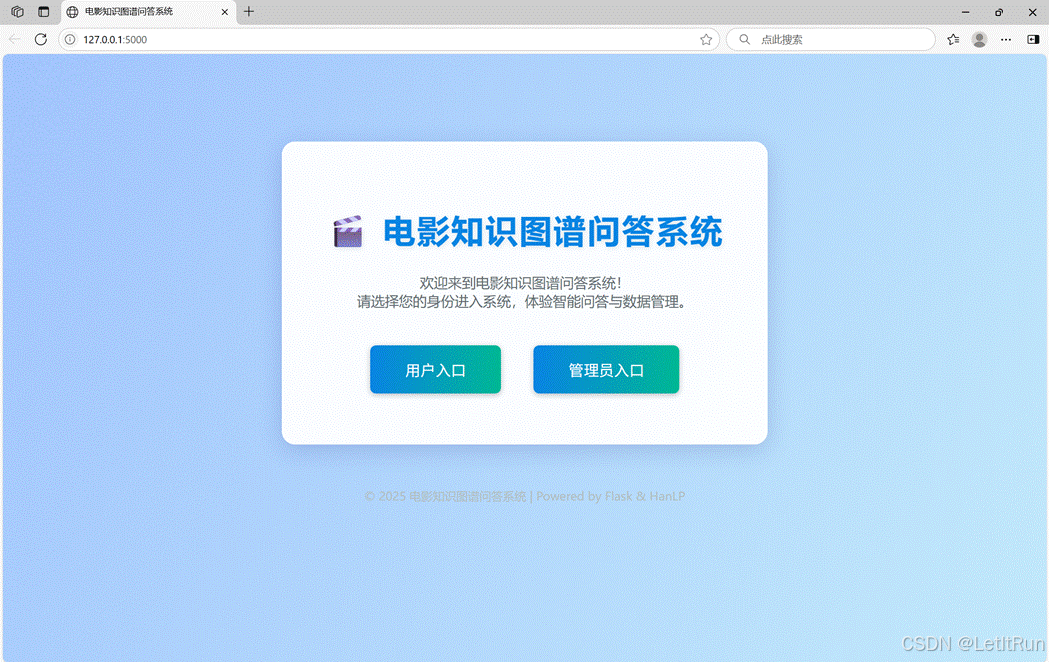
图1. 问答系统入口Web界面
4.1 用户问答界面
进入用户问答界面后,用户可以进行与电影相关的询问,如询问电影导演、电影评价、概要等,系统会根据爬取的数据进行处理后给出回答。图2展示了一部分系统的一部分功能:信息询问、人名纠错、多轮对话管理。
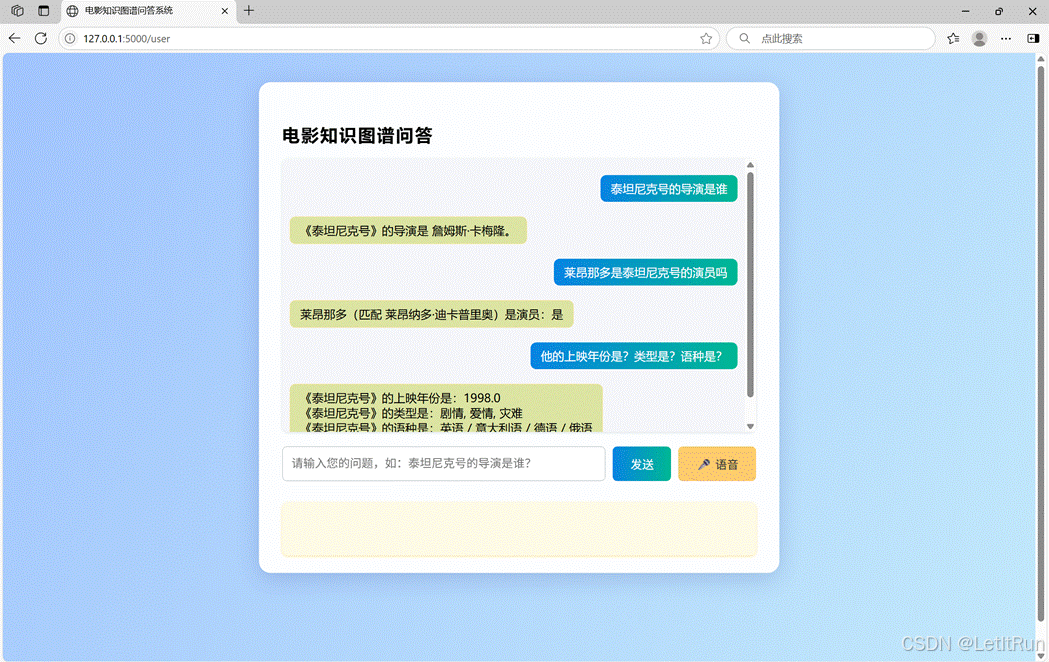
图2. 用户问答系统问答示例
系统的一个特殊功能为在询问电影概要时,系统会先根据爬取的概要数据生成词云图,随后在对话框输出精简版的概要。图3展示了这一过程。
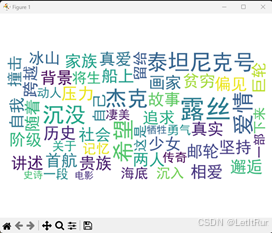
(a)词云图
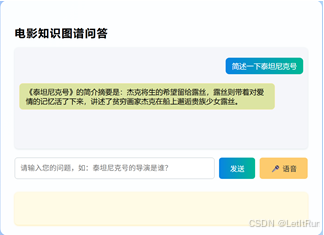
(b)输出精简概要
图3. 询问电影简介回答示例
语音输入功能通过问答框的语音按键启动,该功能依赖现代浏览器的语音识别API,目前支持Chrome和Edge等基于Chromium内核的浏览器,默认使用中文进行语音识别。语音识别采用但此时别模式,每次触发仅识别一段连续语音,结束后自动停止,语音限制为8秒内。
4.2 管理员界面
管理员界面用于在前端进行数据管理,通过管理员界面可以对三元组数据进行删除、增加等操作。初始时管理员界面是没有三元组信息的,初始数据都存储在CSV文件中。
增加操作支持手动增加三元组和NLP自动抽取三元组,手动增加三元组需要管理员定义实体1、实体2以及实体之间的关系,NLP自动抽取则系统会从句子中自动抽取实体关系对,新增的三元组会保存在新建的CSV文件中。图4示例为自动抽取三元组弹窗。
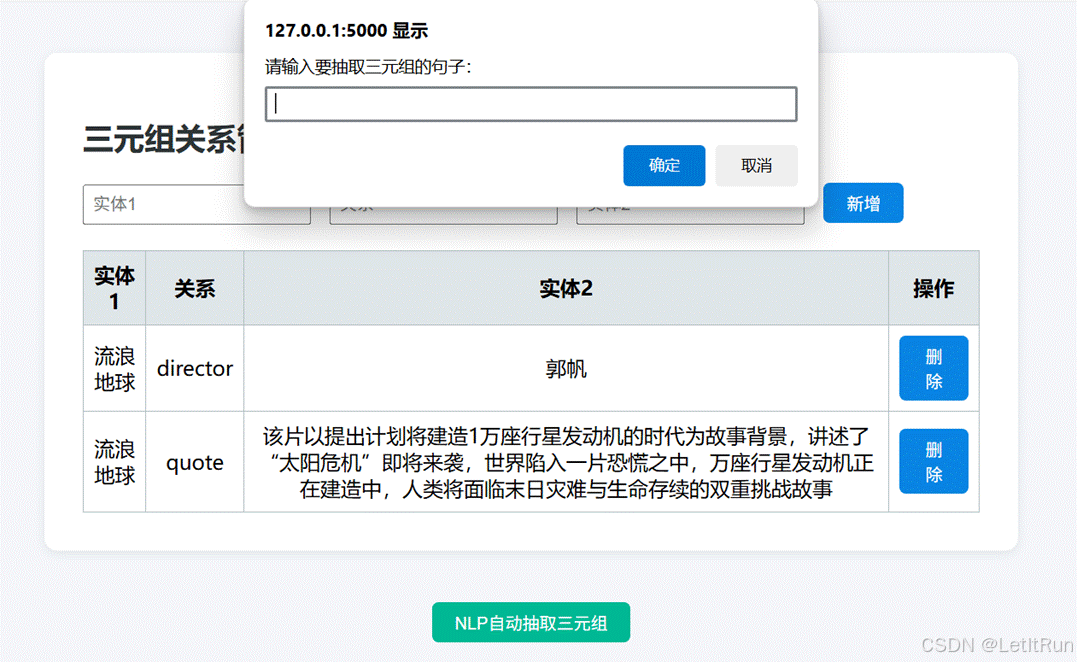
图4. NLP自动抽取三元组弹窗
删除操作只需点击图4中三元组的删除按键即可完成,删除三元组后此数据将在CSV文件中删除,以实现数据同步。
5 期望改进
当前系统主要依赖预定义的正则表达式规则进行意图识别和关系抽取,这种方法虽然实现简单但在泛化能力上存在明显局限。未来计划采用基于BERT等预训练语言模型的语义匹配方案,通过微调中文BERT模型构建端到端的语义理解系统。具体改进包括:1) 使用自监督学习在电影领域语料上继续预训练,增强领域适应性;2) 设计多任务学习框架,同时处理意图分类和实体识别;3) 引入注意力机制动态捕捉查询中的关键语义片段。这种改进将使系统能够理解"这部片子是谁拍的"、"导演是哪位"等多样化的同义表达,显著提升自然语言理解的鲁棒性。
另外,现有模块对HanLP的分词和句法分析结果存在较强依赖,这导致两个主要问题:首先,专有名词可能被错误切分;其次,复杂句式生成的成分句法树存在解析误差。未来拟通过以下方案改进:1) 构建电影领域自定义词典,强化专有名词识别;2) 集成多种分词器的混合投票机制。
6 总结
本电影信息问答系统项目成功构建了一个融合多模态输入与智能分析的电影知识服务平台,实现了从语音/文本输入到结构化信息输出的完整技术链条。系统集成了 8 大核心功能模块与 12 项自然语言处理技术,形成了覆盖数据管理、语义理解、智能交互的综合性解决方案。
在技术实现层面,系统采用三层架构设计:表现层基于 Flask 框架构建响应式 Web 界面,支持用户问答与管理员数据管理双入口;业务逻辑层整合 HanLP、Whisper、LSTM 等技术组件,实现意图识别、指代消解、情感分析等核心功能;数据层通过 CSV 文件存储电影知识图谱,结合爬虫与手动输入实现数据更新。这种分层设计既保证了模块间的低耦合性,又为后续功能扩展奠定了架构基础。
系统在实际应用中展现出良好的实用性与扩展性:用户问答界面支持电影信息查询、多轮对话、语音输入等功能,如查询《泰坦尼克号》时可同时获取导演、评分、类型等多维信息;管理员界面通过 NLP 自动抽取与手动编辑双重方式维护知识图谱,实现三元组关系的动态管理。数据流程从豆瓣 Top250 爬虫采集到 CSV 结构化存储,形成完整的数据闭环。
然而,系统在泛化能力与解析精度上仍有提升空间,未来计划引入 BERT 等预训练模型构建端到端语义理解系统,通过领域语料微调与多任务学习增强自然语言理解能力,同时构建电影领域自定义词典提升专有名词识别精度。
7 附录代码
7.1 管理员输入
import re
import pandas as pd
from typing import List, Tuple
df = pd.read_csv('data/data_upload_cleaned.csv')
def get_relation_patterns() -> List[Tuple[str, str]]:
"""返回预定义的关系提取模式"""
return [
(r'([\u4e00-\u9fa5]+)\s*的导演是\s*([\u4e00-\u9fa50-9·::、,—\-()()]+)', 'director'),
(r'([\u4e00-\u9fa50-9·::、,—\-()()]+)的评分是\s*([\d.]+)', 'rating'),
(r'([\u4e00-\u9fa50-9·::、,—\-()()]+)的年份是\s*(\d{4})', 'release_date'),
(r'([\u4e00-\u9fa50-9·::、,—\-()()]+)的类型是\s*([\u4e00-\u9fa5,、]+)', 'genre'),
(r'([\u4e00-\u9fa50-9·::、,—\-()()]+)的语种是\s*([\u4e00-\u9fa5]+)', 'language'),
(r'([\u4e00-\u9fa50-9·::、,—\-()()]+)的主要内容是\s*(.+?)。', 'quote'),
(r'观众对([\u4e00-\u9fa50-9·::、,—\-()()]+)的评论是\s*(.+?)。', 'first_review'),
(r'([\u4e00-\u9fa5]+)\s*的演员有\s*([\u4e00-\u9fa50-9·::、,—\-()()]+)', 'actors'),
]
def extract_relations(sentence: str) -> List[Tuple[str, str, str]]:
"""
从句子中提取关系三元组并保存到DataFrame中
返回: 列表,每个元素是(实体1, 关系, 实体2)的三元组
"""
patterns = get_relation_patterns()
results = []
for pattern, relation in patterns:
matches = re.finditer(pattern, sentence)
for match in matches:
ent1 = match.group(1)
ent2 = match.group(2)
results.append((ent1, relation, ent2))
# 将结果保存到DataFrame中
# 检查是否已存在该title的记录
if ent1 in df['title'].values:
# 更新现有记录
idx = df[df['title'] == ent1].index[0]
df.at[idx, relation] = ent2
else:
# 创建新记录
new_row = {'title': ent1}
new_row[relation] = ent2
df.loc[len(df)] = new_row
# 每次提取后自动保存到CSV
try:
df.to_csv('data/data_upload_cleaned.csv', index=False, encoding='utf-8')
print("数据已自动保存到CSV文件")
except Exception as e:
print(f"保存CSV文件时出错: {str(e)}")
return results
def format_output(triples: List[Tuple[str, str, str]]) -> str:
"""格式化输出结果"""
if not triples:
return "未识别到有效关系"
output = []
for i, (ent1, rel, ent2) in enumerate(triples, 1):
output.append(f"{i}. 实体: {ent1}, 关系: {rel}, 值: {ent2}")
return "\n".join(output)
def main():
"""主函数"""
print("关系提取系统 - 输入文本识别电影相关信息")
print("支持识别的关系类型: 导演, 参演, 评分, 年份, 类型, 语种, 主要内容, 评论")
print("请输入文本(例如: '(人)导演了(电影)'\n'(人)参演了(电影)'\n'(电影)的评分是(数字)'\n'(电影)的年份是(数字)'\n'(电影)的类型是(类型)'\n'(电影)的语种是(语种)'\n'(电影)的主要内容是(简述)'\n'观众对(电影)的评论是(评论)'):")
while True:
try:
text = input("\n请输入文本(输入q退出): ").strip()
if text.lower() == 'q':
print("系统退出")
break
if not text:
print("输入不能为空,请重新输入")
continue
triples = extract_relations(text)
print("\n识别结果:")
print(format_output(triples))
except KeyboardInterrupt:
print("\n检测到中断,系统退出")
break
except Exception as e:
print(f"处理时发生错误: {e}")
if __name__ == "__main__":
main()7.2 用户文字&语音输入
import hanlp
from nltk import Tree
import pandas as pd
import whisper
import sounddevice as sd
import numpy as np
from scipy.io.wavfile import write
def extract_np_from_dnp_or_cp(node: Tree) -> str:
"""
给定 DNP 或 CP 节点,尝试递归提取其中的 PP/VP/CP → NP
"""
if not isinstance(node, Tree):
return None
# 尝试 DNP 中直接 NP
np_direct = next((c for c in node if isinstance(c, Tree) and c.label() == 'NP'), None)
if np_direct:
return ''.join(np_direct.leaves())
# 尝试 PP → NP
pp = next((c for c in node if isinstance(c, Tree) and c.label() == 'PP'), None)
if pp:
np_in_pp = next((c for c in pp if isinstance(c, Tree) and c.label() == 'NP'), None)
if np_in_pp:
return ''.join(np_in_pp.leaves())
# 尝试 CP → IP → VP → PP → NP 或类似结构
for child in node:
if isinstance(child, Tree) and child.label() in ('CP', 'IP', 'VP', 'PP'):
result = extract_np_from_dnp_or_cp(child)
if result:
return result
return None
def get_top_level_nps(tree: Tree):
results = []
def recurse(node, has_np_ancestor):
if not isinstance(node, Tree):
return
if node.label() == 'NP' and not has_np_ancestor:
# 查找 DNP 或 CP
modifiers = [c for c in node if isinstance(c, Tree) and c.label() in ('DNP', 'CP')]
if modifiers:
extracted = extract_np_from_dnp_or_cp(modifiers[0])
if extracted:
results.append(extracted)
else:
results.append(''.join(node.leaves()))
else:
results.append(''.join(node.leaves()))
has_np_ancestor = True
for child in node:
recurse(child, has_np_ancestor)
recurse(tree, False)
return results
def load_hanlp_model():
"""加载 HanLP 模型"""
return hanlp.load(hanlp.pretrained.mtl.OPEN_TOK_POS_NER_SRL_DEP_SDP_CON_ELECTRA_SMALL_ZH)
def extract_person_entities(ner_results):
"""从 NER 结果中提取 PERSON 实体"""
return [ent[0] for ent in ner_results if ent[1] == 'PERSON']
def parse_constituency_tree(con_tree_obj):
"""解析成分句法树"""
con_str = con_tree_obj if isinstance(con_tree_obj, str) else str(con_tree_obj)
return Tree.fromstring(con_str)
QUESTION_WORDS = {'她', '它', '他', '谁', '什么', '哪部', '哪一年', '哪年', '哪种', '哪位', '哪些'}
def is_question_np(np_str):
"""判断该NP是否是疑问代词组成"""
return np_str.strip() in QUESTION_WORDS
def filter_top_nps(top_nps, person_entities, matched_intents, df):
"""过滤顶层 NP,移除已在 PERSON 实体和意图关键词中的内容,以及疑问代词;修复并列结构"""
result = []
for np in top_nps:
if np in matched_intents or is_question_np(np):
continue
if np in person_entities:
if np in df['title'].values:
result.append(np)
continue
# 若包含连接词
if any(conn in np for conn in ['和', '与', '以及']):
if np in df['title'].values:
result.append(np)
else:
# 拆开并加入
for conn in ['和', '与', '以及']:
if conn in np:
part1, part2 = np.split(conn, 1)
part1, part2 = part1.strip(), part2.strip()
if part1:
result.append(part1)
if part2:
result.append(part2)
break
else:
result.append(np)
return result
def detect_intents(tokens):
"""检测用户意图并返回意图列表和匹配的关键词"""
intent_keywords = {
'评分': ["评价", "打分", "评分", "星级"],
# 回应:def Request_rate(movie_name), 返回rate的数值、(所有电影or同类型电影中的rate排名)、前三名用户评论的情感数值(snownlp or pytorch)
'导演': ["导演"],
# 回应:def Request_dire(movie_name, director_name), 若director_name为空,返回director_name;若非空,返回(是/不是+真的名字)的判断。注:director_name是个列表
'演员': ["主演", "参演", "演员", "演职人员"],
# 回应:def Request_act(movie_name, act_name), 若act_name为空,返回act_name;若非空,返回(是/不是+真的名字)的判断。注:act_name是个列表
'年份': ["哪一年", "哪年", "年份"],
# 回应:def Request_year(movie_name), 返回year的数值
'类型': ["类型", "喜剧", "恐怖片", "恐怖", "科幻片", "科幻", "惊悚", "爱情", "爱情片", "动作片", "悬疑", "悬疑片", "烧脑"],
# 回应:def Request_type(movie_name), 返回type的值
'语种': ["中文", "中文版", "英文", "英文版", "英语版", "语种", "语言", "德语", "法语", "葡萄牙语"],
# 回应:def Request_lang(movie_name), 返回language的值
'简介': ["主要内容", "内容", "简述", "简介"],
# 回应:def Request_cont(movie_name), 返回content的摘要 textrank返回关键词即可
'推荐': ["推荐", "类似", "相似", "差不多"]
# 回应:def Request_sim(movie_name), node2vec推荐前3个相似的,内容相似大于结构相似,返回推荐的电影名、在graph中的距离(相似的数值)、推荐的理由
}
intent_list = []
matched_intents = set()
for intent, keywords in intent_keywords.items():
matched = [tok for tok in tokens if tok in keywords]
if matched:
intent_list.append(intent)
matched_intents.update(matched)
return intent_list, matched_intents
def filter_person_entities(person_entities, final_movies):
"""如果人名实体出现在电影名列表中,则从人名实体中移除"""
# return [person for person in person_entities if person not in final_movies]
filtered_persons = []
for person in person_entities:
# 如果这个人名是某个电影名的子串,则跳过(不加入最终结果)
if any(person in movie for movie in final_movies):
continue
filtered_persons.append(person)
return filtered_persons
def ensure_punctuation(text):
"""确保文本以标点符号结尾,如果没有则添加"""
# 中文和英文的常见结尾标点
punctuations = {'?', '?'}
if not text:
return text
# 检查最后一个字符是否是标点
if text[-1] not in punctuations:
# 根据语言倾向选择句号(中文优先)
if any('\u4e00' <= char <= '\u9fff' for char in text): # 检测中文字符
text += '?'
else:
text += '?'
return text
def process_text(text, hanlp_model):
"""处理输入的文本并返回结果"""
text = ensure_punctuation(text)
# 执行分词 & NER & 成分句法
res = hanlp_model(text, tasks=['tok', 'ner', 'con'])
print(res['con'])
# 1. 提取 PERSON 实体
person_entities = extract_person_entities(res['ner'])
# 2. 提取最高层 NP
nltk_tree = parse_constituency_tree(res['con'])
top_nps = get_top_level_nps(nltk_tree)
# 3. 检测用户意图
tokens = res['tok']
intent_list, matched_intents = detect_intents(tokens)
# 4. 过滤 NP
df = pd.read_csv('data/data_upload_cleaned.csv')
final_movies = filter_top_nps(top_nps, person_entities, matched_intents, df)
# 5. 过滤人名实体
person_entities = filter_person_entities(person_entities, final_movies)
return {
"人名": person_entities if person_entities else [],
"电影名": final_movies if final_movies else [],
"用户意图": intent_list if intent_list else []
}
def record_audio(duration=8, sample_rate=44100):
"""录制音频"""
print(f"开始录制 {duration} 秒音频...")
recording = sd.rec(int(duration * sample_rate), samplerate=sample_rate, channels=1, dtype='float32')
sd.wait() # 等待录制完成
print("录制完成")
return recording, sample_rate
def transcribe_audio(model, audio, sr):
"""将音频转录为文本"""
# 保存临时音频文件
temp_file = "ui/static/user_in_aud/temp_audio.wav"
write(temp_file, sr, audio)
# 转录
result = model.transcribe(temp_file, language="zh")
return result["text"]
def main():
"""主函数"""
# 加载模型
hanlp_model = load_hanlp_model()
# 获取用户输入方式
input_method = input("请选择输入方式(1-语音输入,其他-文本输入):").strip()
if input_method == "1":
# 语音输入模式
whisper_model = whisper.load_model("base")
audio, sr = record_audio()
audio = (audio * 32767).astype(np.int16) # 转换为int16格式
text = transcribe_audio(whisper_model, audio, sr)
print(f"识别结果:{text}")
else:
# 文本输入模式
text = input("请输入文本:").strip()
# 处理文本并获取结果
results = process_text(text, hanlp_model)
# 输出结果
print("人名:", results["人名"])
print("电影名:", results["电影名"])
print("用户意图:", results["用户意图"])
if __name__ == "__main__":
main()7.3 情感模型
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import jieba
from collections import Counter
import os
train_data = [
# 强烈好评(2)
("这部电影简直完美,剧情紧凑,情感真挚,演技在线,必须满分推荐!", 2),
("视效炸裂,故事动人,是近年来少有的诚意之作。", 2),
("不管是配乐、摄影还是节奏控制都堪称一流,值得二刷三刷。", 2),
("剧情流畅,情节张力十足,演员表现令人惊艳。", 2),
("一部很有深度的影片,值得静下心来欣赏,回味无穷。", 2),
("感情戏份处理得非常细腻,情绪代入感极强。", 2),
("导演功底扎实,整体完成度极高,令人佩服。", 2),
("观影体验极佳,节奏掌控到位,令人沉浸其中。", 2),
("演员演技精湛,每一个情绪变化都很到位。", 2),
("结尾的反转太惊喜了,编剧真是个天才!", 2),
("从视觉到听觉都是一种享受,电影美学体现得淋漓尽致。", 2),
("角色塑造丰满,每一个人都有血有肉。", 2),
("台词自然流畅,人物对话很真实,有生活感。", 2),
("整部影片让人笑中带泪,是一场心灵的洗礼。", 2),
("这部片子情感细腻,节奏紧凑,非常感人。", 2),
("打斗设计精彩纷呈,动作场面流畅干净。", 2),
("电影节奏掌控得非常好,没有任何拖沓。", 2),
("影片传达的主题深刻,引发了我对人生的思考。", 2),
("配乐非常契合剧情,烘托气氛一级棒。", 2),
("情节设定精彩绝伦,完全沉浸其中无法自拔。", 2),
("一部充满艺术气息的作品,非常有价值。", 2),
("感情细节描绘入微,看得我热泪盈眶。", 2),
("无论是主角还是配角,都演得特别到位。", 2),
("整体节奏紧凑,一气呵成,毫无尿点。", 2),
("剧本扎实,结构合理,逻辑严谨。", 2),
("很多镜头拍得很有美感,审美体验很棒。", 2),
("小成本却拍出了大片的质感,太惊喜了!", 2),
("惊悚与情感交织得恰到好处,非常震撼。", 2),
("演技炸裂,剧情反转精彩,必须推荐!", 2),
("一部让我久久不能平静的好电影,值得收藏。", 2),
("在有限的时间里表达了深刻的主题,佩服。", 2),
("电影非常有力量,情节触动人心。", 2),
("故事设定新颖,完全颠覆了我的预期。", 2),
("完全被剧情吸引,紧张又感人。", 2),
("所有元素都很协调,是部成熟作品。", 2),
("笑点和泪点都处理得恰到好处,非常精彩。", 2),
("这是一部可以引起广泛共鸣的电影。", 2),
("故事真实动人,细节打磨得很好。", 2),
("角色成长线清晰有力,令人动容。", 2),
("整部片流畅自然,没有冗余。", 2),
("这才是真正的好电影,有内容有情感。", 2),
("一部值得全家人一起看的作品。", 2),
("导演讲故事的能力非常出众。", 2),
("全程无尿点,节奏感强。", 2),
("从头爽到尾,燃点十足。", 2),
("很久没有一部电影能让我这么投入了。", 2),
("主角魅力十足,演得特别好。", 2),
("电影节奏快、台词有趣,是完美的商业片。", 2),
("艺术性与娱乐性兼具,佩服创作者。", 2),
("拍得真的好,适合推荐给朋友一起看。", 2),
# 一般评价(1)
("电影一般般,没有太大亮点,也不至于差。", 1),
("节奏有点慢,但也不算难看。", 1),
("故事老套,不过演员演得还行。", 1),
("就是普通水平,适合无聊时看看。", 1),
("整部电影不功不过,没什么记忆点。", 1),
("观影体验中规中矩,没有太多槽点。", 1),
("剧本比较简单,看完也不会太难受。", 1),
("不是很出色但也不难看。", 1),
("台词有些做作,但还能接受。", 1),
("细节不错但剧情缺乏张力。", 1),
("部分演员演技尚可,整体发挥稳定。", 1),
("制作还行,节奏略拖沓。", 1),
("配乐不错,可惜剧情平淡。", 1),
("特效中规中矩,没有惊艳但不差。", 1),
("笑点偶有,整体比较平稳。", 1),
("结局有些仓促,但前半部分还可以。", 1),
("如果没事做可以看看,不看也不会遗憾。", 1),
("不是很推荐,但也没有踩雷。", 1),
("虽然不喜欢,但也能理解别人的喜好。", 1),
("影院体验一般,没什么特别的印象。", 1),
("情节安排合理但缺乏情感爆发。", 1),
("前半段不错,后半段有点拉垮。", 1),
("剪辑节奏尚可,但故事没新意。", 1),
("演员有的出彩,有的拖后腿。", 1),
("没特别不满,也谈不上满意。", 1),
("主题明确但手法平淡。", 1),
("有些地方还蛮有趣的,就是不够打动人。", 1),
("设定比较普通,没有突破。", 1),
("摄影不错,叙事一般。", 1),
("有些桥段还是挺抓人的。", 1),
("适合打发时间但不值得深思。", 1),
("导演还是有点能力的,只是剧本不够好。", 1),
("演技在线但故事太老。", 1),
("整体偏平,没有亮点也没大问题。", 1),
("感觉挺普通的电影,没啥记忆点。", 1),
("片长合适,不累,但也没激情。", 1),
("有想法但表达得不够到位。", 1),
("有些情节挺真实的,有共鸣。", 1),
("角色发展合理但缺乏惊喜。", 1),
("故事结构清晰但太稳妥。", 1),
("整体质量尚可,但缺少灵魂。", 1),
("就那样吧,看了就忘。", 1),
("评分略高于实际感受。", 1),
("最后五分钟有点意思,前面不行。", 1),
("如果免费能看看,花钱不值。", 1),
("部分台词写得还不错。", 1),
("整体气氛比较松散。", 1),
("主角人设略显平庸。", 1),
("拍得不差,但也不特别好。", 1),
# 差评(0)
("剧情无聊,几乎没有任何看点。", 0),
("演技差到令人尴尬,全程出戏。", 0),
("特效简陋,像十年前的电视剧。", 0),
("完全没逻辑,瞎编乱造的故事。", 0),
("浪费我时间,看到一半就想关掉。", 0),
("这部电影真的太糟糕了,毫无亮点。", 0),
("背景音乐吵闹刺耳,非常影响观感。", 0),
("台词生硬,像在背书。", 0),
("完全没有代入感,人物刻板单调。", 0),
("简直是一场灾难,没有任何艺术价值。", 0),
("剧本写得很差,连基本逻辑都没有。", 0),
("剪辑混乱,时间线莫名其妙。", 0),
("演员表现浮夸,令人作呕。", 0),
("这是我今年看过最差的一部电影。", 0),
("本来是冲着导演去的,结果失望透顶。", 0),
("毫无节奏感,看到最后只剩困意。", 0),
("摄影镜头抖得让人头晕。", 0),
("完全感受不到情感投入,全程冷漠。", 0),
("剧情不知所云,胡编乱造。", 0),
("导演一点想法都没有,全靠堆画面。", 0),
("演员演得像机器人,毫无情绪变化。", 0),
("配角比主角还要出戏。", 0),
("台词尴尬,几度让我起鸡皮疙瘩。", 0),
("题材本身不错,可惜被拍烂了。", 0),
("情节推进拖泥带水,一点也不爽快。", 0),
("整个故事一点吸引力都没有。", 0),
("对白浮夸、尴尬、无趣。", 0),
("演出风格极其生硬,看得想笑。", 0),
("导演野心很大,但能力配不上。", 0),
("一星都嫌多,真的劝退。", 0),
("毫无新意,重复老套路。", 0),
("看完想报警,太难受了。", 0),
("整部电影像拼凑出来的垃圾。", 0),
("视觉效果和音效都令人崩溃。", 0),
("完全不知道这片子拍来干什么。", 0),
("主题不清,剧情混乱。", 0),
("毫无逻辑,漏洞百出。", 0),
("整部影片都没说清楚自己要表达什么。", 0),
("观影过程极其痛苦,毫无快感。", 0),
("导演强行煽情,非常做作。", 0),
("让人不断出戏,根本无法入戏。", 0),
("制作水平非常低劣。", 0),
("真的是烂片代表。", 0),
("全程无趣无感。", 0),
("哪怕做背景音都嫌吵。", 0),
("演技和剪辑双重灾难。", 0),
("完全对不起票价。", 0),
("我已经忘了我看过这片。", 0),
("严重低于预期,非常失望。", 0),
]
def tokenize(text):
'''
jieba分词
'''
return list(jieba.cut(text))
# ---------- 构建词表 ----------
all_tokens = [tok for text, _ in train_data for tok in tokenize(text)]
vocab = {"<PAD>": 0, "<UNK>": 1}
# 自动编号,编号从2开始(0 和 1 预留给 <PAD> 和 <UNK>)
vocab.update({tok: i+2 for i, tok in enumerate(Counter(all_tokens))}) # 需要保存或调用 vocab
max_len = 20
embedding_dim = 32
hidden_dim = 64
def encode(text):
tokens = tokenize(text)
ids = [vocab.get(t, 1) for t in tokens][:max_len]
return ids + [0] * (max_len - len(ids))
X = torch.tensor([encode(text) for text, _ in train_data])
y = torch.tensor([label for _, label in train_data])
class MovieDataset(Dataset):
def __init__(self, X, y):
self.X, self.y = X, y
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
return self.X[idx], self.y[idx]
train_loader = DataLoader(MovieDataset(X, y), batch_size=2, shuffle=True)
# ---------- 模型定义 ----------
class SentimentModel(nn.Module):
def __init__(self, vocab_size, emb_dim, hidden_dim):
super().__init__()
self.embedding = nn.Embedding(vocab_size, emb_dim, padding_idx=0) # 对每个词ID,查一个可训练的向量表,把它变成一个稠密向量
self.lstm = nn.LSTM(emb_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, 3)
def forward(self, x):
emb = self.embedding(x) # [batch_size, seq_len] → [batch_size, seq_len, emb_dim]
_, (hn, _) = self.lstm(emb) # hn shape: [1, batch_size, hidden_dim] # hn[-1] 是最后一个时刻的隐藏状态 → [batch_size, hidden_dim]
return self.fc(hn[-1]) # 对应 3 类情感(差评 / 一般 / 强烈好评)
model_path = "sentiment_model.pth"
def load_or_train_model():
model = SentimentModel(len(vocab), embedding_dim, hidden_dim)
if os.path.exists(model_path):
print("加载已保存模型")
model.load_state_dict(torch.load(model_path))
else:
print("未找到模型,开始训练...")
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(10):
for batch_x, batch_y in train_loader:
logits = model(batch_x)
loss = criterion(logits, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}, Loss: {loss.item():.4f}")
torch.save(model.state_dict(), model_path)
print("模型已保存为 sentiment_model.pth")
model.eval()
return model
# ---------- 预测函数 ----------
label_map = {0: "差评", 1: "一般", 2: "强烈好评"}
def predict_sentiment(model, text, vocab, max_len=20):
model.eval()
with torch.no_grad():
tokens = tokenize(text)
ids = [vocab.get(t, 1) for t in tokens][:max_len]
padded = ids + [0] * (max_len - len(ids))
input_tensor = torch.tensor([padded])
logits = model(input_tensor)
pred = torch.argmax(logits, dim=1).item()
return label_map[pred]
if __name__ == "__main__":
model = load_or_train_model()
test_text = "剧情特别好,演员演技也很好。"
print("预测情感:", predict_sentiment(model, test_text, vocab))7.4 意图识别和各种操作
from Levenshtein import distance as levenshtein_distance
import pandas as pd
import whisper
from user_input_NER import load_hanlp_model, process_text, record_audio, transcribe_audio
import torch
from sentiment_train import SentimentModel, predict_sentiment, tokenize, vocab
# 定义参数保持一致
embedding_dim = 32
hidden_dim = 64
max_len = 20
# 初始化模型并加载权重
model = SentimentModel(len(vocab), embedding_dim, hidden_dim)
model.load_state_dict(torch.load("mainback\sentiment_model.pth"))
model.eval()
from snownlp import SnowNLP
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from node2vec import Node2Vec
import networkx as nx
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 加载电影数据
df = pd.read_csv('data\data_upload_cleaned.csv')
# 用于指代消解
last_movie_names = None
def find_closest_movie(movie_name, df, max_distance):
"""
使用编辑距离查找最接近的电影名
:param movie_name: 要查找的电影名
:param df: 电影数据DataFrame
:param max_distance: 最大允许的编辑距离
:return: 最接近的电影名或None
"""
min_dist = float('inf')
closest_name = None
for name in df['title'].unique():
current_dist = levenshtein_distance(movie_name, name)
if current_dist < min_dist and current_dist <= max_distance:
min_dist = current_dist
closest_name = name
return closest_name
def get_movie_row(movie_name, df):
"""
获取电影行数据,如果找不到则尝试使用编辑距离查找最接近的电影
:param movie_name: 电影名
:param df: 电影数据DataFrame
:return: (row, corrected_name) 行数据和修正后的电影名
"""
row = df[df['title'] == movie_name]
if not row.empty:
closest_name = None
return row, movie_name, closest_name
# 尝试查找编辑距离为1的最接近电影名
max_distance = len(movie_name) // 2
closest_name = find_closest_movie(movie_name, df, max_distance)
if closest_name:
row = df[df['title'] == closest_name]
if not row.empty:
return row, movie_name, closest_name
return pd.DataFrame(), movie_name, None
# 各类回应函数
def Request_rate(movie_name):
# row = df[df['title'] == movie_name]
row, movie_name, corrected_name = get_movie_row(movie_name, df)
if row.empty and (corrected_name is None):
return f"找不到电影《{movie_name}》的评分信息。"
movie_name = corrected_name if corrected_name else movie_name
try:
# 1. 提取当前电影的评分
rating = float(row.iloc[0]['rating'])
# 2. 排序所有评分(注意去除缺失值,并转换为数值型)
rating_series = pd.to_numeric(df['rating'], errors='coerce').dropna()
sorted_ratings = rating_series.sort_values(ascending=False).reset_index(drop=True)
# 3. 计算当前电影在排序中的名次(排名从0开始)
rank = sorted_ratings[sorted_ratings == rating].index[0] + 1 # index从0起,排名从1起
total = len(sorted_ratings)
# 4. 计算百分比
percentile = (1 - (rank - 1) / total) * 100 # 越高分越靠前
percentile = round(percentile, 2)
# 5. 评论情感分析
review = row.iloc[0]['first_review']
# print(f"原始评论:{review}")
sentiment = predict_sentiment(model, review, vocab, max_len=max_len)
response = (
f"《{movie_name}》的评分是 {rating} 分,排名在所有电影中前 {percentile}%。\n"
f"此外,根据用户评论,体现出的情感倾向为:{sentiment}。"
)
if corrected_name:
response = f"未找到《{movie_name}》,但找到了相似的《{corrected_name}》。\n" + response
return response
except Exception as e:
return f"评分数据处理出错:{str(e)}"
def Request_rate_s(movie_names):
responses = []
for movie_name in movie_names:
row, movie_name, corrected_name = get_movie_row(movie_name, df)
if row.empty:
responses.append(f"找不到电影《{movie_name}》的评分信息。")
continue
used_name = corrected_name if corrected_name else movie_name
try:
rating = float(row.iloc[0]['rating'])
rating_series = pd.to_numeric(df['rating'], errors='coerce').dropna()
sorted_ratings = rating_series.sort_values(ascending=False).reset_index(drop=True)
rank = sorted_ratings[sorted_ratings == rating].index[0] + 1
total = len(sorted_ratings)
percentile = (1 - (rank - 1) / total) * 100
percentile = round(percentile, 2)
response = f"《{used_name}》的评分是 {rating} 分,排名在所有电影中前 {percentile}%。"
if corrected_name:
response = f"未找到《{movie_name}》,但找到了相似的《{corrected_name}》。\n" + response
responses.append(response)
except Exception as e:
responses.append(f"评分数据处理出错({used_name}):{str(e)}")
return "\n".join(responses)
def Request_dire(movie_name, director_name_list):
row, movie_name, corrected_name = get_movie_row(movie_name, df)
if row.empty:
return f"找不到电影《{movie_name}》。"
used_name = corrected_name if corrected_name else movie_name
true_director = row.iloc[0]['director']
response = ""
if corrected_name:
response = f"未找到《{movie_name}》,但找到了相似的《{corrected_name}》。\n"
if not director_name_list:
return response + f"《{used_name}》的导演是 {true_director}。"
result = []
for name in director_name_list:
result.append(f"{name} 是导演:{name == true_director}(实际导演:{true_director})")
return response + ";".join(result)
def min_substring_distance(s1, s2, max_distance):
"""
计算 s1 和 s2 的所有子串之间的最小编辑距离
:param s1: 待匹配字符串
:param s2: 目标字符串
:param max_distance: 最大允许编辑距离
:return: 最小编辑距离(如果 ≤ max_distance),否则返回 None
"""
min_dist = float('inf')
len_s1 = len(s1)
# 遍历 s2 的所有可能子串(长度与 s1 相同)
for i in range(len(s2) - len_s1 + 1):
substring = s2[i:i + len_s1]
current_dist = levenshtein_distance(s1, substring)
if current_dist < min_dist:
min_dist = current_dist
if min_dist == 0: # 提前终止,如果找到完美匹配
return 0
return min_dist if min_dist <= max_distance else None
def is_actor_fuzzy_match(name, true_actors, max_distance):
"""
结合子串匹配和子串编辑距离判断是否为演员
:param name: 待检查的名称
:param true_actors: 真实演员列表
:param max_distance: 最大允许编辑距离(默认2)
:return: (是否匹配, 最接近的演员名)
"""
# 1. 子串匹配(完全包含)
for actor in true_actors:
if name in actor:
return True, actor
# 2. 子串编辑距离匹配
closest_actor = None
min_dist = float('inf')
for actor in true_actors:
dist = min_substring_distance(name, actor, max_distance)
if dist is not None and dist < min_dist:
min_dist = dist
closest_actor = actor
if min_dist == 0: # 提前终止
break
return (min_dist <= max_distance), closest_actor
def Request_act(movie_name, actor_name_list):
row, movie_name, corrected_name = get_movie_row(movie_name, df)
if row.empty:
return f"找不到电影《{movie_name}》。"
used_name = corrected_name if corrected_name else movie_name
true_actors = row.iloc[0]['actors'].split(',')
response = ""
# if corrected_name:
# response = f"未找到《{movie_name}》,但找到了相似的《{corrected_name}》。\n"
# if not actor_name_list:
# return response + f"《{used_name}》的演员包括:{','.join(true_actors)}。"
# result = []
# for name in actor_name_list:
# is_actor = any(name in actor for actor in true_actors)
# result.append(f"{name} 是演员:{'是' if is_actor else '否'}")
# return response + ";".join(result)
if corrected_name:
response = f"未找到《{movie_name}》,但找到了相似的《{corrected_name}》。\n"
if not actor_name_list:
return response + f"《{used_name}》的演员包括:{','.join(true_actors)}。"
result = []
for name in actor_name_list:
max_distance = len(name) // 2
is_match, closest_actor = is_actor_fuzzy_match(name, true_actors, max_distance)
if is_match:
if closest_actor != name: # 如果是模糊匹配,提示实际演员名
result.append(f"{name}(匹配 {closest_actor})是演员:是")
else: # 精确匹配
result.append(f"{name} 是演员:是")
else:
result.append(f"{name} 是演员:否")
return response + ";".join(result)
def Request_year(movie_name):
row, movie_name, corrected_name = get_movie_row(movie_name, df)
if row.empty:
return f"找不到电影《{movie_name}》。"
used_name = corrected_name if corrected_name else movie_name
response = f"《{used_name}》的上映年份是:{row.iloc[0]['release_date']}"
if corrected_name:
response = f"未找到《{movie_name}》,但找到了相似的《{corrected_name}》。\n" + response
return response
def Request_type(movie_name):
row, movie_name, corrected_name = get_movie_row(movie_name, df)
if row.empty:
return f"找不到电影《{movie_name}》。"
used_name = corrected_name if corrected_name else movie_name
response = f"《{used_name}》的类型是:{row.iloc[0]['genre']}"
if corrected_name:
response = f"未找到《{movie_name}》,但找到了相似的《{corrected_name}》。\n" + response
return response
def Request_lang(movie_name):
row, movie_name, corrected_name = get_movie_row(movie_name, df)
if row.empty:
return f"找不到电影《{movie_name}》。"
used_name = corrected_name if corrected_name else movie_name
response = f"《{used_name}》的语种是:{row.iloc[0]['language']}"
if corrected_name:
response = f"未找到《{movie_name}》,但找到了相似的《{corrected_name}》。\n" + response
return response
def generate_wordcloud(text, movie_name):
# 使用jieba分词
words = jieba.lcut(text)
filtered_words = [w for w in words if len(w.strip()) > 1] # 去掉单字和空格
result = ' '.join(filtered_words)
# 创建词云对象
wc = WordCloud(
font_path="simhei.ttf",
width=800,
height=400,
background_color='white'
).generate(result)
# 显示图像
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.tight_layout()
output_path = f"ui\static\quote_wordcloud\{movie_name}.png"
plt.savefig(output_path)
plt.show()
plt.close()
def generate_summary(text, max_sentences=3):
s = SnowNLP(text)
return ','.join(s.summary(max_sentences))+ '。'
def Request_cont(movie_name):
row, movie_name, corrected_name = get_movie_row(movie_name, df)
if row.empty:
return f"找不到电影《{movie_name}》。"
used_name = corrected_name if corrected_name else movie_name
text = row.iloc[0]['quote']
summary = generate_summary(text)
generate_wordcloud(text, used_name)
response = f"《{used_name}》的简介摘要是:{summary}"
if corrected_name:
response = f"未找到《{movie_name}》,但找到了相似的《{corrected_name}》。\n" + response
return response
# 构建内容相似图(可以基于类型、语言、国家等字段)
def build_similarity_graph(df):
G = nx.Graph()
for i, row_i in df.iterrows():
G.add_node(row_i['title'])
for i in range(len(df)):
for j in range(i + 1, len(df)):
sim_score = compute_content_similarity(df.iloc[i], df.iloc[j])
if sim_score > 0.3: # 可以设置阈值如0.2
G.add_edge(df.iloc[i]['title'], df.iloc[j]['title'], weight=sim_score)
return G
# 计算两个电影的“内容相似度”
def compute_content_similarity(row1, row2):
# 可根据需要扩展字段
features1 = f"{row1['genre']} {row1['language']} {row1['country']} {row1['rating']} {row1['quote']} {row1['first_review']} {row1['runtime']}"
features2 = f"{row2['genre']} {row2['language']} {row2['country']} {row2['rating']} {row2['quote']} {row2['first_review']} {row2['runtime']}"
return jaccard_similarity(features1, features2)
# # 计算基础Jaccard相似度
# base_sim = jaccard_similarity(features1, features2)
# # 单独计算高权重特征相似度
# genre_sim = jaccard_similarity_str(row1['genre'], row2['genre'])
# try:
# rating_diff = abs(float(row1['rating']) - float(row2['rating']))
# rating_sim = 1 - min(rating_diff / 5.0, 1.0) # 假设评分范围0-5
# except:
# rating_sim = 0
# quote_sim = jaccard_similarity_str(str(row1['quote']), str(row2['quote']))
# # 加权融合(原始相似度占55%,高权重特征占45%)
# weighted_sim = (
# 0.55 * base_sim +
# 0.25 * genre_sim +
# 0.15 * rating_sim +
# 0.05 * quote_sim
# )
# return float(weighted_sim)
def jaccard_similarity(text1, text2):
set1 = set(text1.lower().replace(',', ' ').split())
set2 = set(text2.lower().replace(',', ' ').split())
intersection = set1.intersection(set2)
union = set1.union(set2)
return len(intersection) / len(union) if union else 0
# 计算文本Jaccard相似度
def jaccard_similarity_str(str1, str2):
set1 = set(str1.replace(',', ' ').split())
set2 = set(str2.replace(',', ' ').split())
intersection = set1 & set2
union = set1 | set2
return len(intersection) / len(union) if union else 0
# 判断字段是否“相似”
def field_is_similar(field, val1, val2):
if pd.isna(val1) or pd.isna(val2):
return False
if field in ['genre', 'country', 'language', 'quote', 'first_review']:
return jaccard_similarity_str(str(val1), str(val2)) >= 0.5
elif field == 'rating':
try:
return abs(float(val1) - float(val2)) <= 0.5
except:
return False
elif field == 'runtime':
try:
return abs(float(val1) - float(val2)) <= 20
except:
return False
return False
def Request_sim(movie_name):
row, movie_name, corrected_name = get_movie_row(movie_name, df)
if row.empty:
return f"找不到电影《{movie_name}》。"
used_name = corrected_name if corrected_name else movie_name
try:
G = build_similarity_graph(df)
node2vec = Node2Vec(G, dimensions=64, walk_length=10, num_walks=100, workers=1, quiet=True)
model = node2vec.fit(window=5, min_count=1, batch_words=4)
movie_vec = model.wv[used_name]
all_titles = list(G.nodes)
vectors = np.array([model.wv[title] for title in all_titles])
similarities = cosine_similarity([movie_vec], vectors)[0]
title_sim_pairs = list(zip(all_titles, similarities))
title_sim_pairs = sorted(title_sim_pairs, key=lambda x: -x[1])
top_matches = [(t, round(s, 3)) for t, s in title_sim_pairs if t != used_name][:2]
if not top_matches:
response = f"《{used_name}》没有找到相似推荐。"
else:
reasons = []
for rec_title, sim_score in top_matches:
sim_fields = []
r1 = df[df['title'] == used_name].iloc[0]
r2 = df[df['title'] == rec_title].iloc[0]
for field in ['genre', 'language', 'country', 'rating', 'quote', 'first_review', 'runtime']:
if field_is_similar(field, r1[field], r2[field]):
sim_fields.append(field)
reason_str = "、".join(sim_fields) if sim_fields else "多个内容维度"
reasons.append(f"推荐《{rec_title}》(相似度 {sim_score:.4f}),在 {reason_str} 上与原片相似。")
response = "\n".join(reasons)
if corrected_name:
response = f"未找到《{movie_name}》,但找到了相似的《{corrected_name}》。\n" + response
return response
except Exception as e:
return f"推荐系统出错:{str(e)}"
# 主流程
def handle_request(text):
global last_movie_names # 声明使用全局变量
hanlp_model = load_hanlp_model()
result = process_text(text, hanlp_model)
movie_names = result['电影名']
persons = result['人名']
intents = result['用户意图']
# 指代消解逻辑
if not movie_names and any(pronoun in text for pronoun in ["它", "他", "她"]):
if last_movie_names:
movie_names = last_movie_names
print(f"使用指代消解,引用最近一次的电影名: {movie_names}")
else:
return "未识别出电影名且无历史记录可供引用。"
# if not movie_names:
# return "未识别出电影名。"
last_movie_names = movie_names
movie_name = movie_names[0]
responses = []
for intent in intents:
if intent == '评分':
if len(movie_names) > 1:
responses.append(Request_rate_s(movie_names))
else:
responses.append(Request_rate(movie_name))
elif intent == '导演':
responses.append(Request_dire(movie_name, persons))
elif intent == '演员':
responses.append(Request_act(movie_name, persons))
elif intent == '年份':
responses.append(Request_year(movie_name))
elif intent == '类型':
responses.append(Request_type(movie_name))
elif intent == '语种':
responses.append(Request_lang(movie_name))
elif intent == '简介':
responses.append(Request_cont(movie_name))
elif intent == '推荐':
responses.append(Request_sim(movie_name))
else:
responses.append("暂不支持该意图。")
return "\n".join(responses)
if __name__ == "__main__":
# 获取用户输入方式
while True:
input_method = input("请选择输入方式(1-语音输入,其他-文本输入):").strip()
if input_method == "1":
# 语音输入模式
whisper_model = whisper.load_model("base")
audio, sr = record_audio()
audio = (audio * 32767).astype(np.int16) # 转换为int16格式
text = transcribe_audio(whisper_model, audio, sr)
print(f"识别结果:{text}")
else:
# 文本输入模式
text = input("请输入文本:").strip()
print(handle_request(text))
7.5 homepage页面
<!DOCTYPE html>
<html lang="zh-cn">
<head>
<meta charset="UTF-8">
<title>电影知识图谱问答系统</title>
<style>
body { background: #f5f6fa; font-family: "微软雅黑", Arial; text-align: center; }
.container { margin-top: 120px; }
h1 { color: #2d3436; }
.btn { margin: 30px 20px; padding: 18px 48px; font-size: 1.3em; border-radius: 8px; border: none; background: #0984e3; color: #fff; cursor: pointer; }
.btn:hover { background: #00b894; }
.desc { color: #636e72; margin-top: 30px; }
</style>
</head>
<body>
<div class="container">
<h1>电影知识图谱问答系统</h1>
<div class="desc">请选择您的身份进入系统</div>
<a href="/user"><button class="btn">用户入口</button></a>
<a href="/admin"><button class="btn">管理员入口</button></a>
</div>
</body>
</html>7.6 用户页面
<!DOCTYPE html>
<html lang="zh-cn">
<head>
<meta charset="UTF-8">
<title>电影知识图谱问答系统</title>
<style>
body { background: #f5f6fa; font-family: "微软雅黑", Arial; }
.chatbox { width: 600px; margin: 40px auto; background: #fff; border-radius: 10px; box-shadow: 0 2px 8px #dfe6e9; padding: 30px; }
.msg-list { min-height: 200px; max-height: 400px; overflow-y: auto; margin-bottom: 20px; }
.msg { margin: 10px 0; }
.msg.user { text-align: right; color: #0984e3; }
.msg.bot { text-align: left; color: #636e72; }
.input-area { display: flex; }
.input-area input { flex: 1; padding: 10px; font-size: 1em; border-radius: 5px; border: 1px solid #b2bec3; }
.input-area button { margin-left: 10px; padding: 10px 24px; font-size: 1em; border-radius: 5px; border: none; background: #0984e3; color: #fff; cursor: pointer; }
.input-area button:hover { background: #00b894; }
.graph-area { margin-top: 30px; }
</style>
</head>
<body>
<div class="chatbox">
<h2>电影知识图谱问答</h2>
<div class="msg-list" id="msgList"></div>
<div class="input-area">
<input id="userInput" type="text" placeholder="请输入您的问题,如:泰坦尼克号的导演是谁?" onkeydown="if(event.key==='Enter'){sendMsg();}">
<button onclick="sendMsg()">发送</button>
<button id="voiceBtn" onclick="startVoiceInput()" style="margin-left:10px;background:#fdcb6e;color:#2d3436;">🎤 语音</button>
</div>
<div class="graph-area" id="graphArea"></div>
</div>
<script>
let msgList = document.getElementById('msgList');
let history = [];
function appendMsg(text, sender) {
let div = document.createElement('div');
div.className = 'msg ' + sender;
div.innerText = text;
msgList.appendChild(div);
msgList.scrollTop = msgList.scrollHeight;
}
function sendMsg() {
let input = document.getElementById('userInput');
let text = input.value.trim();
if (!text) return;
appendMsg(text, 'user');
input.value = '';
fetch('/api/qa', {
method: 'POST',
headers: {'Content-Type': 'application/json'},
body: JSON.stringify({question: text, history: history})
})
.then(res => res.json())
.then(data => {
// 兼容后端返回 answer 或 response 字段
let answer = data.answer || data.response || data.summary || data.director || JSON.stringify(data);
appendMsg(answer, 'bot');
history.push({question: text, answer: answer});
// 可视化图谱(如有)
if (data.graph) {
showGraph(data.graph);
}
});
}
function showGraph(graph) {
let area = document.getElementById('graphArea');
area.innerHTML = '<pre style="text-align:left;">' + JSON.stringify(graph, null, 2) + '</pre>';
// 可用 Echarts/Cytoscape.js 等前端库替换这里的展示
}
function startVoiceInput() {
let SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition;
if (!SpeechRecognition) {
alert('当前浏览器不支持语音识别,请使用新版Chrome或Edge浏览器!');
return;
}
let recognition = new SpeechRecognition();
recognition.lang = 'zh-CN';
recognition.continuous = false;
recognition.interimResults = false;
recognition.onresult = function(event) {
let text = event.results[0][0].transcript;
document.getElementById('userInput').value = text;
sendMsg();
};
recognition.onerror = function(event) {
alert('语音识别出错: ' + event.error);
};
recognition.start();
}
</script>
</body>
</html>7.7 flask
from flask import Flask, render_template, request, jsonify
import sys
sys.path.append('./mainback')
from mainback.request import handle_request
from mainback.manage_input_RE import extract_relations
app = Flask(__name__, template_folder='ui/templates')
@app.route('/')
def home():
return render_template('homepage.html')
@app.route('/user')
def user():
return render_template('user_request.html')
@app.route('/admin')
def admin():
return render_template('managedata.html')
@app.route('/api/qa', methods=['POST'])
def api_qa():
data = request.json
question = data.get('question', '')
result = handle_request(question)
return jsonify({"answer": result, "graph": None})
@app.route('/api/extract', methods=['POST'])
def api_extract():
data = request.json
sentence = data.get('sentence', '')
triples = extract_relations(sentence)
return jsonify({"triples": triples})
if __name__ == '__main__':
app.run(debug=True)
火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 61
61 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)