【BEV地图(1)】VectorMapNet: End-to-end Vectorized HD Map Learning
自动驾驶系统需要高清 (HD) 语义地图来导航城市道路。现有的解决方案通过离线手动标注来解决语义地图绘制问题,但这种方法存在严重的可扩展性问题。近期基于学习的方法可以生成密集的栅格化分割预测来构建地图。然而,这些预测不包含单个地图元素的实例信息,并且需要启发式后处理才能获得矢量化地图。为了应对这些挑战,我们引入了一种端到端的矢量化高清地图学习流程,称为 VectorMapNet。VectorMap
地址:https://arxiv.org/abs/2206.08920
摘要
自动驾驶系统需要高清 (HD) 语义地图来导航城市道路。现有的解决方案通过离线手动标注来解决语义地图绘制问题,但这种方法存在严重的可扩展性问题。近期基于学习的方法可以生成密集的栅格化分割预测来构建地图。然而,这些预测不包含单个地图元素的实例信息,并且需要启发式后处理才能获得矢量化地图。为了应对这些挑战,我们引入了一种端到端的矢量化高清地图学习流程,称为 VectorMapNet。VectorMapNet 利用车载传感器的观测数据,预测鸟瞰图中一组稀疏的折线。该流程可以明确地建模地图元素之间的空间关系,并生成对下游自动驾驶任务友好的矢量化地图。
大量实验表明,VectorMapNet 在 nuScenes 和 Argoverse2 数据集上均实现了出色的地图学习性能,分别比之前的最优方法分别高出 14.2 mAP 和 14.6 mAP。从质量上讲,VectorMapNet 能够生成全面的地图并捕捉道路几何的细粒度细节。据我们所知,VectorMapNet 是第一个基于车载观测数据进行端到端矢量化地图学习的成果。
1. Introduction
自动驾驶系统需要理解道路上的地图元素,包括车道、人行横道和交通标志,才能在世界各地导航。这些地图元素通常由现有流程中预先标注的高清 (HD) 语义地图提供 (Rong et al., 2020)。然而,由于这些方法严重依赖人工标注高清地图,因此面临可扩展性问题。此外,它们需要对自车进行精确定位,以便从全局地图中获取局部地图,而这一过程可能会引入米级误差。
相比之下,我们的重点在于开发一种基于学习的在线高清语义地图学习方法。目标是利用包括激光雷达和摄像头在内的机载传感器,实时估算地图元素。这种方法无需定位,从而能够快速更新。此外,基于学习的方法可以生成不确定性或置信度指标,供运动预测和规划等下游模块用来弥补感知的缺陷。这些方法可以利用不断增长的数据和模型规模,及时反映当前情况,并能够从带注释的地图推广到注释不足甚至无注释的区域(参见图6)。
大多数高清语义地图学习方法 (Li et al., 2021; Philion & Fidler, 2020; Roddick & Cipolla, 2020; Zhou & Kr¨ ahenb¨ uhl, 2022) 将该任务视为鸟瞰视图 (BEV) 中的语义分割问题,即将地图元素栅格化为像素,并为每个像素分配一个类别标签。这种方案使得利用全卷积网络变得非常简单。然而,栅格化地图并非自动驾驶的理想地图表示,原因有三。首先,栅格化地图缺乏区分具有相同类别标签但不同语义的地图元素(例如左边界和右边界)所需的实例信息。其次,难以在预测的栅格化地图中强制实现空间一致性,例如,相邻像素可能具有相互矛盾的语义或几何形状。第三,2D 栅格化地图与大多数自动驾驶系统不兼容,因为这些系统使用实例级 2D/3D 矢量化地图进行运动预测和规划。
Li, Q., Wang, Y., Wang, Y., and Zhao, H. Hdmapnet: A local semantic map learning and evaluation framework.
arXiv preprint arXiv:2107.06307, 2021.
Philion, J. and Fidler, S. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In European Conference on Computer Vision, pp. 194–210. Springer, 2020.
Roddick, T. and Cipolla, R. Predicting semantic map representations from images using pyramid occupancy networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11138
11147, 2020
Zhou, B. and Kr¨ahenb¨uhl, P. Cross-view transformers for real-time map-view semantic segmentation. arXiv
preprint arXiv:2205.02833, 2022.
为了缓解这些问题并生成矢量化输出,HDMapNet(Li 等人,2021)生成语义、实例和方向图,并使用手动设计的后处理算法对这三种地图进行矢量化。然而,HDMapNet 仍然依赖于栅格化地图预测,其启发式后处理步骤限制了模型的可扩展性和性能。
在本文中,我们提出了一种端到端的矢量化高清地图学习模型 VectorMapNet。这是一个端到端的框架,它不涉及密集语义像素或复杂的后处理步骤。相反,它将地图元素表示为一组与下游任务(例如运动预测 (Gao et al., 2020))密切相关的折线。因此,建图问题归结为根据传感器观测值预测一组稀疏的折线。具体来说,我们将其视为一个检测问题,并利用最新的集合检测和序列生成方法。首先,VectorMapNet 将不同模态(例如摄像头图像和激光雷达)生成的特征聚合到一个通用的 BEV 特征空间中。然后,它基于可学习的元素查询和 BEV 特征检测地图元素位置。最后,我们将每个元素查询解码为一条折线。VectorMapNet 的概览如图 1 所示。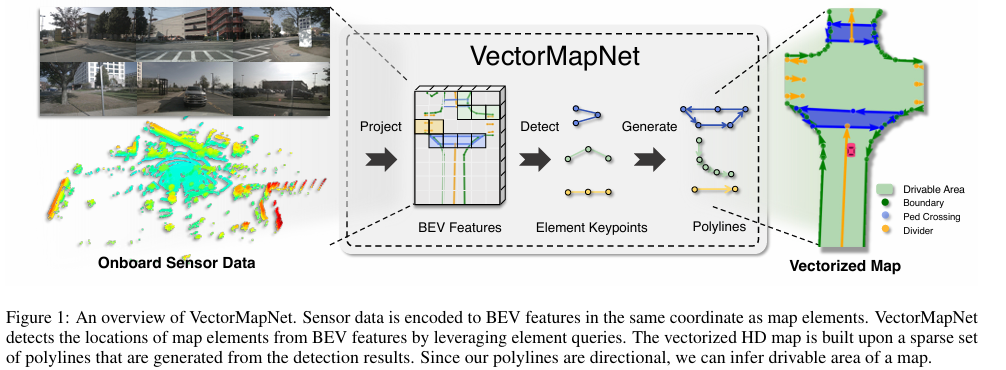
我们的实验表明,VectorMapNet 在公共 nuScenes 数据集(Caesar 等人,2020 年)和 Argoverse2(Wilson 等人,2021 年)上达到了最佳性能,比 HDMapNet 和另一个基准模型至少高出 14.2 mAP。从质量上看,VectorMapNet 构建的地图比以往的研究成果更全面,能够捕捉精细的细节,例如锯齿状边界。此外,我们将预测的矢量化高清地图输入到下游运动预测模块,证明了预测地图的兼容性和有效性。总结一下,本文的贡献如下:
• 我们提出了一种端到端的地图绘制方法 VectorMapNet,它通过直接从传感器观测数据预测矢量化输出,无需进行地图栅格化和后处理。
• 我们利用折线(polyline)这一灵活的基元,其长度和编码顺序可变,以适应地图元素的异构性。这种方法有效地将折线地图的构建转化为检测问题,从而为地图绘制范式引入了一种新的策略。
我们采用检测变换器 (DETR) 模型来定位三维空间中的可变形元素。鉴于目前流行的基于中心点的特征提取方法在处理不同大小和形状的地图元素时存在不足,我们提出了一种创新的解决方案。我们的新方法克服了这些局限性,在在线语义高清地图学习任务中实现了最佳性能。
2. Related Works
语义地图学习。由于自动驾驶的发展,语义地图标注引起了广泛关注。近年来,语义地图学习被表述为语义分割问题 (Mattyus et al., 2015),并利用航拍图像 (Mattyus et al., 2016)、激光雷达点云 (Yang et al., 2018) 和高清全景图 (Wang et al., 2016) 进行求解。众包标签 (Wang et al., 2015) 用于提升细粒度分割的性能。近期的研究并未使用离线数据,而是专注于从车载摄像头图像 (Lu et al., 2019; Yang et al., 2021) 和视频 (Can et al., 2020) 中理解车辆行驶 (BEV) 语义。仅使用车载传感器作为模型输入尤其具有挑战性,因为输入和目标地图位于不同的坐标系中。最近,一些跨视图学习方法(Philion & Fidler,2020;Pan 等人,2020;Li 等人,2021;Zhou & Kr¨ahenb¨uhl,2022;Wang 等人,2022;Chen 等人,2022)利用场景的几何结构来缓解传感器输入与 BEV 表示之间的不匹配。一些方法(Casas 等人,2021;Sadat 等人,2020)使用像素级语义图来解决下游任务,但整个下游流程需要重新设计以适应这些栅格化的图输入。
除了像素级语义地图之外,我们的工作还从周围的摄像头或激光雷达中提取了围绕自身车辆的一致矢量化地图,这适用于现有的下游任务,例如运动预测(Gao et al., 2020; Zhao et al., 2020; Liu et al., 2021),而无需进一步的后处理。
车道检测。车道检测旨在从道路场景中精确地分离出车道线段。大多数车道检测算法(Panet 等,2018;Neven 等,2018)使用像素级分割技术,并结合复杂的后处理。另一项研究利用预定义的提案来实现高精度和快速推理速度。这些方法通常涉及手动设计元素,例如消失点(Lee 等,2017)、多项式曲线(Van Gansbeke 等,2019)、线段(Li 等,2019)和贝塞尔曲线(Feng 等,2022)来建模提案。除了使用透视摄像机作为输入外,(Homayounfaretal., 2018) 和 (Liangetal., 2019) 还使用当前的神经网络从高架高速公路摄像机和激光雷达图像中提取车道线段。STSU (Canetal., 2021) 和 LaneGraphNet (Zuurnetal., 2021) 不是通过边界检测来发现道路的拓扑结构,而是根据分别由贝塞尔曲线和线段编码的中心线段构建车道图。为了在城市环境中模拟复杂的几何形状,我们利用折线来表示感知范围内的所有地图元素。
几何数据建模。与矢量地图网 (VectorMapNet) 密切相关的另一项工作是几何数据生成。这些方法通常将几何元素视为序列,例如家具的原始部件 (Lietal., 2017; Moetal., 2019)、草图笔触的状态 (Ha & Eck, 2017)、n 边形网格的顶点 (Nashetal., 2020) 以及 SVG 基元的参数 (Carlieetal., 2020)。这些方法利用自回归模型(例如 Transformer)生成这些序列。由于直接建模序列对于长距离中心线地图来说具有挑战性,HDMapGen (Mi etal., 2021) 将地图视为两级层次结构。它使用分层图RNN分别生成全局图和局部图。LETR(Xuetal.,2021)不是将几何元素视为序列生成问题,而是将线段建模为检测问题,并使用基于查询的检测器来处理。与上述专注于单级几何建模(例如场景级(例如图像中的线段)或对象级(例如家具))的方法不同,VectorMapNet 旨在同时解决场景级和对象级几何建模。具体而言,VectorMapNet 通过建模场景中地图元素之间的全局关系以及每个元素内部的局部几何细节来构建地图。
从图像中学习矢量表示。VectorMapNet 与从光栅图像预测矢量图形有一些相似之处。最近的几篇研究(Carlie 等,2020;Reddy 等,2021)使用不同的矢量表示来生成矢量图像。 (Ganinetal.,2021) 将图像转换为 CAD,CanvasVAE (Yamaguchi,2021) 从图像中学习矢量化的画布布局,以及(Liuetal.,2022) 从光栅线图生成矢量化的笔触基元。实例分割社区也关注类似的任务,即从图像中检测矢量形式的对象轮廓。这些方法 (Acunaetal.,2018;Liangetal.,2020;Castrejoetal.,2017;Zorzietal.,2022;Zhang&Wang,2019) 为每个对象实例初始化轮廓,然后细化轮廓的每次曝光。然而,上述方法它们高度依赖于领域,因此,要使它们适应我们的任务并不容易,因为我们需要在 3D 世界中检测和生成具有不同语义和几何形状的地图元素。
3. VectorMapNet
问题表述与挑战。与 HDMapNet (Li et al., 2021) 类似,我们的任务是利用来自自动驾驶汽车车载传感器(例如 RGB 摄像头和/或 LiDAR)的数据对地图元素进行矢量化。这些地图元素包括但不限于:道路边界(分隔道路和人行道的道路边界,通常是任意长度的不规则形状的曲线)、车道分隔线(道路上划分车道的边界,通常为直线)以及人行横道(带有白色标记的区域,表示合法的人行横道点,通常以多边形表示)。虽然这项任务定义明确,但在执行过程中却充满了复杂性和独特的挑战。(1) 地图元素的几何结构多样,难以建立统一的几何表示。(2) 建图问题的输入和输出并非完全对齐。它们存在于不同的视图空间中(例如,摄像头数据位于透视图中,而地图元素位于 BEV 图中),并且并非所有地图元素都能从输入传感器完全看到。在某些极端情况下,地图元素可能会被车辆完全遮挡。(3)这项任务需要的不仅仅是简单的矢量化;由于地图元素之间存在复杂的几何和拓扑关系,它还需要场景理解。例如,地图元素可能会重叠,或者用电线连接的两个交通锥可能指示道路边界。
3.1. Method Overview
上述挑战强调了需要一种能够有效表示各种几何结构的基元以及一种能够捕捉来自各种传感器输入的几何和拓扑关系的模型。
折线表示。地图元素的异构几何结构需要统一的矢量化表示。我们选择使用 N 条折线 Vpoly = {Vpoly1,…,Vpoly N } 作为图元,在 mapM 中表示这些地图元素。每条折线 Vpolyi = {vi,n ∈R2|n = 1,…,Nv} 是 Nv 个有序顶点 vi,n 的集合。在实践中,我们对公开的自动驾驶语义地图进行预处理,以获得地图元素的统一折线表示:多边形表示为闭合折线;曲线则通过应用 Ramer-Douglas-Peucker 算法(Ramer, 1972)转换为折线。
使用折线表示地图元素有三大优势:(1) 高清地图通常由多种几何图形组成,例如点、线、曲线和多边形。折线是一种灵活的图元,可以有效地表示这些几何元素。(2) 折线顶点的顺序是编码地图元素方向的自然方式,这对于驾驶至关重要。(3) 折线表示已被下游自动驾驶模块广泛应用,例如运动预测 (Gao et al., 2020)。
VectorMapNet。我们引入了 VectorMapNet,这是一个端到端模型,旨在用一组稀疏的折线 Vpoly 表示地图 M,从而将任务表述为稀疏集检测问题。在我们的方法中,我们将传感器数据转换为规范的鸟瞰图 (BEV) 表示 FBEV,并基于此 BEV 建模折线。鉴于地图元素结构和位置模式及关系的复杂性和多样性,我们将任务分为三个不同的部分:(1) BEV 特征提取器 (§ 3.2),将各种传感器模态输入提升到规范的特征空间。(2) 地图元素检测器 (§ 3.3),通过预测元素关键点 A = {Ai ∈ Rk×2|i = 1, …,N} 及其类标签 L = {li ∈ Z|i = 1, …,N} 来定位和分类所有地图元素。元素关键点表示 A 的定义在§3.3中描述。(3)折线生成器(§3.4)生成一系列有序的折线顶点,描述每个检测到的地图元素(Ai,li)的局部几何形状。图2展示了三个组件的概览。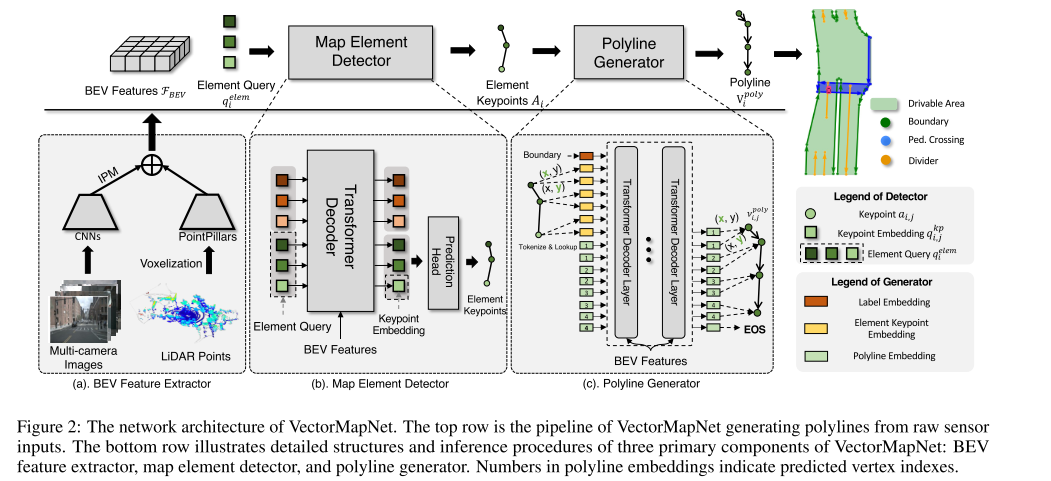
3.2. BEV Feature Extractor
BEV 特征提取器的目标是将各种模态输入提升到规范特征空间,并根据其坐标将这些特征聚合并对齐为一个规范表示,称为 BEV 特征 FBEV ∈ RW×H×(C1+C2),其中 W 和 H 分别表示 BEV 特征的宽度和高度;C1 和 C2 表示从两种常见模态中提取的 BEV 特征的输出通道:周围的摄像机图像 I 和 LiDAR 点 P。
相机分支。我们使用 ResNet 从图像中提取特征,然后使用特征转换模块从图像空间转换到 BEV 空间。VectorMapNet 不依赖于某些特征转换方法,我们选择使用 IPM 的一个简单但流行的变体,它生成的 BEV 特征为 FIBEV ∈ RW×H×C1。图像提取器的详细结构可参见附录 C.3。
LiDAR 分支。对于 LiDAR 数据 P,我们使用 PointPillars (Lang et al., 2019) 的变体,并进行动态体素化 (Zhou et al., 2020),将 3D 空间划分为多个柱状点云,并使用柱状点云来学习柱状特征图。我们将此特征图在 BEV 中表示为 FPBEV ∈ RW×H×C2。
对于传感器融合,我们通过连接 FIBEV 和 FP BEV 得到 BEV 特征 FBEV ∈ RW×H×(C1+C2),然后用两层卷积网络处理连接结果。图 2 左下方展示了 BEV 特征提取器的概览。
3.3. Map Element Detector
提取鸟瞰图 (BEV) 特征后,VectorMapNet 需要识别地图元素并利用这些特征进行抽象表示。为此,我们采用分层表示,具体来说,通过元素查询Element queries和关键点查询Keypoint representations,使我们能够有效地对地图元素的非局部形状进行建模。我们利用 Transformer 集预测检测器 (Carion et al., 2020) 的一个变体来实现这一目标,因为它是一个强大的检测器,无需额外的后处理。具体来说,该检测器通过根据 BEV 特征 FBEV 预测元素关键点 A 和类标签 L 来表示地图元素的位置和类别。
Element queries. 元素查询。检测器使用可学习的元素查询 qelemi ∈ Rk×d|i = 1, … ,Nmax 作为输入,其中 d 表示隐藏嵌入大小,Nmax 是预设常数,远大于场景中地图元素的数量 N。第 i 个元素查询 qelemi 由 k 个元素关键点嵌入 qkp i,j 组成:qelem = {qkp i i,j ∈ Rd|j = 1, … , k}。元素查询类似于 Detection Transformer (DETR) (Carion et al., 2020) 中使用的对象查询,其中一个查询代表一个对象。在我们的例子中,一个元素查询代表一个地图元素。
关键点表示。在物体检测问题中,人们使用边界框来抽象物体形状。这里我们使用 k 个元素关键点位置 Ai = {ai,j ∈ R2|j = 1, …, k}(请参见图 3)来表示地图元素的轮廓。然而,由于地图元素的多样性,定义关键点并非易事。我们在§4.3 中进行了一项消融研究,以探究不同选择的性能。需要注意的是,元素关键点不同于折线顶点,元素关键点是 VectorMapNet 的中间表示,会传递给折线生成器(§3.4)进行条件预测,每种折线的关键点数量是固定的,由其定义决定。折线是我们的输出表示。
架构。地图元素检测器的整体架构由一个变换器解码器(Vaswani 等人,2017)和一个预测头组成,如图 2 中下部分所示。解码器使用多头自注意力/交叉注意力机制对元素查询进行变换。具体而言,我们使用可变形注意力模块(Zhu 等人,2020)作为解码器的交叉注意力模块,其中每个元素查询都有一个二维位置基准。这提高了可解释性并加速了训练收敛(Li 等人,2022)。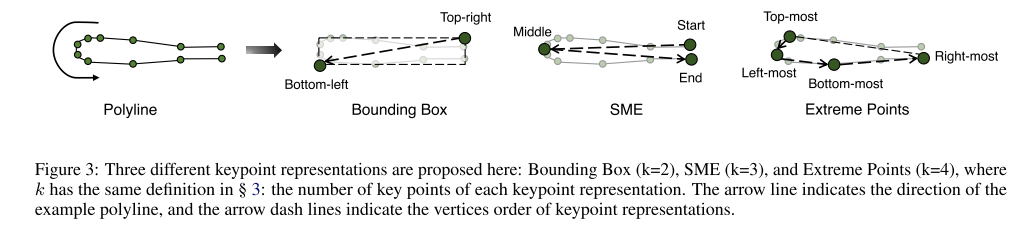
预测头有两个 MLP,分别将元素查询解码为元素关键点 ai,j = MLPkp(qkpi,j) 及其类标签 li = MLPcls([qkp i,1, . . . , qkp i,k])。[·] 是连接运算符。地图元素检测器中的每个关键点嵌入 qkpi,j 包含两个可学习的部分。第一部分是关键点位置嵌入 {ekpj ∈ Rd|j = 1, . . . , k},指示该点属于元素关键点中的哪个位置。第二个嵌入 {ep i ∈ Rd|i = 1, . . . ,Nmax} 编码关键点属于哪个地图元素。关键点嵌入 qkpi,j 是这两个嵌入 ep i + ekp
3.4. Polyline Generator
基于地图元素检测器识别出的地图元素的大致位置、形状和类别,折线生成器专注于高清地图的详细几何形状,这需要计算可变长度的折线顶点及其顺序。精确建模顶点关系至关重要 - 例如,两个顶点之间的白线通常表示矢量化地图中的线路连接。折线生成器以每个折线顶点上的离散分布 p(Vpolyi |Ai, li,Ff BEV) 运行,以初始布局(即元素关键点 Ai 和类标签 li)和 BEV 特征为条件。为了估计该分布,我们将每个折线 Vpoly i 上的联合分布分解为一系列条件顶点坐标分布的乘积。具体而言,我们将每个折线 Vpolyi = {vi,n ∈R2|n = 1, …,Nv} 转换为扁平序列 {vf i,n ∈R|n = 1, … …,2Nv} 通过连接折线顶点的坐标值并在每个序列的末尾添加一个额外的序列结束标记(EOS),目标分布变为: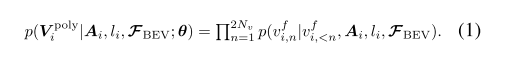
遵循 PolyGen (Nash et al., 2020) 的方法,我们使用分类分布来建模给定前一个顶点位置的每个顶点位置的概率。这使我们能够在保持离散分布效率的同时,对地图元素复杂且不规则的形状进行建模。我们使用自回归网络对此分布进行建模,该网络在每一步输出下一个顶点坐标的预测分布参数。此预测分布定义在所有可能的离散顶点坐标值和状态方程 (EOS) 上。
顶点作为离散变量。使用离散分布来建模折线顶点具有表示任意形状的优势,例如,分类分布可以轻松表示各种折线,例如我们任务中常见的多峰、倾斜、峰状或长尾。因此,我们将坐标值量化为离散的 token,并用分类分布对每个 token 进行建模。我们还在附录 § D.2 中进行了一项简化研究,以探索其他选择。
架构。为了对折线的局部几何结构进行建模,我们选择的自回归网络是 Transformer (Vaswani et al., 2017)(见图 2 右下角)。Transformer 架构在条件序列生成任务中始终展现出卓越的性能,并且能够高效地捕捉地图数据中存在的顶点依赖关系。每条折线的关键点坐标和类标签都被标记化,并作为 Transformer 解码器的查询输入。然后,一系列顶点标记被迭代地输入到 Transformer 中,将 BEV 特征与交叉注意力机制相结合,并解码为折线顶点。需要注意的是,生成器可以并行生成所有折线。
顶点嵌入。遵循 PolyGen (Nash et al., 2020) 的方法,我们使用三个学习到的嵌入作为每个顶点 token 的嵌入:坐标嵌入,指示 token 代表 x 坐标还是 y 坐标;位置嵌入,表示 token 属于哪个顶点;值嵌入,表示 token 的量化坐标值。
3.5. Learning
我们通过最小化地图元素检测器损失和折线生成器损失的总和来训练我们的模型: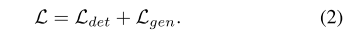
地图元素检测器损失。遵循 (Wang et al., 2022; Zhu et al., 2020) 的方法,检测器采用二分匹配损失进行训练,从而避免了非最大抑制 (NMS) 等后处理步骤。我们在附录 § C.4 中详细描述了地图元素检测器损失 Ldet 函数的细节。
Wang, Y., Guizilini, V. C., Zhang, T., Wang, Y., Zhao, H., and Solomon, J. Detr3d: 3d object detection from multiview images via 3d-to-2d queries. In Conference on Robot Learning, pp. 180–191. PMLR, 2022.
Zhu, X., Su, W., Lu, L., Li, B., Wang, X., and Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv preprint arXiv:2010.04159, 2020.
折线生成器损失。折线生成器经过训练,可以最大化折线顶点的对数概率。我们使用负对数似然作为其损失函数: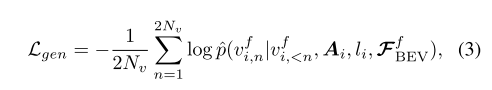
其中 p() 是离散坐标值 vf i,n 的条件概率,vf i,<n 是索引小于 n 的地面真实离散坐标值。默认训练策略是教师强制,这意味着我们使用地面真实关键点作为生成器输入。为了避免曝光偏差 (Bengio et al., 2015),我们进一步尝试先使用教师强制进行训练,然后再使用预测的关键点进行微调。
4. Experiments
实验方案。我们在 nuScenes (Caesar et al., 2020) 和 Argoverse2 (Wilson et al., 2021) 数据集上进行实验。效仿 HDMapNet (Li et al., 2021),我们通过将预测的高清地图的组成部分(即折线)与地面实况进行比较来评估其质量。HDMapNet 和本文均使用倒角距离 (Chamfer AP) 进行折线匹配。此外,我们还引入了另一种称为 Fr´echet 距离 (Fr´echet AP) 的距离度量,它通过考虑顶点的顺序来更好地测量折线之间的距离。Chamfer AP 和 Fr´echet AP 的定义和计算过程在§ A.2 中。此外,数据集设置(§ A.1)、实现(§ C)和其他定性结果(§ B)的详细信息也在附录中提供。
4.2. Qualitative Analysis
使用折线作为图元的优势。从可视化结果来看,我们发现使用折线作为图元与基线相比有两大优势:首先,折线能够有效地编码地图元素的几何细节,例如边界的拐角(参见图 4 中的红色椭圆)。其次,由于折线表示始终编码方向信息,因此可以防止 VectorMapNet 生成模糊的结果。相比之下,光栅化方法容易错误地生成环形曲线(参见图 4 中的蓝色椭圆)。这些模糊性会阻碍安全的自动驾驶。因此,折线是地图学习的理想图元,因为它能够反映现实世界的道路布局并明确地编码方向。
将地图学习作为检测问题的优势。VectorMapNet 采用自上而下的检测方式:它首先对地图的拓扑结构和地图元素的位置进行建模,然后生成这些元素的细节。可视化结果显示,VectorMapNet 能够全面捕捉所有地图元素,即使是边缘附近的较小元素也能捕捉到。与其他基线相比,VectorMapNet 的高 mAP 值验证了这一观察结果。我们将这些令人印象深刻的结果归功于该模型能够对地图元素之间的拓扑关系进行建模,从而隐式地捕捉复杂的场景相互关系。图 6 证明了这一点,其中模型识别出了数据集提供的高清地图注释中遗漏的交叉路口处的人行横道。虽然这些关系并非明确教授,但该模型通过使用自注意力模块(源自原始 Transformer 论文的技术)在查询嵌入之间进行受控信息传播来学习它们。这展示了该模型对场景的熟练理解。
VectorMapNet 的中心线预测。如上文 §3.1 及以上所述,折线是一种用途广泛的图元,能够表示超出高清语义地图元素范围的地图元素类别。为了进一步展示这种灵活性,我们扩展了 VectorMapNet 以预测中心线。中心线是一条虚拟的线,通常用作行车路线、车辆定位和导航的参考。这种扩展非常简单:VectorMapNet 将中心线视为一组折线,并隐式编码它们的拓扑关系。此过程无需修改模型结构。图 5 展示了 VectorMapNet 的中心线预测结果。
4.3. Ablation Studies
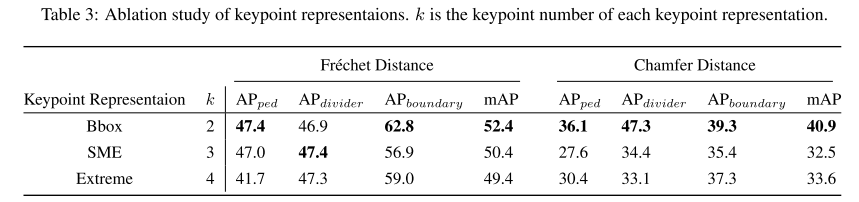
关键点表示。由于没有直接的关键点设计来用少量固定的点来表示地图元素,我们提出了三种简单的表示方法,如图 3 所示:边界框 (Bbox),它是包围折线的最小框,其关键点定义为框的右上角和左下角点;起点-中点-终点 (SME),从折线中采样起点、中间点和终点;极值点,是折线的最左点、最右点、最上点和最下点。我们对这些表示方法进行了实验,并将结果列于表 3 中。结果表明,边界框表示在两个指标中均能获得最佳平均性能,比其他表示方法高出 2.0 Fr´echet mAP 和 7.3 Chamfer mAP。
4.4. 使用 VectorMapNet 的矢量化高清地图进行运动预测
为了评估我们的方法理解场景关系的能力,并探究其在后续任务中的实用性,我们在运动预测任务中测试了我们预测的高清地图。这项任务高度依赖精确的地图信息来准确预测未来的运动。
任务设置。运动预测要求模型根据过去智能体的轨迹(1 秒)和 60 米×30 米的高清语义地图预测 6 条可能的未来轨迹(3 秒)。数据来自 nuScenes 追踪数据集,选取具有完整 3 秒未来观测值的智能体。最终生成 25,645 个训练样本和 5,460 个测试样本。我们研究了三种输入场景:仅过去轨迹、结合真实高清地图的过去轨迹以及结合 VectorMapNet 预测地图的过去轨迹。我们利用 mmTransformer(Liu et al., 2021)进行运动预测,因为它既可以灵活地使用地图数据,也可以仅依赖过去轨迹。这有助于评估我们学习到的地图的质量。
结果。为了评估不同输入设置下运动预测的性能,我们报告了三个常用指标(Chang et al., 2019)的结果:最小平均位移误差 (minADE)、最小最终位移误差 (minFDE) 和缺失率 (MR)。为了获得结果,这些指标仅考虑了 6 条预测轨迹中的最佳轨迹。表 4 中的结果表明,与仅将过去轨迹作为输入的模型相比,VectorMapNet 预测的地图已编码环境信息,这对运动预测器有很大帮助。真实地图与预测地图之间的差距也不大,尤其是在 MR 方面(-0.2%)。我们认为未来的研究可以进一步缩小性能差距。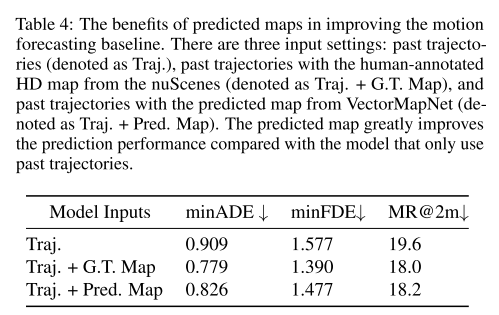
在VectorMapNet论文中,mmTransformer被用于运动预测(Motion Prediction)任务,具体是预测周围智能体(如车辆、行人等)的未来轨迹,而非直接预测自车轨迹或障碍物静态属性。以下是关键点解析:
mmTransformer的核心作用
- 任务目标:基于历史轨迹(1秒)和高清地图(HD Map)信息,预测智能体未来3秒内的6条多模态轨迹(即多种可能的运动模式)。
- 输入数据:
- 智能体的过去轨迹(动态信息)。
- 高清语义地图(静态环境信息,来自VectorMapNet预测或真实标注)。
- 输出:6条未来轨迹的概率分布及置信度,通过minADE/minFDE/MR指标评估。
与障碍物预测的区别
- 运动预测:关注动态智能体的未来轨迹,属于时序行为预测(如变道、转弯)。
- 障碍物预测:通常指静态或动态障碍物的存在性检测与定位,属于感知任务。
- mmTransformer在此任务中不直接检测障碍物,而是利用地图信息(如车道线、路缘)辅助轨迹预测,间接建模障碍物对智能体行为的影响。
VectorMapNet与mmTransformer的协同
- VectorMapNet:生成矢量化高清地图(如车道线、人行道),为运动预测提供结构化环境表示。
- mmTransformer:通过注意力机制融合地图与轨迹数据,建模智能体-地图交互(例如车辆是否会沿车道行驶或偏离),提升预测准确性。
- 实验对比:使用VectorMapNet预测的地图(而非真实地图)时,性能接近真实地图,证明其地图预测质量足以支持下游任务。
技术实现细节
- 多模态输出:mmTransformer通过堆叠Transformer层和基于区域的训练策略(RTS),生成覆盖不同运动模式的轨迹。
- 指标意义:
- minADE:最佳预测轨迹与真实轨迹的平均偏差。
- minFDE:最终位置的偏差。
- MR:预测轨迹未接近真实轨迹的比率。
在VectorMapNet的实验中,mmTransformer用于运动预测(预测周围智能体未来轨迹),而非障碍物检测。其通过融合VectorMapNet提供的矢量化地图信息,显著提升了预测精度,验证了预测地图的实用性。
5. 讨论
局限性。值得注意的是,该模型存在一些局限性,我们将留待后续研究。
- 缺乏时间信息:该模型在单帧中生成连贯的几何图形,但无法保证预测在时间上一致。
- 两阶段模型的不匹配问题:由于教师强制训练策略,地图元素检测器和折线生成器之间存在特征空间不匹配。虽然微调对于获得最佳性能至关重要,但这会导致训练计划的复杂性。
- 幻觉能力:该模型可以在被遮挡且摄像头无法看到的位置进行预测,展现了其场景理解能力。然而,这降低了模型的可解释性。有关进一步讨论,例如我们的方法的潜在社会影响,请参阅附录§E。
6. 结论
我们提出了 VectorMapNet,一个端到端模型来解决高清语义地图学习问题。与现有研究不同,VectorMapNet 使用折线作为基元来表示矢量化的高清地图元素。为了根据传感器数据预测折线,我们将问题分解为检测步骤和生成步骤。我们的实验表明,得益于折线基元,VectorMapNet 可以为城市地图元素生成连贯且复杂的几何图形。我们相信,这种新颖的高清地图学习方法为高清语义地图学习问题提供了新的视角。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)