多模态大模型驱动的三维视觉理解技术前沿进展
本文全面综述了多模态大模型在三维视觉理解领域的最新进展,涵盖三维视觉数据表示、多模态大模型的发展、三维视觉表征方法、多模态大模型驱动的三维视觉理解任务、机器人三维视觉应用以及相关数据集,旨在促进该领域的深入研究与广泛应用。
- 作者:冯明涛1^{1}1,沈军豪1^{1}1,武子杰2^{2}2,彭伟星2^{2}2,钟杭2^{2}2,郭裕兰3^{3}3,舒祥波4^{4}4,张辉2^{2}2,董伟生1^{1}1,王耀南2^{2}2
- 单位:1^{1}1西安电子科技大学,2^{2}2湖南大学,3^{3}3中山大学,4^{4}4南京理工大学
- 论文标题:多模态大模型驱动的三维视觉理解技术前沿进展
- 出版信息:中国图象图形学报,30(6):1744-1791
- 论文链接:https://www.cjig.cn/zh/article/doi/10.11834/jig.240588/
主要贡献
- 梳理多模态大模型为三维视觉表示学习提供的智能解决方案,介绍利用多模态大模型的力量来学习2D/3D视觉、文本等多模态数据的联合表示,使多模态大模型能够更有效地推理空间关系、三维对象属性和三维场景上下文。
- 系统调研多模态大模型驱动的三维视觉理解任务,深入总结多模态三维视觉理解的最新研究进展,涵盖近3年内的最新研究成果,具有较强的时效性,并根据下游任务进行分类,方便读者获取。
- 总结多模态三维视觉数据集,重点包含三维、文本和图像三个模态的数据集及涵盖的任务方向,为不同领域任务发展提供支撑。
- 对未来前景进行深刻讨论,在系统调研和综合性能比较的基础上,讨论未来研究方向,包括更高效的三维视觉表征、多模态大模型三维空间推理能力提升、机器人边端三维视觉任务场景下多模态大模型小型化和云边协同等。
引言
三维视觉理解的重要性
- 三维视觉感知和理解的广泛应用:三维视觉感知和理解在机器人导航、自动驾驶以及智能人机交互等众多领域具有广泛应用,是计算机视觉领域备受瞩目的研究方向。这些应用依赖于对三维空间环境的准确理解和感知,以实现自主决策和交互。
- 三维视觉领域的进展:近年来,三维视觉领域取得了重大进展,从对三维环境的主动/被动感知到高层次的语义理解和决策推理,涵盖了从低层次视觉任务到高层次认知任务的广泛研究。
多模态大模型的发展背景
- 大模型(LLM)的兴起:LLM的出现标志着自然语言处理的一个变革时代,使机器能够以前所未有的方式理解、生成和与人类语言交互。然而,LLM本质上对视觉“视而不见”,因为它们只能理解离散文本。
- 大型视觉模型(LVM)的发展:LVM具备精细化视觉信息的解析能力,但推理能力通常滞后。鉴于LLM和LVM的互补性,催生了多模态大模型的新领域,其基于LLM,具有接收、推理和输出多模态信息的能力。
- 多模态大模型的优势:多模态大模型在图像字幕、问题回答、开放词汇识别和图像生成等广泛的图像处理问题上显著提高了性能。这些模型通过聚合多元数据源,提供更准确、鲁棒的解决方案,尤其在处理复杂应用场景时表现出独特优势。
多模态大模型在三维视觉领域的应用前景
- 多模态大模型与三维视觉数据的融合:多模态大模型与三维视觉数据的融合为理解和与三维物理世界的交互提供了前所未有的能力,展现出独特优势,如上下文学习、逐步推理、开放词汇能力和丰富的世界知识。这种融合引领了三维视觉领域的创新,为多个子领域带来了新的机遇。
- 三维视觉领域的研究增长:随着多模态大模型的发展,三维视觉领域的研究论文数量稳步增长,表明该领域受到了越来越多的关注和研究投入。
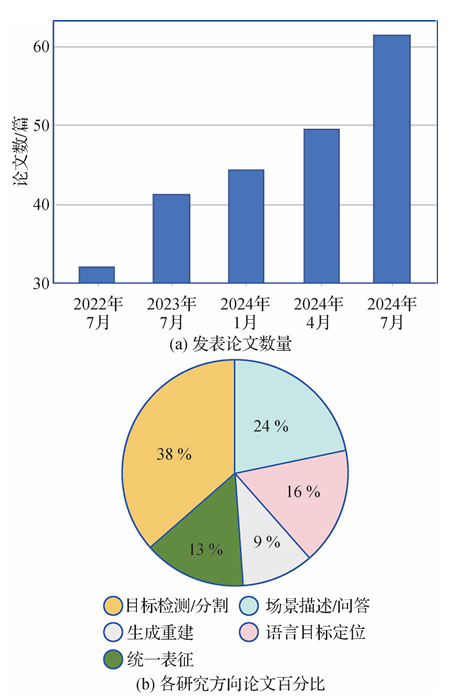
本文旨在全面综述多模态大模型在三维视觉理解领域的最新进展,系统梳理多模态大模型与三维视觉的交叉研究,为未来的研究绘制一条路线,探索和扩展多模态大模型在理解和与复杂三维世界的互动能力。
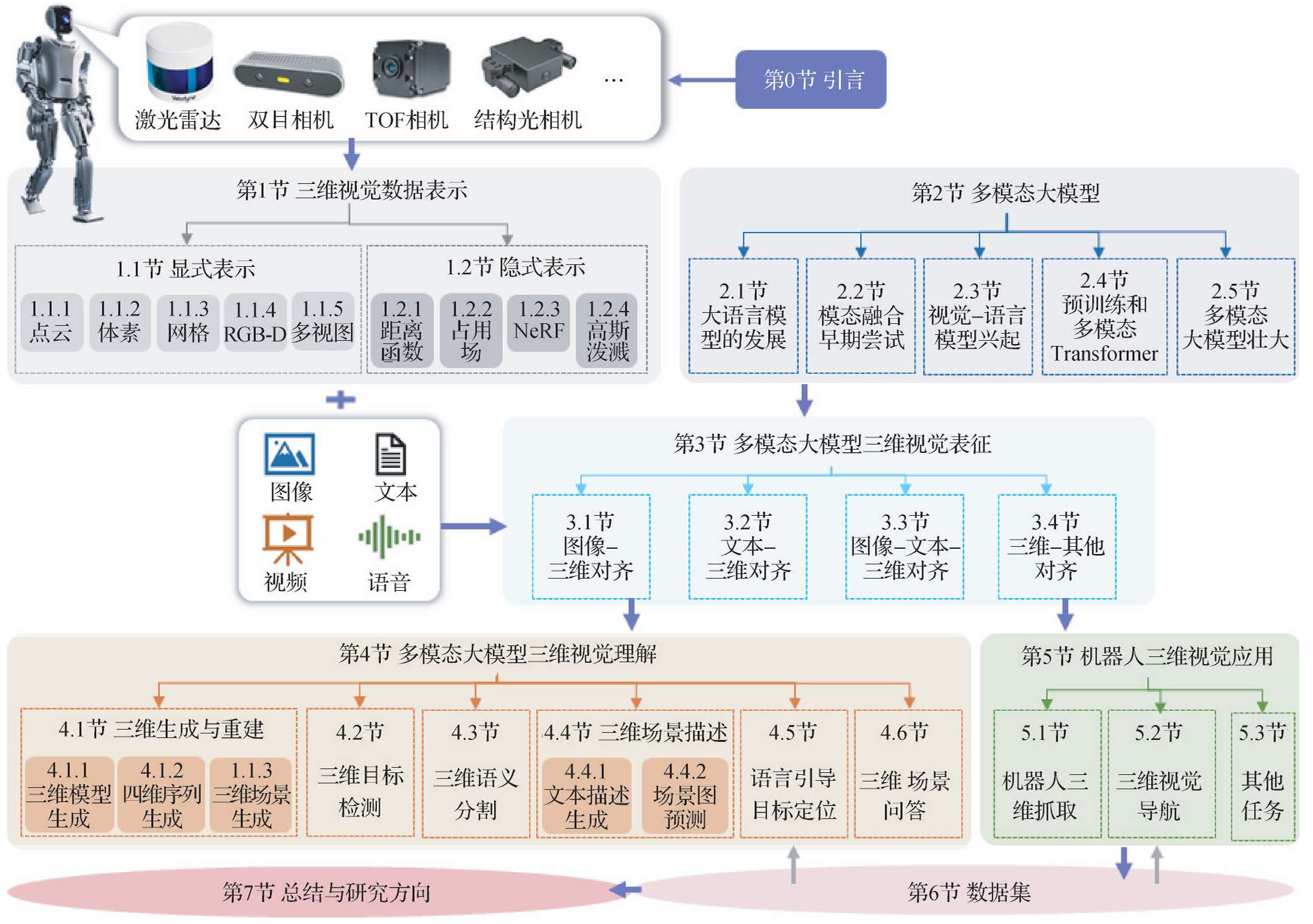
三维视觉数据的基本表示
显式表示
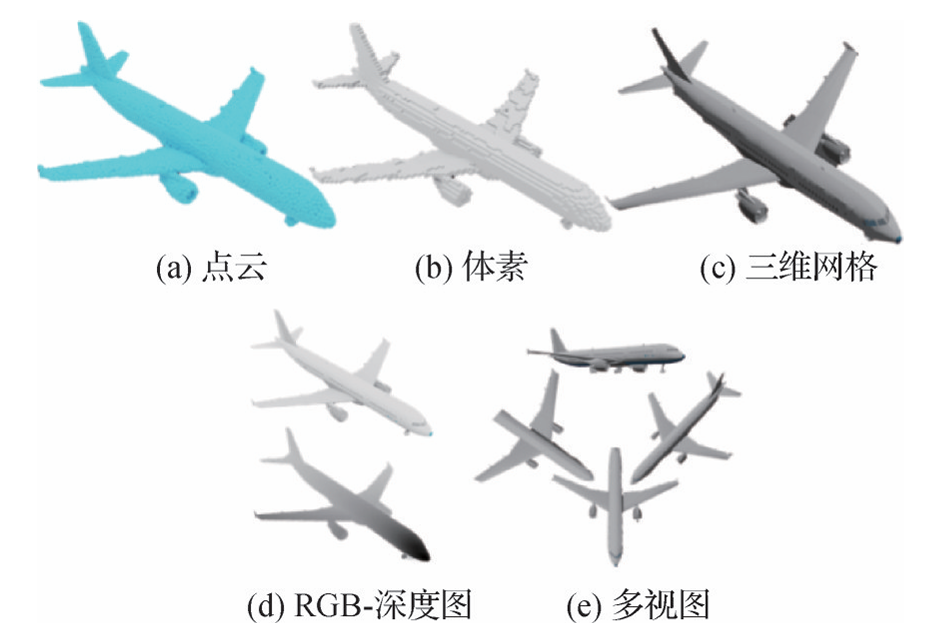
三维点云
- 定义与特点:点云是三维空间中大量离散点的集合,每个点包含三维空间坐标信息,还可以附加颜色、类别和强度等信息。点云具有无序性、稀疏性和不规则性等特点,这给深度学习中的特征提取带来了挑战。
- 获取方式:主要通过激光雷达(LiDAR)设备和RGB-D相机等深度传感器获取。激光雷达通过发射激光脉冲并测量反射时间来获取距离信息,RGB-D相机则利用结构光或飞行时间(ToF)技术同时捕获场景的颜色和深度信息。此外,ToF相机、结构光相机以及双目相机系统也可用于捕获点云数据。
- 处理方法:为了更好地处理点云数据,研究者们提出了一系列方法。例如,Qi等人提出的PointNet利用多层感知机和最大池化来学习点云特征并聚合全局信息;PointNet++进一步分层提取点云的局部上下文和整体特征。此外,还有针对点云旋转不变性的研究,如ACLSPC框架和RoITr架构,以及基于Transformer的点云Transformer(PCT)架构等。
体素
- 定义与特点:体素是三维空间中规则排列的立方体网格单元,类似于二维图像中的像素,用于表征和存储三维形状信息,如几何占用等。体素化可以将点云数据转换为规则的网格结构,便于处理和分析。
- 处理方法:Maturana和Scherer提出的VoxNet通过三种网格划分策略将点云转化为体素,并运用三维卷积提取特征以进行模型分类。3D ShapeNets和3D-R2N2等基于体素化的方法也取得了显著成果。然而,体素化可能导致分辨率和纹理信息的损失,因此研究者们引入了稀疏体素网格和动态体素网格优化等技术。PV-RCNN及其增强版PV-RCNN++结合了3D体素CNN和PointNet的优势,提升了目标检测的性能和效率。
三维网格
- 定义与特点:三维网格是由顶点、边和面构成的集合,以顶点相连的多边形作为基本单元。网格明确表达了表面点间的连接关系,便于点间关系建模,且表示方式紧凑。三维网格能够精确描述物体表面的细节,适用于高质量渲染、机器人抓取和交互等应用。
- 处理方法:MeshNet利用边面信息构建对称函数,并设计模块聚合面片信息。MeshCNN和MeshNet++通过定义网格边缘的卷积层和池化层直接处理网格数据。此外,还有将网格数据转换为点云、体素或图等其他类型的方法,如GMR-Net和3DGen等。
RGB-D数据
- 定义与特点:RGB-D图像是结合颜色与深度信息的结构化图像表示方式,每个像素包含红、绿、蓝三通道的颜色信息以及单通道的深度信息。RGB-D图像的生成得益于深度相机的发展,如Kinect等,通过结构光、ToF、LiDAR、立体相机系统或单目深度估计技术实现对场景深度信息的快速获取和处理。
- 处理方法:Xing等人提出使用HHA编码处理RGB-D数据,将深度信息转换为三通道编码。CANet通过共同注意力机制自适应融合颜色和深度特征,GLPNet引入局部与全局上下文融合模块实现深度与颜色信息的逐元融合。VirConvNet结合随机体素丢弃和抗噪声子流形卷积机制,高效融合RGB图像与LiDAR数据。Zheng和Gao提出双分支RGB-D图像压缩框架,利用YUV域采样与模态内外注意力机制消除冗余,实现率失真优化。
多视图几何
- 定义与特点:多视图几何从不同视点将3D对象渲染为2D图像,并使用2D卷积处理。这些视图数据可通过传统相机或模拟人眼视觉的双目相机采集,每个视图都表示特定视角下的二维特征。多视图几何不依赖复杂的三维特征,且视图数据丰富,能有效利用先进网络架构。
- 处理方法:Su等人提出的多视图卷积神经网络(MVCNN)开创了三维模型多视图卷积神经网络,通过多视角投影生成视图,并采用最大池化融合特征。Yu等人提出聚合局部卷积特征的MHBN,Han等人提出利用注意力机制提取全局特征的3DViewGraph。Xie等人推出的X-View通过平移原点模拟不同视角,突破视角约束。Hong等人提出从多视角图像学习三维概念并进行推理的方法,使用神经场学习紧凑表示,并将其绑定到3D空间,通过神经推理运算符进行可视化推理。
隐式表示
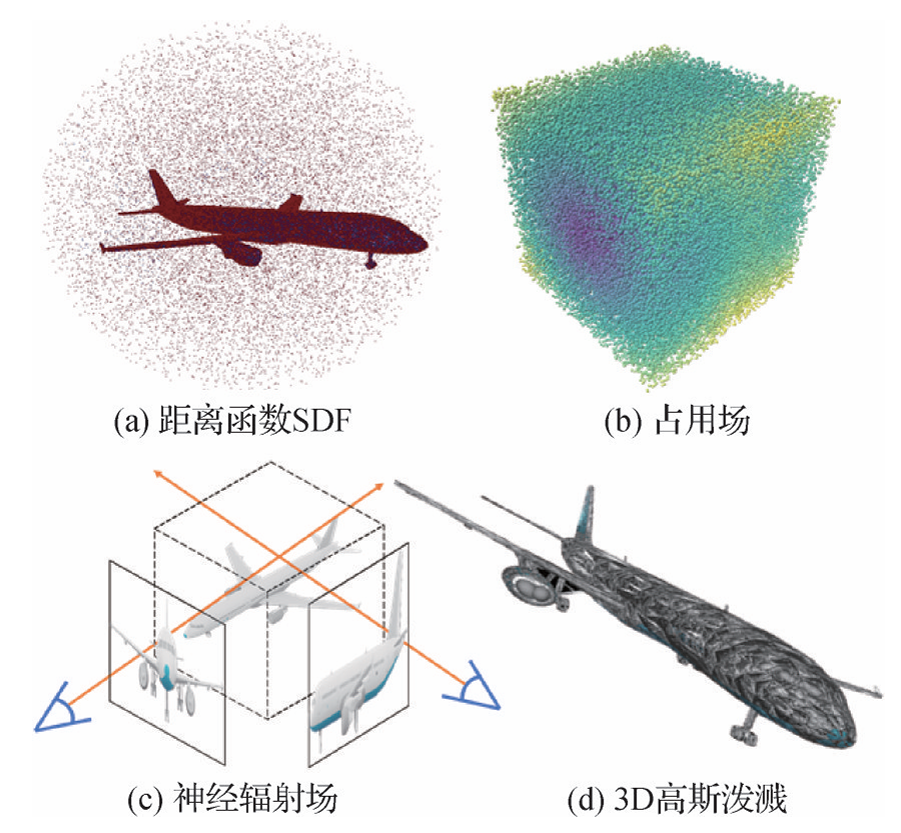
距离函数
- 定义与特点:距离函数(Signed Distance Field, SDF)是一种表征三维空间点与最近表面点间距的水平集表示法,分为有符号和无符号两种形式。有符号距离函数通过存储带符号的距离值来区分内外结构,擅于构建连续密闭表面,并常使用均匀体素网格实现离散化表示,进而能够描绘任意拓扑结构。
- 处理方法:Park等人提出利用自编码器学习的DeepSDF,Mittal等人推出以VQ-VAE编码的AutoSDF。Chou等人介绍的Diffusion-SDF将符号距离函数用于三维形状表征,并通过坐标多层感知机(MLP)隐式编码物体表面。Long等人提出的NeuralUDF将无符号距离函数融入体积渲染,基于密度函数处理任意拓扑结构。NeUDF进一步优化了渲染权重函数和采样策略,并解决表面方向模糊问题,仅凭多视角监督即可重建复杂表面。
占用场
- 定义与特点:占用场是一种概率模型,用于描述三维空间中物体的分布。它通过记录每个点被曲面占用的概率来呈现物体分布,在处理不确定性和噪声方面具有鲜明优势。此外,占用场还能处理来自多种传感器的数据融合问题。
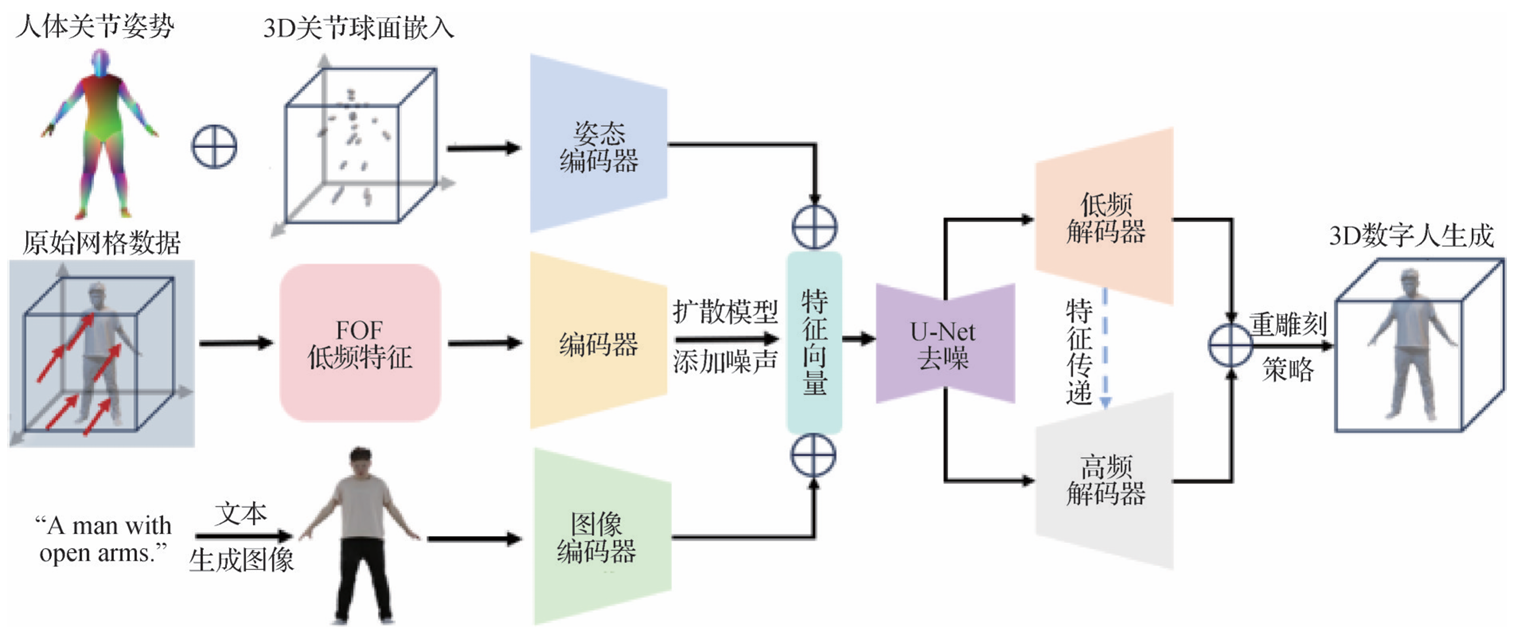
- 处理方法:Mescheder等人提出占用网络概念,利用神经网络对连续的占用函数进行预测,以此编码物体的形状信息。Peng等人提出集成局部信息以预测占用概率的卷积占用网络,增强模型处理复杂几何形状的能力。Chatzipantazis等人提出的TFONet模型引入基于SE(3)群的等变性注意力机制,提升模型处理3D形状的效率和准确性。OccFormer通过创新编码和注意力机制的应用,显著提高了静态及动态物体表面重建的保真度与效率。FOF通过傅里叶级数将3D占用场分解为2D向量场,保留3D拓扑和空间关系,并整合人体参数模型作为先验知识,扩展为FOF-X,避免了由纹理和光照引起的性能下降。
神经辐射场
- 定义与特点:神经辐射场(Neural Radiance Fields, NeRF)是一种利用多层感知机进行视图合成和三维隐式空间建模的技术。在NeRF中,每个输入对应一个五维坐标,输出是该坐标的密度和幅度值。NeRF能够生成高质量的三维场景渲染,尤其在新视角合成方面表现出色。
- 处理方法:Zhang等人提出NeRF++,解决了形状—辐射模糊性、近场模糊性和无界场景参数化问题。Yu等人提出的PixelNeRF从少量图像合成三维场景,Lin等人提出基于NeRF的视觉变换器(Vision Transformer, ViT),减少对大量输入图像的依赖。MipNeRF改进了NeRF的多尺度处理能力,Latent-NeRF结合扩散模型指导三维物体生成。此外,还有大量工作研究如何提升NeRF的视图质量和渲染效率。
高斯泼溅
- 定义与特点:3D高斯泼溅(3D Gaussian Splatting)是一种基于辐射场的场景表示方法,采用各向异性的三维球体和三维高斯分布建模辐射场。这种方法的表征能力和建模效率优异,但通常需要数百万参数且占用大量内存。
- 处理方法:Lu等人提出受网格NeRF启发的内存高效模型Scaffold-GS。Navaneet等人通过向量量化压缩参数,减少存储空间并提高渲染质量。Chung等人引入深度正则化和无监督几何平滑性约束,解决样本稀疏问题。Zhu等人提出的FSGS方法通过扩展运动结构恢复(Structure from Motion, SFM)初始化的三维高斯分布来逐步填充场景。此外,还有研究致力于将3D高斯泼溅从静态场景扩展到四维(4D)场景,以处理动态场景的建模和渲染。
多模态大模型
大语言模型的发展
早期语言模型
- 基于规则的方法:早期的语言模型主要依赖于基于规则的方法,如Bar-Hillel等(1960)的研究。然而,这些方法在处理语言的复杂性和多样性方面逐渐暴露出局限性。
- 统计模型:随后,统计模型成为主流,如Brown等(1992)提出的N-gram模型和Fine等(1998)的隐马尔可夫模型。这些模型在文本预测和生成方面表现出色。
- 循环神经网络(RNN):进入21世纪,随着计算能力和算法的进步,研究者开始开发能够捕捉序列数据长期依赖关系的模型,如Schuster和Paliwal(1997)提出的循环神经网络(RNN)及其变种长短期记忆网络(LSTM)(Hochreiter和Schmidhuber,1997),有效解决了传统RNN在处理长序列时的梯度消失问题。
- 词嵌入技术:词嵌入技术如Word2Vec(Mikolov等,2013)的发展,使得机器能够以向量形式高效地表示词语,显著增强了模型对语义的理解能力。
Transformer架构与大语言模型
- Transformer架构:2017年,Vaswani等提出了Transformer架构,其独特的自注意力机制极大提高了处理自然语言任务的效率,使模型能高效处理大规模数据。
- 大语言模型(LLM):大语言模型是一类基于Transformer架构的语言模型,其参数规模通常达到数十亿甚至数百亿。LLM采用自注意力机制来捕捉输入序列中的长程依赖关系,并引入了位置编码、解码器和编码器技术。例如,GPT-3(Brown等,2020)、LLaMA(Touvron等,2023)和GPT-4(OpenAI,2024)等模型以卓越的性能持续推动自然语言处理领域的前沿发展。
- LLM的涌现能力:LLM的一个显著特征是其涌现能力,这是随着语言模型规模和复杂性的增加而出现的新能力,如上下文学习(Brown等,2020)、指令跟随(Ouyang等,2022)和思维链推理(Wei等,2022)。这些能力在自然语言处理领域已有广泛研究。
模态融合的早期尝试
- 多模态数据的重要性:单一模态数据因其信息维度有限,通常仅限于处理特定任务,尤其面对复杂的应用场景时表现不足。多模态学习通过聚合多元数据源,能提供更准确、鲁棒的解决方案。
- 早期融合方法:模态融合的早期工作可以追溯到1970年代提出的典型相关分析(CCA)、平行因子分解(PARAFAC)以及其他张量分解方法。Slaney和Thiébaux(2001)提出根据文本指令重排彩色积木块的积木世界问题,尽管它并非基于深度学习技术,但这一早期尝试将视觉与语言结合,标志着视觉语言模型的启蒙。
视觉—语言模型的兴起
- 视觉与语言模态的结合:近年来,随着CNN和RNN等深度学习技术的发展,多模态模型研究领域取得了一系列突破性进展,推动了视觉—语言任务处理方式的根本性变革。视觉理解与生成任务的处理主要采用早期融合和晚期融合两种策略。
- 晚期融合:晚期融合利用联合嵌入技术,将不同的模态数据嵌入至一个共享的语义空间,然后测算其相似度,以促进跨模态的学习和理解。例如,Mao等(2015)、Antol等(2015)和Vinyals等(2015)的工作。
- 早期融合:早期融合策略则是在模型早期阶段将各种模态特征结合,并直接基于融合后的特征表示进行相似性分数预测。例如,Yu等(2017)、Wang等(2019)和Xu等(2019)的工作。
- 视觉语言模型(VLM):视觉语言模型的核心优势在于通过学习图像和文本之间的对应关系来捕获更丰富的语义信息。通过多模态特征提取与融合、跨模态对比学习和多任务学习等方式,VLM在图像字幕生成、视觉问答(VQA)以及图像检索等领域展现出卓越能力。
预训练和多模态Transformer
- 预训练方法:随着多模态模型领域的不断演进,预训练方法已成为一种重要的研究趋势。此方法首先在大规模数据集上预训练多模态模型,然后针对特定任务进行微调,已在多个应用领域证明了其提升模型性能的有效性。
- 预训练模型的发展:
- CLIP:Radford等人(2021)提出对比语言—图像预训练模型(CLIP),其由两个核心组件构成:视觉编码器和文本编码器。CLIP最大化给定图像的特征向量与相应的文本描述的特征向量之间的相似度来训练模型,并在推理阶段实现零样本迁移性。
- BEiT:Bao等人(2022)受BERT模型的启发,提出BEiT,一个以掩码图像模型为预训练任务的生成式自监督预训练大模型。
- SimVLM:Wang等人(2022b)提出SimVLM,该模型采用大规模弱监督和单一的前缀语言建模目标进行端到端训练,证明了简洁的预训练框架也能高效处理视觉语言数据。
- Flamingo:Alayrac等人(2022)推出Flamingo,它结合了两个互补的预训练模型,并引入新的结构组件以链接这些模型在预训练期间积累的知识,从而实现跨任务的零样本或少样本迁移。
- CoCa:Yu等人(2022a)提出CoCa,通过模块训练模型,采用对比损失和描述损失进行训练。
- 多模态Transformer:受BERT等预训练NLP模型的启发,研究人员进一步开发了能够处理文本、图像、音频和点云等多模态输入的Transformers模型(Zhan等,2024;Wang等,2024d;Li等,2024e)。
多模态大模型的壮大
- 多模态大语言模型(MLLM):多模态预训练领域的研究已取得显著进展,整体发展流程如图5所示,这些模型持续不断地突破下游任务的性能界限。MLLM已成为一个重要的研究领域,其经典框架如图6所示。
- 输入数据处理:输入的多模态数据首先通过模态编码器编码成统一的模态特征,然后经过特征投影、查询和融合转换器处理,将模态特征转换为适配LLM输入的形式,并将其和文本特征送入LLM进行语义理解和信息处理。
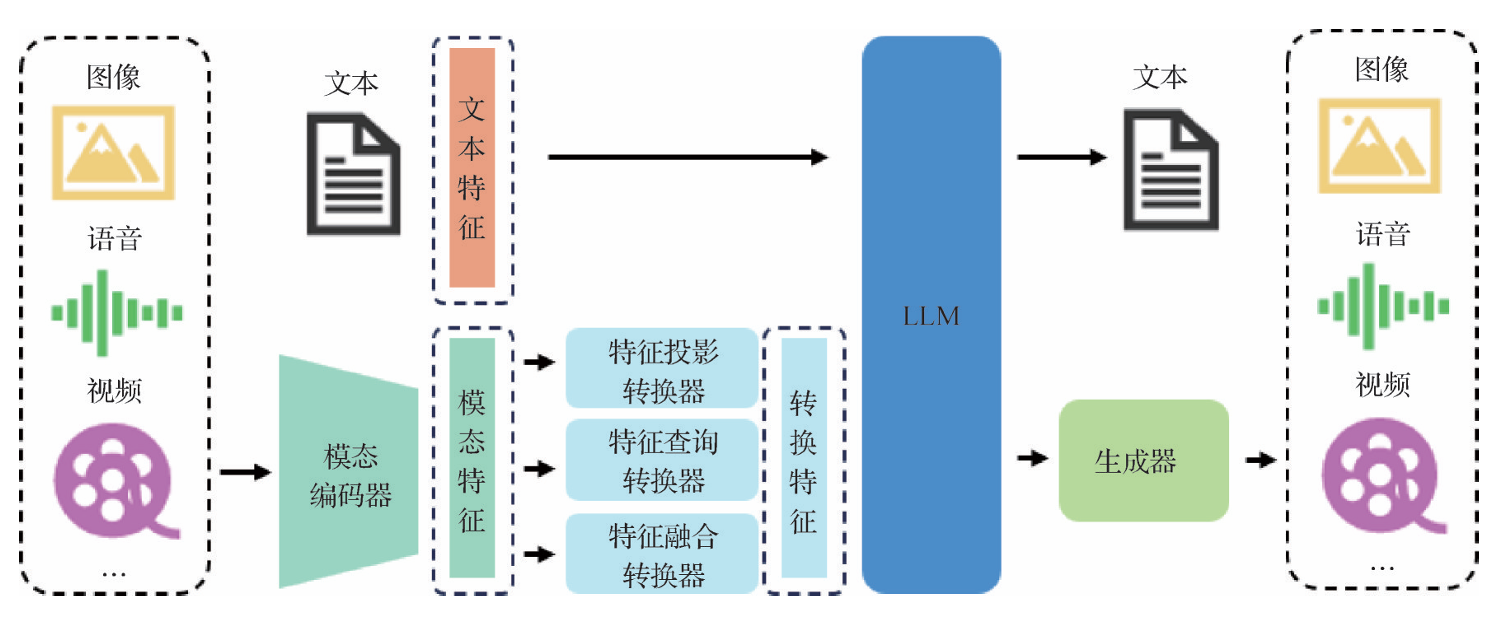
- 输出与应用:最终,LLM生成文本及利用生成器获得所需的多模态内容。例如,OpenAI提出的ChatGPT和GPT-4系列模型,通过融合多模态数据和LLM的能力来执行跨越多种模态的任务。GPT-4V和Gemini展示了令人印象深刻的多模态理解和生成能力,激发了众多学者对MLLM的研究热情。
- 多模态内容理解与文本生成:MLLM的研究主要集中在多模态内容理解与文本生成,包括图像文本理解生成(Li等,2023a;Zhu等,2023b;Koh等,2023)、视频文本理解生成(Rubenstein等,2023)、音频文本理解生成(Chu等,2023)以及三维数据文本理解(Hong等,2023c;Li等,2024e)。
- 多模态模型的创新应用:许多研究团队通过将LLM与外部工具结合,实现了接近于任意模态输入、输出的MLLM(Shen等,2023;Zhan等,2024)。同时,为了减少级联系统中错误传播的问题,CoDi-2(Tang等,2023b)和ModaVerse(Wang等,2024d)等模型开发了端到端的解决方案,关键技术和应用主要为多模态指令微调(Zhu等,2023b;Liu等,2023a)、多模态上下文学习(Yang等,2023d;Lu等,2023a)、多模态思维链(Ge等,2023;Stechly等,2024)以及LLM辅助的视觉推理(Shen等,2023;Lu等,2023a)。
多模态大模型三维视觉表征
三维模型—图像对齐表征
- PointCLIP:Zhang等人(2022b)提出PointCLIP,首先对点云进行编码,将点云投影到多视图深度图中,端到端聚合多视图,利用CLIP进行零样本三维模型分类。
- PointCLIP V2:Zhu等人(2023c)提出PointCLIP V2,通过形状投影模块生成更逼真的深度图,缩小投影点云与自然图像之间的域差距。
- CrossPoint:Afham等人(2022)利用跨模态对比学习方法,在3D点云和2D图像间进行对比学习,减小特征空间中两种模态特征的距离。
- CLIP2Point:Huang等人(2023c)引入新的深度渲染方法将点云渲染为更易对齐的RGB图像和深度图像,整合跨模态学习以增强深度特征,并采用内模态学习来提高深度聚合的不变性。
- CLIP-FO3D:Zhang等人(2023a)尝试改变投影方向,将多视图图像特征投影到点云上,并使用特征蒸馏训练3D模型,直接将CLIP的视觉特征空间转移到3D数据中,不需要任何形式的监督。
- EPCL:Huang等人(2024e)提出高效的点云学习器,用于直接训练高质量的点云模型,通过在语义上对齐图像特征和点云特征来连接2D和3D模式,而无需配对的2D-3D数据。
- MvNet:Peng等人(2024)提出一种新的多视图视觉融合网络,将3D点云编码为多个不同视图的图像特征,并开发多视图提示融合模块,弥合了三维点云数据与二维预训练模型之间的差距。
- LidarCLIP:Hess等人(2024)介绍LidarCLIP,使用图像—激光雷达对,监督具有图像CLIP嵌入的点云编码器,有效地将文本和激光雷达数据以图像域为中介相关联。
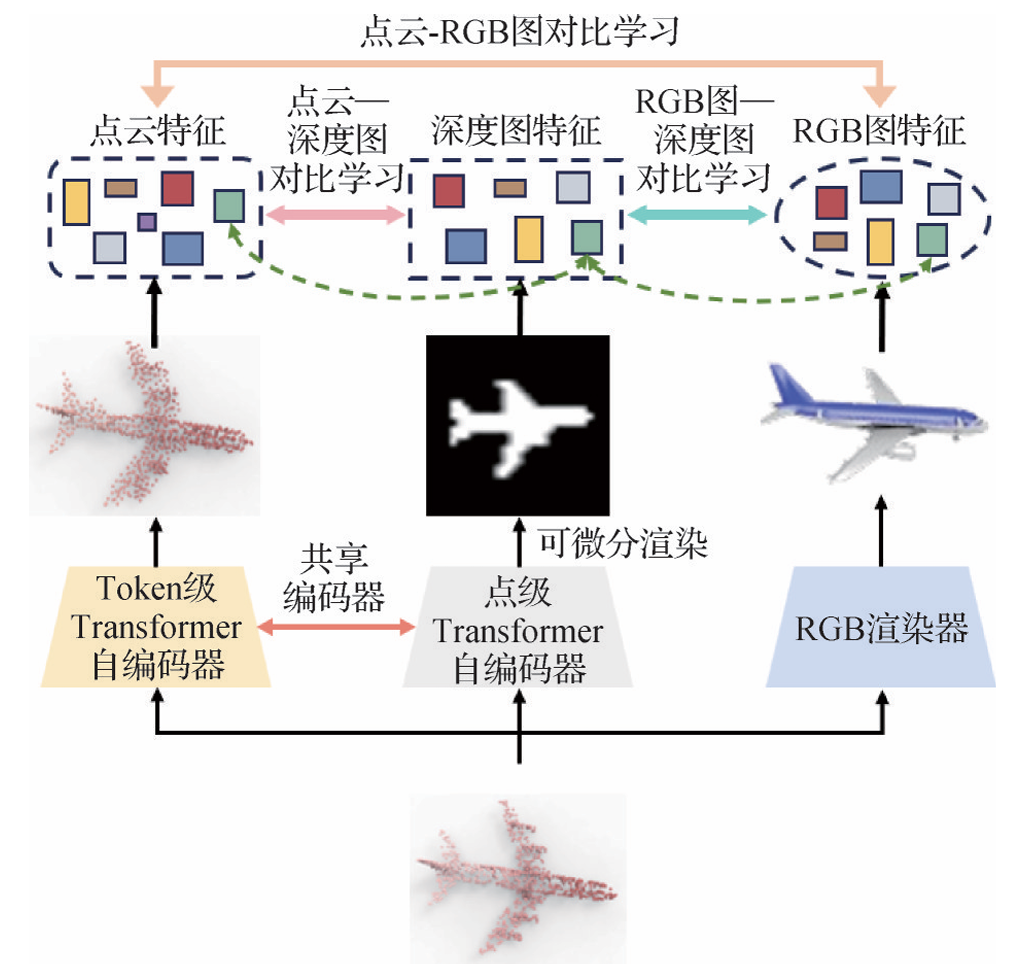
- ULIP-2:Fei等人(2024a)提出ULIP-2,输入点云数据,利用Token级Transformer自编码器,经过Token级掩码重建任务来获取离散Token,进而提取点云特征。同时,初始点云也输入与Token级共享模态表征的点级Transformer自编码器,经过点级掩码重建任务和可微分渲染技术,生成深度图并提取特征。最后,通过3种模态特征间的对比学习训练,实现了点云、RGB图和深度图的无缝对齐。
三维模型—文本语言对齐表征
- Point-BERT:Yu等人(2022b)提出Point-BERT,利用点云—文本预训练模型对齐点云和文本模态。
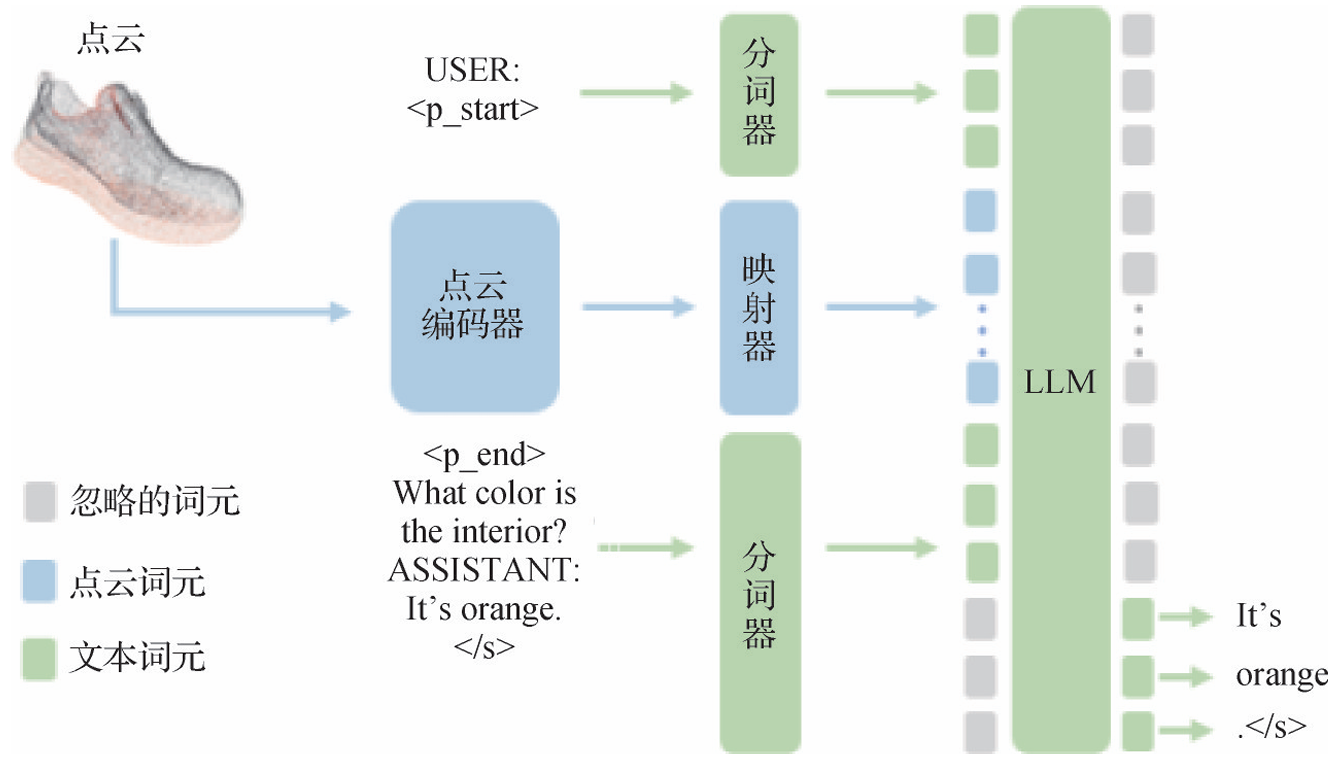
- PointLLM:Xu等人(2024b)提出PointLLM,将点云数据和用户提出的文本问题通过分词器被编码为文本词元,然后共同输入映射器,映射器将词元转换为嵌入向量,送入LLM的特征空间,经由LLM处理以生成相应的文本输出。
- Text4Point:Huang等人(2024d)提出Text4Point,采用二维图像作为跨模态融合的桥梁,通过对比学习在预训练阶段建立图像与点云的对应关系,并借助CLIP实现点云特征与文本嵌入的隐式对齐。
- ShapeLLM:Qi等人(2024b)基于多视图图像蒸馏,设计并改进了3D编码器,增强几何形状的理解,在3D几何理解和语言统一的3D交互任务方面实现了最先进的性能。
- Uni3DL:Li等人(2023e)提出Uni3DL,不依赖于多视图图像投影,设计了一个查询转换器用来学习与任务无关的语义,并基于3D视觉特征来屏蔽输出。
- GPT4Point:Qi等人(2023)构建了超过1M个带注释样本的大型数据集,并提出GPT4Point模型,经此数据集训练,利用低质量的点—文本特征生成高质量的3D对象,同时保持几何形状和颜色的准确性。
- MiniGPT-3D:Tang等人(2024)提出MiniGPT-3D,仅需一台RTX 3090训练27h即可实现多个SOTA结果。MiniGPT-3D使用2D LLM的2D先验将3D点云与LLM对齐,利用2D和3D视觉信息之间的相似性,设计一种新的四阶段训练策略。
三维模型—图像—文本对齐表征
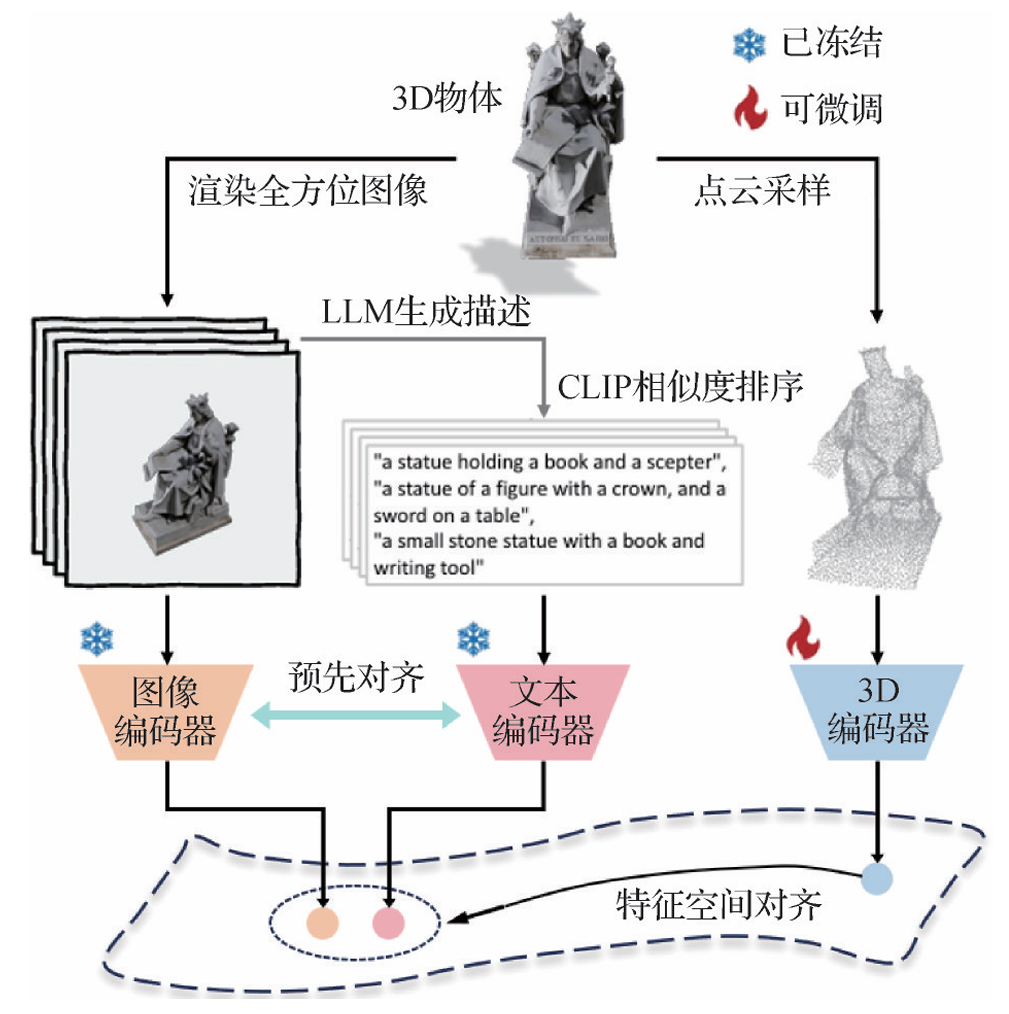
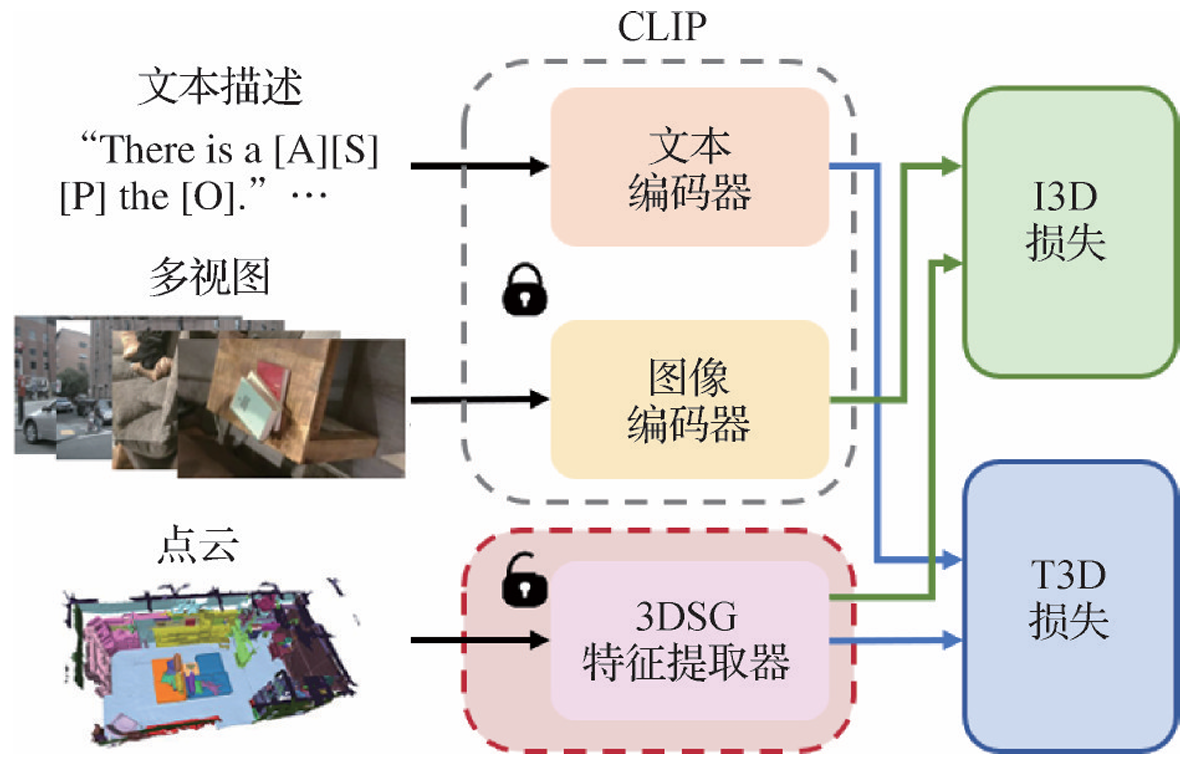
- ULIP:Xue等人(2023)提出ULIP,构建了包含3D点云、2D图像和自然语言描述的对象三元组,通过利用有限的自动合成三元组,学习与图像—文本空间对齐的3D表征空间,进行多模态预训练。
- ULIP-2:Xue等人(2024)改进了ULIP对数据集元数据和类别名称的依赖性,提出简单而有效的三模态预训练框架ULIP-2。该框架通过从3D物体表面采样点云作为3D编码器输入,同时从多个视角渲染3D物体生成全方位图像,随后输入图像编码器来提取视觉特征。框架使用BLIP-2为每幅渲染图像自动生成描述性文本。为确保文本与视觉的特征匹配,还需CLIP对文本描述进行相似度排序。而在预对齐且冻结的视觉—语言特征空间,框架进一步对齐从3D编码器输出的点云特征,进而实现图像、文本和点云3种模态的一致性对齐。
- CG3D:Hegde等人(2023)提出CG3D,一个基于对比损失的预训练框架。CG3D的训练数据源于ULIP,并进一步引入提示调整技术,将预训练视觉编码器的输入空间从计算机辅助设计(CAD)对象的渲染图像转移到自然图像,从而有效利用CLIP处理3D形状。
- OpenShape:Liu等人(2023b)提出OpenShape,采用多模态对比学习框架用于学习文本、图像和点云的多模态联合表示。OpenShape的多模态嵌入通过编码丰富的视觉和语义信息,实现了细粒度的文本到3D、图像到3D交互。
- TAMM:Zhang等人(2024h)提出TAMM,基于3个协同适配器的新型两阶段学习方法,以减少三模态表示学习过程中由于二维图像的域移位和每个模态的不同焦点带来的影响。CLIP图像适配器减轻了3D渲染图像和自然图像之间的域差距,双适配器将三维形状表示空间解耦为专注视觉属性和语义理解的两个互补的子空间,确保了全面有效的多模态预训练。
- JM3D:Ji等人(2024)提出集成点云、文本和图像的综合方法JM3D。主要贡献包括结构化多模态组织器,通过多视图图像序列和分层文本树,增强视觉和语言模态的独立表示;联合多模态对齐,将语言理解与视觉表示相结合;通过高效的微调,将3D表示与LLM相结合,形成JM3D-LLM模型,在零样本3D分类和图像检索任务中取得出色成果。
三维模型—其他表征
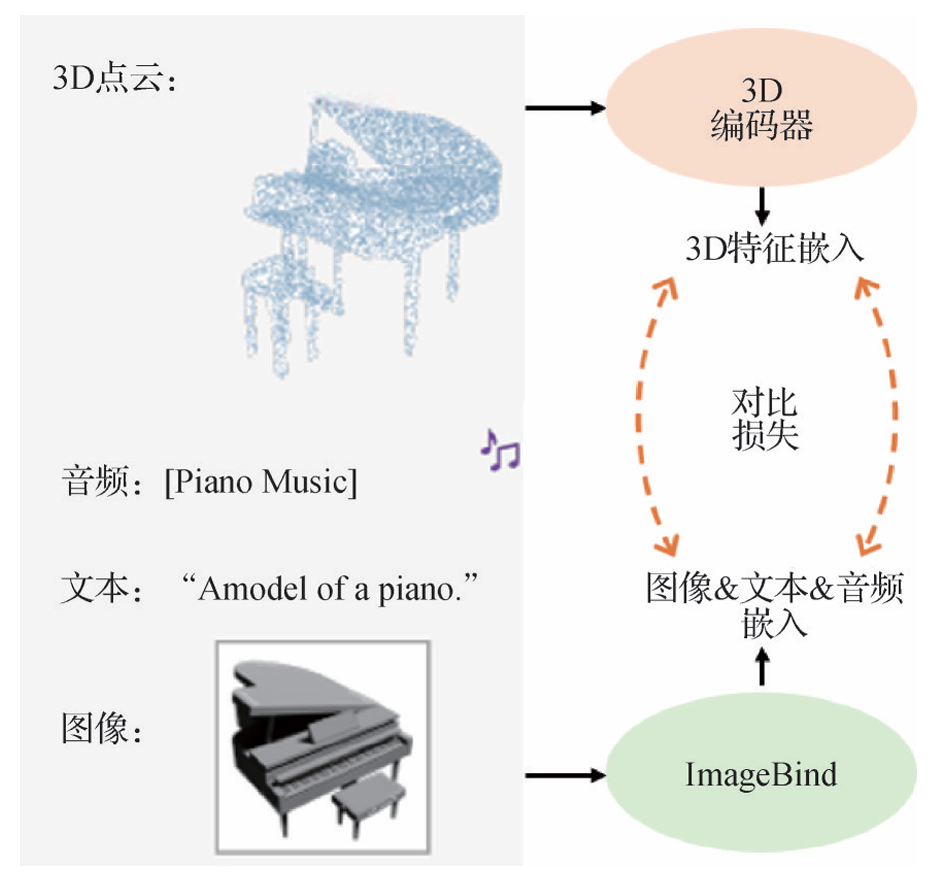
- Point-Bind:Guo等人(2023b)提出Point-Bind,实现了点云、图像、文本、音频和视频5种模态的特征融合。3D编码器首先将3D点云编码为3D特征嵌入,同时,音频、文本和图像模态数据通过Image-Bind处理并嵌入到一个联合的特征空间。这些嵌入在特征空间通过对比损失函数与3D特征对齐,以提升3D视觉任务中的跨模态交互和精确理解。Point-LLM采用参数高效的微调技术,将Point-Bind捕获的3D语义注入预训练的LLM中。
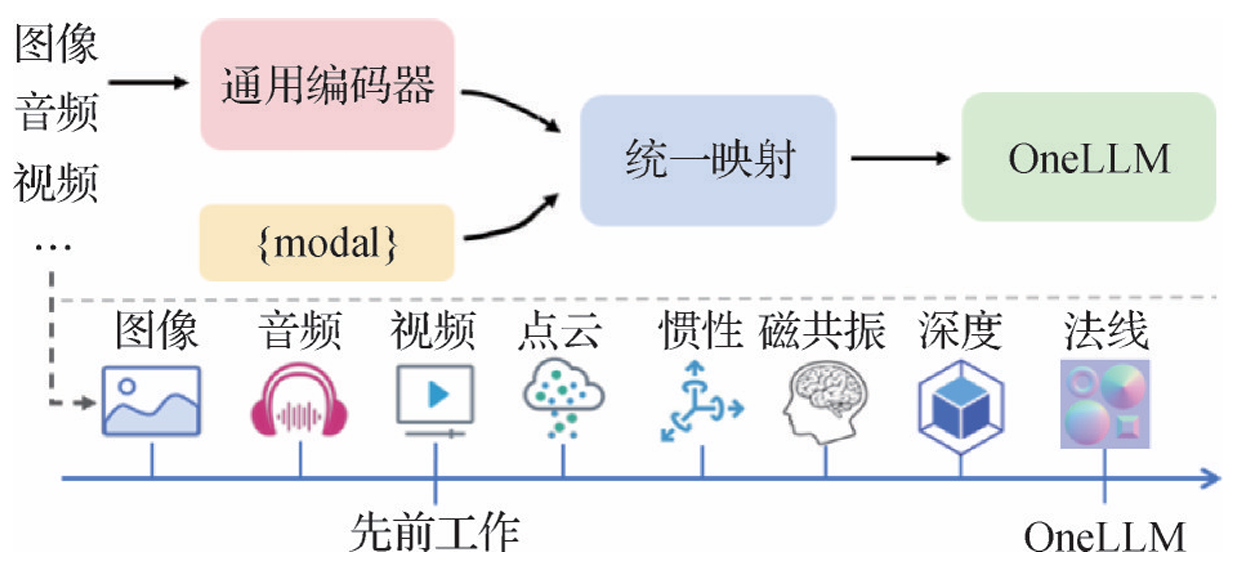
- OneLLM:Han等人(2024b)提出OneLLM,一个统一的多模态编码器和渐进式多模态对齐策略。图像、音频和视频等8种不同模态数据通过通用编码器被转换为token序列,并利用可学习的模态切换器将不同长度的多模态输入token转化为固定长度。这些token随后被输入通用投影模块进行统一映射,最终输入LLM以实现多模态理解。
多模态大模型三维视觉理解
三维视觉生成与重建
三维模型生成
- ShapeGPT:Yin等人(2023)提出ShapeGPT,通过形状特定的3D VQ-VAE将三维形状离散化为token,使得形状数据能与文本和图像共同构成多模态输入框架。
- GPT4Point:Qi等人(2023)采用双流框架,通过Point-QFormer将点云几何特征与文本对齐,并输入到耦合的LLM和扩散路径。
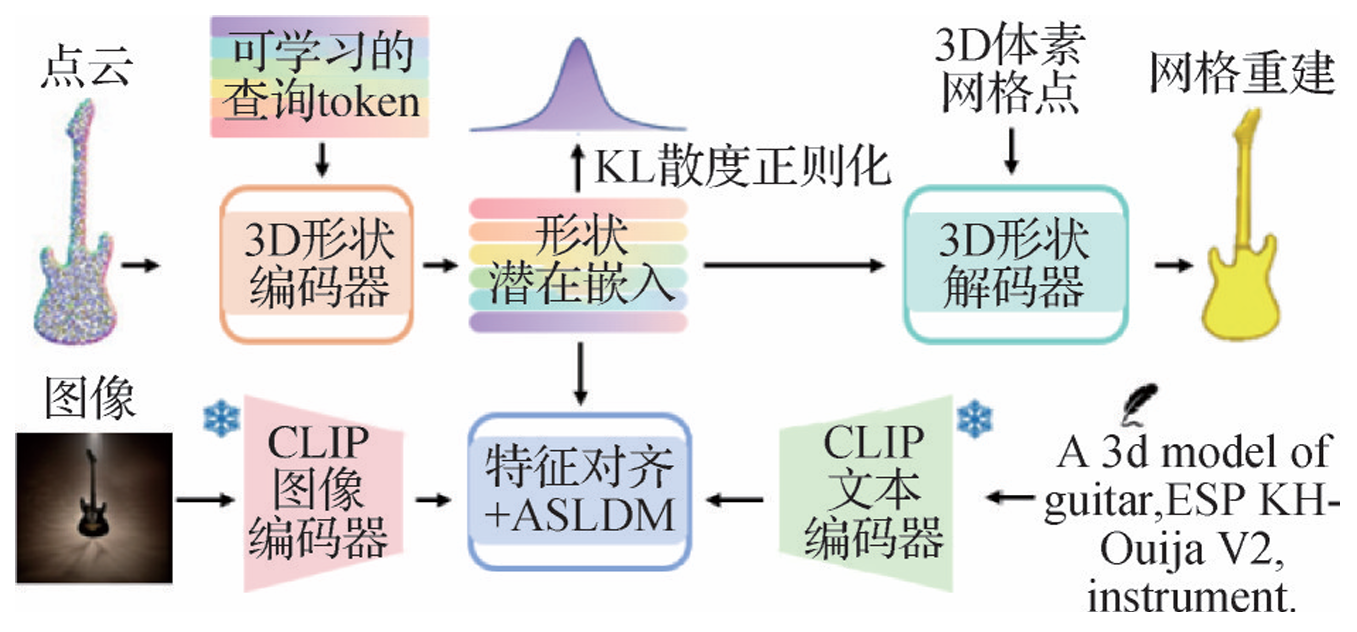
- Michelangelo:Zhao等人(2024)提出Michelangelo,包含形状图像文本对齐变分自编码器(SITA-VAE)和对齐形状潜在扩散模型(ASLDM)。通过这种方式,3种模态特征在形状潜在空间对齐,并基于KL散度正则化进行优化。
- Dream3D:Xu等人(2023b)将3D形状先验引入文本到图像扩散模型,强化了以文本为导向的3D重建。
- HyperSDFusion:Leng等人(2024)使用双分支扩散模型,引入双曲文本—图像编码器来学习双曲空间中的文本顺序和多模态层次特征。
- Direct2.5:Lu等人(2024)通过微调预训练的2D扩散模型构建2.5D扩散模型,填补了2D与3D扩散内容生成方法之间的空白。
四维序列生成
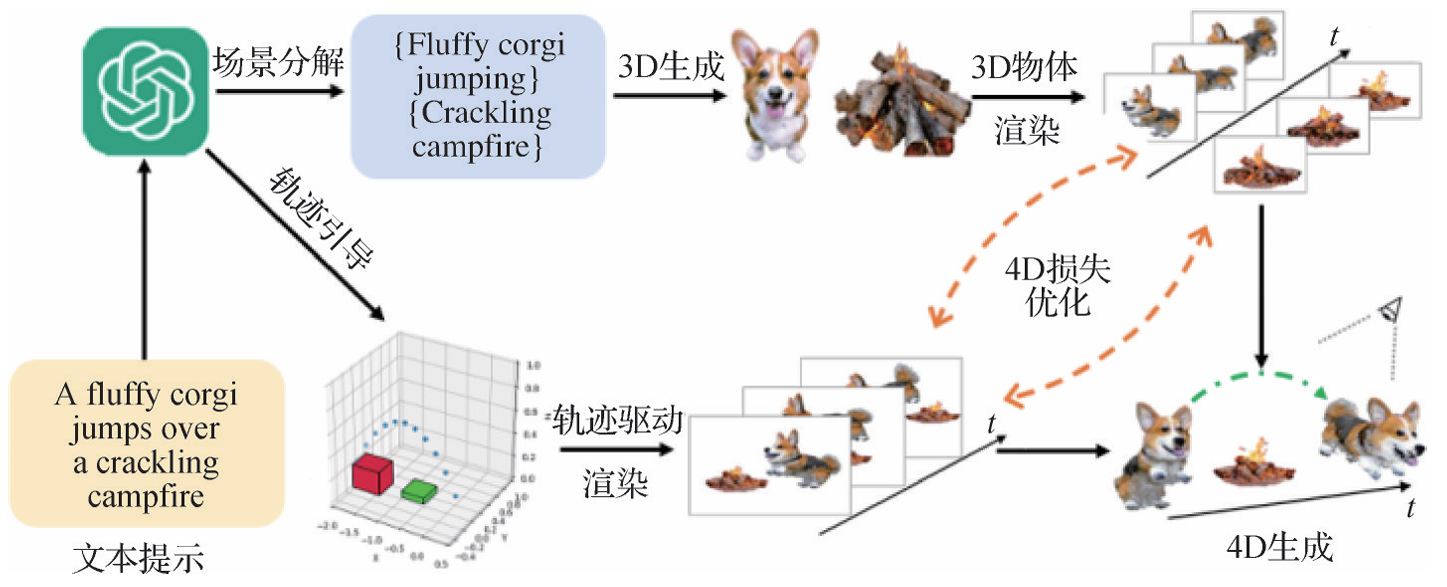
- STAG4D:Zeng等人(2024)提出STAG4D,结合预训练的扩散模型和动态3D泼溅,通过组合得分蒸馏优化4D损失,生成动态的4D场景。
- Comp4D:Xu等人(2024a)提出Comp4D,利用LLM指导运动轨迹,生成具有真实感和复杂交互的4D动态场景。LLM首先根据文本输入将场景分解为多个对象的文本描述,再生成相应的多个独立3D对象。接着,LLM用于设计对象轨迹,通过基于3D高斯分布的组合4D表示,在每次迭代过程中灵活地在以对象为中心的渲染和轨迹引导的渲染之间切换,以优化4D损失。
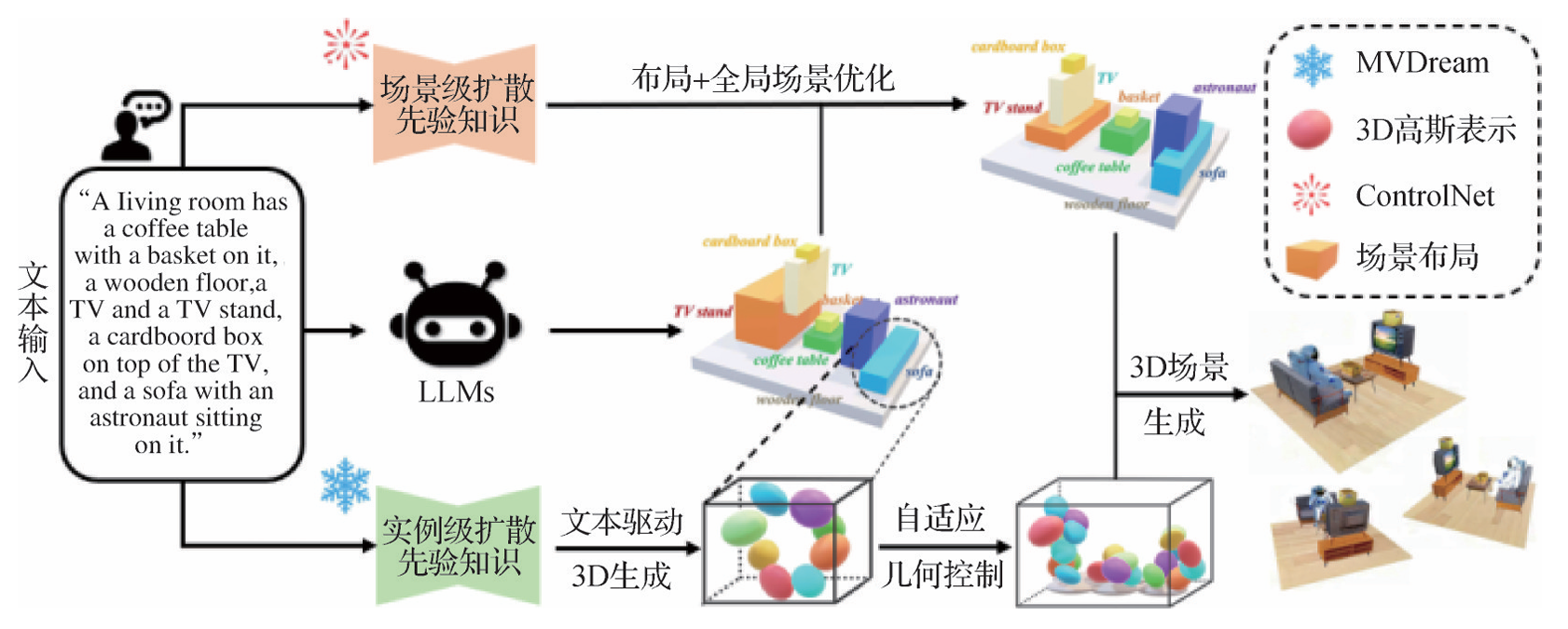
三维场景生成
- Text2NeRF:Zhang等人(2024c)结合扩散模型和单目深度估计技术,通过场景补全绘制出具有逼真视觉效果的图像,但受到3D一致性的限制。
- CompoNeRF:Bai等人(2024)提出将文本解释为可编辑的、包含多个NeRF的3D布局,并对每个对象特定的NeRF进行组合、分解和重新排列,增强多对象场景的一致性。
- GALA3D:Zhou等人(2024)提出GALA3D,通过LLM生成场景布局和对象描述,结合多视图提示融合模块,生成具有高交互性的3D场景。
- LLplace:Yang等人(2024c)提出LLplace,通过轻量级微调Llama3,实现基于自然语言命令的零样本端到端导航任务,减少了对场景对象空间关系的先验假设,增强了对上下文信息的理解。
三维目标检测
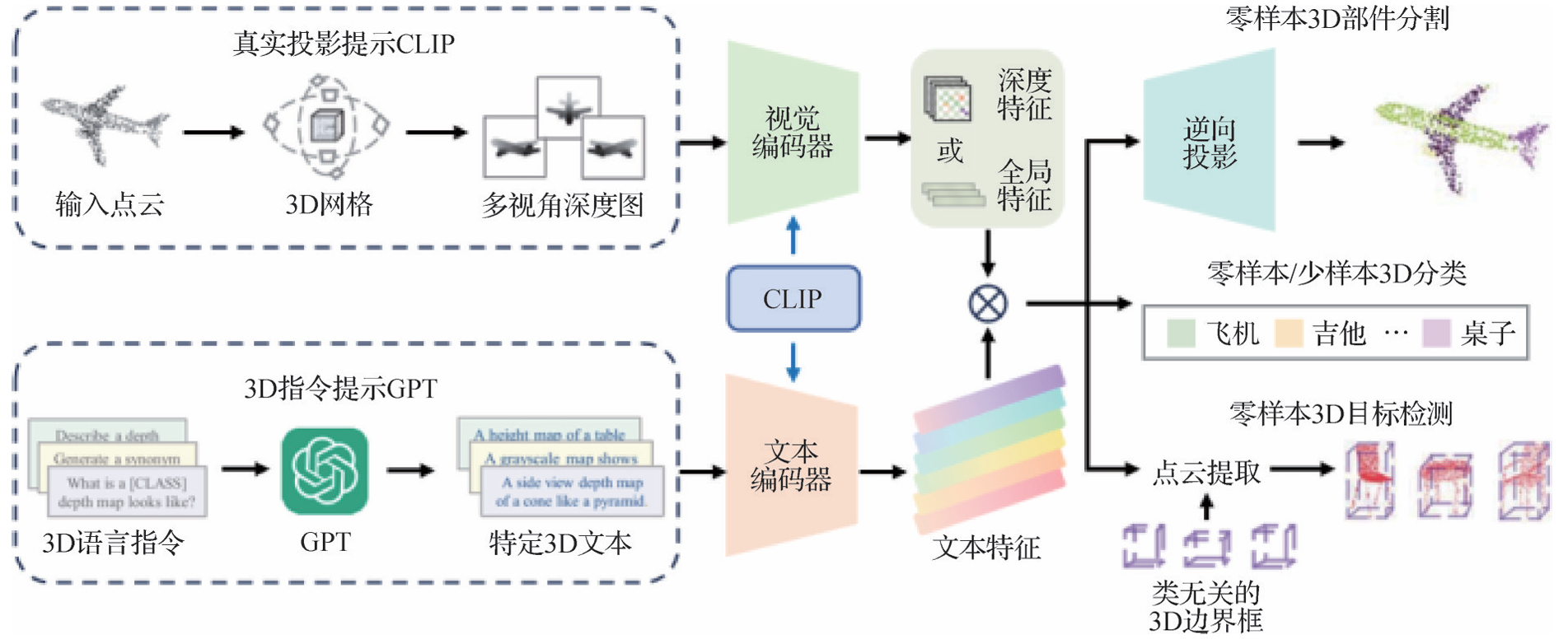
- 开放词汇目标检测:Zareian等人(2021)和Banga⁃lathe等人(2022)提出使用微弱的监督信号训练检测器,或采用蒸馏VLM对数据集进行预训练、微调或冻结等操作。Peng等人(2023)提出使用未标记数据进行自监督预训练,提高新目标定位的准确性。Khurana等人(2024)从未配对的RGB和LiDAR数据生成零样本3D边界框,并使用现成的图像基础模型将边界框作为伪标签训练。Coda(Cao等人,2023b)利用3D框几何先验和2D语义先验来生成新对象的伪框标签,并开发跨模态对齐模块。
- PointCLIP系列:Lu等人(2023d)和Zhu等人(2023c)使用CLIP处理从3D模态投影的多视图图像。Point-Bind&PointLLM(Guo等人,2023b)利用LLM和多模态语义实现零样本3D分析。
三维语义分割
- 开放词汇3D语义分割:Gu等人(2023b)和Peng等人(2023)利用VLM来辨识未知类别。OpenScene(Peng等人,2023)对齐了点特征与2D开放词汇语义分割模型的像素特征。ConceptGraphs(Gu等人,2023b)通过多视图关联并将输出融合到3D空间,构建了涵盖对象属性的开放词汇场景图。OV3D(Jiang等人,2024)通过整合VLM的开放场景知识,在3D点和文本实体描述之间建立细粒度的对应关系。
- 点云—图像数据对:Chen等人(2023b)和Ding等人(2023)通常借助图像作为桥梁,将点云特征与已经和文本特征校准的图像特征对齐,建立文本与3D模态的联系。OpenMask3D(Takmaz等人,2023)和OVIR-3D(Lu等人,2023b)分别使用3D点云生成类别不可知的实例掩码候选簇和2D掩码来生成3D候选簇。Open-YOLO 3D(Boudjoghra等人,2025)采用高效的2D-3D联合推理策略,显著提升检测效率。UniM-OV3D(He等人,2024)设计分层的点云提取器,用于获取局部和全局特征,并构建分层的点—语义文本对,实现3D点云与多模态数据的深度融合。
三维场景描述
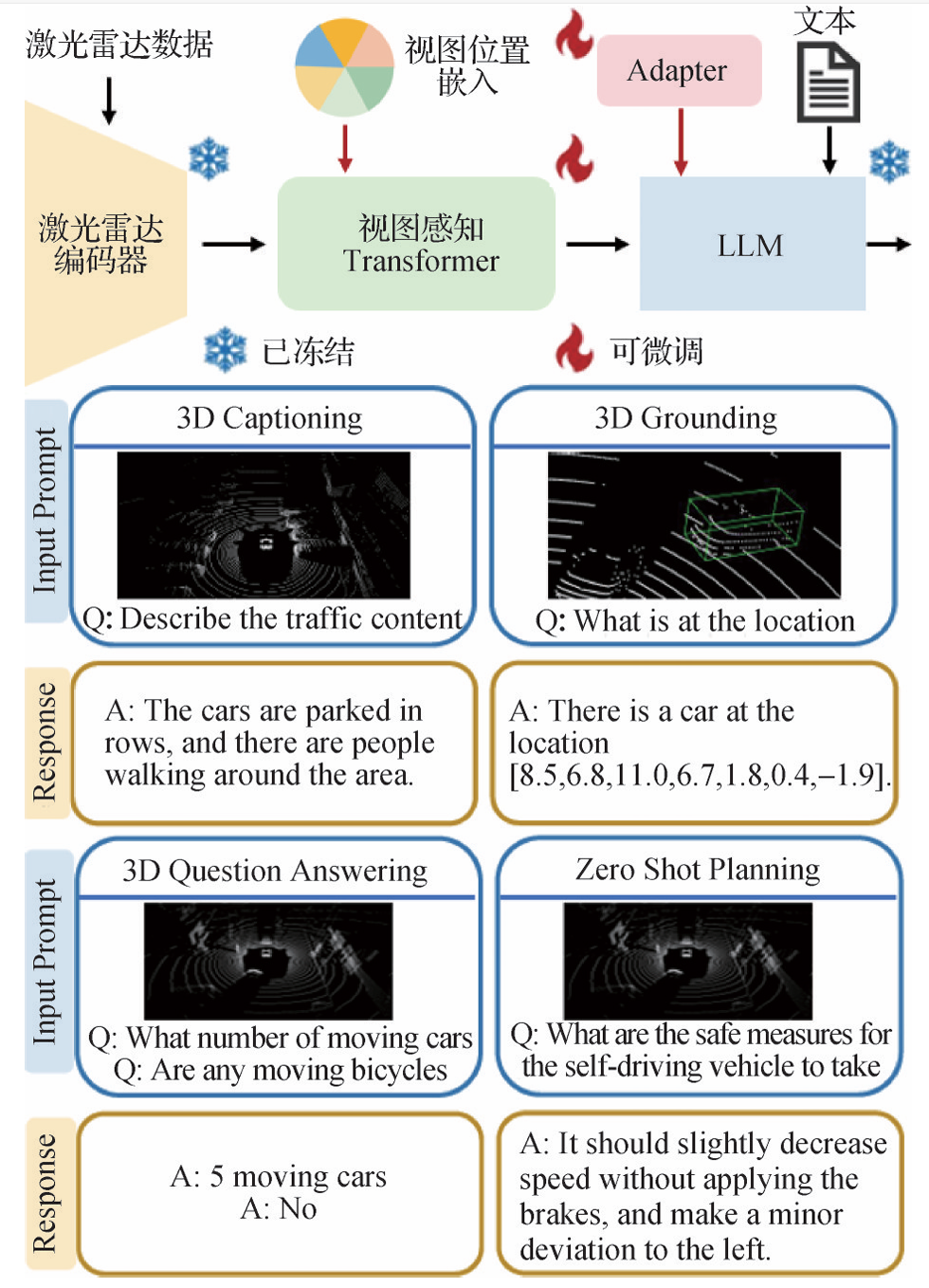
三维场景文本描述
- 先检测后描述:XTrans2Cap(Yuan等人,2022)首先利用检测器提取场景中的实例对象,然后使用师生框架提取输入的多模态信息,最终由解码器生成文本描述。Vote2Cap-DETR(Chen等人,2023d)和Vote2Cap-DETR++(Chen等人,2023e)采用“集合到集合”范式,将3D场景文本描述视为一个集合到集合的问题,并使用基于Transformer的框架解耦对象定位与字幕生成任务,再分别进行独立处理。
- 引入LLM技术:PointLLM(Xu等人,2024b)将3D场景的几何、外观信息融入点云编码器,利用LLM理解文本指令微调任务。LiDAR-LLM(Yang等人,2023c)和LL3DA(Chen等人,2023c)设计视图感知Transformer(VAT)桥接点云和LLM,从而将3D场景理解重述为语言建模问题。
三维场景图预测
- 基于视觉上下文的方法:Granular3D(Huang等人,2024c)使用自适应实例包络法,构建具有全面上下文环境信息的子场景,实现多粒度3D场景图预测。
- 基于先验知识的方法:类别分组嵌入(Qi等人,2024a)和统计先验(Feng等人,2025)将实例类别和对象间关系的常识嵌入3D表示,显著提高了3D场景图生成的预测准确性。VL-SAT(Wang等人,2023b)通过训练多模态预测模型集成视觉语言知识,并利用CLIP辅助3D模型,解决子场景信息提取的缺陷问题。ConceptGraphs(Gu等人,2023b)和Open3dsg(Koch等人,2024)将3D场景嵌入VLM的特征空间,并利用LLM表征3D场景的语义信息。Chen等人(2024b)基于CLIP开发了一个强大的3D场景图特征提取器。
语言引导的三维场景目标定位
- 两阶段训练方法:Cai等人(2022)和Jin等人(2023)首先使用预训练检测器生成物体边界框并提取特征,然后通过位置回归或属性分类来建模物体的位置及关系。
- 单阶段方法:Luo等人(2022)和Wu等人(2023c)直接整合语言信息,通过逐点过滤在单一阶段内完成目标定位,极大简化了训练流程。
- 利用LLM的先验知识:3D-CLR(Hong等人,2023b)使用文本蕴含的空间信息和3D数据来训练一个先于文本引导过程的、解析和组合语义查询的框架。CoT3DRef(Abdelrahman等人,2024)重述3D定位问题为Seq2Seq任务,通过预测一系列锚点来定位最终目标。Dora(Wu等人,2024)利用LLM从文本描述生成理想的参考顺序,使预测锚定对象无需确切位置也能逐步定位目标对象。
- 多视图架构:ViewRefer(Guo等人,2023a)利用LLM扩展单文本至多个几何一致的描述,引入多头注意力机制以增强物体跨视图交互。
三维场景问答
- ScanQA:Azuma等人(2022)基于ScanNet数据集构建了一个3D-VQA数据集,并设计一个融合模型来对齐三维对象和文本表征,以预测正确答案。
- SQA3D:Ma等人(2023)介绍SQA3D数据集,专注于场景的具身化理解和问答,要求智能体根据文本描述确定其在三维空间坐标,并能根据周围环境进行问答。
- Point-Bind LLM:Guo等人(2023b)推出第一个遵循3D多模态指令的三维语言模型,即Point-Bind LLM。经过参数微调,Point-Bind LLM将Point-Bind的多模态语义融入预训练的语言模型,展现出卓越的3D问答性能。
- Scene-LLM和SIG3D:Chen等人(2024d)和Man等人(2024)结合文本引导的LLM和3D视觉编码器,以自身中心的视角获取场景信息,以应对3D视觉语言推理的态势感知难题。
- SpatialVLM:Chen等人(2024a)运用视觉MLLM自动生成和增强3D-VQA数据集,并凭此训练VLM以增强3D空间推理能力。
多模态大模型机器人三维视觉应用
机器人三维抓取
传统方法
- 基于几何的方法:传统机器人抓取方法主要依赖于分析物体与抓取装置的几何属性来生成与评估潜在的抓取姿势。这些方法通常需要详尽且精确的物体模型,缺乏对物体语义信息的理解。
- 基于深度学习的方法:许多研究提出基于卷积神经网络(CNN)的物体抓取方法,以点云(Lundell等人,2020;Breyer等人,2021)和视图(Morrison等人,2018;Kumra等人,2020)为主要的3D表示形式。
多模态大模型的应用
- LEO:Huang等人(2024a)提出LEO,首个3D具身多任务多模态的通用智能体,在统一框架内依据视图、场景和指令设计了大量的特定标记来精确控制机器人运动。
- Voxposer:Huang等人(2023d)提出Voxposer,利用LLM从输入指令中提取可用性和约束条件,并整合VLM提供的视觉信息在观察空间中构建3D体素图,以指导机器人交互。
- Singh等人(2024):利用MLLM的常识库和鲁棒推理能力,使用图像和显隐式指令来推理生成最佳的抓取姿势。
机器人三维视觉导航
传统方法
- SLAM方法:传统机器人导航技术主要依赖于同步定位和映射(SLAM)方法来构建高精度的密集空间地图。
- 3D场景图结构:近年来,许多研究采用3D场景图结构来解决大范围场景的空间表示问题,提高了空间表示效率,并为LLM提供了有效的语义标记接口。
多模态大模型的应用
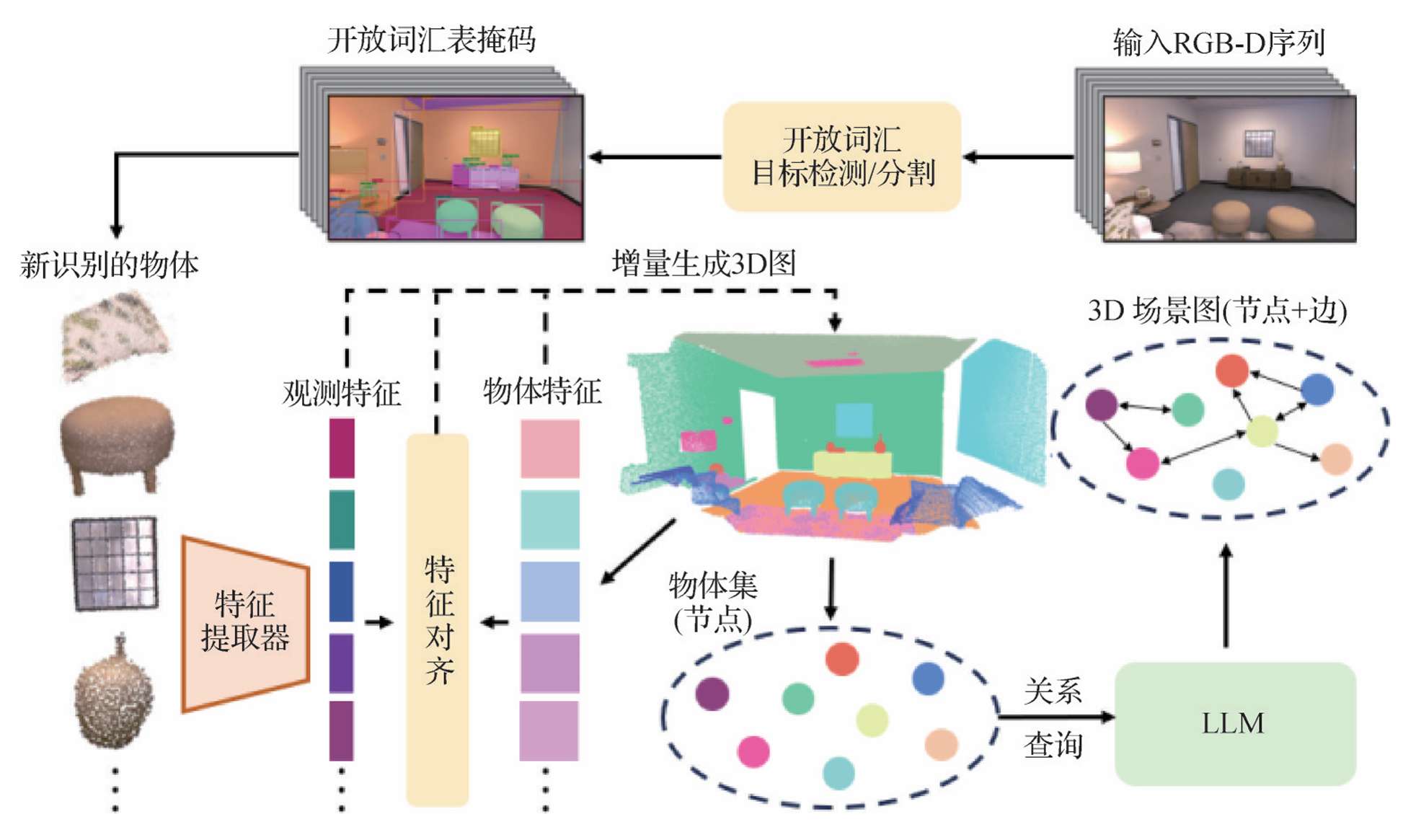
- ConceptGraphs:Gu等人(2023b)开发了一个以对象为中心的3D映射系统,接收RGB-D序列作为输入,通过开放词汇的目标检测/分割模型识别和分割出候选对象,生成3D空间并构建物体集,最终生成3D场景图。
- HOV-SG:Werby等人(2024)提出一种分层结构的3D场景图,通过分解抽象查询,使用Voronoi图遍历检索场景目标以实现长视距机器人导航。
- VELMA:Schumann等人(2024)通过文本提示查询过去的运动轨迹,然后利用LLM预测动作序列,有效应对复杂城市环境下的导航问题。
- IVLMap:Huang等人(2024b)将自然语言转换为具有实例和属性信息的导航目标,并基于自然语言命令完成零样本的端到端导航任务。
- NaviLLM:Zheng等人(2024)通过引入基于模式的指令,灵活地将各种任务转换为生成问题,使得LLM能适应具身导航的需求,显著提升了机器人在未知场景中的导航泛化能力。
其他任务
感知领域
- VLM在感知任务中的应用:VLM通过学习视觉和文本数据之间的关联来提供跨模态理解,从而辅助完成如3D分类(Hong等人,2023c)、6D姿态估计(Cai等人,2024)以及手术场景分割(刘敏等人,2024)等任务。
- FoundationPose:Wen等人(2024)使用6D物体姿态跟踪,实现以时间线索的方式对视频序列进行更高效、流畅和准确的姿态预测。
决策规划领域
- LLM在高层次规划中的应用:LLM和VLM能协助机器人进行任务规范,以实现高层次规划。这些基于LLM的框架涵盖了广泛的推理层次,从初级的自回归代码策略生成(Liang等人,2023b)到纯粹使用自然语言对任务计划进行推理(Mikami等人,2024)。
- 语言模型为策略学习提供反馈:研究人员还采用语言模型为策略学习技术提供反馈(Han等人,2024a;Bartsch和Farmani,2024),提高机器人的学习效率和性能。
Scene-LLM
- Scene-LLM在环境理解中的应用:Scene-LLM(Fu等人,2024)进一步将VLM的上下文理解与3D现实世界对齐,通过将文本描述与3D环境中的特定对象、位置或动作相关联,机器人能够更好地理解和操作周围的环境。
数据集

基本三维数据集
-
ScanNet:
- 包含1513个室内场景的2.5M幅RGB-D图像,每个场景都提供相机位置姿态、三维表面模型和语义信息。数据采集通过结合自动化表面重建和众包语义标注的RGB-D捕获系统完成。
- 适用于深度学习方法在3D场景理解领域的研究,包括3D对象分类、语义体素标记和CAD模型检索。
-
Matterport3D:
- 包含90个建筑规模场景的194k幅RGB-D图像,覆盖10.8k个全景视图。数据采集利用三脚架安装的相机装置,通过旋转获取6个方向的HDR照片及连续深度数据,合成与彩色图像对齐的深度图。
- 适用于关键点匹配、视图重叠预测、表面法线估计、区域分类和语义体素标记等计算机视觉任务。
-
ShapeNet:
- 从公共在线存储库的多个类别收集了超过3M个3D CAD模型。数据采集过程包括自动化下载和人工验证,以确保模型的质量和准确性。ShapeNet通过WordNet的语义类别组织,支持多种任务,包括几何分析、对象识别和场景理解。
- 广泛应用于3D对象识别、几何分析和场景理解等任务。
-
3RScan:
- 包含478个室内环境的1482个RGB-D扫描序列,涵盖多次扫描以捕捉环境变化。数据集通过Google Tango应用采集,经相机姿态校准和纹理映射的后处理,生成精确的3D重建模型。注释信息包括语义实例分割、对象对齐和对称性属性。
- 适用于长期SLAM、场景变化检测和对象重定位等任务。
-
3DSSG:
- 基于3RScan室内环境3D重建数据集,通过半自动方式生成,旨在提供丰富的语义场景图。包含1482个3D场景,每个场景都由一组场景图表示,这些图由节点和边组成,节点代表3D扫描中的具体物体实例,边则表示这些物体之间的关系。
- 适用于3D场景理解任务,如语义分割、对象检测和场景图生成,尤其在跨域检索如2D-3D场景检索中表现突出。
-
Structured3D:
-利用专业室内设计师的设计和先进的渲染引擎生成,包含21835个房间的3D结构注释和超过196k幅逼真的2D渲染图像。数据采集过程包括从原始房屋设计文件中提取几何结构信息,并通过行业领先的渲染引擎生成高质量图像。- 适用于结构化3D建模任务,如房间布局估计,通过结合真实图像训练深度网络,展示了在基准数据集上的改进性能。
-
HM3D:
- 由Facebook AI Research联合多所大学共同创建,包含来自全球38个国家的1000个建筑规模的室内3D重建。数据通过Matterport Pro2设备扫描获取,经过严格的筛选和质量控制流程,确保数据的多样性和高质量。
- 适用于具身智能代理的感知、导航和行动能力的研究,尤其适用于室内环境。
-
Objaverse:
- 含818k个3D模型及其文本描述,覆盖21k个不同类别,来源于Sketchfab平台并由超10万名艺术家设计。数据集的采集遵循Creative Commons许可,确保使用的合法性与多样性。
- 支持广泛的3D应用,包括3D生成模型训练、长尾类别分割改进、开放词汇导航以及视觉模型鲁棒性分析。
-
Objaverse-XL:
- 基于Objaverse数据集,包含超过10M个从GitHub、Thingiverse、Sketchfab、Polycam和史密森尼学会等来源搜集的多样化3D对象。数据集的采集通过Python脚本自动化完成,并通过Blender软件进行渲染和去重处理。
- 适用于3D视觉任务,如新视角合成、3D重建和生成,能够显著提升模型的零样本泛化能力。
-
nuScenes:
- 由nuTonomy公司采集,涵盖美国波士顿和新加坡两地,通过6个摄像头、5个雷达和1个激光雷达传感器,提供360度全方位视角。包含1000个场景,每个场景20秒长,详尽标注了23个类别的3D边界框和8个属性。
- 支持自动驾驶车辆的多种任务,如物体检测、跟踪和行为建模。
-
STCrowd:
- 由上海科技大学等机构合作采集,通过车载128束激光雷达和单目摄像头在不同场景和天气条件下同步获取,包含219k个行人实例,平均每帧20人,具有高密度和严重遮挡的特点。
- 支持激光雷达、图像及多传感器融合的行人检测与跟踪任务,并提供了基准方法。
三维视觉语言数据集
-
ScanRefer:
- 基于ScanNet构建,涵盖800个室内场景中的11046个3D对象,并附有51583条详细的人工文本注释。数据集的构建过程包括数据收集、描述编写、验证和筛选等步骤。
- 显著增强了3D视觉语言模型在复杂环境中的语言理解和空间定位性能,为3D视觉与语言交互的研究提供了重要资源。
-
ReferIt3D:
- 基于ScanNet的室内场景构建,涵盖76个细粒度的对象类别。通过自然语言描述构建的Nr3D数据集和基于空间关系的合成语言描述的Sr3D数据集,为3D对象识别和空间关系识别任务提供了丰富的上下文信息。
- 适用于3D目标识别和多模态交互任务,但对模型的计算资源和算法设计提出更高要求。
-
3D-FUTURE:
- 由阿里巴巴集团创建,旨在填补高质量3D家具形状和纹理研究领域的空白。利用先进的3D渲染引擎,基于专业设计师构建的房间场景,生成了20240幅高质感的室内图像,并提供了9992个细节丰富的3D家具模型。
- 支持3D对象姿态估计、基于图像的3D形状检索、单视图3D重建和3D形状纹理恢复等研究任务。
-
ScanQA:
- 源自ScanNet,通过自动化生成和人工编辑过程构建,包含41363个问答对,覆盖800个室内场景。数据采集涉及自动化问答对生成、问题过滤、人工编辑和答案收集。
- 专为3D视觉问答任务设计,要求模型利用3D扫描信息和文本问题来定位场景中的对象并提供答案。
-
3DMV-VQA:
- 源自HM3D Sem数据集,通过在模拟环境中操作具身代理来主动捕获RGB图像。包含约5k个场景、600k幅图像及50k个问答对,涵盖概念、计数、关系和比较4种问题类型。
- 旨在评估和提升模型在3D多视图视觉问答任务中的表现,为模型训练和评估提供了高质量的数据基础。
-
ShapeTalk:
- 整合ShapeNet、ModelNet和PartNet等数据库资源,经过去重和质量筛选,最终提供36k个3D形状和536k条文本描述。数据采集使用人工注释方式,根据形状对比提供细粒度描述,确保语言的多样性和准确性。
- 适用于语言驱动的3D形状编辑任务,促进了3D-LLM在语言引导的形状编辑任务中的表现。
-
ScanScribe:
- 由ScanNet和3R-Scan室内场景的RGB-D扫描组成,并利用Objaverse数据集增强场景中对象的多样性。通过模板和GPT-3生成278k个场景描述,涵盖1185个独特室内场景的2995个RGB-D扫描。
- 为3D视觉语言领域的预训练模型带来显著的性能提升,尤其对于3D视觉定位、密集字幕生成、视觉回答和情境推理等任务。
-
OmniObject3D:
- 包含6k个来自日常生活的高质量3D扫描物体,涵盖190个类别,与ImageNet和LVIS等2D数据集共享类别,便于研究者探索通用的3D表示。每个3D物体通过2D和3D传感器捕获,提供纹理网格、点云、多视角渲染图像和真实捕获视频,并进行注释。
- 支持鲁棒3D感知、新视角合成、神经表面重建和3D物体生成等多种研究任务。
-
Pyramid-XL:
- 通过3个层级逐步提升描述的质量和细节:Level 1利用单视图生成简短描述;Level 2合成多视图描述;Level 3利用高级视觉语言模型生成详细密集的描述和问答对。
- 显著提升了3D-LLM在3D对象识别、文本推理任务中的性能,尤其在理解3D几何和颜色信息方面。
-
UniG3D:
- 通过通用数据转换管道,将Objaverse和ShapeNet数据集中的原始3D模型转化为包含文本、图像、点云和网格的多模态数据表示,并生成了1.6M规模的UniG3D-ShapeNet和16M规模的UniG3D-Objaverse数据集。此外,UniG3D还利用渲染引擎和多模态模型来丰富文本信息。
- 适用于包括点云和SDF的多种3D对象生成任务,并通过Point-E和SDFusion等方法验证了其有效性。
-
LiDAR-LLM:
- 采用MLLM和GPT4,为nuScenes数据集中的3D LiDAR场景图像增添文本描述,从而获取了包含420k个LiDAR文本对的nu-Caption数据集。同时,将3D边界框融入文本问答对,创建了包含280k个LiDAR字幕对的nu-Grounding数据集。
- 为3D字幕、3D定位和3D问答等任务提供了丰富的训练资源。
-
Multi3DRefer:
- 扩展自ScanRefer数据集,包含61926条文本描述,覆盖11609个物体实例,是首个支持零目标、单目标或多目标物体定位的3D视觉数据集。通过整合ChatGPT,Multi3DRefer在多样性和自然性方面得到增强,并利用人工审核确保数据质量。
- 适用于3D视觉定位、机器人导航及增强现实等任务,为多模态3D场景理解的研究提供了新的基准。
-
CLEVR3D:
- 专为3D点云上的视觉问答(VQA-3D)任务而设计的大规模数据集,包括171k个问题,覆盖8771个3D场景。利用结构化信息设计问题模板,并填充模板变量,产生各种类型的问题。通过真实场景和增强场景的组合场景操作策略构建,减少模型对常规布局的依赖。
- 适用于VQA-3D任务,还能显著提升3D场景图分析的性能。
-
M3DBench:
- 通过结合文本、图像、3D对象等多模态提示构建的大规模数据集。利用现有的3D数据集,并结合自我指令生成方法,通过GPT系列模型生成与特定任务相关的指令数据,以确保数据的多样性和实用性。
- 适用于包括对象检测、视觉定位、密集描述、视觉问答、多区域推理、场景描述、多轮对话和机器人具身规划等3D视觉中心任务。
-
Cap3D:
- 提出一种自动化3D文本描述生成方法,通过结合图像标题、图像文本对及LLMs,从多视图中整合文本描述,避免了耗时且成本高昂的手动注释过程。应用于大规模3D数据集Objaverse,产生了660k个3D-文本对。
- 适用于3D对象自动注释、几何描述生成,并作为文本到3D生成模型的基准测试。
-
3D LAMM:
- 利用公开可用的数据集,如COCO、Visual Genome、3RScan等,通过GPT-API生成196k个3D指令响应对。数据采集过程包括日常对话、详细描述、事实知识对话和视觉任务对话,强调细粒度信息和事实知识。
- 适用于图像分类、目标检测和视觉问答等3D视觉任务,尤其经过特定任务微调后表现更佳。
-
EmbodiedScan:
- 基于ScanNet、3RScan和Matterport3D等现有大规模3D室内场景扫描数据,通过重新注释和处理,以适应从第一人称视角的连续场景感知变化。包含超过5k个扫描场景,近1M个第一人称视角的RGB-D视图,以及丰富的多模态注释,如160k个3D边界框,涵盖超过760个类别以及1M个对象间空间关系的描述。
- 适用于3D检测、语义占用预测和基于语言的3D场景理解等任务。
-
ScanEnts3D:
- 通过语言关联3D场景对象,并运用Web界面和专业标注团队注释来扩充ReferIt3D和ScanRefer数据集。涵盖705个真实世界场景,以及84k个自然引用语句和369k个对象间的显式对应关系。
- 适用于3D场景密集文本描述和目标物体定位任务。
-
SceneVerse:
- 作为首个百万规模的3D视觉语言数据集,通过人工注释和自动生成的方式构建,包含68k个室内场景、1.5M个3D对象以及2.5M个场景语言对。数据采集过程包括房间分割、点云归一化和语义标签对齐等预处理步骤,确保数据的一致性和质量。
- 适用于3D视觉定位、场景理解和多模态交互等任务,通过大规模预训练,能够显著提升3D-LLM的性能。
-
3D-GRAND:
- 从3DFRONT和Structured3D的合成数据中整合了40k个家庭场景,并使用GPT-4生成6.2M个配对的场景语言指令。
- 适用于多种3D文本任务,包括对象引用、场景描述和问答等。其优点在于提供了大规模、密集关联的数据,有助于提升3D-LLM的性能,特别是在模拟环境到现实世界的迁移学习能力上展现出潜力。
-
MMScan:
- 基于EmbodiedScan,通过精心设计的语言提示和人工校正,生成了层次化的语言注释。包含1.4M个文本描述,涵盖109k个对象和7.7k个区域,为3D视觉定位和问答任务提供了超过3.04M的样本。
- 适用于3D视觉定位和问答任务,其高质量和多样性使其成为训练和评估3D-LLM的重要资源。
结语与展望
挑战和研究展望
三维视觉表示载体的统一
- 问题描述:3D视觉的不同表示在不同应用场景具有不同的侧重性,例如点云主要用于表示室内和室外环境,但难以捕捉准确、丰富的空间模型细节,而体素等结构化表示虽能体现空间上下文关系,但计算量大且分辨率有限。
- 研究方向:开发能够更有效地弥合空间信息和语言之间差距的新型3D场景表示,整合表示体系优势,寻找在3D表示中编码语言和语义信息的创新方法,如使用精简语言和语义嵌入,帮助弥合空间信息和语言模式之间的差距。
多模态大模型的空间推理能力
- 问题描述:尽管多模态大模型在某些视觉问答基准测试中表现出色,但大多数最先进的模型在空间推理方面仍存在显著挑战,难以理解物体在3D空间中的位置、识别物理对象的数量关系、距离或大小差异或它们之间的空间关系。
- 研究方向:研究如何解决多模态大模型训练数据中缺乏三维空间知识的问题,通过使用互联网规模的空间推理数据来训练,提升多模态大模型的空间推理能力,并进一步赋能3D视觉任务。
多模态大模型驱动的3D视觉数据处理普适性
- 问题描述:随着3D环境的复杂度和语言模型尺度的增加,大模型技术严重制约于个人用户硬件设备配置,当前多模态大模型需要一整套计算机集群进行高性能计算,不利于整体计算机社区参与到技术更新迭代中。
- 研究方向:设计为强适应性和高计算效率的多模态大模型架构,降低模型技术使用门槛,拓宽其应用范围。同时,研究如何通过新的泛化性和知识迁移方法,在适应真实数据的同时保持模型的强泛化性和良好性能。
D视觉任务下的多模态大模型落地完善机制
- 问题描述:当前多模态大模型与3D视觉集成技术从构建设计到应用落地是一个持续自我完善的过程,亟须提升完善机制纠正过程中的不足,确保多模态大模型技术更良好地理解3D任务目标,实现高效精准作业。
- 研究方向:在模型性能提升方面,当前3D视觉感知理解任务基准的粒度过于简单,限制了对复杂3D环境理解的洞察。特别是在3D推理方面,基准的规模以及完整性阻碍了对空间推理技能的评估以及3D决策/交互系统的开发。此外,目前使用的基准数量不足以支撑多模态大模型在3D环境中的全部能力发挥。
3D视觉任务下的多模态大模型安全与道德
- 问题描述:当前的模型设计仍处于技术实现阶段,没有充分考虑到模型落地应用之后的安全性以及道德性应用问题。多模态大模型经常不可预测且难以解释的方式输出不准确、不安全的信息,导致关键3D应用任务失效,容易造成国民经济的重大损失。同时,模型训练数据的社会偏见切实影响着3D场景预测的决策优先度,导致某些群体处于不利地位。
- 研究方向:在3D环境任务作业过程中,构建多模态大模型完善机制,采用策略促使模型自我迭代补全模型缺陷,用于偏差检测和纠正的有力升级框架,确保多模态大模型在3D视觉领域的广泛落地,不断自我升级,输出有效且公正的结果。
面向边端侧场景的多模态大模型小型化和云边协同
- 问题描述:面向机器人3D视觉感知等边端侧低算力场景,对多模态大模型提出更高的时延和性能要求。传统3D视觉任务小模型方案面临3D跨场景泛化性不足、任务效能低、重复开发交付成本高等问题。
- 研究方向:探索模型量化、剪枝和蒸馏等模型压缩技术,降低大模型应用门槛。针对云边端多源异构算力等实际3D场景,结合多模态大模型通用能力和3D视觉任务小模型专用能力,实现云—边结合模式下的推理框架,研究大、小模型在协同规划、协同推理以及数据隔离等方面的技术实现。
总结
- 多模态大模型的优势:本文确认了多模态大模型相较于传统技术的独特优势,包括但不限于零样本学习、高级推理和世界知识认知领域。通过提炼并对齐大模型中的文本信息与3D空间解释以弥合模态间的偏差,增强3D环境中的空间理解和交互,展示了多模态大模型与3D视觉数据集成技术在广泛任务上的成功应用案例,推动空间AI系统的发展。
- 面临的挑战:本文强调了统一表示、模型推广和落地完善等方向上面临的重大挑战,克服这些阻碍是保障多模态大模型切实落地的前置必要条件。
- 未来展望:总之,本文不仅全面概述了使用多模态大模型的3D视觉任务现状,还呼吁共同努力探索和扩展多模态大模型在复杂3D世界理解与交互方面的能力,为空间智能领域的持续性技术革新铺平道路。


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)