大模型后训练——DPO基础
大模型后训练——DPO基础
大型语言模型在能够执行指令和回答问题之前,需要经历预训练(Pre-training)和后训练(Post-training)两个核心阶段。
- 预训练阶段,模型通过学习从海量未标注的文本中预测下一个词或token来掌握基础知识。而在后训练阶段,模型则着重学习实际应用中的关键能力,包括准确理解并执行指令、熟练运用工具,以及进行复杂的逻辑推理。
- 后训练是将在海量无标签文本上训练的原始的通用语言模型转变为能够理解并执行特定指令的智能助手的过程。无论是想打造一个更安全的 AI 助手、调整模型的语言风格,还是提升特定任务的精确度,后训练都不可或缺。
后训练是大语言模型训练中发展最迅速的研究方向之一。
而在本课程中,就可以学习到三种常见的后训练方法——监督微调(SFT)、直接偏好优化(DPO)和在线强化学习(Online RL)——以及如何有效使用它们。
学习地址:DPO基础。
在本课程中,你将学习直接偏好优化的基本概念,包括该方法、常见用例,以及在直接偏好优化中高质量数据整理的原则。让我们来看看直接偏好优化的详细公式。
通常,直接偏好优化可以被视为一种从正面和负面回复中进行对比学习的方法。所以,和监督微调一样,我们可以从任何大语言模型开始,通常建议使用指令微调大语言模型,这种模型已经可以回答用户的一些基本问题。比如说,用户问“你是谁?”并且助手说我是Llama。在这种情况下,我们希望通过整理标注员准备的一些对比数据来改变模型身份。这样的标注员可以是人工标注员,甚至是一些基于模型的标注员,为我们整理数据集。所以在这种情况下,用户可能会问“告诉我你的身份”,并且我们需要至少准备两个回复,以便直接偏好优化(DPO)起作用。 所以我们可以准备一个回答说“我是Athene”,另一个回答说“我是大语言模型”。其中“我是Athene”被标记为首选回答,而“我是大语言模型”被标记为较不首选的回答。通过这种方式,当模型回答与身份相关的问题时,我们试图促使它说“我是Athene”而非“我是大语言模型”。收集到这类对比数据后,你就可以使用准备好的数据在这个语言模型上执行近端策略优化(DPO)。在本节课中,我们会深入探讨这个损失函数。 在语言模型之上执行直接偏好优化(DPO)后,我们将得到一个经过微调的大语言模型(LLM),希望它能从这里策划的正向和负向样本中学习。所以在这种情况下,它会尝试模仿偏好的样本。如果用户进一步询问“你是谁?”,希望助手回答“我是Athene”而不是“我是Llama”。通过这种方式,我们可以使用这种直接偏好优化方法改变模型的身份。
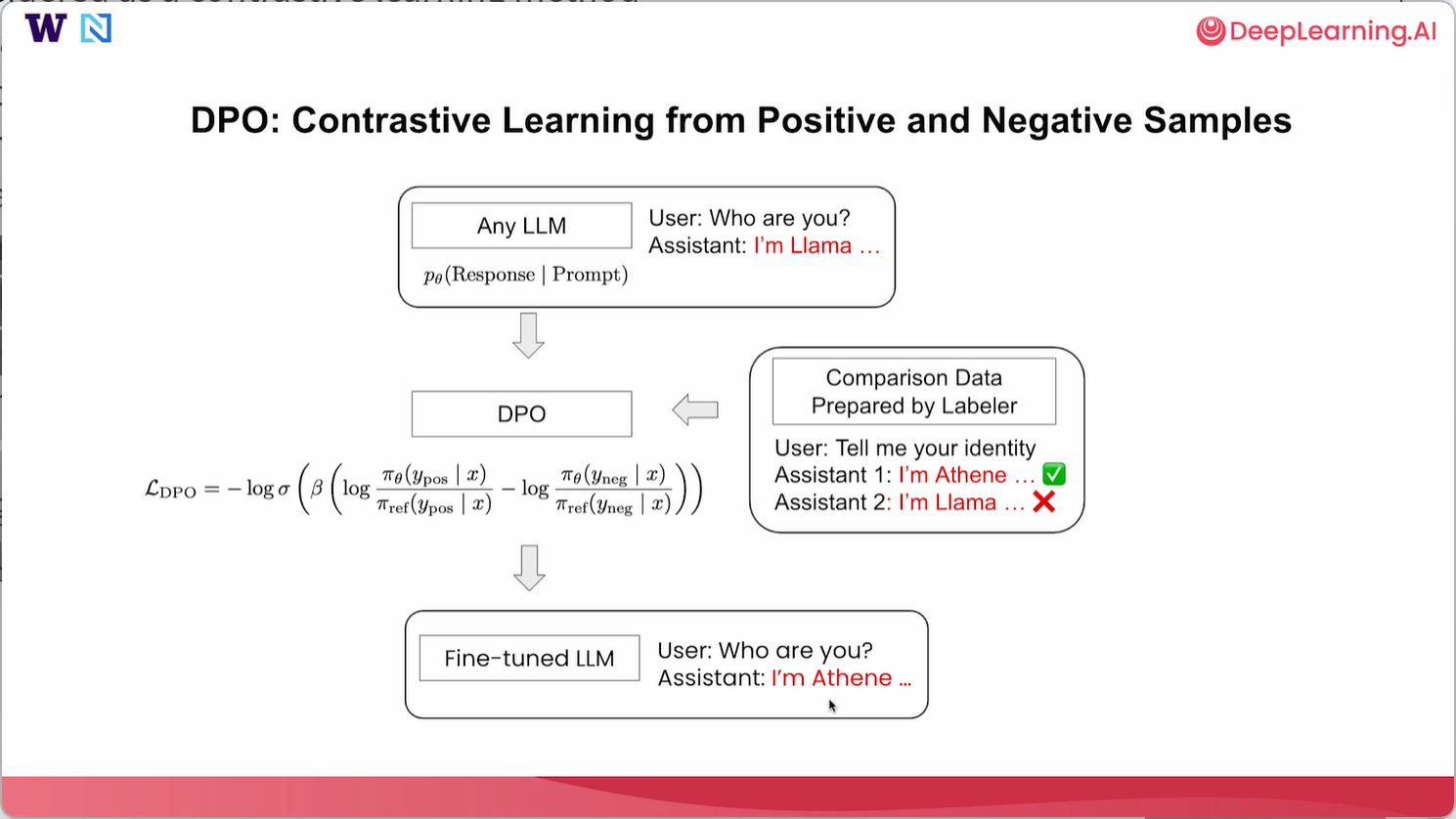
让我们更深入地研究损失函数以及直接偏好优化(DPO)究竟在做什么。DPO旨在最小化对比损失,该损失对负面回复进行惩罚,并鼓励正面回复。DPO损失实际上是对重新参数化奖励模型的奖励差异的交叉熵损失,我们将在此深入探讨。让我们来看看这个DPO损失,它是某个对数差值的sigmoid函数的负对数,其中sigma实际上就是sigmoid函数,而beta是一个非常重要的超参数,我们可以在DPO的训练过程中对其进行调整。beta值越高,这个对数差值就越重要。在这个大括号内,我们有两个对数差值,分别关注正样本和负样本。我们先看上面的部分。首先,我们有两个概率比值的对数。分子,即πθ,是一个微调后的模型。所以这里我们关注的是,对于微调后的模型,在给定提示的情况下,产生正面回复的概率是多少。分母是一个参考模型,它是原始模型的副本,权重固定,不可调整。我们只关注原始模型在给定提示的情况下,产生那些正面回复的概率。同样,对于负样本,我们也有对数比值,其中πθ是你微调后的模型,θ是你在这里想要调整的参数。而π参考是一个固定的参考模型,可以是原始模型的副本。本质上,这个对数比值项可以被看作是奖励模型的重新参数化。如果你将其视为奖励模型,那么这个DPO损失实际上就是正样本和负样本之间奖励差异的sigmoid函数。本质上,DPO试图最大化正样本的奖励,并最小化负样本的奖励。关于为什么这样的对数比值可以被视为这种奖励模型的重新参数化的详细信息,我建议你阅读原始DPO论文,在那里找到详细内容。

因此,直接偏好优化(DPO)也有一些最佳用例,其中第一个最重要的用例将是改变模型行为。通常,当你想对模型响应进行小的修改时,直接偏好优化(DPO)非常有效。这包括改变模型特性,或使模型在多语言响应、指令遵循能力方面表现更好,或者改变模型一些与安全相关的响应。第二个用例是关于提升模型能力。所以通常情况下,如果实施得当,由于直接偏好优化(DPO)能够同时看到好样本和坏样本的对比特性,在提升模型能力方面,它可能比监督微调(SFT)更有效,特别是当你能使直接偏好优化(DPO)实现对齐时,对提升能力来说效果甚至会更好。

所以这里有一些用于直接偏好优化(DPO)的数据整理原则。有几种常见的方法可用于高质量的DPO数据整理。
第一种是一种校正方法,通常可以从原始模型生成回复,将该回复作为一个主动样本,然后进行一些改进,使其成为一个正向回复。在这种情况下,一个最简单的例子是改变模型的身份,你可以从当前模型自身生成的一个负面例子开始,比如对于“你是谁?”这样的问题,模型可能会说“我是Llama”。 你可以直接进行修改,并用你想要的任何模型身份替换这个Llama。在这种情况下,对于同样的问题,我们希望模型说“我是Athene”。所以我们将这个回复设为正向的。通过这种方式,你可以使用这种基于纠正的方法,自动创建大规模、高质量的对比数据,用于DPO的训练。
第二种方法可以被视为在线或策略内DPO的一种特殊情况。在这种情况下,你希望从模型自身的分布中生成正向和负向示例。 实际上,你可以针对同一个提示,从你想要微调的当前模型中生成多个回复,然后你可以收集最佳回复作为正样本,最差回复作为负样本。之后你再判断哪个回复更好,哪个回复更差。你可以使用一些奖励函数或人工判断来完成这项工作。

另外,人们可能需要注意的第二点是在直接偏好优化(DPO)过程中避免过拟合。因为直接偏好优化本质上是在进行某种奖励学习,它很容易过度拟合到一些捷径上。与非首选答案相比,其中一个首选答案可能有一些捷径可学。 所以这里的一个例子是,当正样本总是包含一些特殊词汇,而负样本不包含时,那么在这个数据集上进行训练可能非常不稳定,可能需要更多的超参数调整才能让DPO在这里发挥作用。所以在本节课中,我们详细介绍了DPO训练以及DPO数据整理的一些原则。在下一节课中,我们将深入探讨一个关于DPO的编码实践,这个实践会改变模型的特性。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)