大厂算法实习常见八股文,这些你都会吗?(已拿offer)
首先是模型结构(上面那个图一定要牢牢记在脑海中),其次是embedding的作用,为什么要位置编码,而RNN不需要,MHA在Encoder和Decoder中有什么不同,Encoders提供的是QKV中的什么矩阵,为什么Transformer采用LN而不采用BN,还有其他标准化方法吗,残差连接为什么能缓解梯度消失,输出层的结构是怎么样的,CNN,RNN,Transformer作为三大特征提取器,请对
前面学长总结过一期关于机器学习的八股的问题,八股重点是考察对每个算法模型透彻的了解。现在大家都习惯使用AI工具进行编程,对于机器学习深度学习的基础概念算法可能掌握的不够透彻
这一期学长继续来总结一些机器学习深度学习常见八股,适合算法岗或者相关岗位的同学进行自查
有同学已经根据学长总结的这个八股文拿到大厂的offer了,大家学起来
大家如果看着题目能想到答案,就说明你是真的掌握,但是应该有不少同学是只能讲个大概,会遗漏挺多细节的,对于这种不能完全掌握的,建议大家记录下来,定期查看,复习两三遍,你就能记住了
八股不难,理解不了,就强行硬记。下面是具体的问题(★表示重要性或者频率):
首先是XGBoost的全家桶:
RF和XGBoost算法的对比(★★):可以从模型结构,节点分裂,训练数据,正则化这几个方面来进行描述
XGBoost和LightGBM(★★★):这个面试中大概率会问到,可以从分裂策略,性能与速度,内存使用情况进行对比
XGBoost中有哪些并行化策略(★):从特征并行化,数据并行化,树节点并行化,直方图并行化进行说明即可
XGBoost有什么调参方法(★):首先考虑调什么参数,比如最大树深度,学习率等,调参可以考虑正则化,早停机制,网格搜索,随机搜索,贝叶斯优化等
XGBoost和GBDT对比(★★★):非常重要的一个问题,可以从基分类器的类型,一阶二阶泰勒展开,数据采样,缺失值处理这些角度来分析✅以上几个基本上就囊括了大部分的xgboost考点
ID3, C4.5和CART的对比(★★):可以从节点分裂指标,缺失值处理,离散连续特征支持情况来考虑
其次Transformer全家桶:
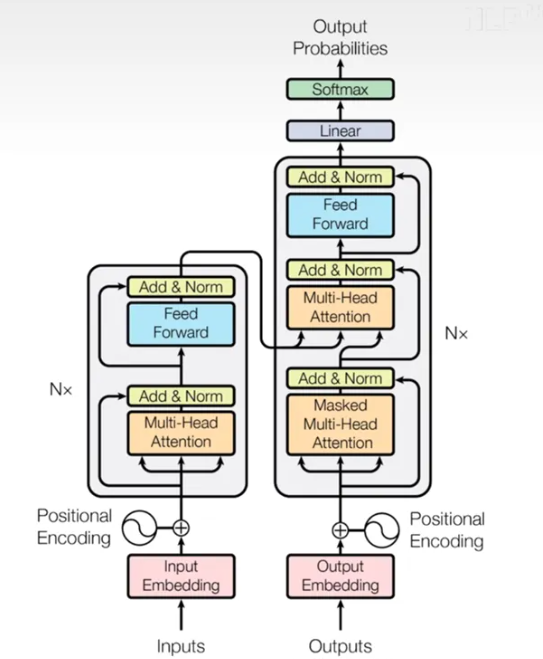
Transformer全家桶(★★★):每逢面试必考
首先是模型结构(上面那个图一定要牢牢记在脑海中),其次是embedding的作用,为什么要位置编码,而RNN不需要,MHA在Encoder和Decoder中有什么不同,Encoders提供的是QKV中的什么矩阵,为什么Transformer采用LN而不采用BN,还有其他标准化方法吗,残差连接为什么能缓解梯度消失,输出层的结构是怎么样的,CNN,RNN,Transformer作为三大特征提取器,请对比分析一下
这个真的非常非常重要,考点也很多,硬背也要背下来,复习几遍
k-means(★):初始中心中心怎么选,以及怎么优化,比如让初始中心尽可能分散等;K-means++是怎么改进的
再来信息熵全家桶(十次面试可能问6-7次):
信息熵全家桶(★★★):超级重要的点,信息熵,条件熵,固定值,信息增益,信息增益率,基尼指数,交叉熵损失,互信息,KL散度这些指标之间的关系,以及计算公式概率一定要区分清楚,和Transformer一样重要✅
正则化操作(★★★):正则化操作包括哪些,除了常规的L1,L2正则化,还有dropout,BN,early stopping,权重衰减,剪枝等✅
过拟合和欠拟合(★★★):虽然概念很简单,但是常考,记住过拟合和欠拟合可以采取什么策略✅
逻辑回归中损失函数(★★):交叉熵损失函数要会写,交叉熵损失函数在二分类和多分类中公式区别
Python中的深拷贝和浅拷贝(★):简单来说,原来的对象变化,浅拷贝也会变化,深拷贝中拷贝对象和原来的数据是独立的,不受影响
Dict的底层实现(★★):python中字典底层采用哈希表来实现的,哈希表会存在哈希冲突,怎么解决的要清楚,这也是一个比较重要的点
PCA原理(★):大家很可能会遗忘PCA,因为比较少面试中会问到,但是一旦问到,可能就一击必碎
机器学习和深度学习的八股文对于大家提升模型的基础理解还是很有帮助的,有需要的同学可以自查一下,如果都会了,那说明基础非常扎实
以上就是本次分享的所有内容,面试八股找下面这个免费领取


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 15
15 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)