Figma Context MCP 源码解析
01
MCP (Model Context Protocol) 协议概述
Model Context Protocol (MCP) 是一个开放标准,它定义了AI应用程序如何与外部数据源和工具进行安全、受控的交互。MCP的核心理念是为AI模型提供标准化的上下文获取机制,让AI助手能够访问实时、准确的信息来增强其响应能力。
MCP 的工作原理
MCP基于客户端-服务器架构:
-
MCP客户端:通常是AI应用程序(如Cursor、Claude code等)
-
MCP服务器:提供特定功能或数据访问的服务
-
传输层:支持STDIO、HTTP等多种通信方式
MCP借鉴了微服务架构的设计思想,AI客户端进行服务发现,并且实现了安全管控能力。MCP服务将传统API拆解为"Tools",通过统一JSON-RPC协议暴露,解决AI模型调用的标准化问题。MCP请求中嵌入context字段(如用户意图、历史步骤),使服务能基于业务状态动态调整策略。
基于modelcontextprotocol库,我们可以快速创建一个MCP服务,以获取Figma数据为例:
import { McpServer } from"@modelcontextprotocol/sdk/server/mcp.js";
// 1. 创建MCP服务器实例
const server = new McpServer({
name: "Figma MCP Server",
version: "0.4.3"
});
// 2. 注册具体工具 - 相当于在店里摆放各种工具
server.tool(
"get_figma_data",
"获取Figma设计文件的节点信息",
{
type: "object",
properties: {
fileKey: { type: "string" }, // 需要文件ID
nodeId: { type: "string" } // 需要节点ID(可选)
},
required: ["fileKey"]
},
async (args) => { // 处理函数:实际执行的逻辑
// 这里是具体的业务代码
returnawait figmaService.getFile(args.fileKey);
}
);当这个McpServer被注册到MCP客户端后,get_figma_data这一工具就可以被AI助手发现并调用,其返回结果可以作为AI助手的上下文。
使用MCP的优势在于:
-
标准化接口:统一的工具注册和调用机制
-
类型安全:基于Schema的参数验证
-
安全控制:严格的权限和访问控制
-
可扩展性:支持多种数据源和功能集成
02
Figma Context MCP
Figma Context MCP是一个专门为AI编程工具设计的MCP服务,它解决了AI助手无法直接访问Figma设计文件的痛点。价值在于:
-
桥接设计与开发:连接Figma设计工具与AI编程助手(如Cursor)
-
确保设计一致性:基于真实设计数据而非截图进行开发,使AI生成更为精确
-
数据裁剪与转化: 对Figma原始数据进行了简化,只保留对写代码最有用的部分提供给AI
项目结构
src/
├── cli.ts # 命令行入口,支持STDIO和HTTP模式
├── config.ts # 配置管理,支持环境变量和CLI参数
├── mcp.ts # MCP服务器入口,工具注册与处理
├── server.ts # HTTP服务器实现
├── services/ # 核心业务逻辑
│ ├── figma.ts # Figma API封装
│ └── simplify-node-response.ts # 数据简化处理
├── transformers/ # 数据转换器
│ ├── layout.ts # 布局信息转换
│ ├── style.ts # 样式属性转换
│ └── effects.ts # 视觉效果转换
└── utils/ # 工具函数
├── common.ts # 通用工具
├── logger.ts # 日志系统
└── sanitization.ts # 数据清理核心依赖
{
"@modelcontextprotocol/sdk": "^1.10.2", // MCP核心SDK
"@figma/rest-api-spec": "^0.24.0", // Figma API类型定义
"zod": "^3.24.2", // 运行时类型验证
"remeda": "^2.20.1" // 函数式编程工具库
}
运行流程
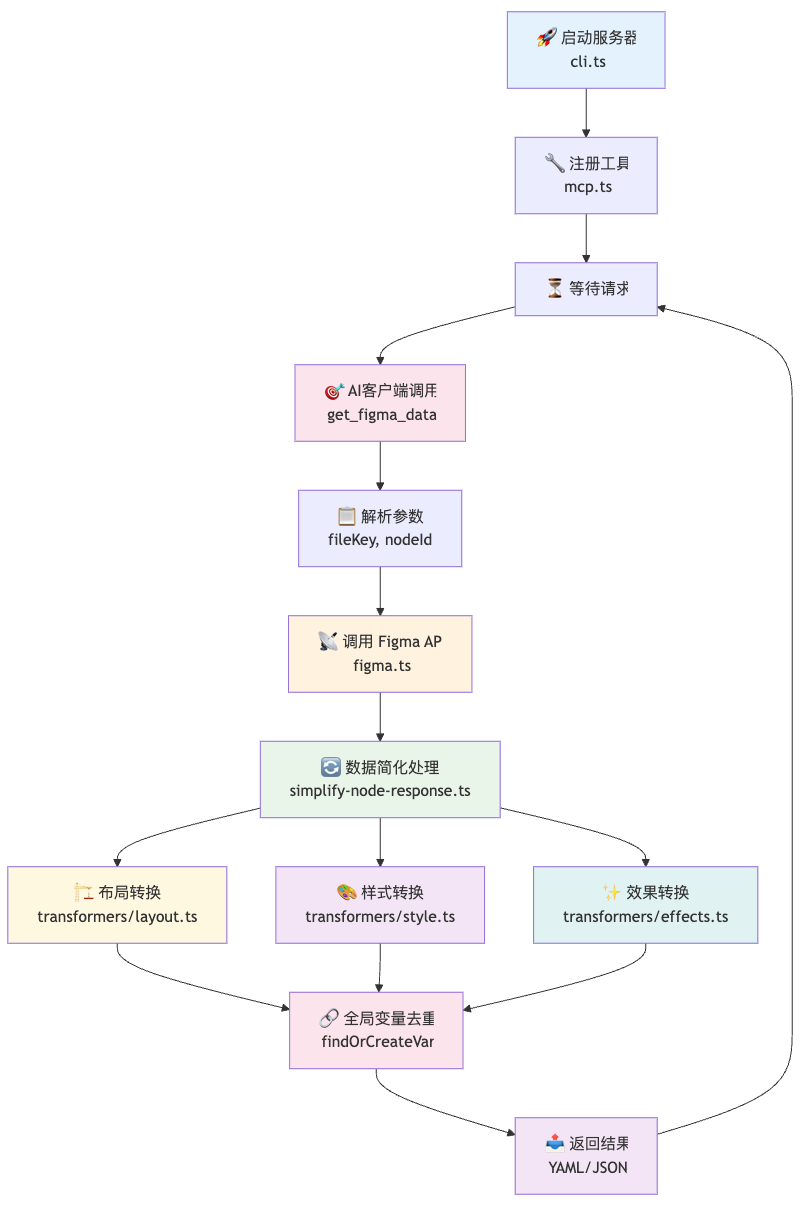
03
实践案例与效果展示
如何使用
项目源码仅支持了streamable http和sse的服务输出格式,为方便本地调试,我们添加一个stdio的方式:
// 启动服务器
if (import.meta.url === `file://${process.argv[1]}`) {
const server = createServer({
figmaApiKey: "figd_your_figma_token",
figmaOAuthToken: "",
useOAuth: false,
});
try {
const transport = new StdioServerTransport();
await server.connect(transport);
console.error('📱 MCP 服务器已启动');
} catch (error) {
console.error('❌ MCP 服务器启动失败:', error);
process.exit(1);
}
}以Cursor为例,可以在mcp.json中添加MCP服务器配置:
"figma-mcp": {
"command": "node",
"args": ["/Users/maoxiongyu/Code/figma-context-mcp/dist/index.js"]
}
这样Cursor就会自行启动这个MCP服务器,服务定义的Tools可以被Cursor Agent发现并调用。
还原效果
现在我们可以从Figma平台获取的选中区域链接,并直接将其粘贴在Cursor的Chat区域:
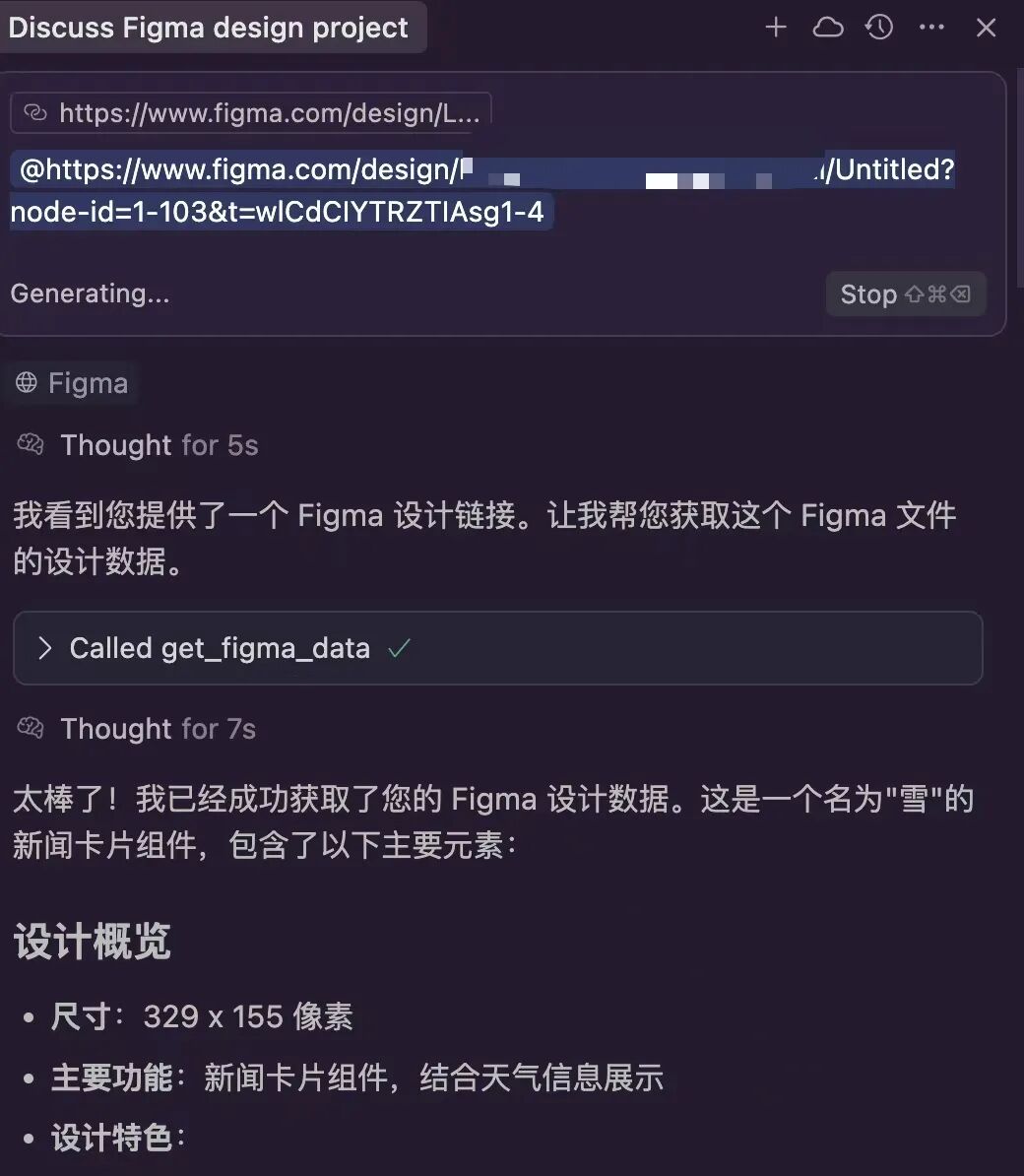
接下来Agent根据读取的信息生成可运行代码:
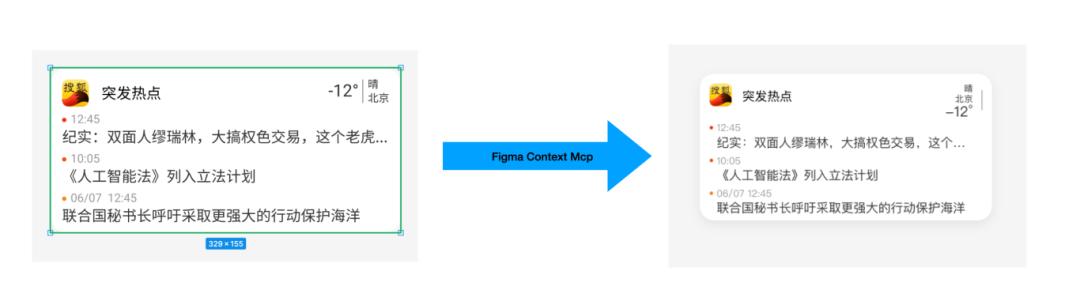
可以看到,Cursor Agent基本准确的还原了设计稿的宽高,颜色,位置等信息,但在右上角温度部分出现了一些瑕疵。
04
4. Figma数据简化处理机制
作为项目的核心功能,Figma-Context-MCP的数据简化机制在 src/services/simplify-node-response.ts 中实现,负责将Figma的复杂原始数据转换为AI友好的结构化信息。
样式去重的执行过程
功能的入口在 parseFigmaResponse 函数,该方法的作用:
-
统一处理两种不同的Figma API响应格式(GetFileResponse 和 GetFileNodesResponse)
-
聚合组件和组件集信息(aggregatedComponents 和 aggregatedComponentSets)
-
过滤可见节点并递归解析为简化的节点结构
-
建立全局样式变量系统,实现样式去重
-
构建最终的简化设计对象并返回
/**
* @param data - Figma API的原始响应数据
* @returns 简化后的设计结构,包含节点、组件、全局样式等信息
*/
exportfunction parseFigmaResponse(data: GetFileResponse | GetFileNodesResponse): SimplifiedDesign {
// ... 处理 aggregatedComponents 和 aggregatedComponentSets
// 初始化全局样式变量系统
let globalVars: GlobalVars = {
styles: {},
};
// 解析所有可见节点为简化结构
const simplifiedNodes: SimplifiedNode[] = nodesToParse
.filter(isVisible) // 过滤掉不可见的节点
.map((n) => parseNode(globalVars, n)) // 递归解析每个节点
.filter((child) => child !== null && child !== undefined); // 过滤掉解析失败的节点
// ... 构建最终的简化设计对象
}深度优先的节点遍历
parseNode 函数是整个数据转换的核心,采用深度优先的递归策略:
function parseNode(
globalVars: GlobalVars,
n: FigmaDocumentNode,
parent?: FigmaDocumentNode,
): SimplifiedNode | null {
const { id, name, type } = n;
const simplified: SimplifiedNode = { id, name, type };
// 处理文字样式
if (hasValue("style", n) && Object.keys(n.style).length) {
const textStyle: TextStyle = {
fontFamily: style.fontFamily,
fontWeight: style.fontWeight,
fontSize: style.fontSize,
lineHeight: style.lineHeightPx && style.fontSize
? `${style.lineHeightPx / style.fontSize}em` : undefined,
// ...其他属性
};
// 执行去重
simplified.textStyle = findOrCreateVar(globalVars, textStyle, "style");
}
// 继续处理填充、边框、效果、布局(每个都调用findOrCreateVar去重)
// ...
// 递归处理子节点(关键:在最后处理)
if (hasValue("children", n) && n.children.length > 0) {
const children = n.children
.filter(isVisible) // 过滤不可见节点
.map((child) => parseNode(globalVars, child, n)) // 递归调用
.filter((child) => child !== null && child !== undefined);
if (children.length) {
simplified.children = children;
}
}
return simplified;
}函数接收的参数中 FigmaDocumentNode 是由Figma官方 @figma/rest-api-spec 定义的节点类型。parseNode 函数通过对 FigmaDocumentNode 节点进行递归裁剪,实现简化数据的目的。
代码注释的设计思考:源代码在递归处理子节点处有个很重要的注释:
"Include children at the very end so all relevant configuration data for the element is output first and kept together for the AI."
这说明作者特意将子节点处理放在最后,确保AI能先看到元素自身的完整信息,再看子元素。这个设计体现了作者对AI认知模式的"焦点机制"的深刻思考,AI可以首先构建元素的骨架,而不是被"淹没"在细节中,导致写出混乱的代码。
在 parseNode 中,findOrCreateVar 函数实现了样式去重的核心逻辑:
function findOrCreateVar(globalVars: GlobalVars, value: any, prefix: string): StyleId {
// 检查是否已存在相同的值
const [existingVarId] =
Object.entries(globalVars.styles).find(
([_, existingValue]) =>JSON.stringify(existingValue) === JSON.stringify(value),
) ?? [];
if (existingVarId) {
return existingVarId as StyleId; // 复用已有样式ID
}
// 创建新的变量ID
const varId = generateVarId(prefix);
globalVars.styles[varId] = value; // 利用globalVars全局变量记录已处理的样式
return varId;
}样式分类存储:项目将样式分为5个类别,每个都有独立的去重机制,然后调用 findOrCreateVar 执行去重:
// GlobalVars 类型定义
type GlobalVars = {
styles: Record<StyleId, StyleTypes>; // 所有样式统一存储
};
// StyleTypes 包含5种样式类型
type StyleTypes =
| TextStyle // 文字样式
| SimplifiedFill[] // 填充样式
| SimplifiedLayout // 布局样式
| SimplifiedStroke // 边框样式
| SimplifiedEffects // 效果样式
| string;05
数据转换与处理策略
前面拆解了MCP对Figma原始数据的解析流程,接下来探讨一下作者对不同Figma文件节点数据的处理细节。
单位转换中的响应式处理
文字样式处理体现设计感的地方在于单位转换策略。在 parseNode 函数中,作者选择将行高转换为相对单位(em),字符间距转换为百分比:
// src/services/simplify-node-response.ts 文字样式处理
const textStyle: TextStyle = {
fontFamily: style.fontFamily,
fontWeight: style.fontWeight,
fontSize: style.fontSize,
lineHeight: style.lineHeightPx && style.fontSize
? `${style.lineHeightPx / style.fontSize}em` : undefined, // 转换为相对单位
letterSpacing: style.letterSpacing && style.letterSpacing !== 0 && style.fontSize
? `${(style.letterSpacing / style.fontSize) * 100}%` : undefined,
textCase: style.textCase,
textAlignHorizontal: style.textAlignHorizontal,
textAlignVertical: style.textAlignVertical,
};Figma中的绝对像素值在不同屏幕尺寸下会失去灵活性,而相对单位能确保文字在各种场景下保持良好的可读性。这不是简单的数值转换,而是设计理念的转译:设计稿是静态的、固定尺寸的,而Web产品是动态的、多设备适配的。通过这种单位转换,让AI生成的代码可以具备响应式特性。
Transformers的模块化设计
作者将复杂的样式处理逻辑拆分为三个专门的转换器(Transformers),每个都负责一类特定的样式转换:
Effects Transformer(src/transformers/effects.ts)专门处理视觉效果,对不同效果类型分类处理:
// 阴影效果的智能分类
const dropShadows = effects.filter((e): e is DropShadowEffect => e.type === "DROP_SHADOW").map(simplifyDropShadow);
const innerShadows = effects.filter((e): e is InnerShadowEffect => e.type === "INNER_SHADOW").map(simplifyInnerShadow);
// 将阴影数组合并为CSS字符串
const allShadows = [...dropShadows, ...innerShadows];
const boxShadow = allShadows.length > 0 ? allShadows.join(', ') : undefined;
// 根据节点类型智能选择CSS属性
const result: SimplifiedEffects = {};
if (boxShadow) {
if (n.type === "TEXT") {
result.textShadow = boxShadow; // 文字节点用textShadow
} else {
result.boxShadow = boxShadow; // 其他节点用boxShadow
}
}Style Transformer(src/transformers/style.ts)处理边框样式,支持复杂的边框配置:
// 支持不同边的独立粗细设置
if (hasValue("individualStrokeWeights", n, isStrokeWeights)) {
strokes.strokeWeight = generateCSSShorthand(n.individualStrokeWeights);
}Layout Transformer(src/transformers/layout.ts)是最复杂的转换器,将Figma的Auto Layout转换为CSS Flexbox布局,包含了大量的布局逻辑转换。
// Figma Auto Layout 转换为 CSS Flexbox
function transformAutoLayout(node: AutoLayoutNode): SimplifiedLayout {
const layout: SimplifiedLayout = {};
// 布局方向转换
if (node.layoutMode === "HORIZONTAL") {
layout.display = "flex";
layout.flexDirection = "row";
} elseif (node.layoutMode === "VERTICAL") {
layout.display = "flex";
layout.flexDirection = "column";
}
// 主轴对齐方式转换
const alignmentMap = {
"MIN": "flex-start",
"CENTER": "center",
"MAX": "flex-end",
"SPACE_BETWEEN": "space-between"
};
layout.justifyContent = alignmentMap[node.primaryAxisAlignItems];
// 交叉轴对齐转换
layout.alignItems = alignmentMap[node.counterAxisAlignItems];
// 间距处理
if (node.itemSpacing) {
layout.gap = `${node.itemSpacing}px`;
}
return layout;
}这种复杂性体现在需要处理Figma和CSS两套不同的布局系统映射关系。
Transformers模块化设计的好处是每个转换器专注于自己的领域,代码更清晰,也更容易维护和扩展。
图片的处理机制
图片处理是Figma文件数据转换中不可或缺的一项功能。作者设计了针对不同场景的处理策略:
Fill Images(填充图片):通过 getImageFills 方法处理,获取已经作为背景填充使用的现有图片:
// src/services/figma.ts - 处理填充图片
async getImageFills(fileKey: string, nodes: FetchImageFillParams[], localPath: string): Promise<string[]> {
const endpoint = `/files/${fileKey}/images`; // 获取文件中的图片资源
const file = awaitthis.request<GetImageFillsResponse>(endpoint);
const { images = {} } = file.meta;
const promises = nodes.map(async ({ imageRef, fileName }) => {
const imageUrl = images[imageRef]; // 通过imageRef获取已存在的图片
if (!imageUrl) return"";
return downloadFigmaImage(fileName, localPath, imageUrl);
});
returnPromise.all(promises);
}Rendered Images(渲染图片):通过 getImages 方法处理,将Figma节点渲染成图片文件,支持PNG和SVG两种格式:
// src/services/figma.ts - 将节点渲染成图片
async getImages(fileKey: string, nodes: FetchImageParams[], localPath: string, pngScale: number, svgOptions: {...}): Promise<string[]> {
// 分别处理PNG和SVG渲染请求
const pngIds = nodes.filter(({ fileType }) => fileType === "png").map(({ nodeId }) => nodeId);
const svgIds = nodes.filter(({ fileType }) => fileType === "svg").map(({ nodeId }) => nodeId);
// 并行请求不同格式的渲染
const pngFiles = pngIds.length > 0
? this.request<GetImagesResponse>(`/images/${fileKey}?ids=${pngIds.join(",")}&format=png&scale=${pngScale}`)
: ({} as GetImagesResponse["images"]);
const svgFiles = svgIds.length > 0
? this.request<GetImagesResponse>(`/images/${fileKey}?${svgParams}`)
: ({} as GetImagesResponse["images"]);
// Promise.all 确保并行执行
const files = awaitPromise.all([pngFiles, svgFiles]).then(([f, l]) => ({ ...f, ...l }));
// 批量下载处理好的图片 files...
}两者的区别:
-
Fill Images:获取设计稿中已有的图片资源(如背景图片、Logo等)
-
Rendered Images:将设计元素(如图标、形状、文字等)渲染导出为图片文件,这里的PNG/SVG是渲染格式的选择
语义化转换的AI友好性考量
在 parseNode 函数末尾,有一个看似简单但极其重要的类型转换:
// src/services/simplify-node-response.ts 语义化类型转换
if (type === "VECTOR") {
simplified.type = "IMAGE-SVG";
}对AI助手来说,"VECTOR" 是一个抽象的Figma概念,而 "IMAGE-SVG" 则直接指向Web开发中的具体实现方式。AI看到 "IMAGE-SVG" 会立即联想到 <img> 标签、SVG嵌入、矢量图形等前端开发概念,从而生成更准确的代码。
06
总结
随着MCP生态的成熟,可以预见一个新的开发范式:设计师在Figma这样的设计平台中创作,AI助手实时理解设计意图并生成高质量代码,开发者专注于代码审查和架构设计。设计稿不再是"参考图片",而是"可执行的数据源"。
Figma-Context-Mcp 提供了从"截图驱动"到"数据驱动"的开发模式转变,让AI助手能够基于真实设计数据生成更为准确的代码。同时,通过MCP这样的标准协议,不同工具间可以无缝集成,构建更加智能的开发生态。


中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 15
15 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)