RAG评估:G-Eval与其他LLM评估框架
G-Eval是一种创新的AI评估框架,利用大语言模型(如GPT-4)作为裁判来评估RAG系统的输出质量。它通过"思维链"技术生成详细评估步骤,再结合概率加权打分,显著提升了评估效率与准确性。相比传统的人工打分或BLEU等指标,G-Eval与人类判断高度一致,为AI系统评估提供了新范式。该框架已在摘要和对话生成等任务中展现出色表现,成为AI评估领域的重要突破。
你是不是也和我一样,每天都在捣鼓着各种RAG(检索增强生成)应用?我们满怀激情地搭建管道、调试Prompt、优化检索,期待着它能像个“万事通”一样有问必答。但一个灵魂拷问随之而来:我们怎么知道它到底好不好?
过去,我们评估AI生成的文本,要么靠“人肉”——找一群人来打分,但这种方式成本高昂、耗时漫长,难以规模化。要么靠传统的自动化指标,比如BLEU、ROUGE,这些指标主要看生成文本和参考答案在字词上有多大重叠。对于需要一点创意和多样性的任务来说,它们就像一个只会对标准答案的刻板老师,经常给出和人类直觉相去甚远的分数。
然而,一个全新的范式正在崛起,那就是“LLM-as-a-Judge”,即“让大模型来当裁判”。 核心思想很简单:既然GPT-4这样的大模型已经具备了强大的语言理解和推理能力,为什么不让它来评估我们RAG系统的输出质量呢?
在这个浪潮中,一个名为 G-Eval 的框架脱颖而出,它不仅是这个新范式的先行者,更以其出色的表现,证明了“让模型评模型”这条路,走得通!
G-Eval是什么?—— 不仅仅是“让GPT-4打个分”
初听G-Eval,你可能会觉得,这不就是写个Prompt,然后把RAG的回答丢给GPT-4,让它给个1到5分吗?如果你这么想,那就小看G-Eval了。它不是一次简单的调用,而是一套设计精巧、有章可循的结构化评估框架。
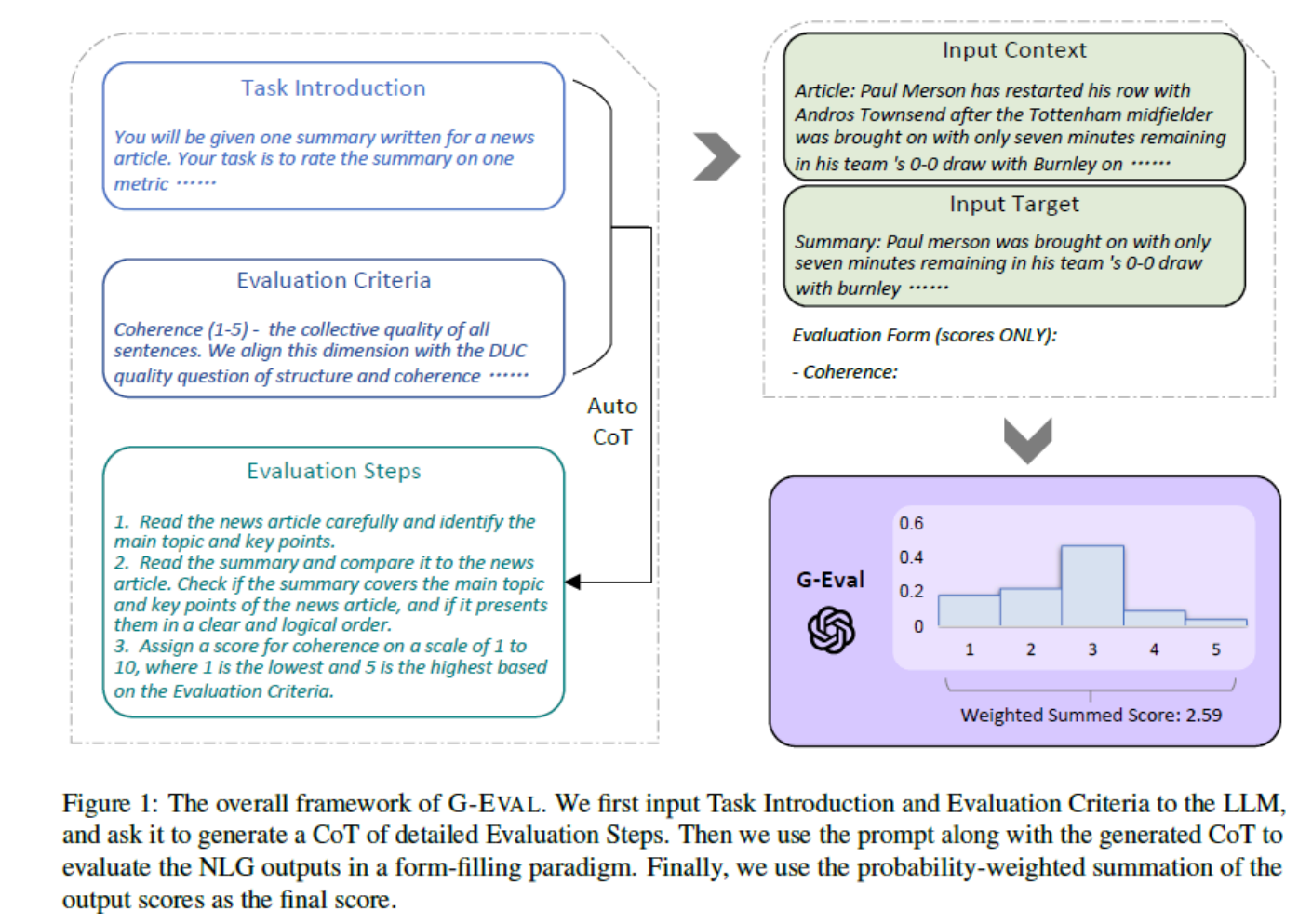
根据其开创性论文《G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment》,G-Eval的核心流程可以分为两大步:
第一步:生成评估“思维链”(Chain-of-Thought, CoT)
这正是G-Eval的精髓所在。你不需要给评估模型(比如GPT-4)一堆复杂的指令。你只需要提供一个简单的任务介绍和高级评估标准,比如“请评估这段摘要的连贯性”。 G-Eval会利用模型的“思维链”能力,首先生成一个详细、分步骤的评估计划。
这就好比你请一位美食评论家评价一道菜,你只说“尝尝这道菜怎么样”,他会先在脑中形成一套评价体系:“首先,我要看它的摆盘;其次,闻一下香气;然后,品尝主料和辅料的融合度;最后,感受它的余味。” G-Eval的CoT步骤,就是让LLM自己先把这个评价体系(即评估步骤)清晰地列出来。
第二步:“填表式”打分与概率加权
当LLM生成了详细的评估步骤后,它就会进入“裁判”模式。它会综合考虑你给的所有信息——用户的原始问题、RAG系统生成的答案、检索到的上下文,以及它自己在第一步生成的评估步骤——然后像填写一份评估表格一样,对每个维度进行分析,最终给出一个分数。
但G-Eval还有一手“秘密武器”:概率加权。最终的分数,并不仅仅是模型输出的那个数字(比如“4”分)。G-Eval会考察模型在生成这个分数时,输出各个分数(如“1”到“5”)的概率分布。最终得分是这些分数基于其生成概率的加权总和。这种方法可以有效减少大模型自身的一些评分偏见(比如总是倾向于给中间分),让结果更加稳定和可靠。
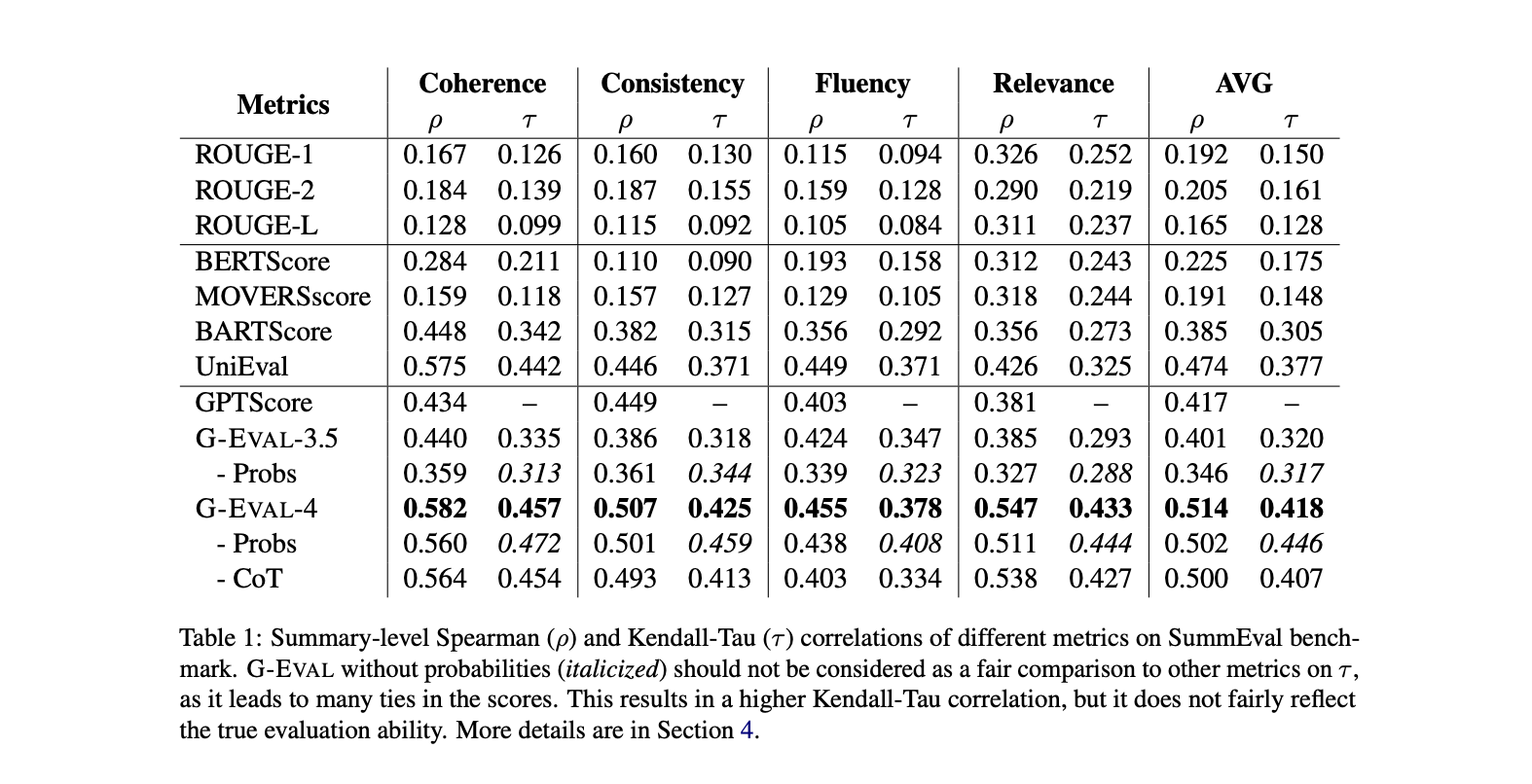
正是这套“先思考,再打分”的组合拳,让G-Eval在摘要和对话生成等任务上,与人类裁判的判断达到了惊人的高相关性,远超以往的各种自动化评估方法。
Prompt




G-Eval 的实验结果
从论文到代码:DeepEval如何将G-Eval发扬光大
点击链接RAG评估:G-Eval与其他LLM评估框架阅读原文

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)